Pandas для одноразового кодирования данных, предотвращающего высокую мощность

В этой статье мы раскроем тему простого метода однократного кодирования переменных с использованием Pandas
Будем полагать, что большинство согласится с тем, что для начала необходима очистка данных. Проект обычно начинается с некоторого исследования и очистки, прежде чем мы сможем перейти к части моделирования.
Действительно, большая часть работы специалиста по обработке данных выполняется между очисткой и преобразованием набора данных.
Проблема, которую необходимо решить в этом кратком руководстве, заключается в том, что мы должны иметь дело с кодировкой переменных. Большинство алгоритмов машинного обучения ожидают, что для оценки чего-либо используются цифры, а не текст. В конце концов, компьютеры - это логические машины, которые полагаются на числа в качестве своего основного языка.
С учетом сказанного, когда мы получим набор данных, содержащий категориальные переменные, нам, вероятно, потребуется преобразовать его в числа, чтобы мы могли представить преобразованные данные для работы алгоритма с ними.
Обычно используется преобразование One Hot Encoding [OHE], которое берет категории и делает их двоичными значениями. Посмотрите на следующий рисунок. Первая строка — это категория A, поэтому после OHE она становится тремя столбцами, где A — положительное значение (1), а B/C — отрицательное. Следующая строка — это строка для категории B. Поскольку B сейчас положительна, она получает 1, а остальные получают 0. И это относится ко всем категориям, которые у нас есть.
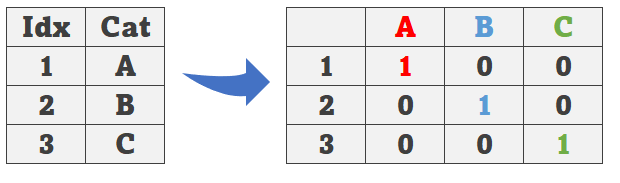
В некоторых случаях преобразование довольно простое, но в других случаях, когда у нас слишком много категорий, это сделает наш набор данных очень широким, со слишком большим количеством переменных после одного горячего кодирования. Это то, о чем мы собираемся поговорить дальше.
Высокая мощность
Посмотрите на этот случайно созданный набор данных.
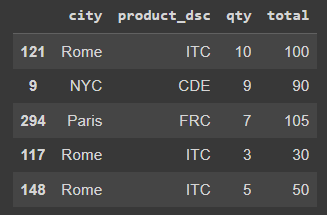
Давайте посмотрим на количество уникальных значений для категориальных переменных city и product_dsc.
# Unique values for city
df.city.nunique()
[OUT]: 24
# unique values for product
df.product_dsc.nunique()
[OUT]: 21Обратите внимание на большое количество разных городов и продуктов. Если мы используем OHE для этого набора данных, мы получим очень большой набор данных.
# One Hot Encoding
pd.get_dummies(df, drop_first=True).head()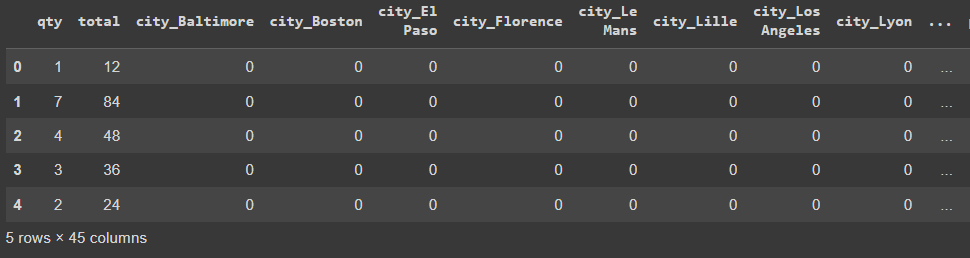
Даже используя аргумент drop_first =True для отбрасывания первой категории каждой переменной, мы все равно получаем 45 переменных, что может быть слишком много и может повлиять на производительность модели.
(Примечание: удаление первого столбца закодированной категории - это нормально. Рассмотрим пример с ABC ранее. Если мы отбросим закодированный столбец A, когда мы увидим наблюдение, которое имеет B = 0 и C = 0, это может означать только то, что наблюдение равно A = 1).
Наборы данных с высокой мощностью (слишком много переменных) могут быть затронуты Curse of Dimensionality, которое гласит, что когда у нас есть набор данных с высокой размерностью, он становится разреженным (слишком много нулей), поэтому потребность в большем количестве данных для обеспечения надежности модели растет экспоненциально, достигая точки, когда мы больше не можем добейтесь идеального количества наблюдений.
И как решить данную проблему?
Простое решение
Вернемся к набору данных и посмотрим на количество городов и продуктов.
# Counting by city
df.city.value_counts()
# Counting by product
df.product_dsc.value_counts()Что дает результат
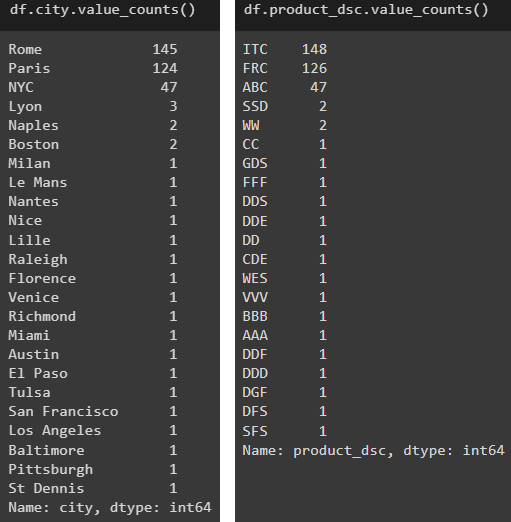
Мы видим, что есть только 3 города и 3 продукта, которые производят ок. 90% данных. Итак, в подобных случаях предлагаемое здесь простое решение состоит в том, чтобы использовать Pandas для уменьшения количества категорий, сохраняя только те верхние значения, как есть, и собирая все остальное в «other» ведро.
# List top 3
city_top3 = df.groupby('city').city.count().nlargest(3).index
prod_top3 = df.groupby('product_dsc').product_dsc.count().nlargest(3).index
# Keep top 3 as is and the rest as "Other"
df['city2'] = df.city.where(df.city.isin(city_top3), other='Other')
df['product2'] = df.product_dsc.where(df.product_dsc.isin(prod_top3), other='Other')Давайте посмотрим на образец полученных данных.
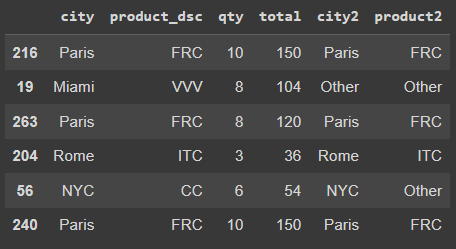
Затем мы можем просто удалить старые переменные city и product_dsc, и снова готовы использовать OHE.
# Drop old city and product
df2 = df.drop(['city', 'product_dsc'],axis=1)
# One Hot Encoding
pd.get_dummies(df2)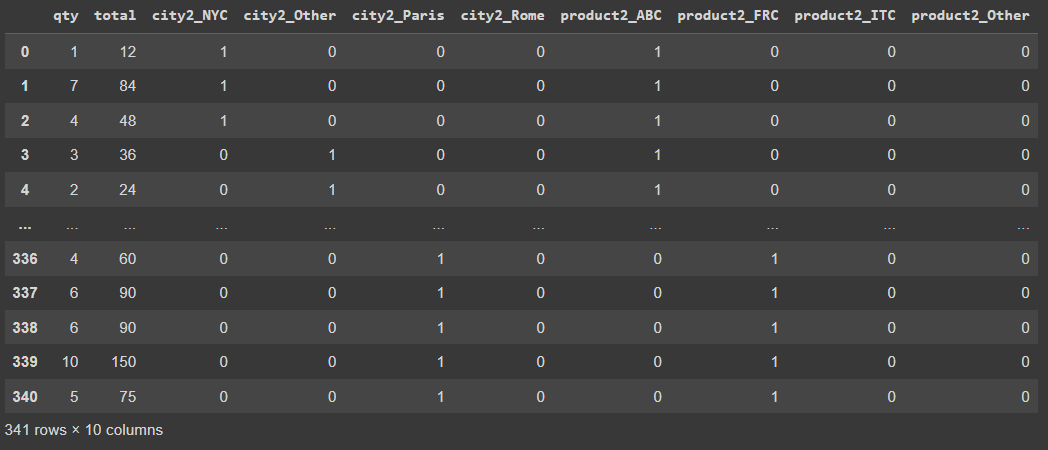
Обратите внимание, что мы сократили количество переменных после OHE с 45 до 10 столбцов. Мы все еще могли бы использовать аргумент drop_first=True или, может быть, использовать еще лучшее решение, заключающееся в том, чтобы вместо этого отбрасывать столбцы для «другого», учитывая, что они в любом случае будут в основном нулями. Ведь мы знаем, что если город не Нью-Йорк, Рим или Париж, то он может быть только «other». Та же логика применима и к продуктам.
Напоследок
Краткое изложение того, что мы узнали:
- One Hot Encoding полезен для преобразования категориальных данных в числа.
- Использование OHE в наборе данных со слишком большим количеством переменных приведет к созданию широкого набора данных.
- Слишком широкие данные могут пострадать от Curse of Dimensionality, что поставит под угрозу производительность модели.
- Простым решением может быть использование Pandas
.groupby(),.nlargest()и.where()для уменьшения количества категорий до OHE.
Ознакомиться кодом по данной теме вы можете здесь.