Оператор причинного вывода «do» полностью объяснен со сквозным примером с использованием Python и DoWhy

Полностью объясненные, сквозные примеры причинно-следственных связей, имеющие реальный, работающий исходный код, очень трудно найти в Интернете или в книгах, чтобы понять, как работает эта новая технология и почему это так важно.
Но если вы проявите настойчивость, это, безусловно, того стоит, поскольку вы сможете решить проблему другого типа, которая не имеет решения с использованием других методов машинного обучения.
Традиционные модели машинного обучения могут предсказать, что, вероятно, произойдет, если будущее в целом окажется похожим на прошлое, но они не могут сказать вам, что вы должны сделать по-другому, чтобы достичь желаемых результатов.
Например, алгоритм классификации может предсказать вероятность дефолта клиентов банковских кредитов, но он не может ответить на такие вопросы, как «Если мы изменим срок погашения кредита, будет ли больше клиентов избегать дефолта?»
Вот еще несколько примеров вопросов, на которые может ответить причинно-следственный вывод, на которые не могут ответить традиционные прогностические модели:
- Улучшает ли предлагаемое изменение системы результаты работы людей?
- Что привело к изменению результатов работы системы?
- Какие изменения в системе, вероятно, улучшат результаты для людей?
Есть много примеров онлайн-статей, в которых подробно рассматриваются математические аспекты причинно-следственного вывода, но очень немногие из них содержат проработанный пример с полным объяснением и всем исходным кодом.
Данные
Первое, что нам нужно, это некоторые данные. Мы создадим чисто синтетический набор данных, вдохновленный известными данными LaLonde, в которых наблюдалось и фиксировалось влияние программы обучения профессиональным навыкам на заработок в 1970-х годах.
Поскольку данные и исследование LaLonde послужили источником вдохновения, в разделе ссылок в конце статьи есть цитата.
import pandas as pd
df_training=pd.read_excel("data/training.xlsx")
df_training["age_group"] = df_training["age_group"].astype("category")
df_training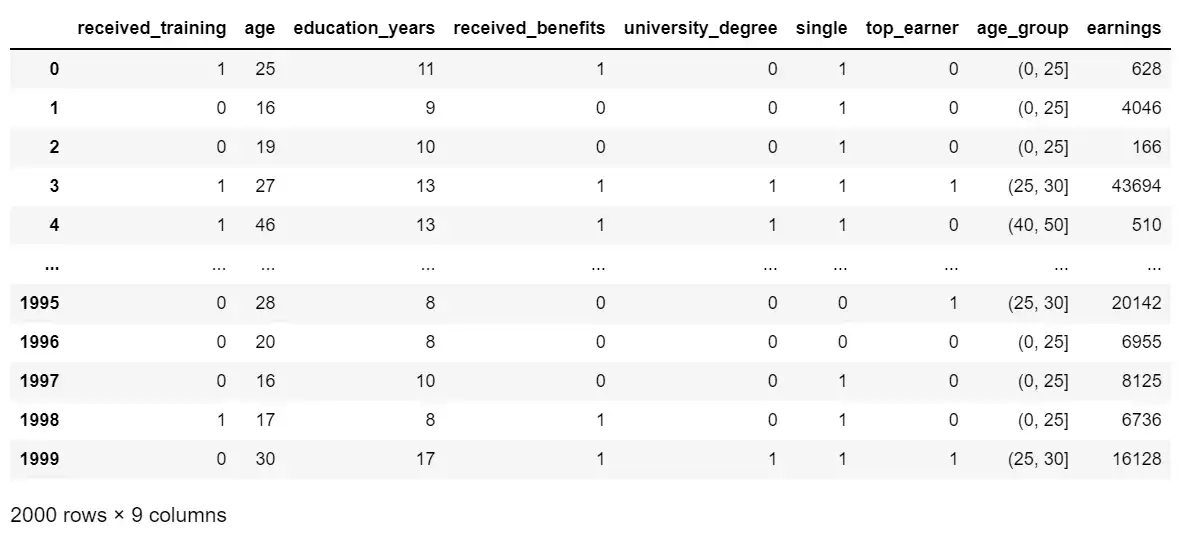
Стоит уделить время тому, чтобы понять ключевые аспекты синтетического набора данных
received_trainingимеет 1 балл, если человек посещал фиктивную программу обучения, предназначенную для получения навыков трудоустройства и увеличения потенциального дохода. В синтетическом наборе данных 640 человек посещали программу обучения и 1360 человек не посещали.ageэто возраст в годах.education_yearsпровести количество лет школьного образования.received_benefitsполучает 1, если человек когда-либо получал пособие по безработице.university_degreeравен 1, если человек учился и получил степень в университете.singleравно 1, если человек холост (т. е. не состоит в браке или в гражданском партнерстве).top_earnerсодержит 1, если человек находится в верхнем квартиле доходов.age_groupявляется категориальной версиейage.earningsэто сумма, которую человек зарабатывал через 3 года после завершения фиктивной программы обучения навыкам трудоустройства, и является «целью» или интересующей характеристикой.
Какое влияние оказала программа обучения?
Теперь давайте посмотрим на данные, чтобы увидеть, какое влияние программа обучения оказала на заработок участников.
received_training_filter = df_training["received_training"] == 1
impact_of_training = df_training[received_training_filter]["earnings"].mean() - df_training[~received_training_filter]["earnings"].mean()
top_earner_received_trainingment = df_training[received_training_filter]["top_earner"].value_counts(normalize=True)
top_earner_no_received_trainingment = df_training[~received_training_filter]["top_earner"].value_counts(normalize=True)
p_top_earner_received_trainingment = top_earner_received_trainingment[1]
p_top_earner_no_received_trainingment = top_earner_no_received_trainingment[1]
print(f"The average impact of participation in the employment skills training program on earnings is ${impact_of_training:+0,.2f}\n")
print(f"P(top earner=1 | received_trainingment=1) = {p_top_earner_received_trainingment}")
print(f"P(top earner=1 | received_trainingment=0) = {p_top_earner_no_received_trainingment}")
display(df_training.groupby("received_training")["earnings"].agg(["median","mean"]))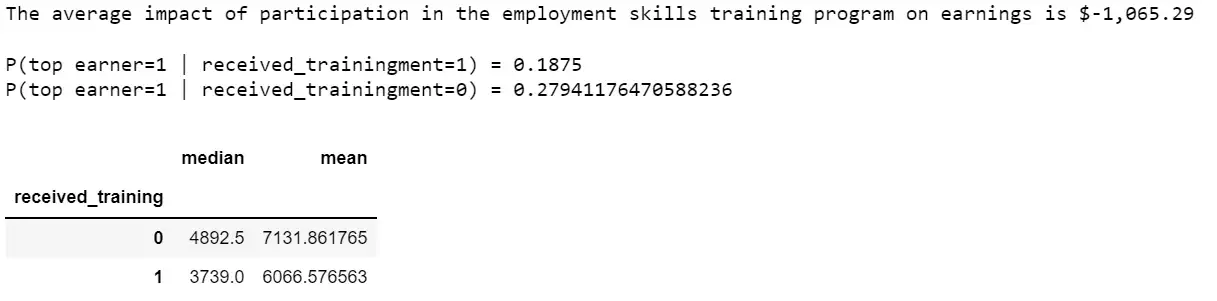
По результатам анализа влияние посещения программы обучения отрицательное.
- Очевидным результатом участия в программе обучения является снижение годового заработка на 1065,29 долларов США.
- Вероятность оказаться в числе высокооплачиваемых составляет 0,19 для тех, кто посещает тренинг, и 0,28 для тех, кто не посещает.
- Средний заработок тех, кто прошел обучение, составляет 3739 долларов, а тех, кто не прошел обучение, — 4893 доллара.
- Средний заработок тех, кто прошел обучение, составляет 6 067 долларов, а тех, кто не прошел обучение, — 7 132 доллара.
Какой совет вы бы дали?
Основываясь на анализе, четким советом было бы прекратить программу обучения, поскольку с помощью четырех различных показателей можно показать, что влияние на заработок неизменно отрицательно.
Хотя интуитивно этот вывод кажется неверным. Даже если обучение было абсолютно ужасным, не кажется правильным, что посещение обучения сделает участника менее трудоспособным и повредит его будущим заработкам.
Что пошло не так с анализом?
На данный момент потенциал традиционных подходов, включая вероятности и прогностические модели, не может продвинуть нас дальше. Любое применение этих методов приведет к выводу, что обучение следует отменить.
Чтобы преодолеть эти ограничения и по-настоящему понять, что происходит, нам нужно построить причинно-следственную модель и применить волшебный оператор «do».
Если вы хотите узнать истинное влияние тренировочной программы и почему использование традиционных вероятностей и прогностических моделей может привести к ошибочным и даже опасным результатам, читайте дальше.
Решение причинно-следственной связи с использованием оператора «do»
Давайте начнем путь к более точной оценке, более подробно рассмотрев некоторые функции в наборе данных.
import matplotlib.pyplot as plt
def plot_comparison(feature : str, normalize : bool = True):
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 6))
df_training[~received_training_filter][feature].value_counts(normalize=normalize).sort_index().plot(ax=axes[0], kind="bar", title="No Training", xlabel=feature, ylim=(0,1) if normalize else False)
df_training[received_training_filter][feature].value_counts(normalize=normalize).sort_index().plot(ax=axes[1], kind="bar", title="Received Training", xlabel=feature, ylim=(0,1) if normalize else False)
plt.show()
plot_comparison("education_years", normalize=False)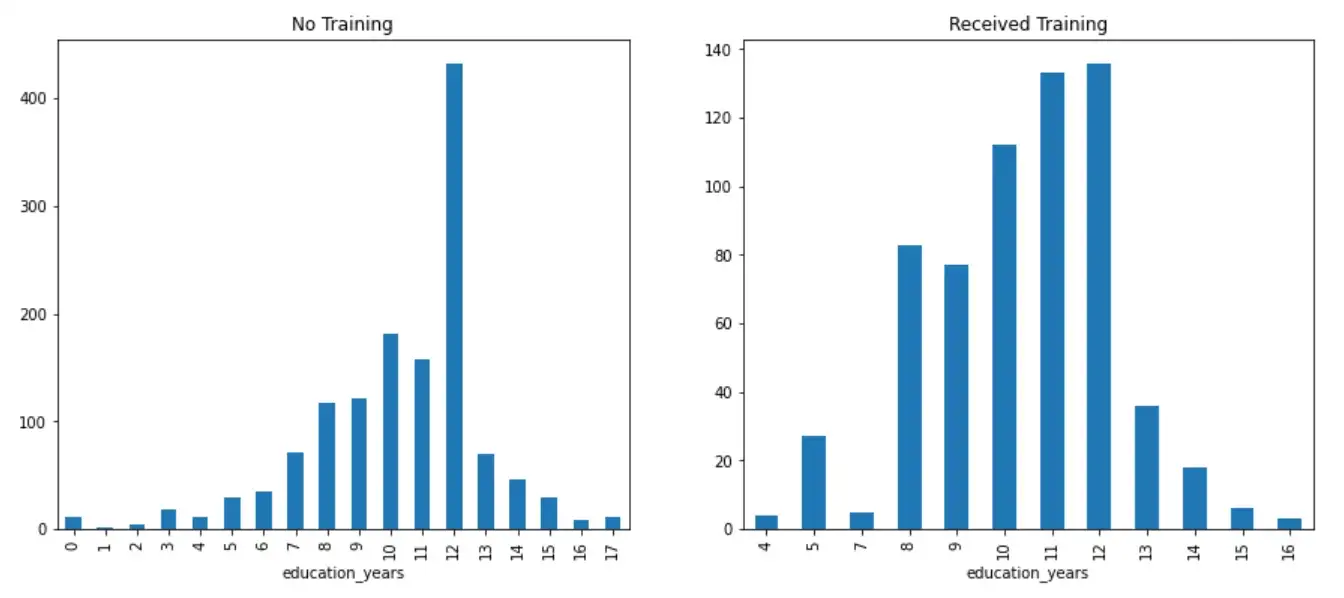
Ясно, что между теми, кто посещал обучение, и теми, кто его не посещал, наблюдается существенное отличие в образовании.
На этом этапе в реальном проекте мы будем работать с экспертами в предметной области, чтобы понять эти закономерности, но даже без знания предметной области разумно сделать вывод, что образование может иметь причинно-следственное влияние как на тех, кто посещает обучение, так и на их способность зарабатывать.
plot_comparison("age_group", normalize=False)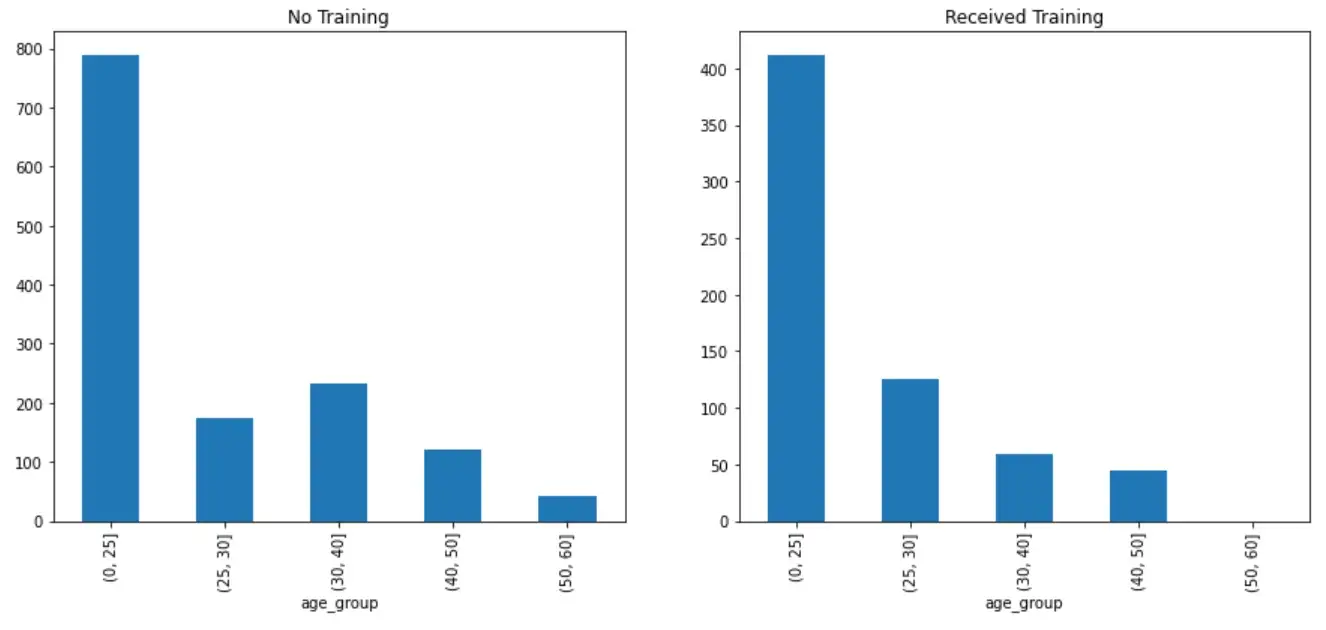
Это похожая история на века. Для тех, кто проходит обучение, это линейная модель с большим количеством молодых людей и меньшим количеством пожилых людей. Отсутствие тренировок имеет всплеск в возрастной группе 30–40 лет. Одна из гипотез может состоять в том, что многие 30–40-летние уже хорошо зарабатывают и не хотят никакого профессионального обучения.
Опять же, это может означать, что возраст влияет как на то, будет ли человек посещать обучение, так и на его потенциальный доход.
Причинно-следственный вывод и «смешение»
Этот простой дополнительный анализ выявил наличие «вмешивающихся факторов». Этот термин используется во многих доступных примерах, часто с сопутствующими расчетами и формулами, но обычно без четкого объяснения.
Проще говоря, влияние таких характеристик, как возраст и образование, смешивается с основным эффектом интереса, т. е. обучением, на заработок, и когда мы применяем традиционные подходы, нельзя отделить отдельный эффект.
Построение «Directed Acyclic Graph» (DAG)
Невозможно обнаружить причинно-следственную связь в данных самостоятельно. Данные должны быть дополнены «Directed Acyclic Graph» (DAG), который строится путем «обнаружения» причинно-следственных связей с использованием знаний предметной области и других методов.
Следующим шагом будет использование моего класса DirectedAcyclicGraph. Мы исключим исходный код из статьи, чтобы сделать его более кратким, но вот ссылка на полный исходный код на случай, если вы захотите запустить код самостоятельно — https://gist.github.com/grahamharrison68/9733b0cd4db8e3e049d5be7fc17b7602.
Вот наше предложение о причинно-следственных связях в данных
from dag_tools import DirectedAcyclicGraph
training_model_edges : list = [("age", "received_training"), ("age", "earnings"),
("education_years", "received_training"), ("education_years", "earnings"),
("received_benefits", "received_training"), ("received_benefits", "earnings"),
("single", "received_training"), ("single", "earnings"),
("university_degree", "received_training"), ("university_degree", "earnings"),
("received_training", "earnings")]
training_model_pos : dict = {"received_training": [1,1], "age": [3, 5], "education_years": [5, 5], "received_benefits": [7, 5], "single": [9, 5], "university_degree": [11, 5], "earnings": [13, 1]}
training_model = DirectedAcyclicGraph(edges=training_model_edges)
training_model.display_pgm_model(pos=training_model_pos)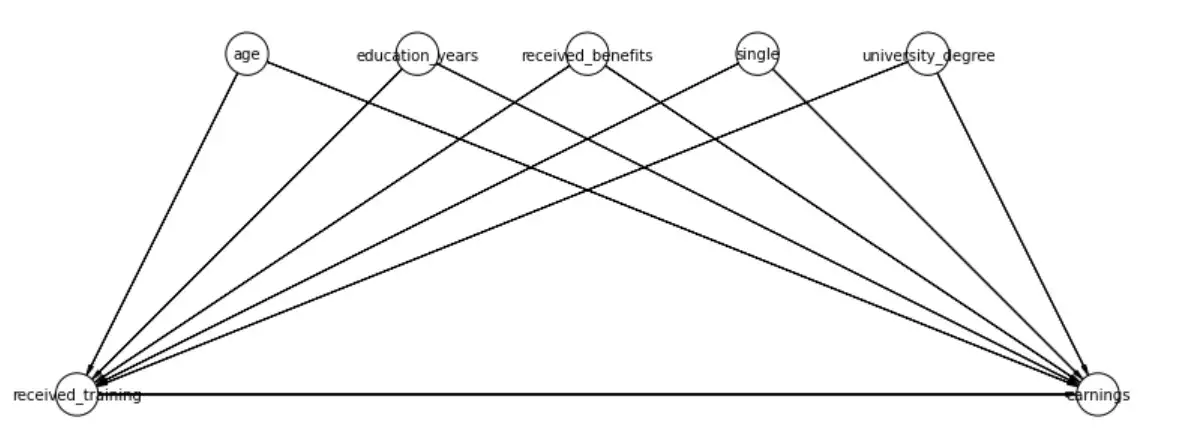
DAG можно интерпретировать следующим образом.:
received_training(т. е. посещение программы обучения) оказывает причинно-следственное влияние наearnings(т. е. будущие заработки).- Все остальные характеристики оказывают причинно-следственное влияние на то, присоединится ли человек к программе обучения или нет.
- Все остальные функции также оказывают причинно-следственное влияние на будущие доходы.
Например, возраст человека «заставляет» его посещать обучение или нет, может быть, больше молодых людей хотят пройти обучение, а возраст также «вызывает» заработок, возможно, потому, что пожилые люди с большим опытом могут зарабатывать больше.
Эта закономерность довольно распространена. Когда статистики проводят рандомизированное контрольное исследование (RCT), они могут обусловливать или контролировать переменные, которые смешиваются с основным эффектом.
Это означает, что для возраста они могут разделить наблюдения на возрастные группы, посмотреть на взаимосвязь между угощением и возрастом для каждой группы, а затем взять пропорциональное среднее значение для каждой группы, чтобы оценить истинный общий эффект.
Тем не менее, есть некоторые проблемы с этим подходом. Например, как вы определяете границы для групп? Что, если бы основное влияние было на возраст 16–18 лет, но граница была установлена на уровне 16–30 лет? А если бы не было наблюдений за 40–45-летними?
Другой подход — не наблюдать, а вмешиваться. Мы могли бы просто заставить всех пройти обучение, и тогда бы мы увидели истинный эффект. Но что, если наблюдения были историческими (как в данных LaLonde) и было слишком поздно вмешиваться? Или что, если бы это было исследование курения или ожирения?
Субъектов нельзя было заставить курить или страдать ожирением только для того, чтобы доказать наши теории!
Здесь в дело вступает оператор «do». Это звучит как волшебство, но действительно возможно построить модель причинно-следственного вывода, которая может точно имитировать эти вмешательства без необходимости выполнять их в реальном мире.
Это значительно сэкономит время и деньги, устранит необходимость в рандомизированных контрольных испытаниях, которые обусловливают большое количество переменных, и позволит изучить факторы, которые могут иметь моральные и этические проблемы в реальных исследованиях, таких как курение и ожирение.
Магия оператора «Do»
Давайте представим, что вместо того, чтобы наблюдать за группой людей, некоторые из которых прошли обучение, а некоторые нет, мы можем отправиться в прошлое, вмешаться, а не наблюдать, и заставить их всех пройти обучение.
В этом случае DAG будет выглядеть так
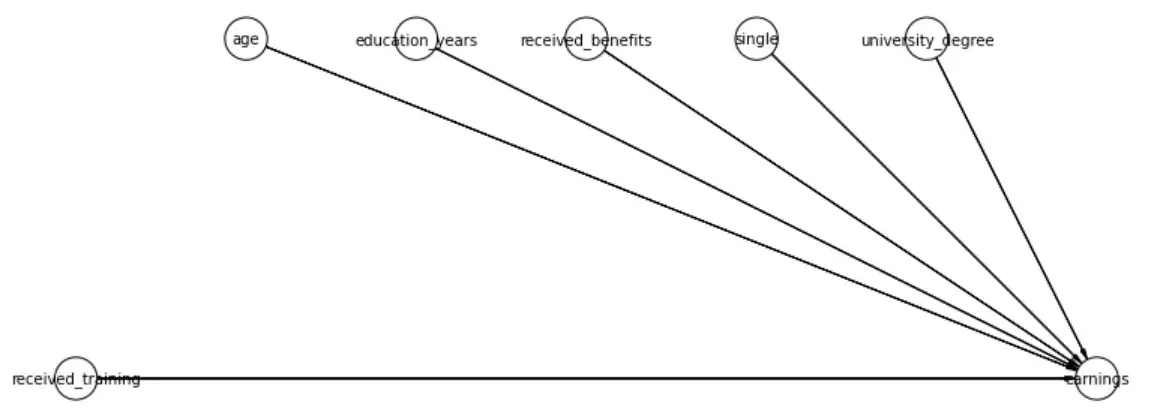
Это фактически то, что делает волшебный оператор «do». Если вы вмешаетесь и 𝑑𝑜(𝑡𝑟𝑒𝑎𝑡=1) вы фактически «сотрете» все входные линии причинно-следственной связи, потому что независимо от того, как возраст, образование и другие особенности влияют на вероятность прохождения обучения, это всегда произойдет.
За кулисами библиотека DoWhy имитирует это вмешательство. Он может сделать это, используя правила исчисления для преобразования 𝑝(earnings|𝑑𝑜(received_training=1), которые нельзя рассчитать напрямую, если мы не совершим физическое вмешательство в набор правил наблюдения, которые можно рассчитать на основе данных.
Мы намеренно опустим детали математики за пределы этой статьи. Существует множество статей, в которых показана математика, но очень мало статей, в которых показан рабочий пример с кодом Python, поэтому в этой статье основное внимание уделяется этому.
Вам понадобится класс DirectedAcyclicGraph, если вы хотите запустить код https://gist.github.com/grahamharrison68/9733b0cd4db8e3e049d5be7fc17b7602.
Вот полный исходный код для выполнения оператора «do» над данными.
import numpy as np
import dowhy.api
variable_types = {'received_training': 'd', 'age': 'c', 'education_years': 'c', 'received_benefits': 'd', 'single': 'd', 'university_degree': 'd', 'earnings': 'c'}
np.random.seed(1)
df_do = df_training.causal.do(x={"received_training": 1},
outcome="earnings",
dot_graph=training_model.gml_graph,
variable_types=variable_types,
proceed_when_unidentifiable=True)
display(df_do.groupby("received_training")["earnings"].agg(["median","mean"]))
display(df_do)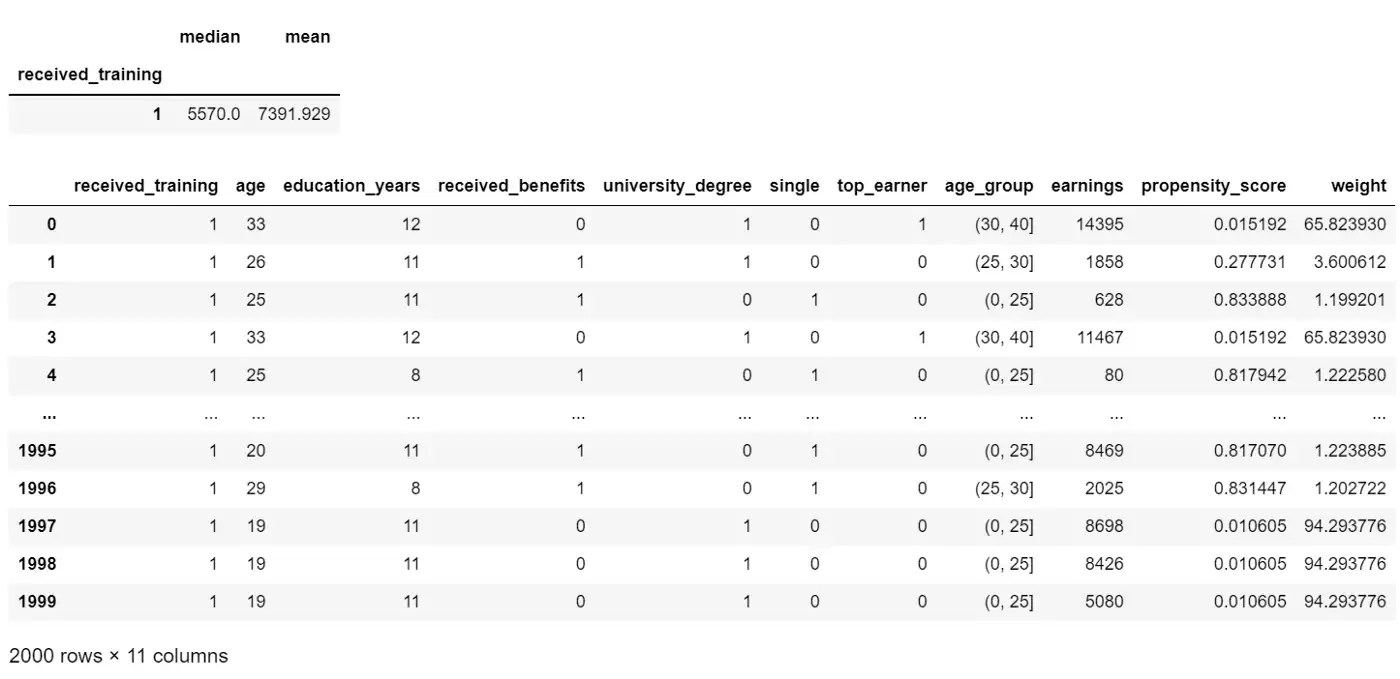
Что означает этот код?
Прежде чем мы перейдем к действительно удивительным результатам, было бы полезно пройтись по коду построчно.
Во-первых, импорт dowhy.api волшебным образом расширяет DataFrame pandas, так что класс получает новый метод causal.do.
Следующая установка случайного начального числа в numpy гарантирует воспроизводимость результатов метода do. В документации DoWhy ничего не упоминается об установке случайного начального числа, и это было обнаружено методом проб и ошибок. Также следует отметить, что случайное начальное число должно быть установлено в предыдущем операторе перед каждым вызовом causal.do, а не только перед первым.
Следующая загадка causal.do — это параметр variable_types. Документация DoWhy является неполной и непоследовательной. Перепробовав множество разных вещей, я пришел к следующим выводам.
- Несмотря на то, что говорится в документации, важны только два типа — «d» для дискретного и «c» для непрерывного.
- В статистике целое число является дискретным, но
DoWhyдает очень странные результаты, если целые числа объявлены как «d». Основываясь на документации и примерахDoWhy, придем к выводу, что целые числа должны быть объявлены как «c» для непрерывного. - В исходном коде
DoWhyесть методinfer_variable_types, но он заглушен без кода, поэтому мы напишем свою собственную реализацию, которая доступна как статический метод вDirectedAcyclicGraph.infer_variable_types().
Вот что означают все важные параметры метода causal.do:
x={"received_training": 1}говорит, что мы хотим «do». В этом случае мы хотим посмотреть, что произойдет, если всех заставят пройти обучение, которое представлено в данных какreceived_training=1.outcome="earnings"- это результат или эффект, который мы ищем, т.е. каково влияние «выполнения» receive_training=1 на заработок отдельных лиц?dot_graph=training_model.gml_graphинформирует операторdoо причинно-следственных связях, которые, по нашему мнению, существуют в данных.training_model— это экземпляр нашего классаDirectedAcyclicGraph, и мы присвоили ему свойство, которое выдает структуру в форматеgml.- Метод
doтребует передачиcommon_causesилиdot_graphдля описания причинно-следственных связей. - Параметр
dot_graphпринимает структуру в форматеdotилиgml, но это нигде не упоминается в документации; На наш взгляд,gmlнамного лучше, так как он используется везде вDoWhy. - Спецификация графа намного лучше, чем установка
common_causes, поскольку граф может охватывать любой тип структуры, тогда какcommon_causesгораздо более ограничивающий. Опять же, это нигде не упоминается в документацииDoWhy. - Параметр
variable_typesуже был объяснен. proceed_when_unidentifiable=Trueпозволяет избежать надоедливой подсказки пользователя, которая прерывает расчет.
Как это работает?
Метод causal.do возвращает новый DataFrame, который эффективно имитирует принудительное вмешательство и предоставляет данные, которые были бы собраны, если бы все прошли обучение.
df_do["received_training"].value_counts()
В этом отношении DoWhy отличается от большинства других каузальных библиотек Python, поскольку большинство других библиотек просто возвращают число, а не DataFrame.
Возврат DataFrame поначалу немного сбивает с толку, но стоит копнуть глубже, и это мощный, гибкий и информативный подход.
Не зная подробностей внутренней реализации, я пришел к выводу, что DoWhy имитирует рандомизированное контрольное испытание (РКИ) путем выборки данных на основе групп, которые необходимо использовать для «разоблачения» эффекта смешивания, описанного ранее в статье.
Например, взгляните на сравнение следующей функции с исходными данными наблюдений и новыми данными о вмешательстве.
def plot_do_comparison(feature : str, normalize : bool = True):
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 6))
df_training[received_training_filter][feature].value_counts(normalize=normalize).sort_index().plot(ax=axes[0], kind="bar", title="Received Training - Observation", xlabel=feature, ylim=(0,1) if normalize else False)
df_do[feature].value_counts(normalize=normalize).sort_index().plot(ax=axes[1], kind="bar", title="Received Training - Intervention", xlabel=feature, ylim=(0,1) if normalize else False)
plt.show()
plot_do_comparison("received_benefits", normalize=True)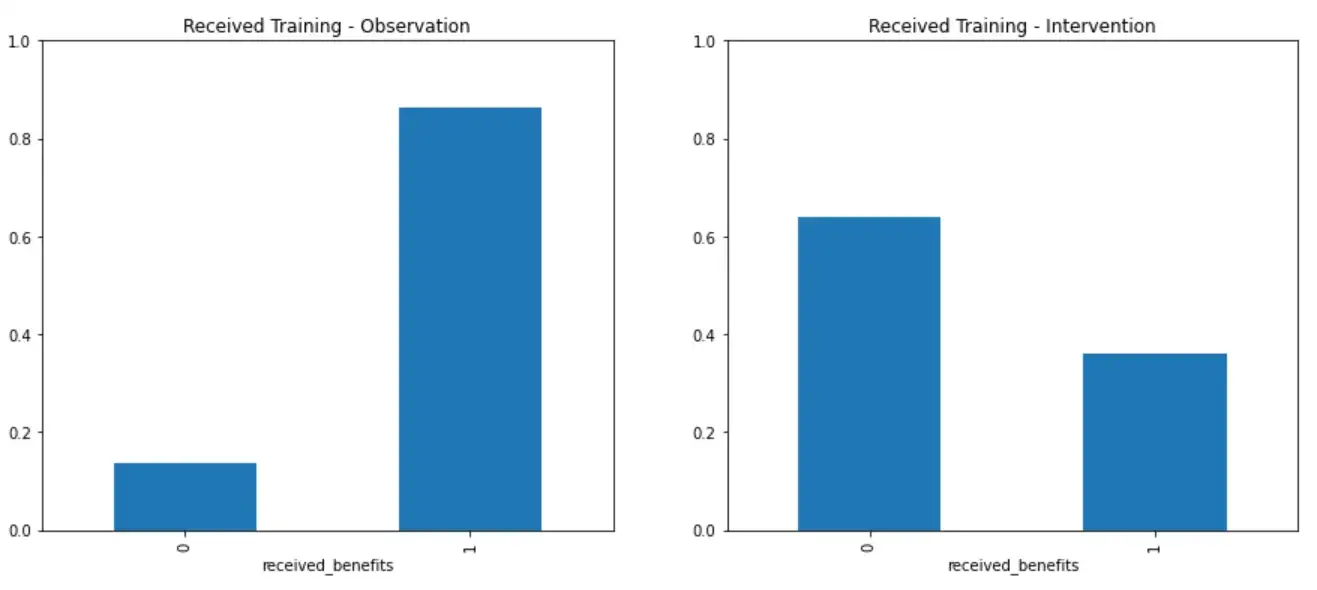
Очевидно, что DoWhy изменил выборку данных о вмешательстве для этой функции совершенно по-другому.
Каково истинное, «рассеянное» влияние тренинга на прибыль?
Теперь осталось только интерпретировать истинное влияние обучения на заработок, заглянув внутрь df_do DataFrame.
print("Median and mean earnings of those receiving training from the interventional data")
display(df_do.groupby("received_training")["earnings"].agg(["median","mean"]))
print("Median and mean earnings of those receiving training from the original observational data")
display(df_training[received_training_filter].groupby("received_training")["earnings"].agg(["median","mean"]))
Заключение
Традиционный подход с использованием вероятностей на данных наблюдений предполагал, что у тех, кто посещал обучение, на самом деле была бы более низкая заработная плата, чем если бы они не утруждали себя обучением.
Средняя заработная плата тех, кто прошел обучение на основе данных наблюдений, составляет 6 067 долларов, в то время как подход причинно-следственной связи «do» к моделированию вмешательства выявил истинное влияние — повышение заработной платы и среднюю заработную плату в размере 7 392 долларов.
Вместо того, чтобы отменять программу обучения, советом после применения подходов причинного вывода будет расширение программы обучения, потому что она предоставляет более равные возможности для групп, которым необходимо помочь увеличить свои долгосрочные доходы.
Всякий раз, когда в данных действуют причинно-следственные связи, традиционные прогностические подходы могут привести к неправильным выводам и рекомендациям, и это делает причинно-следственный вывод важным инструментом, который должен иметь в своем арсенале каждый специалист по данным.