Легко сгенерируйте Mock данные с помощью PostgreSQL

При написании статей о PostgreSQL мне иногда приходится генерировать большие объемы данных для тестирования и демонстрации темы. Вставлять данные вручную или создавать CSV-файл и импортировать его в PostgreSQL — для этого мне всегда приходится использовать StackOverflow — может быть затруднительно. Недавно я столкнулся с гораздо более простым решением для генерации данных: generate_series функцией. Она идеально подходит для целых чисел и типов данных временных меток, оптимизируя различные задачи, такие как заполнение тестовых баз данных или настройка диапазонов дат для отчетов.
Генерация фиктивных данных
generate_series можно рассматривать как цикл for или генератор для создания диапазона чисел или дат.
Чтобы сгенерировать диапазон чисел, мы вызываем generate_series начальное и конечное значение:
SELECT * FROM generate_series(1, 10);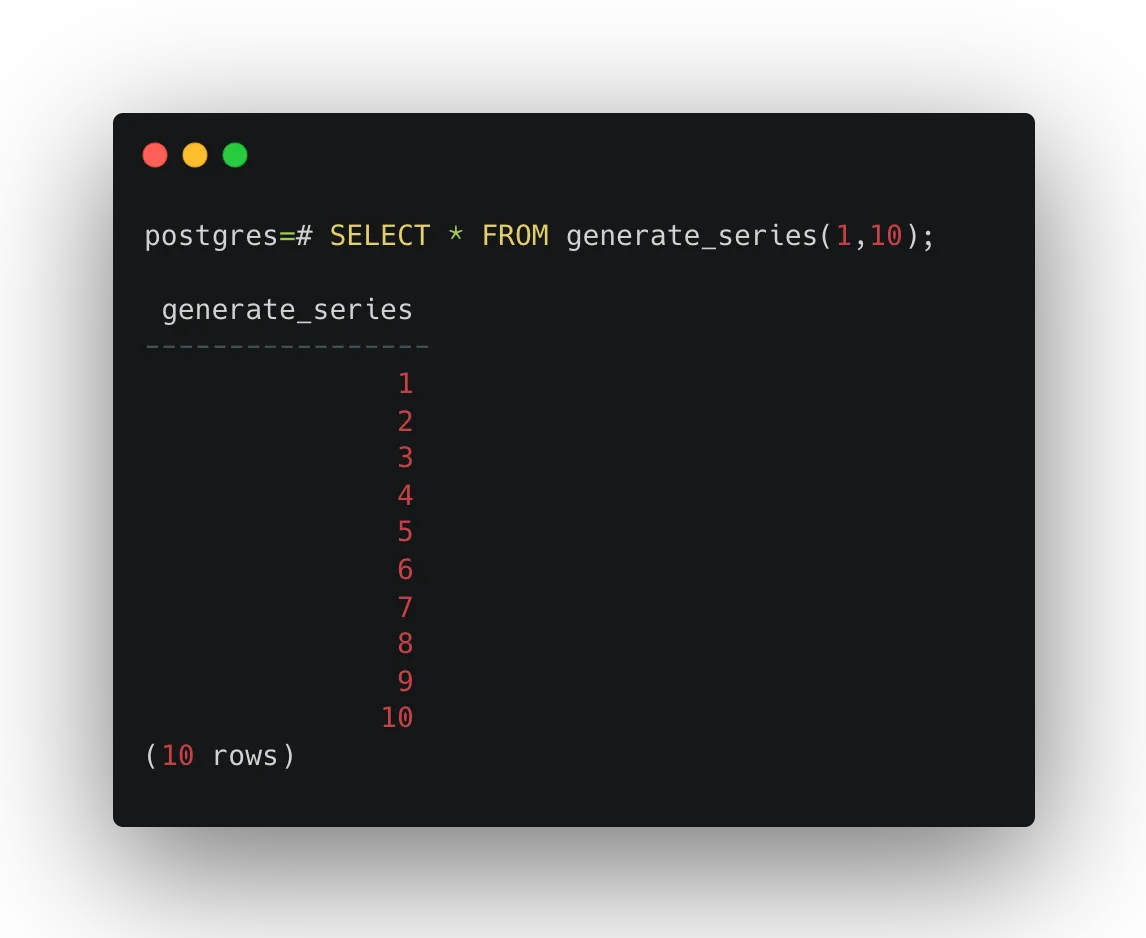
Мы можем указать значение шага, указав generate_series в качестве необязательного третьего аргумента.
SELECT * FROM generate_series(1, 10, 2.5);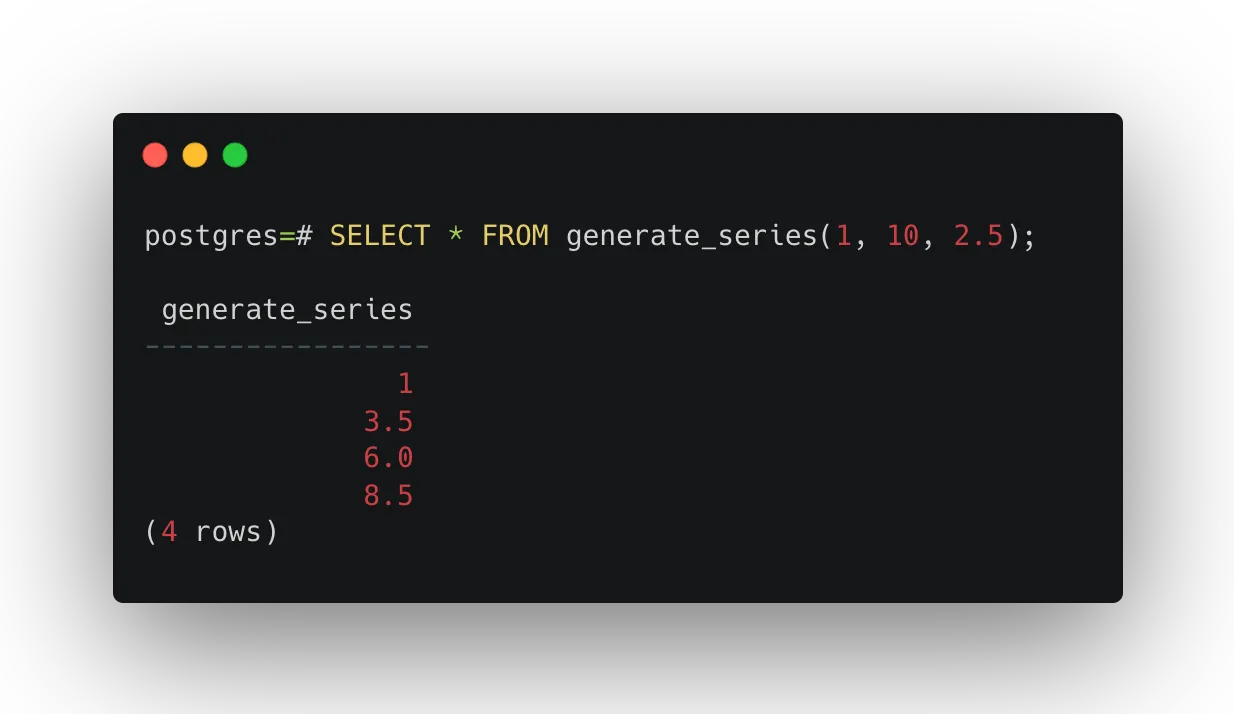
Вставка фиктивных данных
generate_series сила проявляется, когда нам нужно вставить Mock Data в таблицу. Мы можем легко вставить диапазон чисел в таблицу, используя оператор generate_series в SELECT, а затем вставив результаты в таблицу.
В оставшейся части статьи мы будем использовать для наших примеров таблицу users, которая выглядит следующим образом:
CREATE TABLE users (
id serial PRIMARY KEY,
name text NOT NULL,
created_on timestamptz
);Затем, если бы мы хотели вставить в таблицу пять пользователей, мы могли бы запустить:
INSERT INTO users (name)
SELECT
'Dylan'
FROM generate_series(1, 5);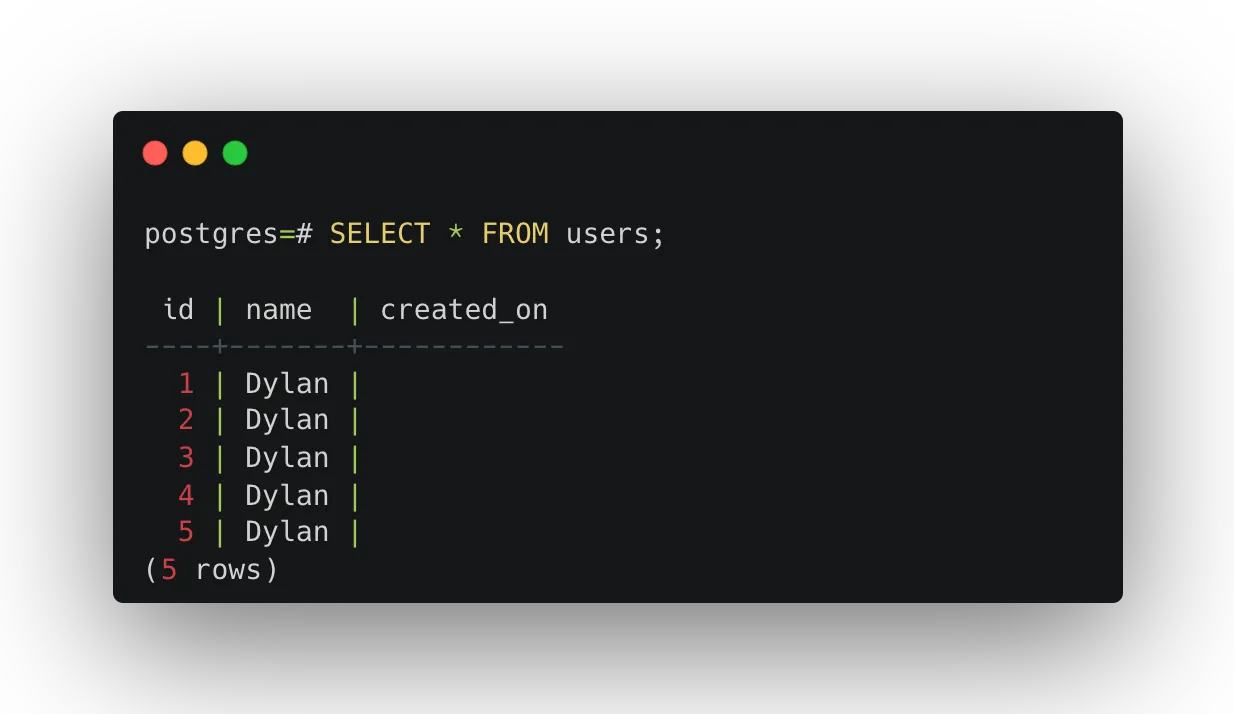
Этот шаблон можно использовать для вставки любого количества строк в таблицу. Если у вас есть смелость, попробуйте добавить в таблицу 1 000 000 пользователей, изменив generate_series(1, 5) на generate_series(1, 1000000)!
До этого момента мы создавали много дублирующихся данных. Что, если мы захотим создать группу пользователей со всеми разными именами? Мы можем получить доступ к текущему индексу цикла (используя as), чтобы сгенерировать уникальное имя для каждого пользователя.
Это будет выглядеть так:
INSERT INTO users (name)
SELECT
'Dylan number ' || i
FROM generate_series(1, 5) as i;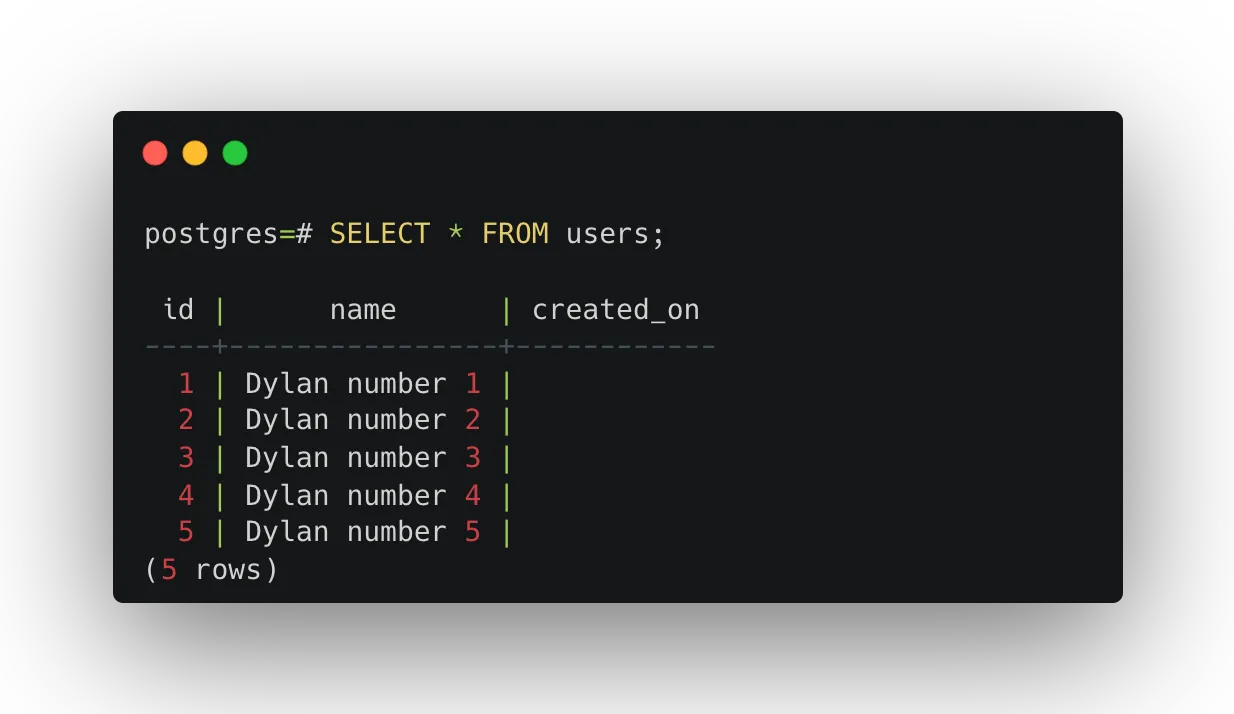
Создание данных Time-Series
generate_series невероятно эффективен при создании данных временных рядов. Именно здесь я получаю от этого максимальную пользу, потому что создание большого количества данных во временных диапазонах может оказаться чрезвычайно утомительным.
Как и в примере с целым числом, сгенерируйте диапазон временных меток, указав начальное и конечное значения, за которыми следует необязательный шаг или интервал.
Например, чтобы генерировать пользователя на каждый час в неделю, мы могли бы запустить следующий SQL:
INSERT INTO users (name, created_on)
SELECT
'Dylan',
time_hour
FROM generate_series(
TIMESTAMPTZ '2023-11-01',
TIMESTAMPTZ '2023-11-07',
INTERVAL '1 hour'
) as time_hour;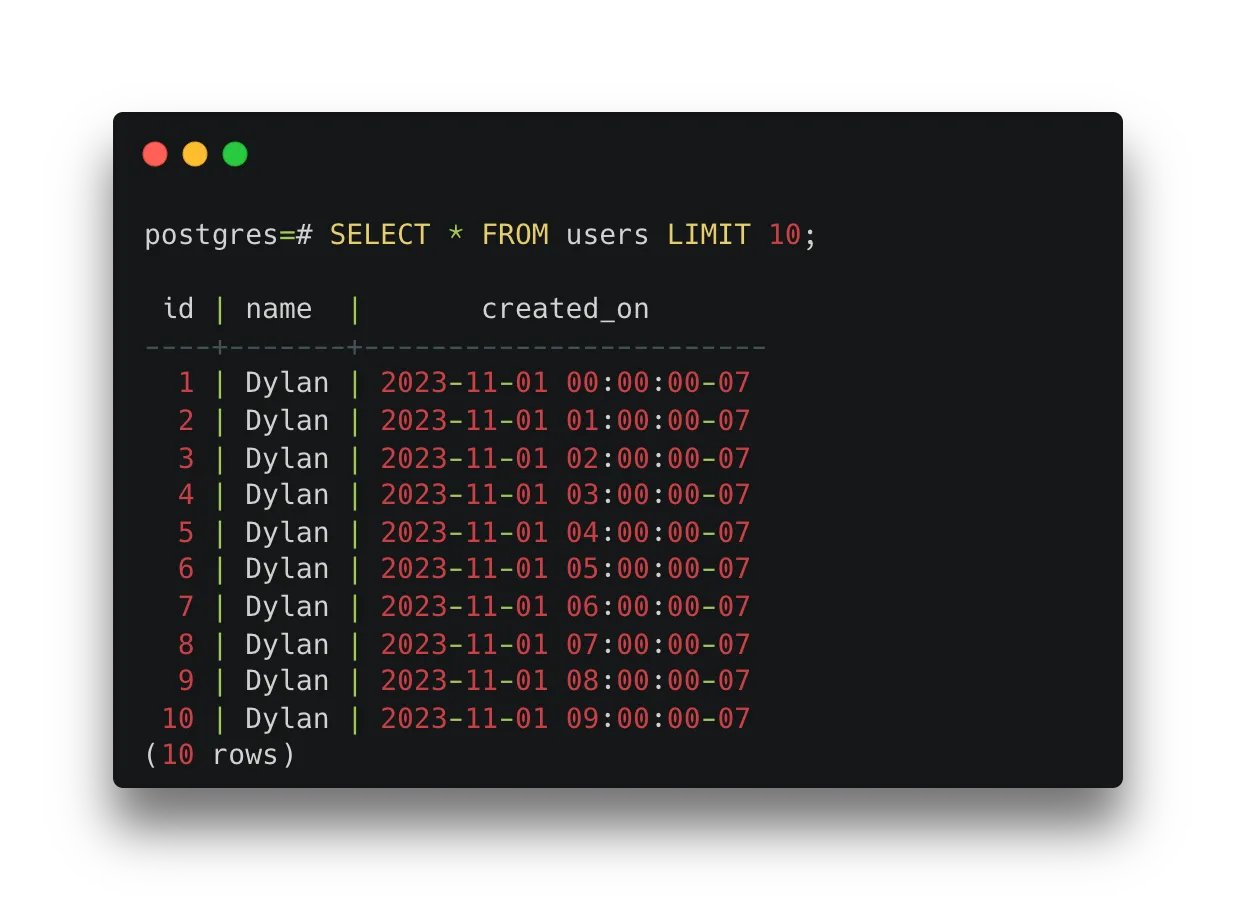
Этот запрос создает 146 строк с пользователем по имени Дилан каждый час в период с 1 по 7 ноября 2023 года.
Вы можете спросить себя, можем ли мы использовать Multiple generate_series для заполнения нескольких полей? Да! Но нам нужно использовать соединения, чтобы объединить данные из двух серий. Чтобы быстро создать сетку пользователей и дат create_on, мы можем взять декартово произведение двух рядов, также известное как перекрестное соединение, добавив еще один generate_series в FROMпредложение.
INSERT INTO users (name, created_on)
SELECT
'Dylan number' || i,
time_hour
FROM
generate_series(1, 5) as i,
generate_series(
TIMESTAMPTZ '2023-11-01',
TIMESTAMPTZ '2023-11-07',
INTERVAL '2 days'
) as time_hour;В INSERT приведенном выше утверждении мы создадим четыре time_hour временные метки для каждых двух дней недели для каждой итерации i(их пять). В результате 4 * 5 = 20 создано двадцать строк. Чтобы лучше понять, что здесь происходит, будет проще взглянуть на SELECT выходные данные таблицы пользователей.
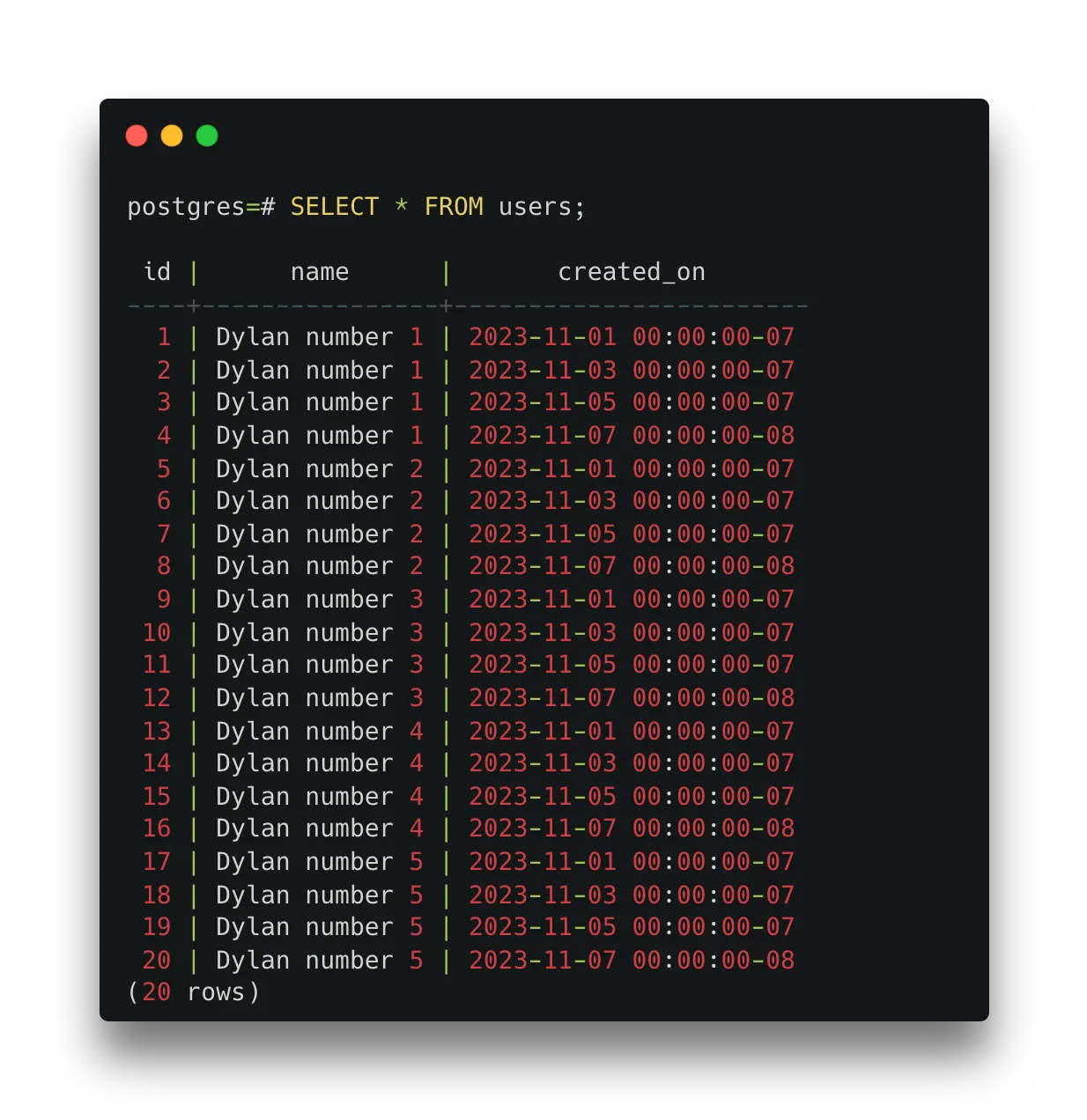
Использование нескольких generate_series функций в сочетании с декартовым произведением может стать мощной комбинацией для создания уникальных данных временных рядов.
Заключение
PostgreSQL generate_series меняет правила игры для таких разработчиков, которые часто погружаются в глубокие этапы генерации данных для тестирования и оптимизации запросов. Это мощный инструмент, который может без особых усилий создать что угодно, от нескольких до миллионов строк, превращая потенциально трудную задачу в несколько простых строк SQL. Итак, когда вам нужно смоделировать данные, пусть это generate_series будет вашим идеальным решением.