Парсинг HTML в Node.js: Подробное руководство

HTML (Hypertext Markup Language) - это стандартный язык разметки, используемый для создания веб-страниц, определяющий структуру и компоненты веб-страницы с помощью различных элементов и тегов. Для приложений Node.js npm node-html-parser предоставляет мощный инструмент для разбора HTML. Он упрощает взаимодействие с HTML-материалами, облегчая такие задачи, как извлечение данных, скраппинг сайтов и манипулирование контентом.
В этой статье мы рассмотрим возможности npm node-html-parser и узнаем, как использовать его функции для эффективного разбора HTML в приложениях Node.js.
Как работает HTML-парсер?
HTML-парсер работает, анализируя структуру HTML-документов в соответствии с правилами и спецификациями языка HTML. В общем виде парсеры HTML работают следующим образом:
Шаг 1: Токенизация - парсер HTML начинает с токенизации входного HTML-содержимого. В ходе этого процесса отдельные элементы разделяются на лексемы.
Шаг 2: Парсинг - после создания маркера парсер начинает его разбор и построение дерева, известного как объектная модель документа (DOM). Каждый узел в дереве соответствует HTML-элементу, представляющему иерархическую структуру HTML-страницы.
Шаг 3: Манипулирование и обход - После того как дерево DOM построено, мы можем получить доступ к его узлам или изменить их, обходя дерево.
Поскольку они позволяют разработчикам интерпретировать, анализировать и изменять HTML-страницы, HTML-парсеры необходимы для веб-разработки. Для таких операций, как извлечение данных, рендеринг контента, веб-скраппинг и других приложений.
Парсинг HTML в Node.js с помощью node-html-parser
Шаг 1: Инициализация проекта Node.js - Мы можем инициализировать наш проект Node.js, перейдя в каталог проекта в терминале и выполнив следующую команду.
npm init -yШаг 2: Установка пакета - Установите пакет npm node-html-parser, выполнив следующую команду в терминале.
npm install node-html-parser
Шаг 3: Импорт пакета - После установки npm node-html-parser вы можете импортировать его в свой скрипт, чтобы использовать функциональность, предоставляемую пакетом.
const { parse } = require('node-html-parser');
Шаг 4: Вот пример использования npm node-html-parser для разбора HTML-строки.
const { parse } = require('node-html-parser');
const htmlString = '<div><p>Hello, world!</p></div>';
const root = parse(htmlString);
console.log(root.querySelector('p').text);
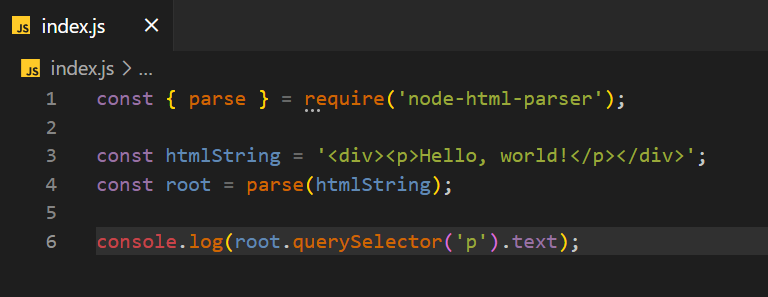
Во-первых, мы импортируем функцию parse из модуля node-html-parser и определяем HTML-строку ("Hello, world!"), содержащую элемент <div> с вложенным элементом <p>.
Она использует функцию parse для разбора HTML-строки и создания древовидного представления HTML-содержимого в DOM. Затем она использует метод querySelector на разобранном корневом элементе (<div>) для выбора первого элемента <p> внутри него и обращается к свойству text выбранного элемента <p> для получения его текстового содержимого. Наконец, он записывает текстовое содержимое в консоль.
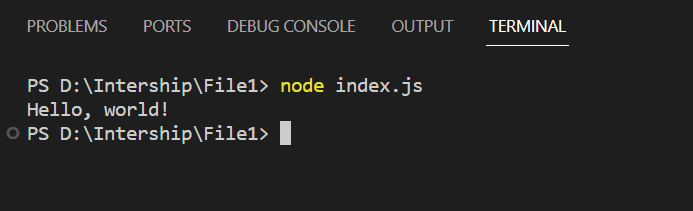
Выходные данные:
Применение HTML-парсера
Ниже приведены примеры того, почему парсер HTML чрезвычайно полезен.
1. Анализ структуры дерева DOM
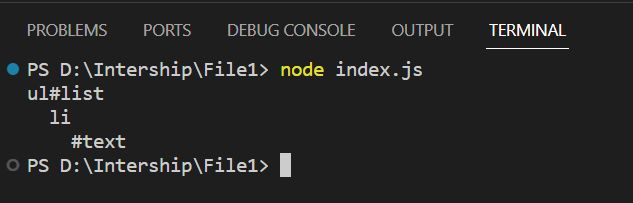
Мы можем использовать библиотеку npm node-html-parser для разбора HTML, а затем получить доступ к структуре первого дочернего узла корневого элемента.
import { parse } from 'node-html-parser';
const root = parse('<ul id="list"><li>Hello World</li></ul>');
console.log(root.firstChild.structure);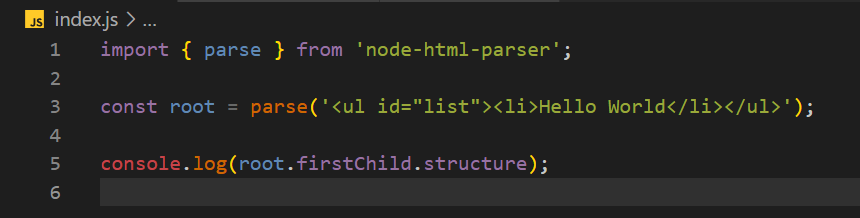
Сначала мы импортируем функцию parse из модуля npm node-html-parser. Функция parse используется для разбора HTML-строк и создания представления DOM-дерева (корня) HTML-контента. Затем мы регистрируем структуру дерева DOM, начиная с первого дочернего узла корневого узла. Структура показывает иерархию элементов в содержимом HTML.
Выходные данные:
2. Изменение содержимого DOM
Мы также можем использовать библиотеку npm node-html-parser для изменения содержимого корневого узла.
import { parse } from 'node-html-parser';
const root = parse('<div></div>');
root.set_content('<div>Hello World</div>');
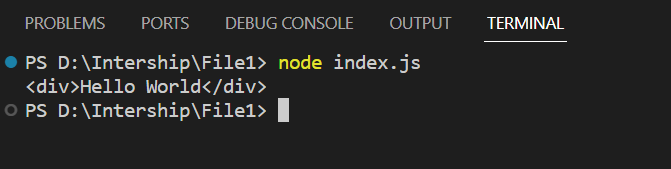
console.log(root.toString());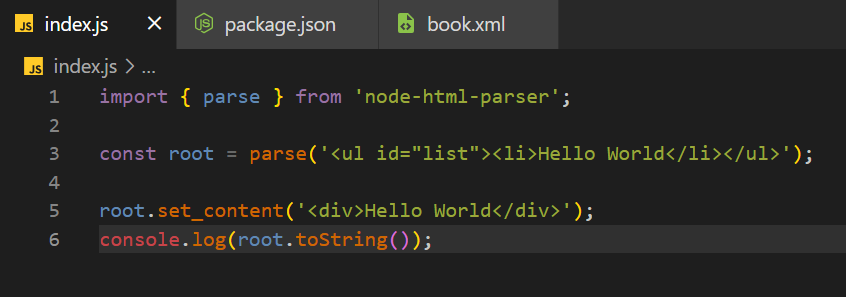
Сначала мы импортируем функцию parse из модуля node-html-parser, а затем используем функцию parse для анализа предоставленной HTML-строки и создания древовидного представления DOM (корня) содержимого HTML.
Затем установите содержимое корневого узла на <div>Hello World</div>. Это эффективно заменяет существующее содержимое корневого узла предоставленной HTML-строкой. Функция root.toString() преобразует измененное дерево DOM (корень) обратно в представление HTML-строки. Наконец, мы регистрируем обновленную HTML-строку в консоли.
Выходные данные:
Заключение
В заключение, node-html-parser - это мощная и универсальная библиотека для синтаксического анализа HTML-документов и манипулирования ими в приложениях Node.js. На протяжении всей этой статьи мы изучали функции и возможности Node HTML Parser, включая его способность анализировать HTML-строки, перемещаться по дереву DOM, извлекать определенные элементы и изменять атрибуты и содержимое.