Как перебирать строки в фрейме данных Pandas

Pandas - чрезвычайно популярный фреймворк для обработки данных в Python. Во многих случаях вам может потребоваться перебрать данные - либо для их распечатки, либо для выполнения с ними некоторых операций.
В этом руководстве мы рассмотрим, как перебирать строки в Pandas DataFrame.
Давайте рассмотрим три основных способа перебора DataFrame:
items()iterrows()itertuples()
Итерация DataFrames с помощью items()
Давайте настроим некоторые данные о вымышленных людях в DataFrame:
import pandas as pd
df = pd.DataFrame({
'first_name': ['John', 'Jane', 'Marry', 'Victoria', 'Gabriel', 'Layla'],
'last_name': ['Smith', 'Doe', 'Jackson', 'Smith', 'Brown', 'Martinez'],
'age': [34, 29, 37, 52, 26, 32]},
index=['id001', 'id002', 'id003', 'id004', 'id005', 'id006'])
Обратите внимание, что мы используем id как наш индекс DataFrame. Давайте посмотрим, как выглядит этот DataFrame:
print(df.to_string())
first_name last_name age
id001 John Smith 34
id002 Jane Doe 29
id003 Marry Jackson 37
id004 Victoria Smith 52
id005 Gabriel Brown 26
id006 Layla Martinez 32
Теперь, чтобы перебрать этот DataFrame, мы воспользуемся функцией items():
df.items()
Он возвращает генератор:
<generator object DataFrame.items at 0x7f3c064c1900>
Мы можем использовать это для генерации пар col_name и data. Эти пары будут содержать имя столбца и каждую строку данных для этого столбца. Давайте пройдемся по именам столбцов и их данным:
for col_name, data in df.items():
print("col_name:",col_name, "\ndata:",data)
Это приводит к:
col_name: first_name
data:
id001 John
id002 Jane
id003 Marry
id004 Victoria
id005 Gabriel
id006 Layla
Name: first_name, dtype: object
col_name: last_name
data:
id001 Smith
id002 Doe
id003 Jackson
id004 Smith
id005 Brown
id006 Martinez
Name: last_name, dtype: object
col_name: age
data:
id001 34
id002 29
id003 37
id004 52
id005 26
id006 32
Name: age, dtype: int64
Мы успешно перебрали все строки в каждом столбце. Обратите внимание, что столбец индекса остается неизменным на протяжении итерации, поскольку это связанный индекс для значений. Если вы не определяете индекс, Pandas соответствующим образом пронумеровывает столбец индекса.
Мы также можем напечатать конкретную строку, передав номер индекса в data, как мы это делаем со списками Python:
for col_name, data in df.items():
print("col_name:",col_name, "\ndata:",data[1])
Обратите внимание, что индекс списка начинается с нуля, поэтому data[1] будет относиться ко второй строке. Вы увидите этот вывод:
col_name: first_name
data: Jane
col_name: last_name
data: Doe
col_name: age
data: 29
Мы также можем передать значение индекса в data.
for col_name, data in df.items():
print("col_name:",col_name, "\ndata:",data['id002'])
Результат будет таким же, как и раньше:
col_name: first_name
data: Jane
col_name: last_name
data: Doe
col_name: age
data: 29
Итерация DataFrames с помощью iterrows()
В то время как df.items() перебирает строки по столбцам, выполняя цикл для каждого столбца, мы можем использовать iterrows(), чтобы получить все строковые данные индекса.
Попробуем перебрать строки с помощью iterrows():
for i, row in df.iterrows():
print(f"Index: {i}")
print(f"{row}\n")
В цикле for i представляет столбец индекса (наш DataFrame имеет индексы от id001 до id006) и row содержит данные для этого индекса во всех столбцах. Наш результат будет выглядеть так:
Index: id001
first_name John
last_name Smith
age 34
Name: id001, dtype: object
Index: id002
first_name Jane
last_name Doe
age 29
Name: id002, dtype: object
Index: id003
first_name Marry
last_name Jackson
age 37
Name: id003, dtype: object
...
Точно так же мы можем перебирать строки в определенном столбце. Просто передав номер индекса или имя столбца в row. Например, мы можем выборочно распечатать первый столбец строки следующим образом:
for i, row in df.iterrows():
print(f"Index: {i}")
print(f"{row['0']}")
Или:
for i, row in df.iterrows():
print(f"Index: {i}")
print(f"{row['first_name']}")
Оба они производят такой вывод:
Index: id001
John
Index: id002
Jane
Index: id003
Marry
Index: id004
Victoria
Index: id005
Gabriel
Index: id006
Layla
Итерация DataFrames с помощью itertuples()
Функция itertuples() также возвращает генератор, который генерирует значение строк в кортежах. Давайте попробуем это:
for row in df.itertuples():
print(row)
Вы увидите это в своей оболочке Python:
Pandas(Index='id001', first_name='John', last_name='Smith', age=34)
Pandas(Index='id002', first_name='Jane', last_name='Doe', age=29)
Pandas(Index='id003', first_name='Marry', last_name='Jackson', age=37)
Pandas(Index='id004', first_name='Victoria', last_name='Smith', age=52)
Pandas(Index='id005', first_name='Gabriel', last_name='Brown', age=26)
Pandas(Index='id006', first_name='Layla', last_name='Martinez', age=32)
У метода itertuples() два аргумента: index и name.
Мы можем не отображать столбец индекса, установив для параметра index значение False:
for row in df.itertuples(index=False):
print(row)
У наших кортежей больше не будет отображаться индекс:
Pandas(first_name='John', last_name='Smith', age=34)
Pandas(first_name='Jane', last_name='Doe', age=29)
Pandas(first_name='Marry', last_name='Jackson', age=37)
Pandas(first_name='Victoria', last_name='Smith', age=52)
Pandas(first_name='Gabriel', last_name='Brown', age=26)
Pandas(first_name='Layla', last_name='Martinez', age=32)
Как вы уже заметили, этот генератор выдает именованные кортежи с именем по умолчанию Pandas. Мы можем изменить это, передав People аргумент параметру name. Вы можете выбрать любое имя, которое вам нравится, но всегда лучше выбирать имена, соответствующие вашим данным:
for row in df.itertuples(index=False, name='People'):
print(row)
Теперь наш вывод будет:
People(first_name='John', last_name='Smith', age=34)
People(first_name='Jane', last_name='Doe', age=29)
People(first_name='Marry', last_name='Jackson', age=37)
People(first_name='Victoria', last_name='Smith', age=52)
People(first_name='Gabriel', last_name='Brown', age=26)
People(first_name='Layla', last_name='Martinez', age=32)
Производительность итерации с помощью Pandas
Официальная документация Pandas предупреждает, что итерационный процесс медленный. Если вы выполняете итерацию, чтобы изменить данные DataFrame, векторизация была бы более быстрой альтернативой. Кроме того, не рекомендуется изменять данные во время итерации по строкам, поскольку Pandas иногда возвращает копию данных в строке, а не ссылку на нее, что означает, что не все данные будут фактически изменены.
Для небольших наборов данных вы можете использовать этот метод to_string() для отображения всех данных. Для больших наборов данных, содержащих много столбцов и строк, вы можете использовать методы head(n) или tail(n) для печати первых n строк вашего DataFrame (значение по умолчанию n- 5).
Сравнение скорости
Чтобы измерить скорость каждого конкретного метода, мы обернули их в функции, которые будут выполнять их 1000 раз и возвращать среднее время выполнения.
Чтобы проверить эти методы, мы будем использовать обе функции print() и list.append(), чтобы обеспечить более точные данные сравнения и для покрытия общих случаев использования. Чтобы определить справедливого победителя, мы будем перебирать DataFrame и использовать только одно значение для печати или добавления в цикл.
Вот как выглядят возвращаемые значения для каждого метода:
Например, при items():
('first_name',
id001 John
id002 Jane
id003 Marry
id004 Victoria
id005 Gabriel
id006 Layla
Name: first_name, dtype: object)
iterrows() предоставит все данные столбца для конкретной строки:
('id001',
first_name John
last_name Smith
age 34
Name: id001, dtype: object)
И, наконец, одна строка для элемента itertuples() будет выглядеть так:
Pandas(Index='id001', first_name='John', last_name='Smith', age=34)
Вот средние результаты в секундах:
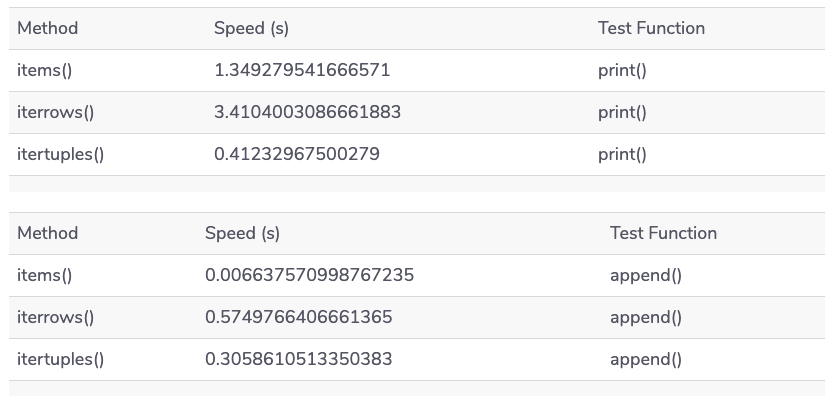
Печать значений потребует больше времени и ресурсов, чем добавление в целом, и наши примеры не являются исключением. Хотя метод itertuples() работает лучше в сочетании с print(), метод items() значительно превосходит другие при использовании append() и iterrows() остается последним для каждого сравнения.
Обратите внимание, что результаты этих тестов сильно зависят от других факторов, таких как ОС, среда, вычислительные ресурсы и т.д. Размер ваших данных также будет влиять на ваши результаты.
Вывод
Мы научились перебирать в DataFrame с тремя различными методами Pandas - items(), iterrows(), itertuples(). В зависимости от ваших данных и предпочтений вы можете использовать один из них в своих проектах.