Как я создавал анимацию вложений во время тонкой настройки

Использование Cleanlab, PCA и Procrustes для визуализации тонкой настройки ViT на CIFAR-10.
В области машинного обучения Vision Transformers (ViT) — это тип модели, используемый для классификации изображений. В отличие от традиционных сверточных нейронных сетей, ViT для обработки изображений используют архитектуру преобразователя, которая изначально была разработана для задач обработки естественного языка. Точная настройка этих моделей для достижения оптимальной производительности может оказаться сложным процессом. Эти вложения были созданы на основе моделей на различных этапах тонкой настройки и соответствующих им контрольных точек.
![Проецирование вложений с помощью PCA во время тонкой настройки модели Vision Transformer (ViT) [1] на CIFAR10 [3]; источник: создано автором](/static/storage/61219133647460553346852519487690187580.gif)
Анимация получила более 200 000 просмотров. Он был хорошо принят, и многие читатели проявили интерес к тому, как он был создан. Эта статья предназначена для поддержки читателей и всех, кто заинтересован в создании подобных визуализаций.
В этой статье я стремлюсь предоставить подробное руководство о том, как создать такую анимацию, с подробным описанием необходимых шагов: точная настройка, создание вложений, обнаружение выбросов, PCA, Прокруст, проверка и создание анимации.
Полный код анимации также доступен в прилагаемом репозитории на GitHub.
Подготовка: Тонкая настройка
Первым шагом является тонкая настройка модели google/vit-base-patch16–224-in21k Vision Transformer (ViT) [1], которая предварительно обучена. Для этого мы используем набор данных CIFAR-10 [2], содержащий 60 000 изображений, классифицированных по десяти различным классам: самолеты, автомобили, птицы, кошки, олени, собаки, лягушки, лошади, корабли и грузовики.
Вы можете выполнить шаги, описанные в руководстве «Обнимающее лицо», для классификации изображений с помощью преобразователей, чтобы выполнить процесс точной настройки также для CIFAR-10. Кроме того, мы используем TrainerCallback для сохранения значений потерь во время обучения в файл CSV для последующего использования в анимации.
from transformers import TrainerCallback
class PrinterCallback(TrainerCallback):
def on_log(self, args, state, control, logs=None, **kwargs):
_ = logs.pop("total_flos", None)
if state.is_local_process_zero:
if len(logs) == 3: # skip last row
with open("log.csv", "a") as f:
f.write(",".join(map(str, logs.values())) + "\n")Важно увеличить интервал сохранения контрольных точек, установив save_strategy="step" и низкое значение для save_step в TrainingArguments, чтобы обеспечить достаточное количество контрольных точек для анимации. Каждый кадр анимации соответствует одной контрольной точке. Папка для каждой контрольной точки и файл CSV создаются во время обучения и готовы к дальнейшему использованию.
Создание вложений
Мы используем AutoFeatureExtractor и AutoModel из библиотеки Transformers для создания вложений из тестового разделения набора данных CIFAR-10 с использованием различных контрольных точек модели.
Каждое вложение представляет собой 768-мерный вектор, представляющий одно из 10 000 тестовых изображений для одной контрольной точки модели. Эти внедрения можно хранить в той же папке, что и контрольные точки, чтобы обеспечить хороший обзор.
Извлечение выбросов
Мы можем использовать класс OutOfDistribution, предоставляемый библиотекой Cleanlab, для выявления выбросов на основе вложений для каждой контрольной точки. Полученные оценки затем позволяют определить 10 лучших выбросов для анимации.
from cleanlab.outlier import OutOfDistribution
def get_ood(sorted_checkpoint_folder, df):
...
ood = OutOfDistribution()
ood_train_feature_scores = ood.fit_score(features=embedding_np)
df["scores"] = ood_train_feature_scores
Применение PCA и анализа Прокруста
С помощью анализа главных компонентов (PCA) для пакета scikit-learn мы визуализируем вложения в двумерном пространстве, уменьшая 768-мерные векторы до двухмерных. При пересчете PCA для каждого временного шага могут возникать большие скачки анимации из-за переворота оси или вращения. Чтобы решить эту проблему, мы применяем дополнительный анализ Прокруста [3] из пакета SciPy для геометрического преобразования каждого кадра в последний кадр, который включает в себя только перемещение, вращение и равномерное масштабирование. Это обеспечивает более плавные переходы в анимации.
from sklearn.decomposition import PCA
from scipy.spatial import procrustes
def make_pca(sorted_checkpoint_folder, pca_np):
...
embedding_np_flat = embedding_np.reshape(-1, 768)
pca = PCA(n_components=2)
pca_np_new = pca.fit_transform(embedding_np_flat)
_, pca_np_new, disparity = procrustes(pca_np, pca_np_new)
Обзор в Spotlight
Прежде чем доработать всю анимацию, мы проводим обзор в Spotlight. В этом процессе мы используем первую и последнюю контрольные точки для генерации встраивания, PCA и обнаружения выбросов. Загружаем полученный DataFrame в Spotlight:
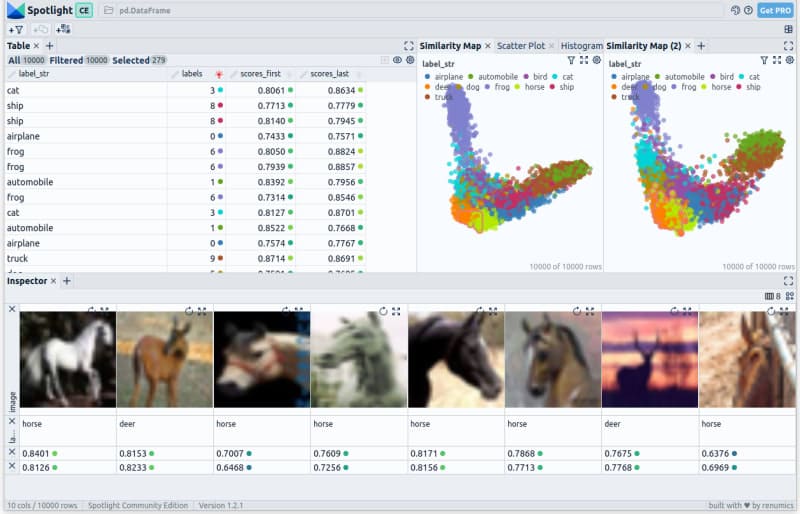
Spotlight предоставляет подробную таблицу в левом верхнем углу, демонстрирующую все поля, присутствующие в наборе данных. В правом верхнем углу отображаются два представления PCA: одно для вложений, созданных с использованием первой контрольной точки, и одно для последней контрольной точки. Наконец, в нижней части представлены выбранные изображения.
Отказ от ответственности: автор оригинальной статьи также является одним из разработчиков Spotlight.
Создайте анимацию
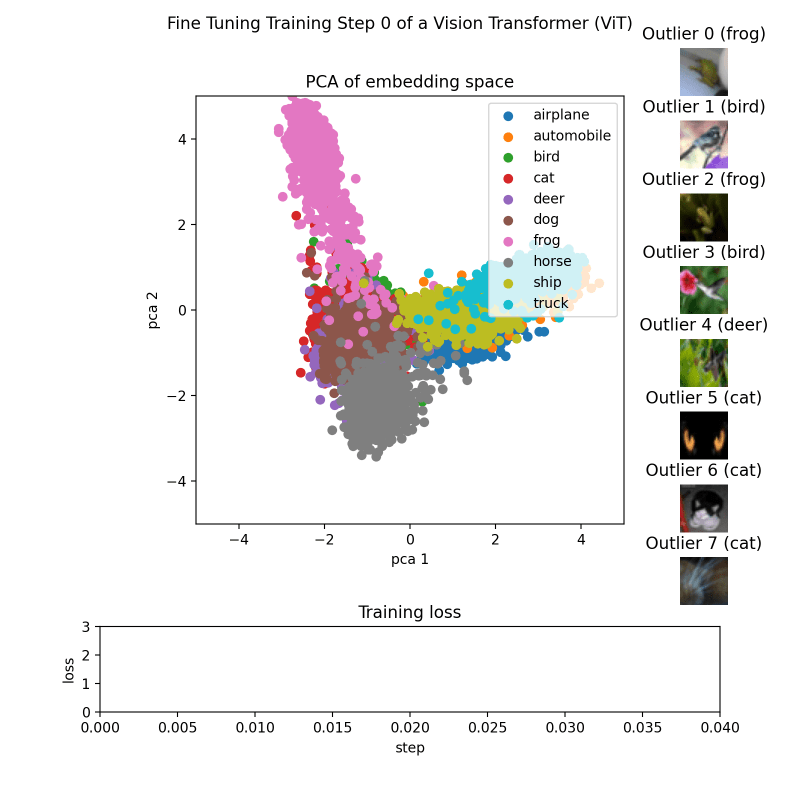
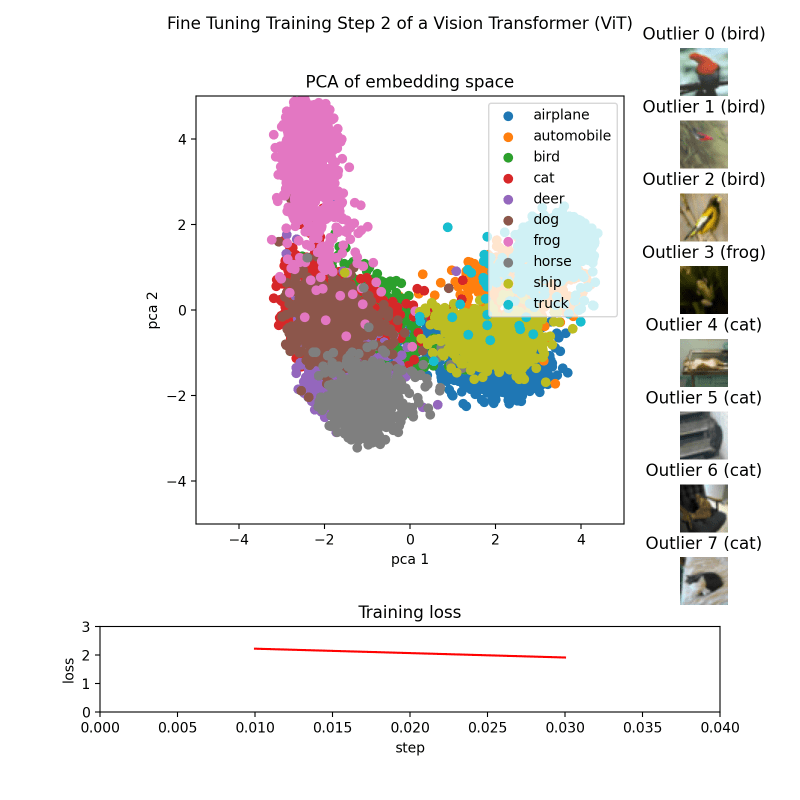
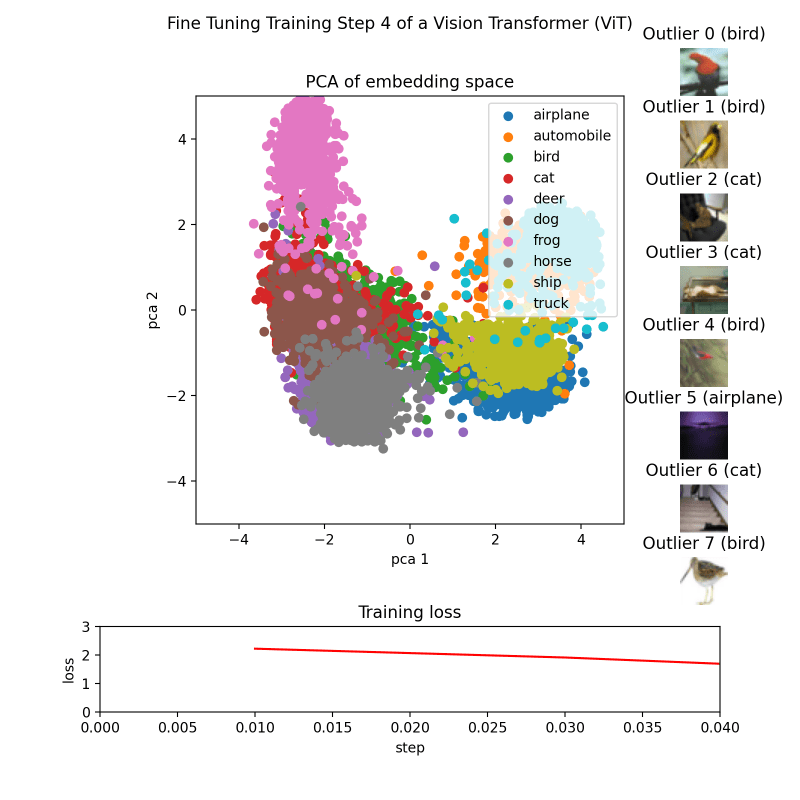
Для каждой контрольной точки мы создаем изображение, которое затем сохраняем рядом с соответствующей контрольной точкой.
Это достигается за счет использования функций make_pca(...) и get_ood(...), которые генерируют 2D-точки, представляющие встраивание, и извлекают 8 верхних выбросов соответственно. Двухмерные точки отображаются цветами, соответствующими их классам. Выбросы сортируются по их баллам, а соответствующие им изображения отображаются в таблице лидеров. Потери на обучение загружаются из файла CSV и отображаются в виде линейного графика.
Наконец, все изображения можно скомпилировать в GIF с помощью таких библиотек, как imageio или аналогичных.
Заключение
В этой статье представлено подробное руководство по созданию анимации, визуализирующей процесс тонкой настройки модели Vision Transformer (ViT). Мы прошли этапы создания и анализа внедрений, визуализации результатов и создания анимации, объединяющей эти элементы.
Создание такой анимации не только помогает понять сложный процесс тонкой настройки модели ViT, но и служит мощным инструментом для передачи этих концепций другим.