Парсинг веб-сайтов с помощью pandas и Python с помощью всего нескольких строк кода.

Парсинг веб-сайтов не должен быть сложным, особенно если вы знаете Python.
Динамические веб-сайты можно парсить с помощью таких библиотек, как Selenium, Scrapy и др. Предоставляем вам полное описание библиотек для парсинга сайтов, их преимущества и недостатки в использовании. Простые веб-сайты можно парсить с помощью BeautifulSoup, а сверх простые сайты можно парсить только с помощью pandas.
И нам нужна всего одна или две строки кода, чтобы парсить сайты с pandas.
В этой статье мы собираемся собрать данные из Wikipedia.
Мы извлечем групповые таблицы с чемпионата мира по футболу FIFA 2022. Есть 8 таблиц от группы A до группы H, и мы получим из с помощью нескольких строк кода, используя pandas и Python.
Первое, что необходимо сделать, установить библиотеки и зависимости.
Первым делом мы установим библиотеки pandas и string.
pandas будут использоваться для извлечения данных, а модуль string поможет нам лучше организовать извлеченные данные.
pip install pandas
pip install stringsПримечание: Для веб-сканирования с pandas нам также необходимо установить некоторые зависимости, такие какlxmlиhtml5lib(мы можем установить их с помощью pip).
Парсинг сайта (одной строчкой кода)
Простые веб-сайты, такие как Wikipedia, можно легко парсить с помощью одной или двух строк кода с помощью pandas.
Для этого мы сначала должны импортировать pandas. Затем мы должны использовать метод .read_html и в скобках указать веб-сайт, который мы хотим очистить.
import pandas as pd
all_tables = pd.read_html("https://en.wikipedia.org/wiki/2022_FIFA_World_Cup")И это все. Теперь все страницы на сайте Wikipedia хранятся в списке all_tables.
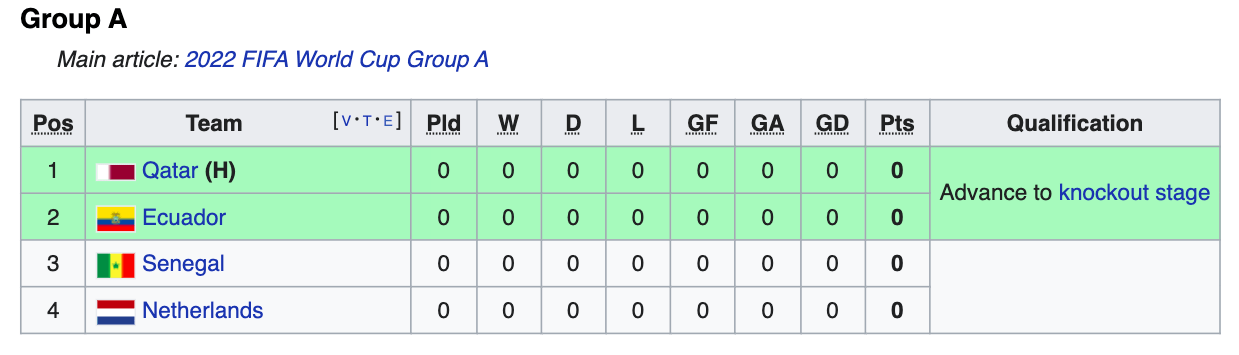
Теперь нам нужно найти таблицы, которые принадлежат группам A, B, …H (всего 8 таблиц). Если мы пройдемся по элементам списка, то увидим, что первая, вторая и третья таблицы находятся в индексах 11, 18 и 25 соответственно.
all_tables[11]
all_tables[18]
all_tables[25]Вот так выглядит таблица группы C (индекс 25).
Организация данных
Если мы пройдемся по индексам списка all_tables, мы обнаружим, что первая таблица имеет индекс 11, а следующие таблицы опережают на 7 индексов.
Мы можем связать все эти индексы с названием каждой группы, используя функцию zip.
for letter, i in zip(alphabet, range(11, 67, 7)):
print(letter, i)Вывод будет следующим:
A 11
B 18
C 25
D 32
E 39
F 46
G 53
H 60Теперь мы знаем, что индекс 11 к группе A, а индекс 60 принадлежит к группе H.
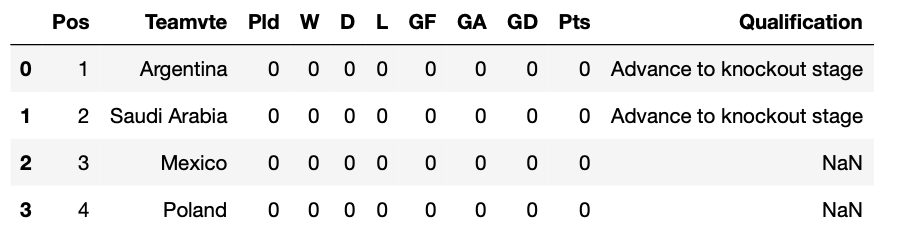
Пришло время лучше организовать таблицы, извлеченные из словаря, чтобы нам больше не приходилось иметь дело с этими индексами. Мы также очистим фреймы данных, переименовав имя второго столбца «Teamvte» и удалив столбец «Qualification».
dict_tables = {}
for letter, i in zip(alphabet, range(11, 67, 7)):
df = all_tables[i]
df.rename(columns={df.columns[1]: 'Team'}, inplace=True)
df.pop('Qualification')
dict_tables[f'Group {letter}'] = dfТеперь у нас есть все таблицы, хранящиеся в словаре dict_tables. Давайте посмотрим
>>> dict_tables.keys()
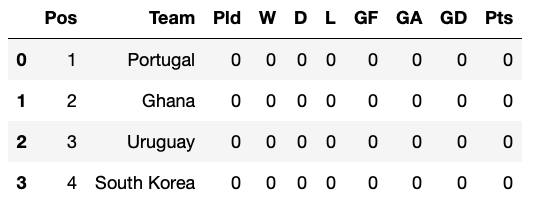
dict_keys(['Group A', 'Group B', 'Group C', 'Group D', 'Group E', 'Group F', 'Group G', 'Group H'])Мы можем получить таблицу любой группы, указав ее ключ. Вот как мы это сделаем для группы H.
dict_tables['Group H']Так выглядит наш результат.
Вы узнали, как парсить сайты с помощью pandas. Вот весь код, который мы написали в этом уроке.
import pandas as pd
from string import ascii_uppercase as alphabet
all_tables = pd.read_html("https://en.wikipedia.org/wiki/2022_FIFA_World_Cup")
dict_tables = {}
for letter, i in zip(alphabet, range(11, 67, 7)):
df = all_tables[i]
df.rename(columns={df.columns[1]: 'Team'}, inplace=True)
df.pop('Qualification')
dict_tables[f'Group {letter}'] = df
# show all the keys
print(dict_tables.keys())
# show table of Group H
dict_tables['Group H']