Как рассчитать доверительный интервал как в R, так и в Python

В статистике частот доверительный интервал (CI) - это диапазон оценок для неизвестного параметра. CI вычисляется как заданный уровень достоверности, при чем наиболее распространенным является уровень достоверности 95%. Факторы, влияющие на ширину CI, включают уровень достоверности, размер выборки и вариабельность выборки. При неизменности всех остальных факторов большая выборка привела бы к более узкому CI, большая вариабельность в выборке приводит к более широкому CI, а более высокий уровень достоверности потребовал бы более широкого CI.
Ниже приведем формулу доверительного интервала:

где, CI - доверительный интервал,
x - выборочное среднее значение,
z - значение уровня достоверности,
s - стандартное отклонение выборки,
n - размер выборки.
Намерения данного поста рассчитать доверительный интервал как в R, так и в Python. Был написан код R в Replit, бесплатном онлайн-интерпретаторе/компиляторе. Код Python был переведен с помощью Google Colab, который представляет собой бесплатный онлайн-блокнот Jupyter, размещенный Google.
Постановка задачи для этого вопроса такова:
Уровень насильственных преступлений за 2000 год по 50 штатам США (+округ Колумбия) приведен в файле данных по преступлениям.
Каков 95%-ный центральный доверительный интервал для среднего уровня насильственных преступлений?
На этот вопрос был дан ответ с использованием функции qnorm от R, где указаны верхний и нижний диапазоны доверительного интервала. Это приводит к нижнему и верхнему диапазонам CI, составляющим 375,2841 и 507,8159 соответственно:

Библиотека scipy.stats на самом деле имеет функцию для вычисления доверительного интервала, который можно увидеть ниже:-
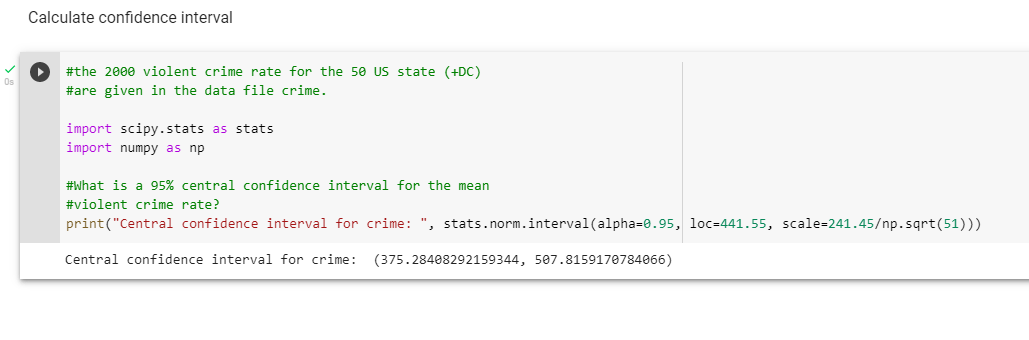
Подводя итог, поскольку в библиотеке scipy в Python есть функция, которая конкретно работает с доверительными интервалами, я чувствую, что в данном случае с языком легче работать.
Сильно удивляет, что R не создал такую функцию в своем языке программирования.