Интерпретация: list, dictionary и set comprehension

Python поддерживает специальные выражения, которые позволяют компактно создавать списки, словари и множества. Эти выражения соответственно называются:
- List comprehensions
- Dictionary comprehensions
- Set comprehensions
К сожалению, официальный перевод на русский звучит как абстракция списков или списковое включение, что не особо помогает понять суть объекта. Эти выражения не только позволяют более компактно создавать соответствующие объекты, но и создают их быстрее. И хотя поначалу они требуют определенной привычки использования и понимания, они очень часто используются.
List comprehension
Типы данных списка Python являются одним из фундаментальных элементов структуры данных. С помощью функции list comprehension (генератор списков) мы можем сгенерировать серию списков из списка.
Например, простейшей формой понимания списка является выполнение поверхностной копии списка следующим образом:
a_list = [1, 2, 3, 4, 5]
b_list = a_list[:] Что мы здесь видим, что Python просто выполняет копии всех элементов по значению или член за членом. Таким образом, изменение в новом списке не изменит исходный список. Например:
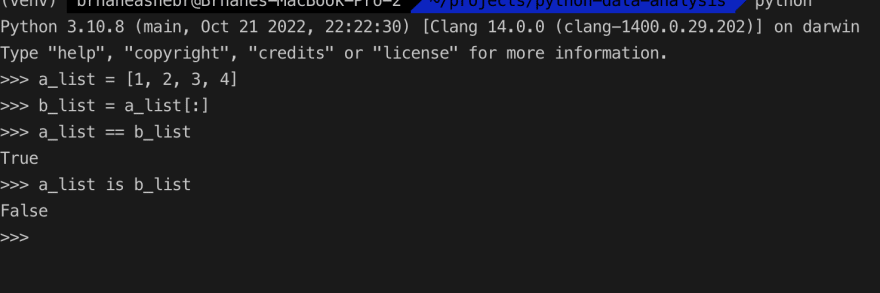
В приведенной выше оболочке Python мы видим, что две переменные содержат равные значения, но ссылаются на разные объекты.
Кстати, оператор is в Python сравнивает две переменные и возвращает значение True, если они ссылаются на один и тот же объект. Если две переменные ссылаются на разные объекты, оператор is возвращает значение False, как в приведенном выше примере. Другими словами, оператор is сравнивает идентичность двух переменных и возвращает значение True, если они ссылаются на один и тот же объект.
Вот еще один способ добиться того же результата с помощью цикла for:
b_list = []
for i in a_list:
b_list.append(i)Общий синтаксис для list comprehension выглядит следующим образом:
new_list = [value for_statement if_expression]value aka expression: принимает значение непосредственно из списка,
for_statement: один или несколько for statements с условиями для участника,
if clauses: для оценки некоторых условий.
Давайте посмотрим на следующий пример:
>>>[(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]Приведенный фрагмент кода содержит два цикла for для проверки условий двух значений в разных списках, которые, в свою очередь, создают кортеж списков на основе предложений if.
Set comprehension
Set - это неупорядоченная коллекция без повторяющихся элементов. Будет использоваться та же концепция, что и list comprehension, за исключением того, что синтаксис для set равен {}. Например, давайте создадим набор из заданного списка со следующим set comprehension (генератор множеств).
>>> a_list = [1, 2, -2, 1, -1, 2, 3]
>>> new_set = {i for i in a_list if i > 0}
>>> new_set
>>> {1, 2, 3}Возможно, вы уже заметили, что повторяющихся значений нет, потому что удаление дубликатов происходит автоматически, когда мы создаем набор с помощью {}.
Dictionary comprehension
Мы собираемся использовать аналогичный подход, но с небольшой сложностью. В dictionary comprehension (генератор словарей) необходимо создать цикл, который генерирует пары ключ-значение, используя синтаксис: key:value.
Предположим, у нас есть список кортежей, которые мы хотели бы использовать в качестве основы для нашего недавно сгенерированного словаря.
>>> list_tuples = [('Netherlands', 'Amsterdam'), ('Germany', 'Berlin')]
>>> new_dict = { i[0] : i[1] for i in list_tuples }Обратите внимание на использование двоеточия (:) в выражении ключ-значение. Затем, если мы хотим проверить, давайте оценим следующее:
>>> new_dict['Netherlands']
'Amsterdam'
>>>Давайте посмотрим еще один пример того, как создать словарь из двух заданных списков.
>>> countries = ['China', 'India', 'U.S.A', 'Indonesia']
>>> population = [1_452_661_848, 1_413_052_163, 335_683_841, 280_581_836]
>>> four_largest_countries_by_population = { countries[i]: population[i] for i in range(len(keys)) }
>>> four_largest_countries_by_population
{'China': 1452661848, 'India': 1413052163, 'U.S.A': 335683841, 'Indonesia': 280581836}
>>>В приведенном выше примере мы предполагаем, что оба списка имеют одинаковую длину.
Мы даже можем повысить производительность кода в приведенном выше примере, используя встроенную функцию zip для объединения списков. Если переданные итераторы имеют разную длину, итератор с наименьшим количеством элементов определяет длину нового итератора.