Надежная проверка 2 DataFrames с помощью Pandas 1.1.0

Pandas - одна из наиболее часто используемых библиотек Python как для специалистов по данным, так и для инженеров. Сегодня я хочу поделиться некоторыми советами по Python, которые помогут нам проводить проверки квалификации между двумя фреймами данных.
Заметьте, я использовал слово « квалификация» вместо «идентичный». Идентичность проверить легко, а вот квалификация - неточная проверка. Он основан на бизнес-логике. Поэтому реализовать сложнее.
Не изобретать велосипед
В версии 1.1.0, выпущенной 28 июля 2020 года, за 8 дней до этого, Pandas представила встроенную функцию сравнения. Все наши последующие шаги построены на его основе.
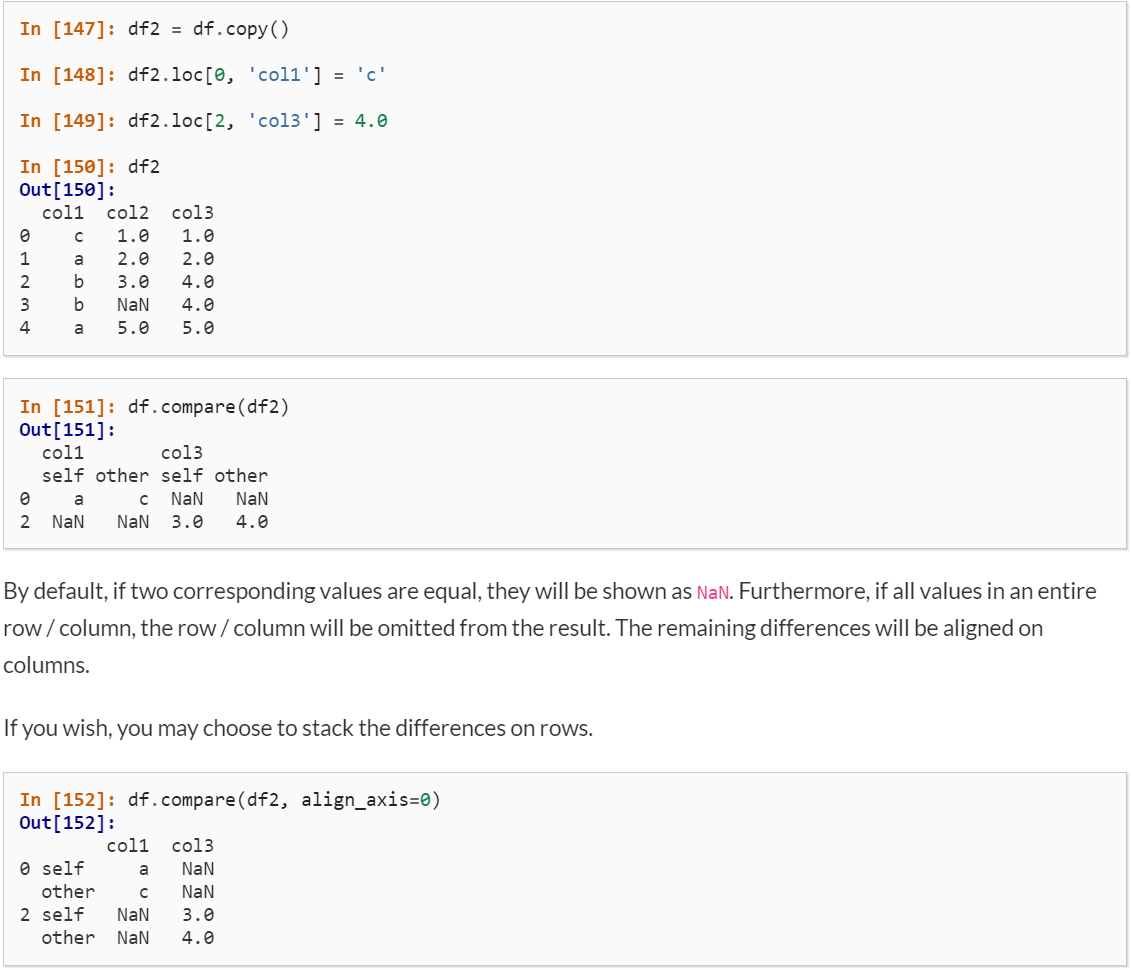
Советы: если вы использовали дистрибутив Anacondas, вы должны использовать следующую команду для обновления вашей версии Pandas.
pip install pandas==1.1
Низко висящий фрукт
Всегда сначала проверяйте количество столбцов между двумя кадрами. В некоторых случаях эта простая проверка может выявить проблемы.
В определенных сценариях, таких как изменение обогащения, у нас может быть другое количество столбцов. Определение квалификации может быть таким: для всех бывших столбцов, имеющих одинаковое значение между двумя кадрами данных. Поэтому мы определим столбцы для проверки и сохраним их в переменных Columns для дальнейшего использования.
import pandas as pd
@staticmethod
def CheckTwoDataFrames(target, test, keys, columnMisAlignedAcceptable = False, writeDiff = False, writeToFile='./diff.tsv'):
# Check on columns first. If # columns is different, print the delta.
# If columns misalign is acceptable, (in certain scenarios it could be desired behavior),
# further proceed and adjust the DataFrame accordingly.
Columns = []
numColumnsTarget = len(target.columns)
numColumnsTest = len(test.columns)
if (not numColumnsTarget == numColumnsTest ):
print('# of columns are different target is {0} and test is {1}'.format(numColumnsTarget, numColumnsTest))
targetColumnSet = set(target.columns)
testColumnSet = set(test.columns)
diffColumnSet = (targetColumnSet - testColumnSet) if numColumnsTarget > numColumnsTest else (testColumnSet - targetColumnSet)
print(diffColumnSet)
if (not columnMisAlignedAcceptable):
print('Columns MisAligned Stop further comparison')
else:
if numColumnsTarget < numColumnsTest:
Columns = target.columns
test = test[Columns]
target = target[Columns]
else:
Columns = test.columns
target = target[columns]
test = test[Columns]
Ключи для разблокировки
В реальном приложении у нас будут различные идентификаторы для идентификации записи, такие как user_id, order_id и т.д. Чтобы сделать уникальный запрос, нам может потребоваться комбинация этих ключей. В конечном итоге мы хотим проверить, что записи с одинаковыми ключами имеют одинаковые значения столбцов.
Первый шаг - составить комбинацию клавиш. Вот где сияет применение DataFrame. Мы могли бы использовать df.apply(lambda: x: func (x), axis = 1) для любого преобразования данных. С axis = 1 мы говорим Pandas выполнять одну и ту же операцию построчно . (ось = 0, столбец за столбцом)
import pandas as pd
class DataFrameComparison:
@staticmethod
def CreateKeyColumn(row, keys):
res = [str(row[key]) for key in keys]
return '_'.join(res)
keys = ['user_id', 'order_id']
df['__keyColumn'] = df.apply(lambda x: DataFrameComparison.CreateKeyColumn(x, keys), axis=1)
Обработка ValueError
Для новой функции DataFrame.compare наиболее запутанной является следующая ошибка.
ValueError: Can only compare identically-labeled DataFrame objects
Причина этой ошибки заключается в том, что форма и порядок столбцов между двумя фреймами данных не идентичны. Да. DataFrame.compare работает только для проверки идентичности, но не проверки квалификации.
Способ решения проблемы: используйте созданный ранее keyColumn, сравните подмножество между DataFrames с тем же значением keyColumn. И сделайте это для каждого значения keyColumn.
Если размеры keyColumn из 2 DataFrames отличаются, поднимите проблему и пропустите проверку.
import pandas as pd
class DataFrameComparison:
@staticmethod
def CompareOneKey(target, test, keyValue):
targetTmp = target[ target['__keyColumn'] == keyValue ].reset_index(drop=True)
testTmp = test[ test['__keyColumn'] == keyValue ].reset_index(drop=True)
diff = pd.DataFrame({'A' : []})
if targetTmp.shape != testTmp.shape:
print('{0} has different shape between target and test. target shape is {1}, test shape is {2}'.format(keyValue, targetTmp.shape, testTmp.shape))
return diff
else:
diff = targetTmp.compare(testTmp)
return diff
for keyValue in keyValues:
DataFrameComparison.CompareOneKey(target, test, keyValue)