Pandas: применять, сопоставлять или трансформировать?

Как человек, который использует Pandas уже несколько лет, мы заметили, как много людей часто прибегают к почти постоянному использованию функции apply. Хотя это не является проблемой для небольших наборов данных, проблемы с производительностью, вызванные этим, становятся намного более заметными при работе с большими объемами данных. Хотя гибкость apply делает его легким выбором, в этой статье представлены другие функции Pandas в качестве потенциальных альтернатив.
В этом посте мы обсудим предполагаемое использование apply, agg, map и transform с несколькими примерами.
Состав статьи:
* map
* transform
* agg
* apply
* Unexpected behaviorПример
Давайте возьмем фрейм данных, содержащий оценки трех студентов по двум предметам. Мы будем работать с этим примером по ходу дела.
df_english = pd.DataFrame(
{
"student": ["John", "James", "Jennifer"],
"gender": ["male", "male", "female"],
"score": [20, 30, 30],
"subject": "english"
}
)
df_math = pd.DataFrame(
{
"student": ["John", "James", "Jennifer"],
"gender": ["male", "male", "female"],
"score": [90, 100, 95],
"subject": "math"
}
)
Теперь мы объединим их, чтобы создать единый фрейм данных.
df = pd.concat(
[df_english, df_math],
ignore_index=True
)Наш окончательный фрейм данных выглядит следующим образом:
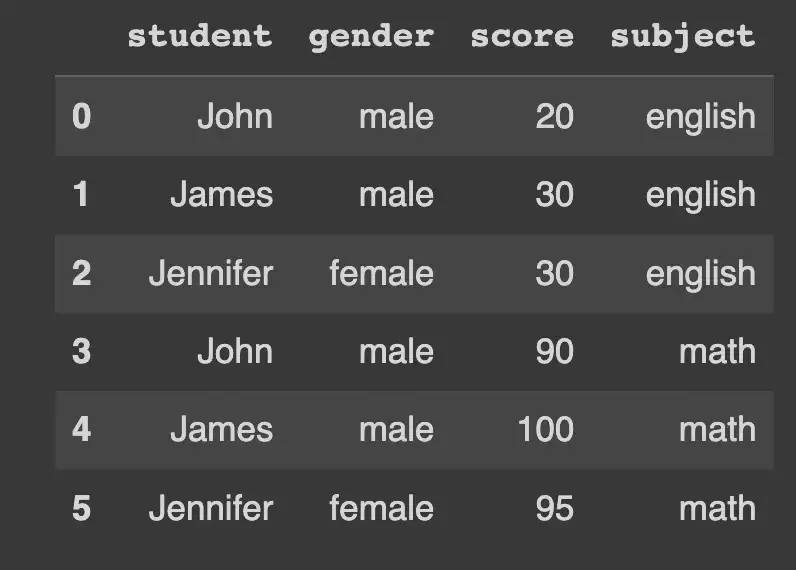
Мы рассмотрим использование каждой функции, используя этот набор данных.
map
Series.map(arg, na_action=None) -> SeriesМетод map работает с Series и сопоставляет каждое значение на основе того, что передается в качеств функции arg. arg может быть функцией — точно такой же, какую может использовать apply, — но это также может быть словарь или серия.
na_action, по сути, позволяет вам решать, что происходит со значениями NaN, если они существуют в серии. Если установлено значение "ignore”, аргумент arg не будет применяться к значениям NaN.
Например, если вы хотите заменить категориальные значения в своей серии с помощью сопоставления, вы можете сделать что-то вроде этого:
GENDER_ENCODING = {
"male": 0,
"female": 1
}df["gender"].map(GENDER_ENCODING)Результат такой, как и ожидалось: он возвращает сопоставленное значение, соответствующее каждому элементу в нашей исходной серии.

Хотя apply не принимает словарь, это все равно можно сделать с его помощью, но это далеко не так эффективно или элегантно.
df["gender"].apply(lambda x:
GENDER_ENCODING.get(x, np.nan)
)
Performance
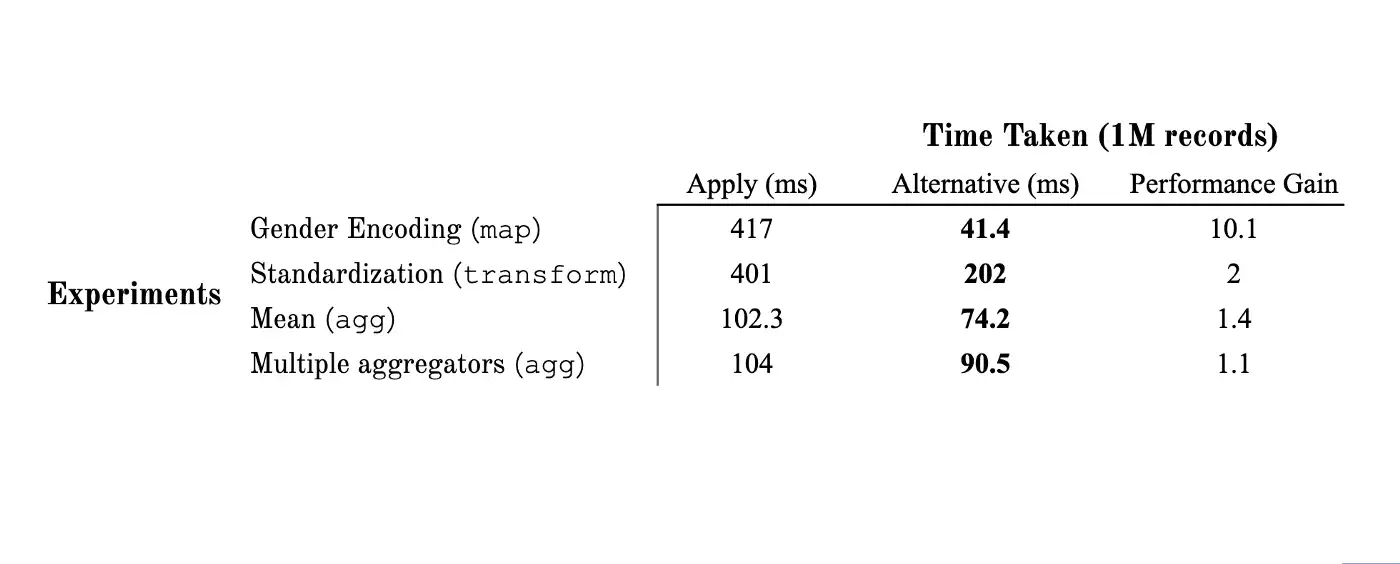
В простом тесте кодирования гендерного ряда с миллионом записей map был в 10 раз быстрее, чем apply.
random_gender_series = pd.Series([
random.choice(["male", "female"]) for _ in range(1_000_000)
])
random_gender_series.value_counts()
"""
>>>
female 500094
male 499906
dtype: int64
""""""
map performance
"""
%%timeit
random_gender_series.map(GENDER_ENCODING)
# 41.4 ms ± 4.24 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)"""
apply performance
"""
%%timeit
random_gender_series.apply(lambda x:
GENDER_ENCODING.get(x, np.nan)
)
# 417 ms ± 5.32 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)Поскольку map также может принимать функции, может быть передано любое преобразование, которое не зависит от других элементов — в отличие от агрегации, такой как, например, mean.
Использование таких вещей, как map(len) или map(upper), действительно может значительно упростить предварительную обработку.
Давайте присвоим этот результат гендерной кодировки обратно нашему фрейму данных и перейдем к applymap.
df["gender"] = df["gender"].map(GENDER_ENCODING)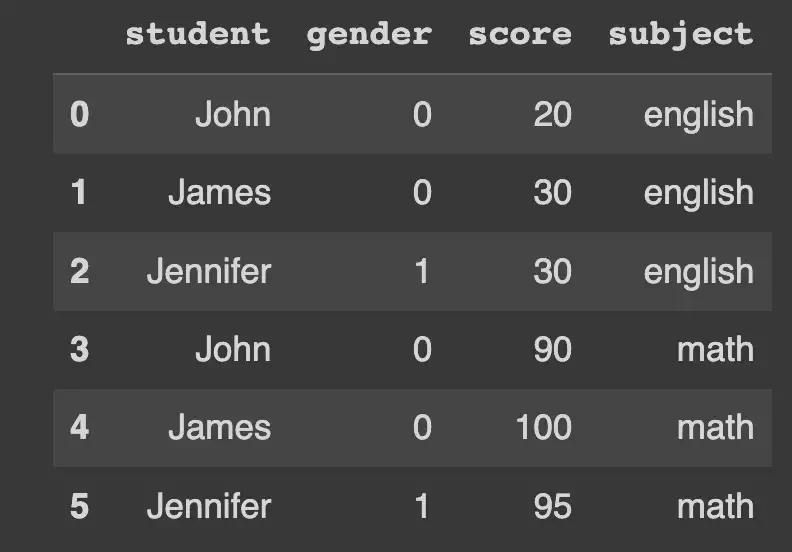
applymap
DataFrame.applymap(func, na_action=None, **kwargs) -> DataFrameНе будем тратить слишком много времени на applymap, так как он очень похож на map и внутренне реализован с помощью apply. applymap работает с фреймом данных поэлементно, точно так же, как и map, но поскольку он внутренне реализован с помощью apply, он не может принимать словарь или серию в качестве входных данных — разрешены только функции.
try:
df.applymap(dict())
except TypeError as e:
print("Only callables are valid! Error:", e)
"""
Only callables are valid! Error: the first argument must be callable
"""na_action работает точно так же, как и в map.
transform
DataFrame.transform(func, axis=0, *args, **kwargs) -> DataFrameВ то время как предыдущие две функции работали на уровне элемента, преобразование работает на уровне столбца. Это означает, что вы можете использовать логику агрегирования с transform.
Давайте продолжим работать с тем же фреймом данных, что и раньше.
Допустим, мы хотели стандартизировать наши данные. Мы могли бы сделать что-то вроде этого:
df.groupby("subject")["score"] \
.transform(
lambda x: (x - x.mean()) / x.std()
)
"""
0 -1.154701
1 0.577350
2 0.577350
3 -1.000000
4 1.000000
5 0.000000
Name: score, dtype: float64
"""То, что мы, по сути, делаем, - это берем серию баллов из каждой группы и заменяем каждый элемент его стандартизированным значением. Это невозможно сделать с помощью map, поскольку для этого требуется вычисление по столбцам, в то время как map работает только по элементам.
Если вы знакомы с apply, вы знаете, что это поведение также может быть реализовано с его помощью.
df.groupby("subject")["score"] \
.apply(
lambda x: (x - x.mean()) / x.std()
)
"""
0 -1.154701
1 0.577350
2 0.577350
3 -1.000000
4 1.000000
5 0.000000
Name: score, dtype: float64
"""Мы получаем, по сути, одно и то же. Тогда в чем смысл использования transform?
transform должен возвращать фрейм данных той же длины по оси, по которой оно применяется.
Помните, что transform должен возвращать фрейм данных той же длины вдоль оси, к которой оно применено. Это означает, что даже если transform используется с операцией groupby, которая возвращает агрегированные значения, оно присваивает эти агрегированные значения каждому элементу.
Например, предположим, что мы хотели узнать сумму баллов всех студентов по каждому предмету. Мы могли бы сделать это с помощью apply следующим образом:
df.groupby("subject")["score"] \
.apply(
sum
)
"""
subject
english 80
math 285
Name: score, dtype: int64
"""Но здесь мы суммировали оценки по предметам, потеряв информацию о том, как соотносятся отдельные учащиеся и их оценки. Если бы мы попробовали сделать то же самое с transform, то получили бы нечто гораздо более интересное:
df.groupby("subject")["score"] \
.transform(
sum
)
"""
0 80
1 80
2 80
3 285
4 285
5 285
Name: score, dtype: int64
"""Таким образом, хотя мы работали на уровне группы, мы все еще могли отслеживать, как информация на уровне группы соотносится с информацией на уровне строк.
Из-за такого поведения transform выдает ошибку ValueError, если ваша логика не возвращает преобразованный ряд. Так что любой вид агрегации не сработал бы. Однако гибкость apply гарантирует, что она отлично работает даже с агрегациями, как мы подробно увидим в следующем разделе.
try:
df["score"].transform("mean")
except ValueError as e:
print("Aggregation doesn't work with transform. Error:", e)
"""
Aggregation doesn't work with transform. Error: Function did not transform
"""df["score"].apply("mean")
"""
60.833333333333336
"""Performance
Что касается производительности, то при переключении с apply на transform происходит двукратное ускорение.
random_score_df = pd.DataFrame({
"subject": random.choices(["english", "math", "science", "history"], k=1_000_000),
"score": random.choices(list(np.arange(1, 100)), k=1_000_000)
})
"""
Transform Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"] \
.transform(
lambda x: (x - x.mean()) / x.std()
)
"""
202 ms ± 5.37 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
""""""
Apply Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"] \
.apply(
lambda x: (x - x.mean()) / x.std()
)
"""
401 ms ± 5.37 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
"""agg
DataFrame.agg(func=None, axis=0, *args, **kwargs)
-> scalar | pd.Series | pd.DataFrameФункцию agg намного проще понять, поскольку она просто возвращает агрегат поверх переданных ей данных. Таким образом, независимо от того, как реализован ваш пользовательский агрегатор, результатом будет одно значение для каждого столбца, который ему передается.
Теперь мы рассмотрим простую агрегацию — вычисление среднего значения каждой группы по столбцу score. Обратите внимание, как мы можем передать позиционный аргумент в agg, чтобы напрямую назвать агрегированный результат.
df.groupby("subject")["score"].agg(mean_score="mean").round(2)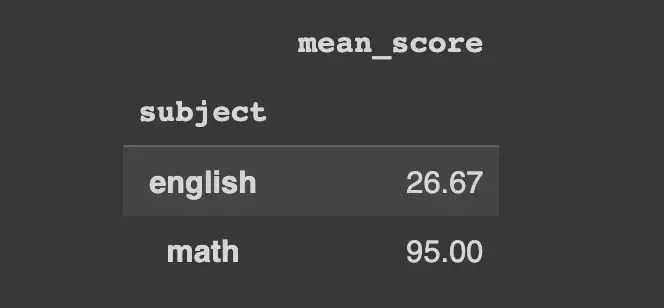
Несколько агрегаторов могут быть переданы в виде списка.
df.groupby("subject")["score"].agg(
["min", "mean", "max"]
).round(2)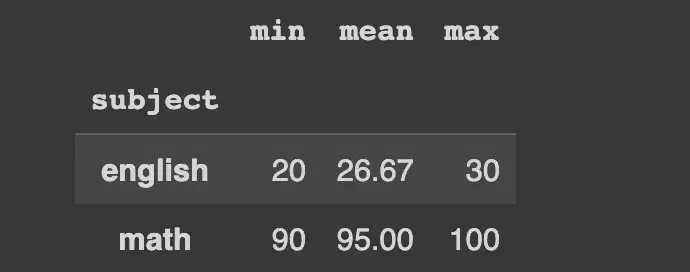
agg предлагает гораздо больше возможностей для выполнения агрегаций. В предыдущих двух примерах мы видели, что он позволяет выполнять несколько агрегаций в списке и даже именованные агрегации. Вы также можете создавать пользовательские агрегаторы, а также выполнять несколько конкретных агрегаций по каждому столбцу, например, вычислять среднее значение по одному столбцу и медиану по другому.
Performance
С точки зрения производительности, agg работает умеренно быстрее, чем apply, по крайней мере, для простых агрегаций. Давайте воссоздадим тот же фрейм данных из предыдущего теста производительности.
random_score_df = pd.DataFrame({
"subject": random.choices(["english", "math", "science", "history"], k=1_000_000),
"score": random.choices(list(np.arange(1, 100)), k=1_000_000)
})
"""
Agg Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"].agg("mean")
"""
74.2 ms ± 5.02 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
""""""
Apply Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"].apply(lambda x: x.mean())
"""
102.3 ms ± 1.16 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""Мы видим увеличение производительности примерно на 30% при использовании agg вместо apply. При тестировании на нескольких агрегациях мы получаем аналогичные результаты.
"""
Multiple Aggregators Performance Test with agg
"""
%%timeit
random_score_df.groupby("subject")["score"].agg(
["min", "mean", "max"]
)
"""
90.5 ms ± 16.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
""""""
Multiple Aggregators Performance Test with apply
"""
%%timeit
random_score_df.groupby("subject")["score"].apply(
lambda x: pd.Series(
{"min": x.min(), "mean": x.mean(), "max": x.max()}
)
).unstack()
"""
104 ms ± 5.78 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""apply
Для нас это был самый запутанный вариант из тех, которые мы обсуждали, главным образом из-за того, насколько он гибкий. Каждый из приведенных выше примеров может быть воспроизведен с помощью apply, как мы только что видели.
Конечно, за такую гибкость приходится платить: она заметно медленнее, как показали наши тесты производительности.
Неожиданное поведение
Другая проблема с гибкостью применения заключается в том, что результат иногда бывает неожиданным.
Обработка первой группы дважды
Одна из таких проблем, которая сейчас решена, касалась некоторых оптимизаций производительности: при apply первая группа обрабатывалась дважды. В первый раз он будет искать оптимизации, а затем будет обрабатывать каждую группу, таким образом, дважды обрабатывая первую группу.
Мы впервые заметили это во время отладки собственной функции применения, которую мы написали: когда распечатывали информацию о группе, первая группа отображалась дважды. Такое поведение привело бы к скрытым ошибкам, если бы были какие-либо побочные эффекты, поскольку любые обновления происходили бы дважды в первой группе.
Когда есть только одна группа
Эта проблема преследует pandas по крайней мере с 2014 года. Это происходит, когда во всем столбце есть только одна группа. В таком сценарии, даже несмотря на то, что ожидается, что функция apply вернет серию, в конечном итоге она выдает фрейм данных.
Результат аналогичен дополнительной операции распаковки. Давайте попробуем воспроизвести это. Мы будем использовать наш исходный фрейм данных и добавим столбец city. Давайте предположим, что все наши три студента, Джон, Джеймс и Дженнифер, родом из Бостона.
df_single_group = df.copy()
df_single_group["city"] = "Boston"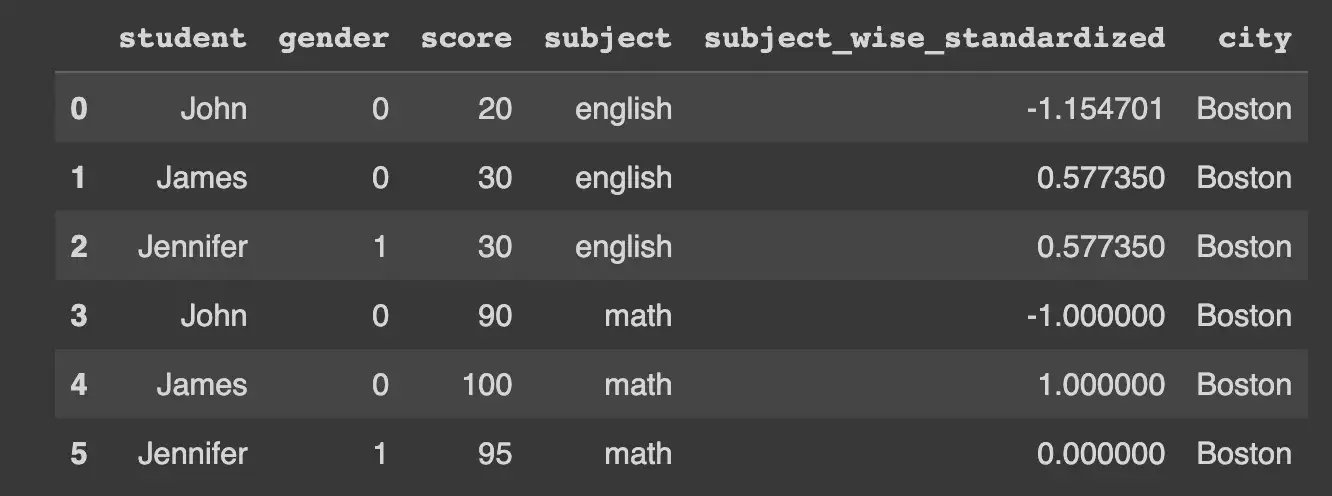
Теперь давайте рассчитаем групповое среднее для двух наборов групп: один на основе столбца темы, а другой на основе города.
Теперь давайте рассчитаем среднее значение по группам для двух наборов групп: одна основана на столбце subject, а другая - на city.
Группируясь по столбцу subject, мы получаем многоиндексированный ряд, как и следовало ожидать.
df_single_group.groupby("subject").apply(lambda x: x["score"])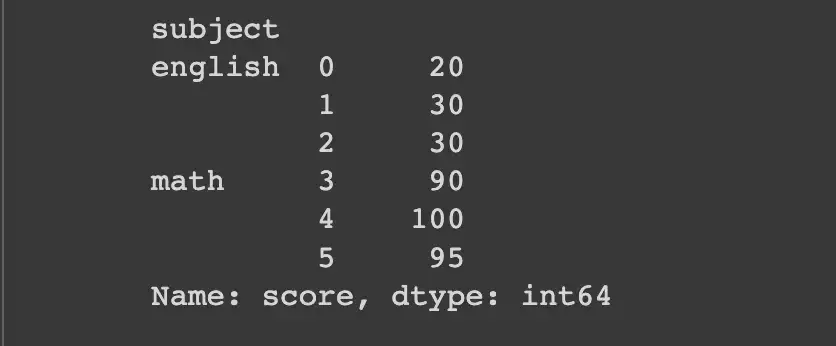
Но когда мы группируем по столбцу city, который, как мы знаем, имеет только одну группу (соответствующую “Boston”), мы получаем это:
df_single_group.groupby("city").apply(lambda x: x["score"])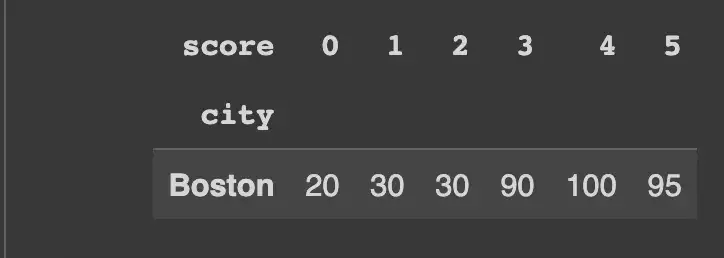
Заметили, как результат поворачивается? Если мы stack это, мы получим ожидаемый результат.
df_single_group.groupby("city").apply(lambda x: x["score"]).stack()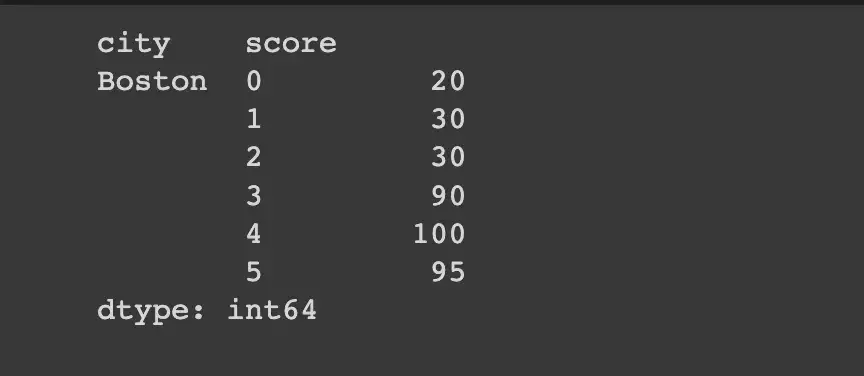
На момент написания этой статьи проблема так и не была решена.
Код
Вы можете найти весь код вместе с тестами производительности здесь.
Заключение
Гибкость, которую обеспечивает apply, делает его очень удобным выбором в большинстве сценариев, но, как мы видели, часто более эффективно использовать то, что было разработано для того, что вам нужно выполнить. Этот пост охватывает только часть истории apply, и в этой функции есть гораздо больше. Следующий пост будет продолжен отсюда.
Этот пост должен был дать вам представление о том, что возможно с Pandas, и мы надеемся, что это побудит вас в полной мере использовать его функциональность.