Как создать ELT с помощью Python

ELT (Извлечение, загрузка, преобразование) - это современный подход к интеграции данных, который немного отличается от ETL (Извлечение, преобразование, данные). ETL преобразует данные перед их загрузкой в хранилище данных, тогда как в ELT необработанные данные загружаются непосредственно в хранилище данных и преобразуются с помощью SQL.
Создание ELT является очень важной частью работы инженеров по данным и аналитике, а также может быть полезным навыком для аналитиков данных и ученых с более широким охватом или соискателей, создающих полное портфолио.
В этой статье мы построим короткий конвейер ELT на Python, используя данные из dummyJSON. dummyJSON - это поддельный REST API. Он предоставляет 9 типов ресурсов:

Мы попытаемся выяснить, какие клиенты потратили больше всего денег на наш фиктивный магазин.
Этот сценарий будет включать в себя 3 шага:
- Извлечение данных из dummyJSON API
- Загрузка необработанных данных в BigQuery
- Выполнение запроса для выполнения анализа
Давайте начнем строить наш трубопровод!
Извлечение данных
Нам нужно будет извлечь из API 2 ресурса: тележки и пользователей.
Давайте создадим функцию, которая выполняет вызов API и возвращает данные в формате JSON:
import requests
ENDPOINT = "https://dummyjson.com/"
def make_api_call(resource):
ENDPOINT = "https://dummyjson.com/"
response = requests.get(f"{ENDPOINT}{resource}") # making a request to the correct endpoint
if response.status_code == 200:
return response.json()
else:
raise Exception(response.text)
print(make_api_call("carts"))Мы используем библиотеку requests для создания простого HTTP-запроса GET. Мы проверяем, что это успешно, с помощью кода состояния и возвращаем данные JSON.
{
"carts": [
{
"id": 1,
"products": [
{
"id": 59,
"title": "Spring and summershoes",
"price": 20,
"quantity": 3,
"total": 60,
"discountPercentage": 8.71,
"discountedPrice": 55
},
{...}
// more products
],
"total": 2328,
"discountedTotal": 1941,
"userId": 97,
"totalProducts": 5,
"totalQuantity": 10
},
{...},
{...},
{...}
// 20 items
],
"total": 20,
"skip": 0,
"limit": 20
}У нас есть наши данные о заказах! Давайте попробуем это с клиентами:
{
"users": [
{
"id": 1,
"firstName": "Terry",
"lastName": "Medhurst",
"maidenName": "Smitham",
"age": 50,
"gender": "male",
"email": "atuny0@sohu.com",
"phone": "+63 791 675 8914",
"username": "atuny0",
"password": "9uQFF1Lh",
"birthDate": "2000-12-25",
"image": "https://robohash.org/hicveldicta.png?size=50x50&set=set1",
"bloodGroup": "A−",
"height": 189,
"weight": 75.4,
"eyeColor": "Green",
"hair": {
"color": "Black",
"type": "Strands"
},
"domain": "slashdot.org",
"ip": "117.29.86.254",
"address": {
"address": "1745 T Street Southeast",
"city": "Washington",
"coordinates": {
"lat": 38.867033,
"lng": -76.979235
},
"postalCode": "20020",
"state": "DC"
},
"macAddress": "13:69:BA:56:A3:74",
"university": "Capitol University",
"bank": {
"cardExpire": "06/22",
"cardNumber": "50380955204220685",
"cardType": "maestro",
"currency": "Peso",
"iban": "NO17 0695 2754 967"
},
"company": {
"address": {
"address": "629 Debbie Drive",
"city": "Nashville",
"coordinates": {
"lat": 36.208114,
"lng": -86.58621199999999
},
"postalCode": "37076",
"state": "TN"
},
"department": "Marketing",
"name": "Blanda-O'Keefe",
"title": "Help Desk Operator"
},
"ein": "20-9487066",
"ssn": "661-64-2976",
"userAgent": "Mozilla/5.0 ..."
},
{...},
{...}
// 30 items
],
"total": 100,
"skip": 0,
"limit": 30
}На этот раз кое-что привлекает наше внимание: всего 100 пользователей, но мы получили только 30.

Следовательно, нам нужно снова вызывать этот API до тех пор, пока у нас не будут все данные, пропуская те, которые у нас уже есть. Однако мы не заинтересованы в отправке этих ключей total, skip и limit в наше хранилище данных; давайте сохраним только пользователей и корзины.
Вот наша обновленная функция:
def make_api_call(resource):
ENDPOINT = "https://dummyjson.com/"
results_picked = 0
total_results = 100 #We don't know yet, but we need to initialize
all_data = []
while results_picked < total_results:
response = requests.get(f"{ENDPOINT}{resource}", params = {"skip" : results_picked})
if response.status_code == 200:
data = response.json()
rows = data.get(resource)
all_data += rows #concatening the two lists
total_results = data.get("total")
results_picked += len(rows) #to skip them in the next call
else:
raise Exception(response.text)
return all_data
users_data = make_api_call("users")
print(len(users_data))На этот раз у нас есть наши 100 пользователей!
Загрузка данных
Теперь пришло время загрузить наши данные в BigQuery. Мы собираемся использовать клиентскую библиотеку BigQuery для Python.

Просматривая документацию, мы видим, что в BigQuery можно загрузить локальный файл. Прямо сейчас наш JSON - это всего лишь dict. Давайте загрузим его в локальный файл.
Мы собираемся использовать нативную библиотеку json и записывать наши данные JSON в файл. Одна вещь, которую мы должны иметь в виду, это то, что BigQuery принимает JSONS в формате с разделителями новой строки, а не в формате с разделителями-запятыми.
import json
def download_json(data, resource_name):
file_path = f"{resource_name}.json"
with open(file_path, "w") as file:
file.write("\n".join([json.dumps(row) for row in data]))
download_json(carts_data, "carts")
download_json(users_data, "users")Теперь мы можем проверить, что наш файл carts.json находится в правильном формате JSON:
{"id": 1, "products": [{"id": 59, "title": "Spring and summershoes", "price": 20, "quantity": 3, "total": 60, "discountPercentage": 8.71, "discountedPrice": 55}, {"id": 88, "title": "TC Reusable Silicone Magic Washing Gloves", "price": 29, "quantity": 2, "total": 58, "discountPercentage": 3.19, "discountedPrice": 56}, {"id": 18, "title": "Oil Free Moisturizer 100ml", "price": 40, "quantity": 2, "total": 80, "discountPercentage": 13.1, "discountedPrice": 70}, {"id": 95, "title": "Wholesale cargo lashing Belt", "price": 930, "quantity": 1, "total": 930, "discountPercentage": 17.67, "discountedPrice": 766}, {"id": 39, "title": "Women Sweaters Wool", "price": 600, "quantity": 2, "total": 1200, "discountPercentage": 17.2, "discountedPrice": 994}], "total": 2328, "discountedTotal": 1941, "userId": 97, "totalProducts": 5, "totalQuantity": 10}
// other carts
{"id": 20, "products": [{"id": 66, "title": "Steel Analog Couple Watches", "price": 35, "quantity": 3, "total": 105, "discountPercentage": 3.23, "discountedPrice": 102}, {"id": 59, "title": "Spring and summershoes", "price": 20, "quantity": 1, "total": 20, "discountPercentage": 8.71, "discountedPrice": 18}, {"id": 29, "title": "Handcraft Chinese style", "price": 60, "quantity": 1, "total": 60, "discountPercentage": 15.34, "discountedPrice": 51}, {"id": 32, "title": "Sofa for Coffe Cafe", "price": 50, "quantity": 1, "total": 50, "discountPercentage": 15.59, "discountedPrice": 42}, {"id": 46, "title": "women's shoes", "price": 40, "quantity": 2, "total": 80, "discountPercentage": 16.96, "discountedPrice": 66}], "total": 315, "discountedTotal": 279, "userId": 75, "totalProducts": 5, "totalQuantity": 8}Давайте попробуем загрузить наши файлы прямо сейчас!
Во-первых, нам нужно загрузить клиентскую библиотеку для Python.
Как только это будет сделано, мы должны загрузить ключ учетной записи службы и создать переменную среды, чтобы сообщить BigQuery, где хранятся наши учетные данные. В терминале мы можем ввести следующую команду:
export GOOGLE_APPLICATION_CREDENTIALS=service-account.jsonЗатем мы можем написать нашу функцию на Python. К счастью, документация BigQuery предоставляет нам пример кода:
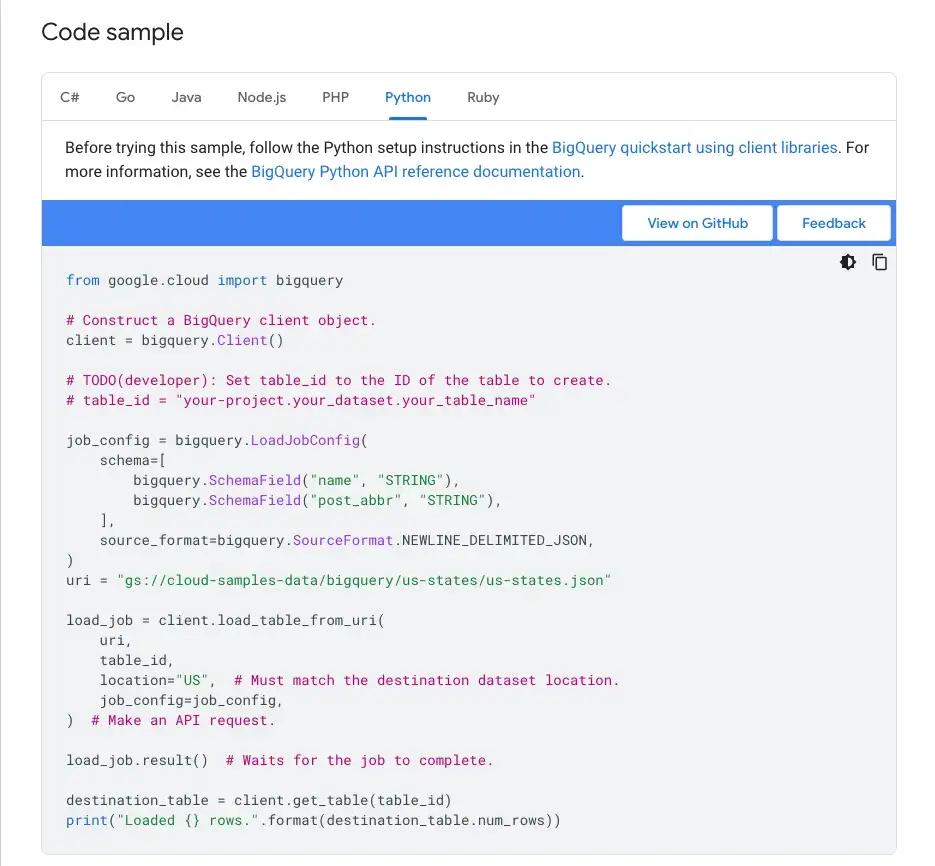
Мы можем определить новую функцию, используя этот пример:
def load_file(resource, client):
table_id = f"data-analysis-347920.medium.dummy_{resource}"
job_config = bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
autodetect=True,
write_disposition="write_truncate"
)
with open(f"{resource}.json", "rb") as source_file:
job = client.load_table_from_file(source_file, table_id, job_config=job_config)
job.result() # Waits for the job to complete.
table = client.get_table(table_id) # Make an API request.
print(
"Loaded {} rows and {} columns to {}".format(
table.num_rows, len(table.schema), table_id
)
)
client = bigquery.Client()
load_file("carts", client)
load_file("users", client)Loaded 20 rows and 7 columns to data-analysis-347920.medium.dummy_carts
Loaded 100 rows and 27 columns to data-analysis-347920.medium.dummy_usersМы сказали BigQuery каждый раз усекать нашу таблицу, поэтому, если мы повторно запустим скрипт, существующие строки будут перезаписаны.
Теперь у нас есть наши 2 таблицы внутри BigQuery:

Преобразование данных
Пришло время перейти к последней букве в ELT!
Мы хотим иметь таблицу с пользователями и суммой, которую они потратили на наш магазин.
Давайте объединим наши две таблицы, чтобы получить эту информацию:
SELECT
u.id AS user_id,
u.firstName AS user_first_name,
u.lastName AS user_last_name,
SUM(total) AS total_spent
FROM `data-analysis-347920.medium.dummy_users` u
LEFT JOIN `data-analysis-347920.medium.dummy_carts` c
ON u.id= c.userId
GROUP BY u.id,user_first_name,user_last_name
ORDER BY total_spent DESC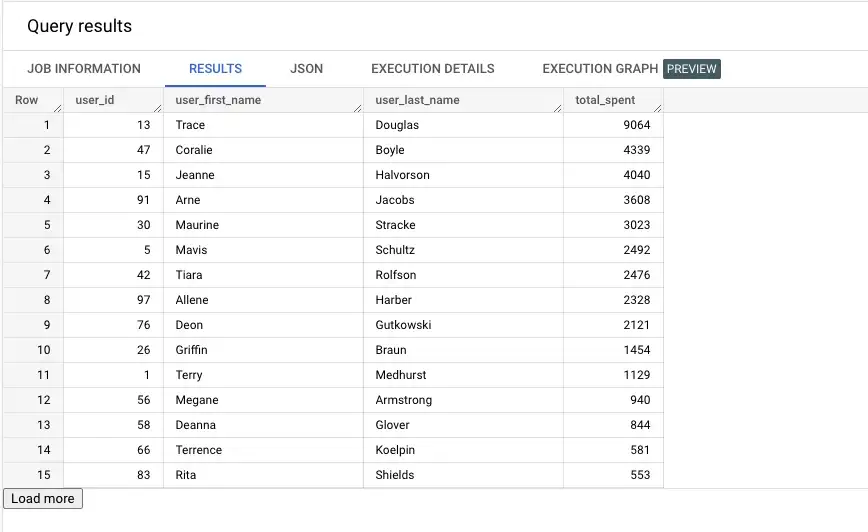
Похоже, Трейс Дуглас - наш главный транжира! Давайте добавим эту таблицу как часть нашего ELT.
query= """
SELECT
u.id AS user_id,
u.firstName AS user_first_name,
u.lastName AS user_last_name,
SUM(total) AS total_spent
FROM `data-analysis-347920.medium.dummy_users` u
LEFT JOIN `data-analysis-347920.medium.dummy_carts` c
ON u.id= c.userId
GROUP BY u.id,user_first_name,user_last_name
"""
query_config= bigquery.QueryJobConfig(
destination = "data-analysis-347920.medium.dummy_best_spenders",
write_disposition= "write_truncate"
)
client.query(query, job_config= query_config)Мы удалили ORDER BY, поскольку это требует больших вычислительных затрат; и все равно можем упорядочить наши результаты, как только запросим таблицу dummy_best_spenders.
Давайте проверим, что наша таблица была создана:
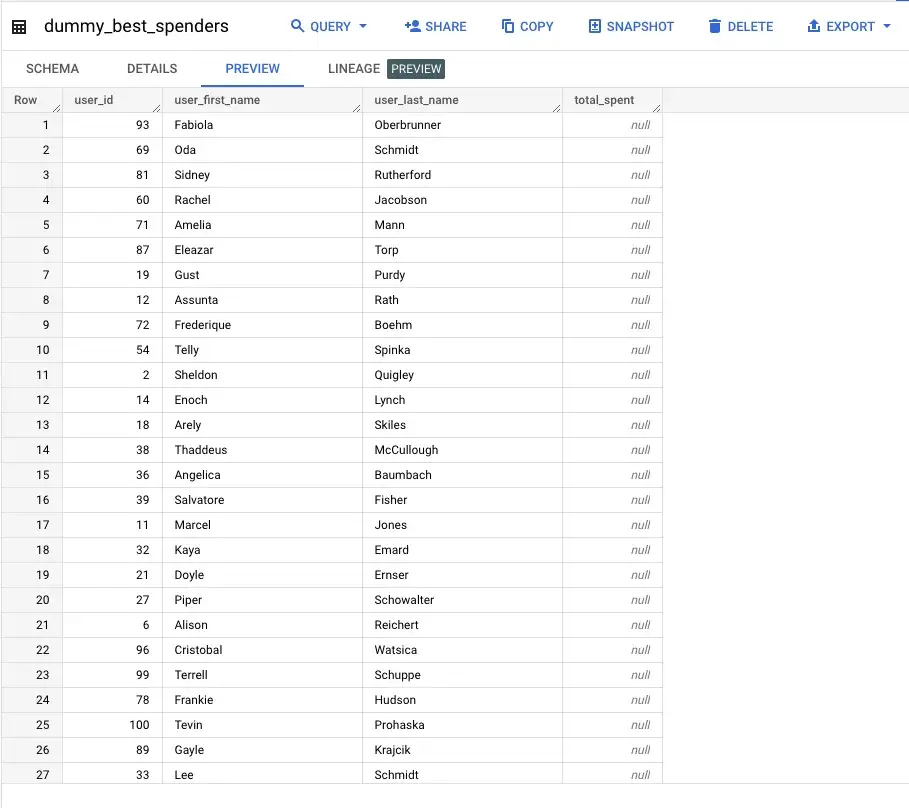
Вот и все, мы создали наш первый ELT всего за несколько строк кода!
Идем дальше с ELT
Когда имеешь дело с реальными и более крупными проектами, есть еще несколько вещей, которые следует учитывать:
- Мы будем иметь дело с большими объемами данных. Каждый день будут появляться новые данные, поэтому нам придется постепенно добавлять данные в наши таблицы вместо того, чтобы обрабатывать все данные каждый день.
- По мере того как наши ELT становятся все более сложными, с несколькими источниками данных, нам может потребоваться использовать инструмент оркестровки рабочего процесса, такой как Airflow или Prefect.
- Мы можем загружать только файлы весом менее 10 МБ непосредственно в BigQuery. Чтобы загрузить большие файлы, нам нужно сначала загрузить их в облачное хранилище.