Понимание потоковой репликации в PostgreSQL
PostgreSQL, продвинутая система управления базами данных с открытым исходным кодом, предлагает различные функции репликации для обеспечения доступности и избыточности данных. Одним из ключевых методов репликации является потоковая репликация, которая обеспечивает синхронную репликацию данных между основным сервером и несколькими резервными серверами. В этом блоге мы углубимся во внутреннюю работу потоковой репликации в PostgreSQL, изучая такие темы, как процесс ее запуска, механизм передачи данных, управление несколькими резервными серверами и обнаружение сбоев. Давайте погрузимся!
Потоковая репликация: Обзор
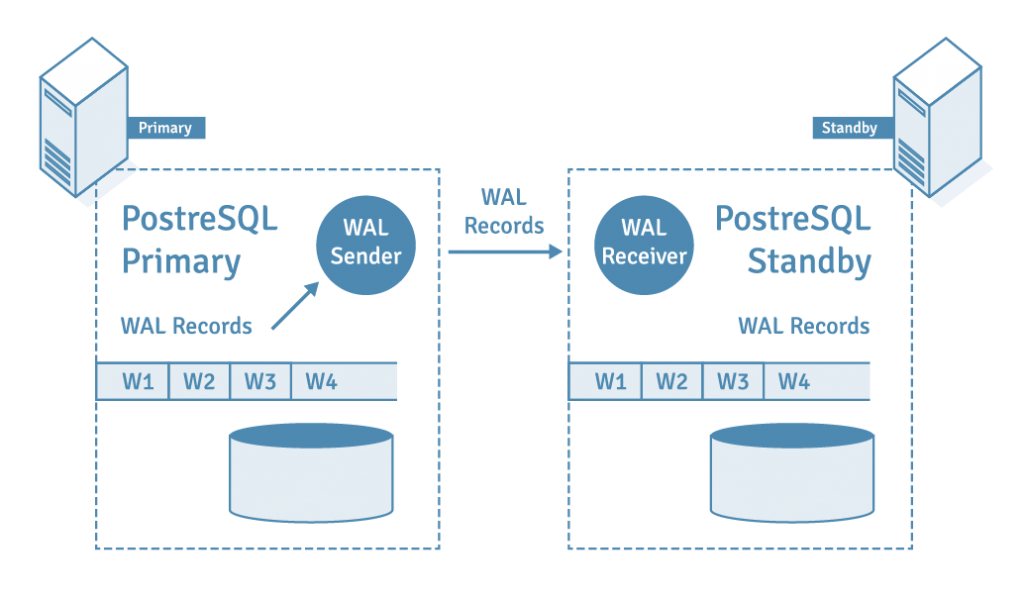
Потоковая репликация (Streaming Replication) в PostgreSQL — это встроенная функция репликации, представленная в версии 9.1. Он работает по архитектуре с одним ведущим и несколькими подчиненными, где основной сервер (также известный как главный) постоянно отправляет данные журнала упреждающей записи (WAL) на резервные серверы (также называемые подчиненными). Затем резервные серверы воспроизводят полученные данные, поддерживая синхронизацию с основным.
Синхронная и асинхронная репликация
До версии 9.1 PostgreSQL поддерживал только асинхронную репликацию. Однако внедрение потоковой репликации обеспечило более надежное решение для синхронной репликации, гарантирующее, что изменения данных реплицируются на резервные серверы в режиме реального времени. Асинхронная репликация по-прежнему доступна, но была заменена более новой реализацией синхронной репликации.
Запуск потоковой репликации
Чтобы понять, как работает потоковая репликация, давайте рассмотрим последовательность запуска и установления соединения между основным и резервным серверами. Следующие шаги описывают этот процесс в общих чертах:
Задействованные процессы
При потоковой репликации три процесса взаимодействуют для облегчения передачи данных: процесс walsender на основном сервере, процесс walreceiver и процесс startup на резервном сервере. Эти процессы взаимодействуют, используя одно TCP-соединение.
Последовательность запуска
Последовательность запуска потоковой репликации разворачивается следующим образом:
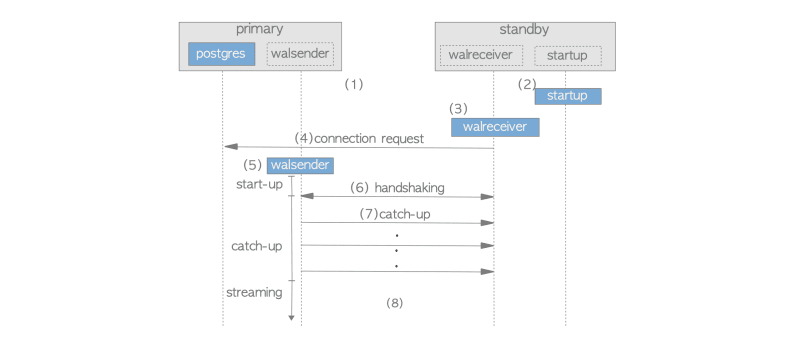
- Запустите основной и резервный серверы.
- Резервный сервер инициирует процесс запуска.
- Резервный сервер запускает процесс walreceiver.
- Walreceiver отправляет запрос на подключение к основному серверу, периодически повторяя попытку, если основной сервер не работает.
- Получив запрос на подключение, основной сервер запускает процесс walsender, устанавливая TCP-соединение с walreceiver.
- Walreceiver отправляет последний порядковый номер журнала (LSN) резервного кластера базы данных, инициируя фазу установления связи.
- Если номер LSN резервного сервера находится за номером LSN основного сервера, walsender отправляет соответствующие данные WAL из каталога сегментов WAL основного сервера (pg_xlog или pg_wal) резервному серверу. Эта фаза наверстывания обеспечивает синхронизацию между основным и резервным.
- Начинается потоковая репликация, а процесс walsender сохраняет состояние, соответствующее рабочей фазе (запуск, наверстывание или потоковая передача).
Связь между основным и синхронным резервным сервером
В потоковой репликации связь между основным сервером и синхронным резервным сервером играет жизненно важную роль. Рассмотрим процесс передачи данных при фиксации транзакции:
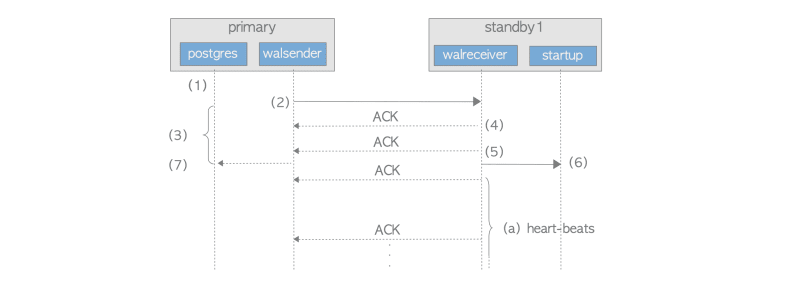
- Бэкенд-процесс на первичном сервере записывает и сбрасывает данные WAL в файл сегмента WAL.
- Процесс walsender отправляет записанные данные WAL процессу walreceiver.
- Бэкенд-процесс ожидает ответа ACK от резервного сервера, получая защелку с помощью SyncRepWaitForLSN().
- Walreceiver записывает полученные данные WAL в сегмент WAL резервного сервера и отправляет ответ ACK walsender.
- Walreceiver сбрасывает данные WAL в сегмент и уведомляет процесс запуска об обновленных данных WAL.
- Startup процесс воспроизводит записанные данные WAL.
- Walsender освобождает защелку внутреннего процесса после получения ответа ACK, завершая действие фиксации или отмены.
Во время этого процесса основной сервер получает ответы ACK от walreceiver, которые содержат такую информацию, как последние записанные, сброшенные и воспроизведенные номера LSN, а также временную отметку ответа. Эти ответы помогают основному серверу контролировать состояние всех подключенных резервных серверов.
Обеспечение восстановления резервного сервера
Что произойдет, если резервный сервер перезапустится после длительного периода остановки? Поведение зависит от версии PostgreSQL:
Версия 9.3 или более ранняя
В более старых версиях, если сегменты WAL основного сервера, необходимые для резервного сервера, уже были переработаны, резервный сервер не может догнать основной сервер. Чтобы устранить эту проблему, можно установить большое значение для параметра конфигурации wal_keep_segments, что уменьшит вероятность возникновения. Однако это решение является лишь временной мерой.
Версия 9.4 или выше
Начиная с версии 9.4, для решения этой проблемы в PostgreSQL появились слоты репликации. Слоты репликации повышают гибкость отправки данных WAL, особенно для логической репликации. Они позволяют сохранять неотправленные файлы сегментов WAL в слоте репликации, приостанавливая процесс повторного использования. Для получения более подробной информации обратитесь к официальной документации.
Обработка сбоев и управление несколькими резервными серверами
В этом разделе мы рассмотрим, как ведет себя основной сервер в случае сбоя синхронного резервного сервера и как осуществляется управление несколькими резервными серверами при потоковой репликации.
Устранение сбоя синхронного резервного сервера
Когда синхронный резервный сервер выходит из строя и не может вернуть ответ ACK, основной сервер продолжает бесконечно ждать ответов. В результате выполняющиеся транзакции не могут быть зафиксированы, а обработка запросов останавливается. Другими словами, все операции основного сервера практически останавливаются. Потоковая репликация не обеспечивает автоматический переход в асинхронный режим по истечении времени ожидания.
Чтобы избежать этой ситуации, есть два подхода. Одним из них является использование нескольких резервных серверов для повышения доступности системы. Другой — вручную переключиться с синхронного на асинхронный режим, выполнив следующие действия:
- Установите пустую строку для параметра
synchronous_standby_names.
synchronous_standby_names = ''- Выполните команду
pg_ctlс параметром перезагрузки.
postgres> pg_ctl -D $PGDATA reloadОписанная выше процедура не влияет на подключенных клиентов. Первичный сервер продолжает обработку транзакций, и все сеансы между клиентами и соответствующими внутренними процессами сохраняются.
Управление несколькими резервными серверами
При потоковой репликации первичный сервер присваивает значения sync_priority и sync_state всем управляемым резервным серверам, обрабатывая каждый резервный сервер на основе этих значений.
sync_priority: указывает приоритет резервного сервера в синхронном режиме и является фиксированным значением. Меньшие значения указывают на более высокий приоритет, а 0 означает "асинхронный режим". Приоритеты резервных серверов назначаются в порядке, указанном в параметре конфигурации основного сервераsynchronous_standby_names. Например, в конфигурацииsynchronous_standby_names = 'standby1, standby2'приоритетыstandby1иstandby2равны 1 и 2 соответственно. Резервные серверы, не указанные в этом параметре, работают в асинхронном режиме с приоритетом 0.sync_state: представляет состояние резервного сервера. Состояние зависит от рабочего состояния всех резервных серверов и их индивидуального приоритета. Возможные состояния следующие:
Sync: состояние синхронного резервного сервера с наивысшим приоритетом среди всех работающих резервных серверов (за исключением асинхронных серверов).Potential: Состояние резервного синхронного резервного сервера со вторым или более низким приоритетом среди всех работающих резервных серверов (за исключением асинхронных серверов). Если синхронный резервный сервер выйдет из строя, он будет заменен резервным сервером с наивысшим приоритетом среди возможных.Async: состояние асинхронного резервного сервера, которое остается фиксированным. Первичный сервер обрабатывает асинхронные резервные серверы так же, как и потенциальные резервные серверы, за исключением того, что ихsync_stateникогда не бывает «Sync» или «Potential».
Чтобы просмотреть приоритет и состояние резервных серверов, вы можете выполнить следующий запрос:
testdb=# SELECT application_name AS host, sync_priority, sync_state FROM pg_stat_replication;
host | sync_priority | sync_state
----------+---------------+------------
standby1 | 1 | Sync
standby2 | 2 | Potential
(2 rows)В приведенном выше примере standby1 имеет приоритет синхронизации 1 и находится в состоянии «Sync», а standby2 имеет приоритет синхронизации 2 и находится в «Potential» состоянии.
Управление основным сервером несколькими резервными серверами
Основной сервер ожидает только ответов ACK от синхронного резервного сервера. Он подтверждает запись и сброс данных WAL только синхронным резервным сервером. Таким образом, потоковая репликация гарантирует, что только синхронный резервный сервер остается в согласованном и синхронном состоянии с основным.
На рис. 3 показан сценарий, в котором ответ ACK от потенциального резервного сервера получен раньше, чем ответ от основного резервного сервера. В этом случае внутренний процесс основного сервера продолжает ожидать ответа ACK от синхронного резервного сервера. После получения ответа основного процесса серверный процесс освобождает защелку и завершает текущую обработку транзакции.
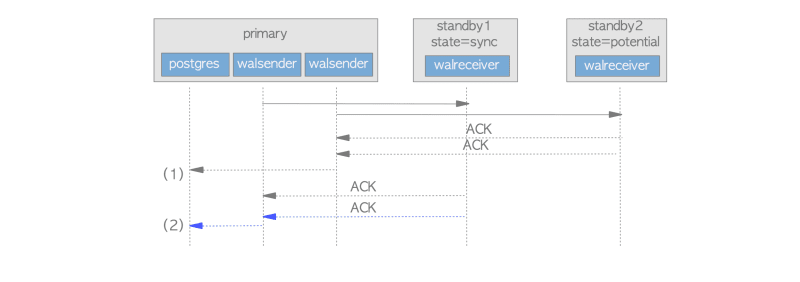
В противоположном сценарии, когда ответ ACK основного сервера получен раньше, чем ответ потенциального резервного сервера, основной сервер немедленно завершает действие фиксации текущей транзакции, не проверяя, записывает ли потенциальный резервный сервер данные WAL и сбрасывает их.
Обработка сбоев резервного сервера и обнаружение сбоев
В этом разделе мы рассмотрим поведение основного сервера при сбое резервного сервера и изучим методы, используемые для обнаружения сбоев при потоковой репликации.
Поведение при сбое резервного сервера
Поведение основного сервера зависит от типа сбоя резервного сервера:
- Сбой потенциального или асинхронного резервного сервера:
Если потенциальный или асинхронный резервный сервер выходит из строя, основной сервер завершает процесс walsender, связанный с отказавшим резервным сервером, и продолжает всю обработку. Другими словами, сбой этих резервных серверов не влияет на обработку транзакций основного сервера. - Сбой синхронного резервного сервера:
Когда синхронный резервный сервер выходит из строя, основной сервер завершает процесс walsender, подключенный к отказавшему резервному серверу, и заменяет его потенциальным резервным сервером с наивысшим приоритетом. Обратитесь к рисунку 4 для визуализации. В отличие от предыдущего сценария, обработка запросов на основном сервере будет приостановлена с момента сбоя до замены синхронного резервного сервера.. Обнаружение отказов резервных серверов играет решающую роль в повышении доступности системы репликации.
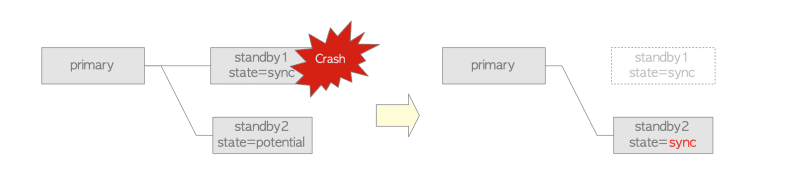
В любом случае, если один или несколько резервных серверов настроены для работы в синхронном режиме, основной сервер всегда поддерживает только один синхронный резервный сервер. Этот синхронный резервный сервер всегда остается в согласованном и синхронном состоянии с основным.
Обнаружение сбоев резервного сервера
- Обнаружение сбоя процесса резервного сервера:
Первичный сервер немедленно идентифицирует неисправный резервный сервер или процесс walreceiver при обнаружении разрыва соединения между walsender и walreceiver. Если низкоуровневая сетевая функция возвращает ошибку из-за сбоя при записи или чтении интерфейса сокета walreceiver, первичный сервер оперативно определяет сбой. - Обнаружение сбоя оборудования и сетей:
Если walreceiver не возвращает никакого ответа в течение времени, заданного параметромwal_sender_timeout(по умолчанию 60 секунд), основной сервер считает резервный сервер неисправным. Однако, в отличие от предыдущего сценария сбоя, может потребоваться некоторое время (доwal_sender_timeoutсекунд), чтобы основной сервер подтвердил сбой резервного. Эта задержка возникает, когда резервный сервер не может отправить какой-либо ответ из-за различных сбоев, таких как проблемы с оборудованием или проблемы с сетью.
В зависимости от характера сбоев, некоторые из них могут быть обнаружены немедленно, в то время как другие могут испытывать временную задержку между возникновением сбоя и его обнаружением. Важно отметить, что если синхронный резервный сервер сталкивается с последним типом сбоя, вся обработка транзакций на основном сервере будет остановлена до тех пор, пока сбой не будет обнаружен, даже если несколько потенциальных резервных серверов работают.
Заключение
В этом блоге мы рассмотрели, как ведет себя основной сервер при различных типах сбоев резервного сервера при потоковой репликации. Кроме того, мы узнали о методах, используемых для обнаружения сбоев в системе репликации. Понимая эти аспекты, вы сможете эффективно справляться со сбоями резервного сервера и обеспечивать доступность и надежность вашей настройки репликации PostgreSQL. В следующем блоге мы рассмотрим более сложные темы, связанные с потоковой репликацией. Быть в курсе! Следите за обновлениями!
Использованная литература:
- Официальная документация PostgreSQL:
https://www.interdb.jp/pg/pgsql11.html - ChatGPT для оптимизации текста и исправления грамматики.