Модель машинного обучения с FLASK REST API

В этом уроке мы увидим, как вы можете создать свой первый REST API для модели машинного обучения с использованием FLASK. Начнем с создания модели машинного обучения. Затем мы увидим пошаговую процедуру создания API с помощью Flask и протестируем его с помощью Postman.
Часть 1: Создание модели машинного обучения
Первое, что нам нужно, это импортировать необходимые библиотеки. После импорта необходимых библиотек нам нужно будет импортировать данные. В этом проекте мы будем использовать набор данных Boston Housing, который можно загрузить с sklearn.datasets
# importing necessary libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import metrics
# importing dataset from sklearn
from sklearn.datasets import load_boston
boston_data = load_boston()
# initializing dataset
data_ = pd.DataFrame(boston_data.data)
### Top five rows of dataset
data_.head()
В настоящее время наш набор данных не имеет никакого имени. Поэтому нам нужно будет импортировать имя объекта для набора данных.
# Adding features names to the dataframe
data_.columns = boston_data.feature_names
data_.head()
Предварительная обработка данных
Переменная, которую мы хотим предсказать, это цена.Теперь мы создадим целевую переменную для нашей модели машинного обучения.
# Target feature of Boston Housing data
data_['PRICE'] = boston_data.target
Теперь мы проверим, являются ли какие-либо из наших функций нулевыми и категоричными или нет. Это связано с тем, что нулевые значения привели бы к тому, что модели машинного обучения с смещением требуют числовых значений, а не категориальных.
# checking null values
data_.isnull().sum()
Нулевые значения не найдены, поэтому объекты остаются без изменений. Теперь давайте проверим, есть ли какие-либо категориальные значения.
# checking if values are categorical or not
data_.info()
Мы видим, что все функции являются числовыми.Так что теперь мы создадим нашу модель.
Создание модели
Сначала нам нужно разделить функцию и целевую переменную. Затем разделите набор данных на набор для обучения и тестирования. И, наконец, создать модель.
# creating feature and target variable
X = data_.drop(['PRICE'], axis=1)
y = data_['PRICE']
# splitting into training and testing set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2, random_state=1)
print("X training shape : ", X_train.shape )
print("X test shape : ", X_test.shape )
print("y training shape :“ , y_train.shape )
print("y test shape :”, y_test.shape )
# creating model
from sklearn.ensemble import RandomForestRegressor
classifier = RandomForestRegressor()
classifier.fit(X_train, y_train)
Теперь давайте оценим производительность модели для обучения и тестирования.
# Model evaluation for training data
prediction = classifier.predict(X_train)
print("r^2 : ", metrics.r2_score(y_train, prediction))
print("Mean Absolute Error: ", metrics.mean_absolute_error(y_train, prediction))
print("Mean Squared Error: ", metrics.mean_squared_error(y_train, prediction))
print("Root Mean Squared Error : ", np.sqrt(metrics.mean_squared_error(y_train, prediction)))
# Model evaluation for testing data
prediction_test = classifier.predict(X_test)
print("r^2 : ", metrics.r2_score(y_test, prediction_test))
print("Mean Absolute Error : ", metrics.mean_absolute_error(y_test, prediction_test))
print("Mean Squared Error : ", metrics.mean_squared_error(y_test, prediction_test))
print("Root Mean Absolute Error : ", np.sqrt(metrics.mean_squared_error(y_test, prediction_test)))
Часть 2. Сохранение и использование модели машинного обучения.
Мы будем использовать pickle для сохранения модели. Механизм сериализации и десериализации помогает сохранить объектную модель машинного обучения в байтовом потоке и наоборот. Модель будет сохранена в папке model. Рабочая структура проекта показана в части 3.
# saving the model
import pickle
with open('model/model.pkl','wb') as file:
pickle.dump(classifier, file)
# saving the columns
model_columns = list(X.columns)
with open('model/model_columns.pkl','wb') as file:
pickle.dump(model_columns, file)
Часть 3: Создание API для машинного обучения с использованием Flask
После успешного создания модели машинного обучения. Нам нужно будет создать веб-сервер во Flask. Flask - это легкое веб-приложение, которое легко использовать и масштабировать до сложных приложений. В этом руководстве рассматривается базовая реализация приложения Flask, т.е. создание веб-сервера и простого REST API. Вот как организован весь проект:
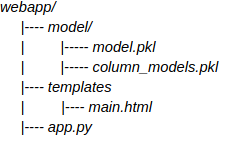
Чтобы использовать Flask, сначала создайте имя папки webapp и установите внутри нее Flask, используя следующую команду в терминале. Убедитесь, что Flask находится в папке веб-приложения.
pip install Flask
Минимальное веб-приложение может быть создано с помощью Flask. Следующий код создаст простое веб-приложение, которое перенаправляет на указанный URL для получения заданных результатов.
from flask import Flask
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def main():
return "Boston House Price Prediction”
if __name__ == "__main__":
app.run()
Запуск приложения
Чтобы запустить Flask-сервер на локальном компьютере, перейдите в папку webapp и выполните команду в терминале.
export FLASK_APP=app.py
export FLASK_ENV=development
flask run
Это выполнит приложение. Теперь перейдите в веб-браузер (localhost:5000), чтобы увидеть результат. Окончательный результат показан ниже:
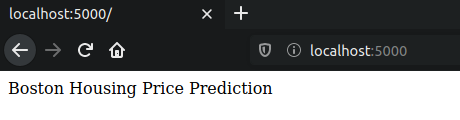
Давайте соединим весь код, чтобы проверить, пропустили мы что-нибудь или нет. Итак, полный app.py файл должен выглядеть так:
from flask import render_template, request, jsonify
import flask
import numpy as np
import traceback
import pickle
import pandas as pd
# App definition
app = Flask(__name__,template_folder='templates')
# importing models
with open('webapp/model/model.pkl', 'rb') as f:
classifier = pickle.load (f)
with open('webapp/model/model_columns.pkl', 'rb') as f:
model_columns = pickle.load (f)
@app.route('/')
def welcome():
return "Boston Housing Price Prediction"
@app.route('/predict', methods=['POST','GET'])
def predict():
if flask.request.method == 'GET':
return "Prediction page"
if flask.request.method == 'POST':
try:
json_ = request.json
print(json_)
query_ = pd.get_dummies(pd.DataFrame(json_))
query = query_.reindex(columns = model_columns, fill_value= 0)
prediction = list(classifier.predict(query))
return jsonify({
"prediction":str(prediction)
})
except:
return jsonify({
"trace": traceback.format_exc()
})
if __name__ == "__main__":
app.run()
Часть 4: Тестирование API в Postman
Для тестирования нашего API нам потребуется клиент API, и мы будем использовать Postman. Как только вы загрузите Postman, он должен выглядеть следующим образом.
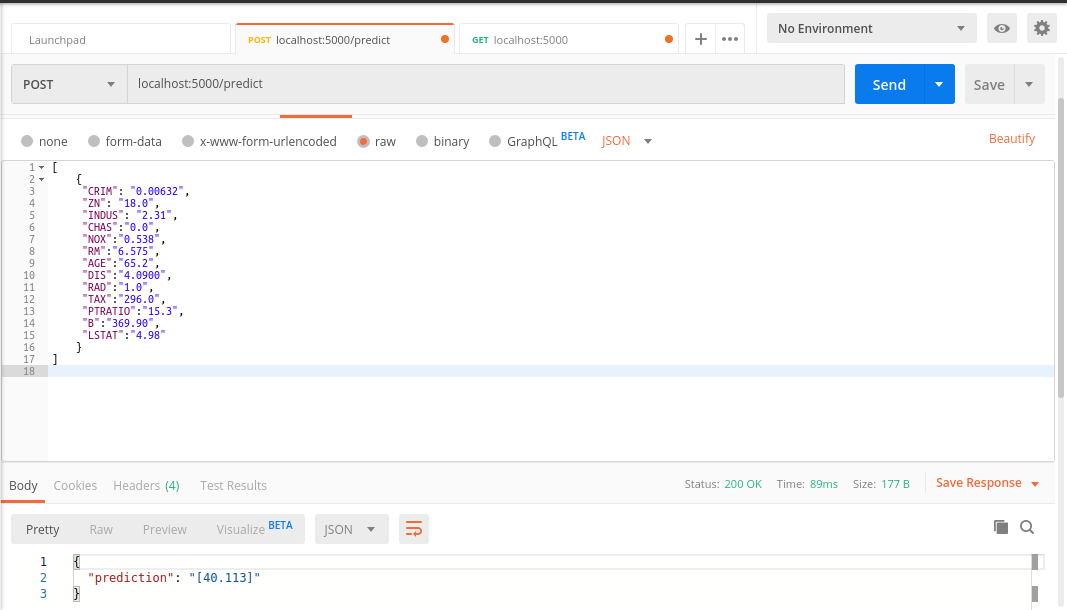
Теперь мы будем вводить наш URL (localhost:5000/predict) и вводить необходимые функции нашей модели. Формат JSON внутри тела. И измените тип запроса на POST. Наш конечный результат должен выглядеть следующим образом.
Резюме
К этому моменту вы разработали модуль машинного обучения и использовали Flask для создания API, который можно использовать для прогнозирования цен на дома в Бостоне.