Как работает индексация в базе данных NebulaGraph

Индексирование - незаменимая функция в системе баз данных. Графовая база данных не является исключением.
Индекс на самом деле представляет собой отсортированную структуру данных в системе управления базами данных. Различные системы баз данных используют разные структуры сортировки.
Популярные типы индексов включают:
- B-Tree index
- B+-Tree index
- B*-Tree index
- Hash index
- Bitmap index
- Inverted index
Каждый из них использует свои собственные алгоритмы сортировки.
Индекс базы данных позволяет эффективно извлекать данные из баз данных. Несмотря на улучшение производительности запросов, у индексов есть некоторые недостатки:
- Для создания и поддержания индексов требуется время, которое масштабируется в зависимости от размера набора данных.
- Индексам требуется дополнительное физическое пространство для хранения.
- Вставка, удаление и обновление данных занимает больше времени, поскольку индекс также необходимо поддерживать синхронно.
Учитывая вышесказанное, NebulaGraph теперь поддерживает индексацию для более эффективного извлечения свойств.
Этот пост дает подробное введение в дизайн индексации NebulaGraph.
Основные понятия для понимания индексации NebulaGraph
Ниже приведен список общих терминов индекса NebulaGraph, которые мы используем в посте.
- Tag: метка, связанная со списком свойств. Каждая вершина может быть связана с несколькими тегами. Тег идентифицируется с помощью TagID. Вы можете рассматривать тег как таблицу узлов в SQL.
- Edge: подобно тегу, тип Edge представляет собой группу свойств на ребрах. Вы можете рассматривать тип ребра как таблицу ребер в SQL.
- Property: пары имя-значение на теге или ребре. Его тип данных определяется типом тега или ребра.
- Partition: минимальная логическая единица хранения NebulaGraph. StorageEngine может содержать несколько разделов. Раздел делится на лидера и ведомого. Мы используем Raft, чтобы гарантировать согласованность данных между лидером и последователем.
- Graph space: физически изолированное пространство для определенного графа. Теги и типы ребер в одном графе не зависят от тегов в другом графе. Кластер NebulaGraph может иметь несколько пространств графа.
- Index: указатель в этом посте относится конкретно к указателю ~~ ~~тегов или свойств типа края. Его тип данных зависит от тега или типа ребра.
- TagIndex: индекс, созданный для тега. Вы можете создать несколько индексов для одного и того же тега. Составной индекс с перекрестными тегами пока не поддерживается.
- EdgeIndex: индекс, созданный для типа ребра. Точно так же вы можете создать несколько индексов для одного и того же типа кромки. Составной индекс перекрестного типа пока не поддерживается.
- Scan Policy: политика сканирования индексов. Обычно существует несколько методов сканирования индексов для выполнения одного оператора запроса, но сама политика сканирования решает, какой метод использовать в конечном итоге.
- Optimizer: оптимизируйте условия запроса, такие как сортировка, разделение и слияние узлов подвыражений дерева выражений предложения _where_. Он используется для повышения эффективности запросов.
Индексация в графовой базе данных
Существует два типичных способа запроса данных в NebulaGraph или, в более общем смысле, в графовой базе данных:
- Один начинается с вершины, извлекая ее соседей (N-hop) по определенным типам ребер.
- Другой — извлечение вершин или ребер, содержащих заданные значения свойств.
В последнем сценарии требуется высокопроизводительное сканирование для выборки ребер или вершин, а также значений свойств.
Чтобы повысить эффективность запроса значений свойств, мы внедрили индексирование в NebulaGraph. Сортируя значения свойств ребер или вершин, пользователи могут быстро найти определенное свойство и избежать полного сканирования.
Вот что нам нужно для индексации в графовой базе данных:
- Поддержка индексации свойств тегов и типов ребер.
- Поддержка анализа и создание стратегии сканирования индекса.
- Поддержка управления индексами, например создание индекса, перестроение индекса, показ индекса и т. д.
Индексы, которые хранятся в NebulaGraph
Ниже представлена схема хранения индексов в NebulaGraph. Индексы являются частью службы хранения NebulaGraph, поэтому мы помещаем их в общую картину архитектуры хранилища.
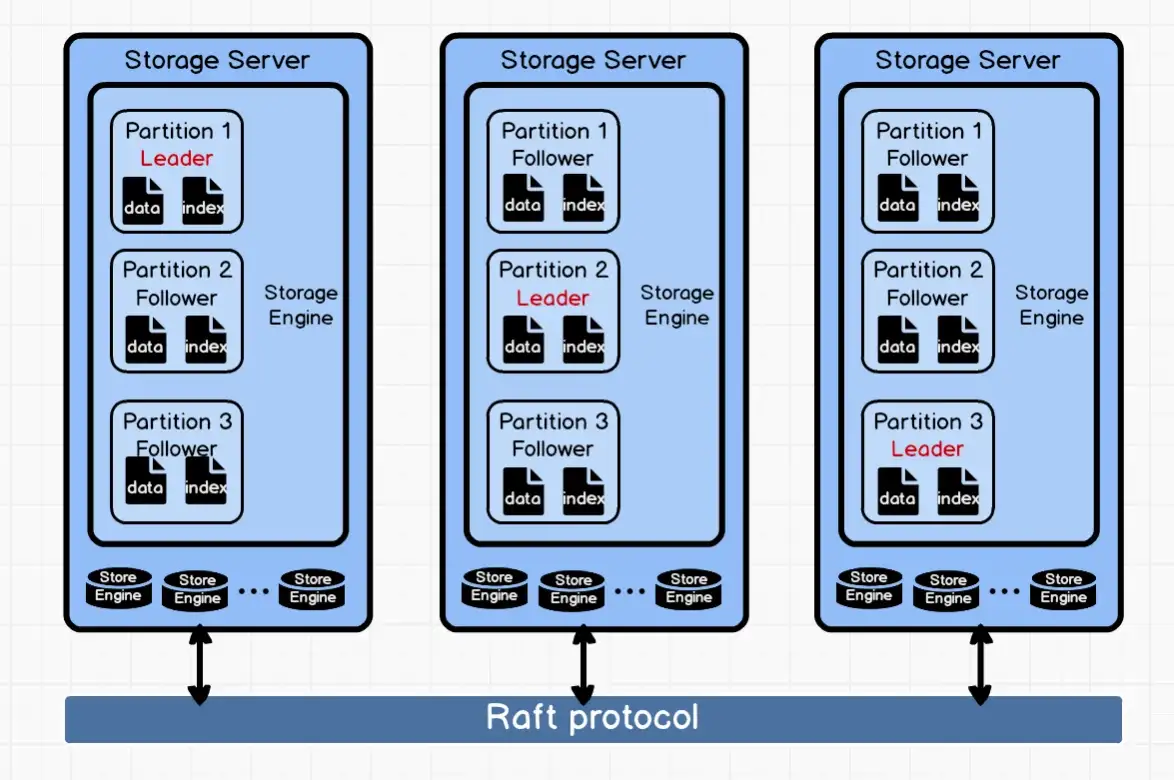
Как видно из приведенного выше рисунка, каждый сервер хранения может содержать несколько модулей хранения, каждый механизм хранения может содержать несколько разделов.
Различные Partition синхронизируются по протоколу Raft. Каждый Partition содержит как данные, так и индексы. Данные и индексы одной и той же вершины или ребра будут храниться в одном и том же разделе.
Разбивка логики индексирования
Структура хранилища: данные и индексы
В NebulaGraph индексы и (необработанные) данные вершин и ребер хранятся вместе. Чтобы лучше описать структуру хранения индексов, мы собираемся сравнить структуру индексов со структурой необработанных данных.
Структура хранения Vertices
Структура данных Vertices

Индексная структура Vertices

Структура индекса вершины показана в таблице выше, ниже приведены подробные пояснения к полям:
PartitionId: Мы помещаем данные и индекс вершины в один и тот же раздел, потому что:
- При сканировании индекса данные вершины в том же разделе могут быть быстро получены с помощью ключа индекса, так что любые значения свойств этой вершины могут быть легко получены, даже если свойство не принадлежит индексу.
- В настоящее время ребра хранятся путем хэширования идентификатора его начальной вершины, что означает, что местоположение каждого исходящего ребра определяется идентификатором его начальной вершины. Если вершина и ее исходящее ребро хранятся в одном разделе, сканирование индекса может быстро найти все исходящие ребра этой вершины.
IndexId: Идентификатор индекса. Вы можете получить метаданные указанного индекса через indexId, например, TagId, связанный с индексом, и информацию о столбце, в котором находится индекс.
Index binary: Основная структура хранения индекса. Это байтовая кодировка значений всех столбцов, связанных с индексом. Подробная структура будет объяснена в разделе «Двоичный индекс».
VertexId: Идентификатор вершины. В реальном использовании вершина может иметь несколько строк данных из-за разных версий. Однако версии для index. Индекс всегда сопоставляется с тегом последней версии.
Поясним структуру хранилища на примере.
Предположим, что:
- Идентификатор раздела равен 100.
- TagId — это tag_1 и tag_2
- tag_1 содержит три свойства: col_t1_1, col_t1_2 и col_t1_3_
- tag_2 содержит два свойства: col_t2_1 и col_t2_2.
Теперь давайте создадим индекс:
- i1 = tag_1 (col_t1_1, col_t1_2), здесь мы предполагаем, что идентификатор i1 равен 1.
- i2 = tag_2(col_t2_1, col_t2_2), здесь мы предполагаем, что идентификатор i2 равен 2.
Мы видим, что хотя столбец col_t1_3 включен в tag_1, он не используется при создании индекса. Это связано с тем, что вы можете создать индекс тегов на основе одного или нескольких столбцов в NebulaGraph.
Вставка вершин
// VertexId = hash("v_t1_1"), assume id is 50INSERT VERTEX tag_1(col_t1_1, col_t1_2, col_t1_3), tag_2(col_t2_1, col_t2_2) \
VALUES hash("v_t1_1"):("v_t1_1", "v_t1_2", "v_t1_3", "v_t2_1", "v_t2_2");Мы видим, что VertexId — это хешированное значение указанного идентификатора. Если значение, соответствующее идентификатору, уже равно int64, нет необходимости хэшировать или выполнять операции, преобразующие значение в int64.
Структура данных вершины:

Структура вершинного индекса:

В индексе строка — это то же самое, что ключ и уникальный идентификатор индекса.
Структура хранения Edge
Структура индекса edge аналогична структуре индекса вершины.
Обратите внимание, что для уникальности ключа индекса мы используем множество элементов данных, таких как VertexId, SrcVertexId и Rank, для их создания. Вот почему в индексе нет тега или идентификатора типа ребра.
Мы используем идентификатор вершины или ребра, чтобы указать конкретный идентификатор тега или типа ребра.
Структура данных Edge

Индексная структура Edge

Index Binary

Index binary — это основное поле индекса. В двоичном индексе есть два типа полей, то есть поля фиксированной длины и поля переменной длины. Типы int, double и bool — поля фиксированной длины, а тип string — поля переменной длины.
Например: предположим, что двоичный индекс index1 состоит из столбца int c1, столбца string c2 и другого столбца string c3:
index1 (c1:int, c2:string, c3:string)Предположим, что есть строка для index1, где значения c1, c2, c3 равны 23, «abc», «здесь» соответственно, тогда index1 хранится следующим образом:
- length = sizeof(“abc”) = 3
- length = sizeof(“here”) = 4

Мы упоминали в начале этого раздела, что двоичный индекс содержит поле длины переменной длины. Тогда для чего это? Вот пример:
Теперь предположим, что есть еще один двоичный индекс index2. Он состоит из строковых столбцов c1, c2 и c3.
index2 (c1:string, c2:string, c3:string)Предположим, теперь у нас есть два набора значений для c1, c2 и c3:
- row1 : (“ab”, “ab”, “ab”)
- row2: (“aba”, “ba”, “b”)
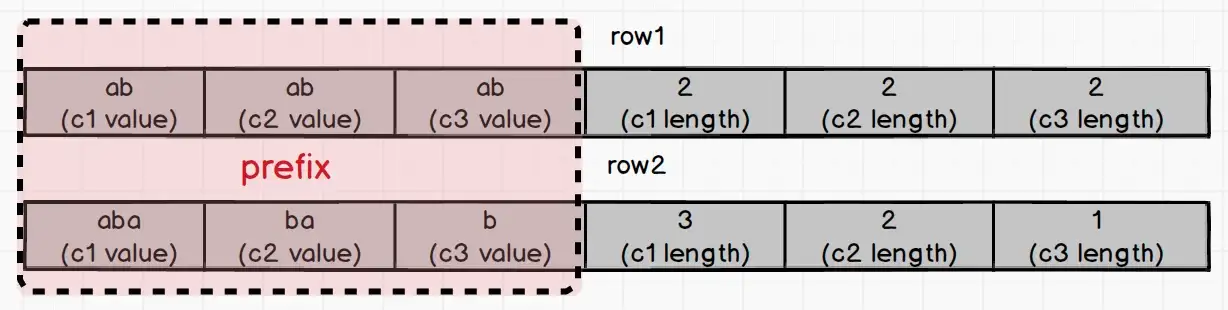
Мы видим, что префикс двух строк одинаков. Как отличить ключ двоичного индекса двух строк? Ответ: Variable-length field length.
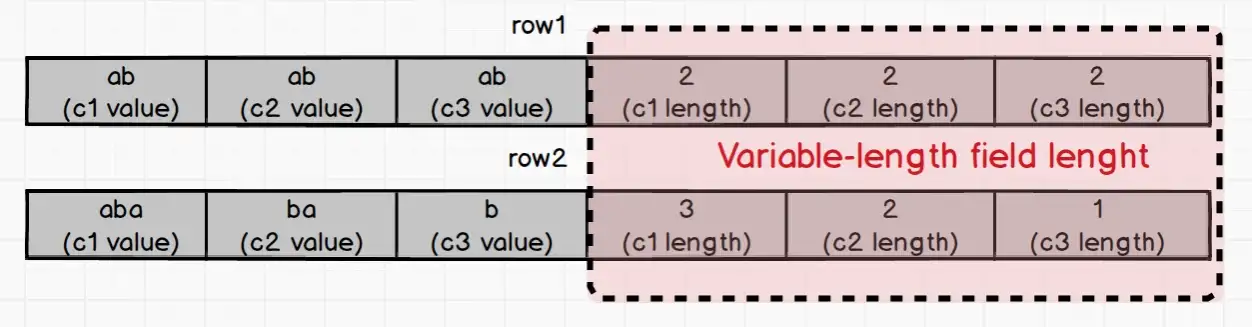
Если ваше условие запроса состоит в том, где c1 == «ab», длина c1 напрямую читается в длине поля переменной длины по порядкам. На основе длины извлекаются значения c1 в row1 и row2, которые равны «ab» и «aba» соответственно. Таким образом, мы можем точно определить, что только «ab» в строке 1 соответствует предложению where.
Операции с индексами
Запись индекса
После индексации одного или нескольких столбцов Tag/Edge, если задействована операция записи или обновления Tag/Edge, соответствующий индекс должен быть изменен вместе с новыми данными. Ниже кратко представлена логика обработки операции записи индекса на уровне хранилища:
Вставка
При вставке vertex/edge процессор вставки сначала определяет, содержат ли вставленные данные то же свойство индекса Tag/Edge. Если нет связанного индекса столбца свойств, создается новая версия, и данные помещаются в механизм хранения; если такой индекс столбца свойств уже существует, данные и индекс записываются атомарно.
Затем NebulaGraph оценивает, есть ли устаревшие значения свойств в текущей vertex/edge. Если это так, устаревшие значения удаляются в атомарной операции.
Удаление
При удалении vertex/edge deleteProcessor удаляет и данные, и индекс (если таковой существует), а также при удалении требуются атомарные операции.
Обновление
Обновление vertex/edge включает в себя как удаление старого индекса, так и вставку нового. Для обеспечения согласованности данных необходима атомарная операция. В то время как для обычных данных обновление — это просто операция вставки, и данные старой версии могут быть перезаписаны последней версией данных.
Index scan
Мы используем оператор LOOKUP для обработки сканирования индекса в NebulaGraph. Оператор LOOKUP использует значение свойства в качестве суждения для фильтрации всех вершин/ребер, соответствующих условиям. Оператор LOOKUP также поддерживает предложение WHERE и YIELD.
Советы по LOOKUP
Как показано в разделе «Структура хранения данных», столбцы индекса упорядочены в соответствии с последовательностью создания индекса.
Например, предположим, что есть тег (col1, col2) и создадим для него различные индексы:
- index1 on tag(col1)
- index2 on tag(col2)
- index3 on tag(col1, col2)
- index4 on tag(col2, col1)
Мы можем создать несколько индексов для col1 и col2, но при сканировании индекса возвращаемые результаты четырех вышеуказанных индексов могут быть совершенно разными. Именно оптимизатор индекса решает, какой индекс использовать, и генерирует оптимальную стратегию выполнения.
На основании приведенного выше индекса:
lookup on tag where tag.col1 == 1 # The optimal index is index1
lookup on tag where tag.col2 == 2 # The optimal index is index2
lookup on tag where tag.col1 > 1 and tag.col2 == 1
# Both index3 and index4 are valid while index1 and index2 invalidВ третьем примере выше оба index3 и index4 допустимы, но оптимизатор должен выбрать один из них. Согласно правилам оптимизации, поскольку tag.col2 == 1 является эквивалентным условием, следовательно, tag.col2 более эффективен, поэтому оптимизатор выбирает index4 в качестве оптимального индекса.
Индексация NebulaGraph на практике
Если у вас есть какие-либо вопросы относительно синтаксисов языка запросов, задайте их на нашем форуме.
Создать индекс
(user@127.0.0.1:6999) [(none)]> CREATE SPACE my_space(partition_num=3, replica_factor=1);
(user@127.0.0.1:6999) [(none)]> USE my_space;
-- create a graph vertex tag
(user@127.0.0.1:6999) [my_space]> CREATE TAG lookup_tag_1(col1 string, col2 string, col3 string);
-- create index for col1, col2, col3
(user@127.0.0.1:6999) [my_space]> CREATE TAG INDEX t_index_1 ON lookup_tag_1(col1, col2, col3);Индекс падения
-- drop index
(user@127.0.0.1:6999) [my_space]> drop TAG INDEX t_index_1;
Execution succeeded (Time spent: 4.147/5.192 ms)REBUILD index
Как и в большинстве баз данных, вы можете загружать большую часть записей (вершин и ребер) без какого-либо индекса и перестраивать индексы в автономном режиме после загрузки, чтобы повысить производительность пакетной загрузки. NebulaGraph использует следующую команду для повторного принудительного восстановления индексов хранилища. Как вы можете себе представить, эта перестройка представляет собой тяжелую операцию ввода-вывода, и мы рекомендуем вам не делать ее при онлайн-обслуживании (по крайней мере, нагрузка на вашу систему низкая).
REBUILD {TAG | EDGE} INDEX <index_name> [OFFLINE]Используйте индекс с LOOKUP
-- insert a graph vertex 200, it has three properties ("col1_200", "col2_200", "col3_200"
(user@127.0.0.1:6999) [my_space]> INSERT VERTEX lookup_tag_1(col1, col2, col3) VALUES 200:("col1_200", "col2_200", "col3_200"), 201:("col1_201", "col2_201", "col3_201"), 202:("col1_202", "col2_202", "col3_202");
-- search the vertex by the property
(user@127.0.0.1:6999) [my_space]> LOOKUP ON lookup_tag_1 WHERE lookup_tag_1.col1 == "col1_200";
============
| VertexID |
============
| 200 |
------------
-- find the vertex with its properties.
(user@127.0.0.1:6999) [my_space]> LOOKUP ON lookup_tag_1 WHERE lookup_tag_1.col1 == "col1_200" \
YIELD lookup_tag_1.col1, lookup_tag_1.col2, lookup_tag_1.col3;
========================================================================
| VertexID | lookup_tag_1.col1 | lookup_tag_1.col2 | lookup_tag_1.col3 |
========================================================================
| 200 | col1_200 | col2_200 | col3_200 |
------------------------------------------------------------------------