Построение модели ИИ «текст-видео» с нуля с помощью Python

Sora от OpenAI, Stable Video Diffusion от Stability AI и многие другие модели преобразования текста в видео, которые уже появились или появятся в будущем, являются одними из самых популярных трендов ИИ в 2024 году, следуя за большими языковыми моделями (LLM). В этом блоге мы построим небольшую модель преобразования текста в видео с нуля. Мы будем вводить текстовую подсказку, а наша обученная модель будет генерировать видео на основе этой подсказки. В этом блоге мы рассмотрим все: от понимания теоретических концепций до кодирования всей архитектуры и генерации конечного результата.
Поскольку у меня нет навороченного GPU, я закодировал небольшую архитектуру. Вот сравнение времени, необходимого для обучения модели на разных процессорах:
| Обучающие видео | Эпохи | CPU | GPU A10 | GPU T4 |
| 10000 | 30 | более 3 часов | 1 час | 1 час 42 мин |
| 30000 | 30 | более 6 часов | 1 час 30 мин | 2 часа 30 мин |
| 100000 | 30 | — | 3–4 часа | 5–6 часов |
Обучение модели на CPU, очевидно, займет гораздо больше времени. Если вам нужно быстро протестировать изменения в коде и увидеть результаты, CPU — не лучший выбор. Я рекомендую использовать GPU T4 от Colab или Kaggle для более эффективного и быстрого обучения.
Чтобы не копировать и не вставлять код из этого блога, вот репозиторий GitHub, содержащий файл блокнота со всем кодом и информацией.
А вот ссылка на блог, в котором рассказывается о том, как создать Stable Diffusion с нуля.
Что же мы создаём?
Мы будем придерживаться подхода, схожего с традиционными моделями машинного обучения или глубокого обучения, которые тренируются на наборе данных, а затем тестируются на невидимых данных. В контексте преобразования текста в видео, допустим, у нас есть обучающая база данных, состоящая из 100 000 видеороликов, на которых собаки ловят мячи, а кошки гоняются за мышами. Мы обучим нашу модель генерировать видео, на которых кошка ловит мяч или собака гонится за мышью.
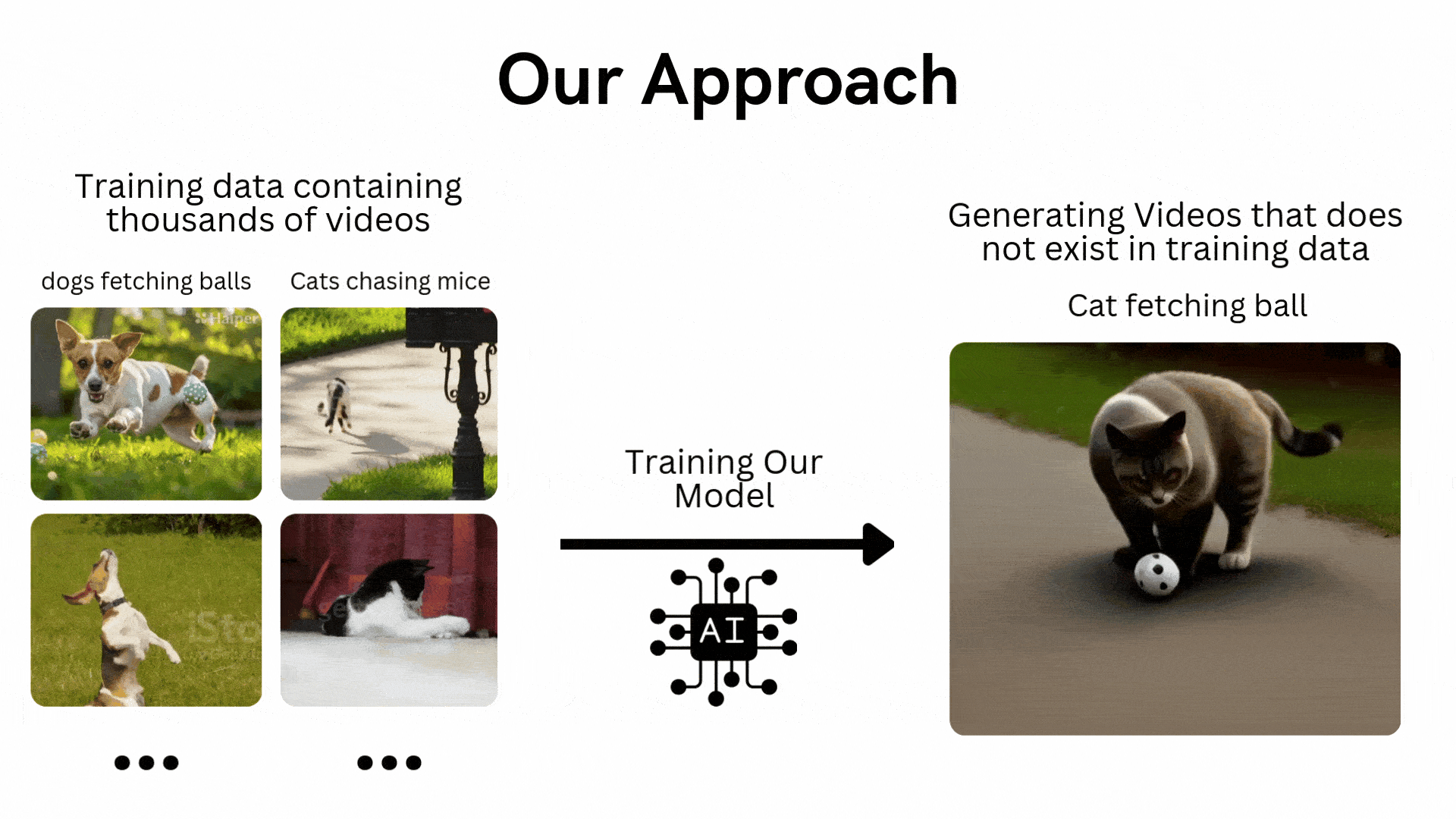
Хотя такие обучающие наборы данных легко доступны в Интернете, требуемая вычислительная мощность чрезвычайно высока. Поэтому мы будем работать с набором видеоданных о движущихся объектах, сгенерированных из кода Python.
Для создания модели мы будем использовать архитектуру GAN (Generative Adversarial Networks), а не диффузионную модель, которую использует OpenAI Sora. Я попытался использовать диффузионную модель, но она потерпела крах из-за требований к памяти, которые мне не по силам. С другой стороны, GAN легче и быстрее обучать и тестировать.
Предварительные требования
Мы будем использовать ООП (объектно-ориентированное программирование), поэтому вы должны иметь базовое представление о нем, а также о нейронных сетях. Знание GAN (Generative Adversarial Networks) не является обязательным, поскольку здесь мы будем рассматривать их архитектуру.
Приведу несколько ссылок на обучающие видео по темам, которые нам понадобятся:
- Объектно-ориентированное программирование
- Теория нейросетей
- Архитектура генеративной адверсарной сети (GAN)
- Основы Python
Понимание архитектуры GAN
Понимание GAN очень важно, поскольку от него зависит многое в нашей архитектуре. Давайте узнаем, что это такое, каковы его компоненты и многое другое.
Что такое GAN?
Генеративная адверсарная сеть (GAN) — это модель глубокого обучения, в которой соревнуются две нейронные сети: одна создает новые данные (например, изображения или музыку) из заданного набора данных, а другая пытается определить, являются ли эти данные настоящими или поддельными. Этот процесс продолжается до тех пор, пока сгенерированные данные не станут неотличимы от реальных.
Применение в реальной жизни
- Генерация изображений: GAN создает реалистичные изображения на основе текстовых подсказок или изменяет существующие изображения, например, повышает разрешение или добавляет цвет к черно-белым фотографиям.
- Дополнение данных: GAN генерирует синтетические данные для обучения других моделей машинного обучения, например, создает данные о мошеннических транзакциях для систем обнаружения мошенничества.
- Восполнение недостающей информации: GAN может заполнять недостающие данные, например, генерировать изображения подповерхностного слоя на основе карт местности для энергетических приложений.
- Генерация 3D-моделей: GAN преобразует 2D-изображения в 3D-модели, что полезно в таких областях, как, например, здравоохранение, для создания реалистичных изображений органов при планировании хирургических операций.
Как работает GAN?
GAN состоит из двух глубоких нейронных сетей: генератора и дискриминатора. Эти сети обучаются вместе в условиях состязательности, когда одна генерирует новые данные, а другая оценивает, являются ли эти данные настоящими или поддельными.
Вот упрощенный обзор того, как работает GAN:
- Анализ обучающего набора: Генератор анализирует обучающий набор для определения атрибутов данных, а дискриминатор самостоятельно анализирует те же данные для изучения их атрибутов.
- Модификация данных: Генератор добавляет шум (случайные изменения) к некоторым атрибутам данных.
- Передача данных: Измененные данные передаются дискриминатору.
- Вычисление вероятности: Дискриминатор вычисляет вероятность того, что сгенерированные данные относятся к исходному набору данных.
- Цикл обратной связи: Дискриминатор обеспечивает обратную связь с генератором, направляя его на уменьшение случайного шума в следующем цикле.
- Адверсарное обучение: Генератор пытается максимизировать ошибки дискриминатора, а дискриминатор - минимизировать свои собственные ошибки. В ходе множественных итераций обучения обе сети совершенствуются и развиваются.
- Состояние равновесия: Обучение продолжается до тех пор, пока дискриминатор не перестанет отличать реальные данные от искусственно сгенерированных, что свидетельствует о том, что генератор успешно научился создавать реалистичные данные. На этом процесс обучения завершен.
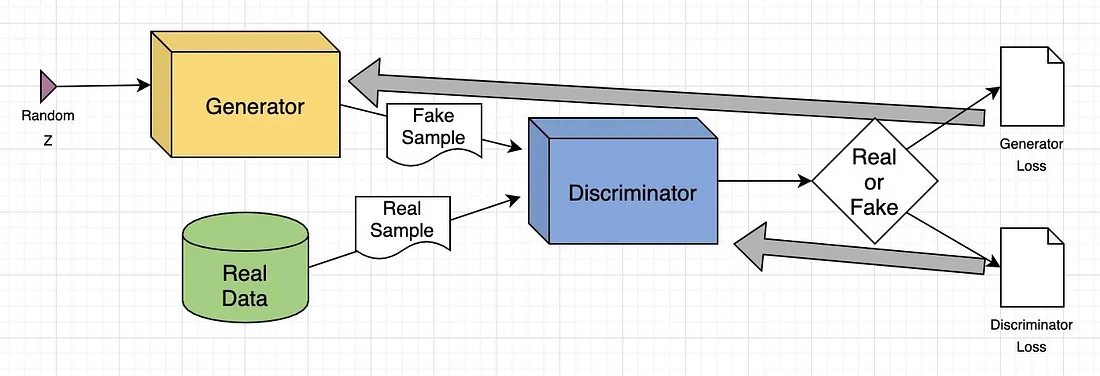
Пример обучения GAN
Поясним модель GAN на примере перевода с изображения на изображение, сосредоточившись на изменении человеческого лица.
- Входное изображение: В качестве входного изображения используется реальное изображение человеческого лица.
- Модификация атрибутов: Генератор изменяет атрибуты лица, например добавляет солнцезащитные очки на глаза.
- Генерация изображений: Генератор создает набор изображений с добавленными солнечными очками.
- Задача дискриминатора: Дискриминатор получает смесь реальных изображений (люди в солнцезащитных очках) и сгенерированных изображений (лица, на которые были добавлены солнцезащитные очки).
- Оценка: Дискриминатор пытается отличить реальные изображения от сгенерированных.
- Цикл обратной связи: Если дискриминатор правильно определяет поддельные изображения, генератор изменяет свои параметры, чтобы получить более убедительные изображения. Если генератор успешно обманывает дискриминатор, он обновляет свои параметры, чтобы улучшить обнаружение.
В ходе этого состязательного процесса обе сети постоянно совершенствуются. Генератор всё лучше создает реалистичные изображения, а дискриминатор всё лучше определяет подделки, пока не достигается равновесие, когда дискриминатор уже не может отличить реальные изображения от сгенерированных. В этот момент GAN успешно научается создавать реалистичные модификации.
Создание базы
Мы будем работать с рядом библиотек Python, давайте их импортируем.
# Operating System module for interacting with the operating system
import os
# Module for generating random numbers
import random
# Module for numerical operations
import numpy as np
# OpenCV library for image processing
import cv2
# Python Imaging Library for image processing
from PIL import Image, ImageDraw, ImageFont
# PyTorch library for deep learning
import torch
# Dataset class for creating custom datasets in PyTorch
from torch.utils.data import Dataset
# Module for image transformations
import torchvision.transforms as transforms
# Neural network module in PyTorch
import torch.nn as nn
# Optimization algorithms in PyTorch
import torch.optim as optim
# Function for padding sequences in PyTorch
from torch.nn.utils.rnn import pad_sequence
# Function for saving images in PyTorch
from torchvision.utils import save_image
# Module for plotting graphs and images
import matplotlib.pyplot as plt
# Module for displaying rich content in IPython environments
from IPython.display import clear_output, display, HTML
# Module for encoding and decoding binary data to text
import base64Теперь, когда мы импортировали все наши библиотеки, следующим шагом будет определение обучающих данных, которые мы будем использовать для обучения нашей архитектуры GAN.
Кодирование обучающих данных
В качестве обучающих данных нам необходимо иметь не менее 10000 видеороликов. Почему? Потому что я тестировал с меньшим количеством, и результаты были очень плохими, практически ничего не было видно. Следующий важный вопрос: о чём эти видео? Наш набор обучающих видео состоит из круга, движущегося в разных направлениях с различными механизмами. Так что давайте закодируем его и сгенерируем 10000 видео, чтобы посмотреть, как это выглядит.
# Create a directory named 'training_dataset'
os.makedirs('training_dataset', exist_ok=True)
# Define the number of videos to generate for the dataset
num_videos = 10000
# Define the number of frames per video (1 Second Video)
frames_per_video = 10
# Define the size of each image in the dataset
img_size = (64, 64)
# Define the size of the shapes (Circle)
shape_size = 10После настройки некоторых основных параметров нам необходимо определить текстовые подсказки нашего обучающего набора данных, на основе которых будут создаваться обучающие видеоролики.
# Define text prompts and corresponding movements for circles
prompts_and_movements = [
("circle moving down", "circle", "down"), # Move circle downward
("circle moving left", "circle", "left"), # Move circle leftward
("circle moving right", "circle", "right"), # Move circle rightward
("circle moving diagonally up-right", "circle", "diagonal_up_right"), # Move circle diagonally up-right
("circle moving diagonally down-left", "circle", "diagonal_down_left"), # Move circle diagonally down-left
("circle moving diagonally up-left", "circle", "diagonal_up_left"), # Move circle diagonally up-left
("circle moving diagonally down-right", "circle", "diagonal_down_right"), # Move circle diagonally down-right
("circle rotating clockwise", "circle", "rotate_clockwise"), # Rotate circle clockwise
("circle rotating counter-clockwise", "circle", "rotate_counter_clockwise"), # Rotate circle counter-clockwise
("circle shrinking", "circle", "shrink"), # Shrink circle
("circle expanding", "circle", "expand"), # Expand circle
("circle bouncing vertically", "circle", "bounce_vertical"), # Bounce circle vertically
("circle bouncing horizontally", "circle", "bounce_horizontal"), # Bounce circle horizontally
("circle zigzagging vertically", "circle", "zigzag_vertical"), # Zigzag circle vertically
("circle zigzagging horizontally", "circle", "zigzag_horizontal"), # Zigzag circle horizontally
("circle moving up-left", "circle", "up_left"), # Move circle up-left
("circle moving down-right", "circle", "down_right"), # Move circle down-right
("circle moving down-left", "circle", "down_left"), # Move circle down-left
]Мы определили несколько движений нашего круга с помощью этих подсказок. Теперь нам нужно составить математические уравнения для перемещения круга в соответствии с подсказками.
# Define function with parameters
def create_image_with_moving_shape(size, frame_num, shape, direction):
# Create a new RGB image with specified size and white background
img = Image.new('RGB', size, color=(255, 255, 255))
# Create a drawing context for the image
draw = ImageDraw.Draw(img)
# Calculate the center coordinates of the image
center_x, center_y = size[0] // 2, size[1] // 2
# Initialize position with center for all movements
position = (center_x, center_y)
# Define a dictionary mapping directions to their respective position adjustments or image transformations
direction_map = {
# Adjust position downwards based on frame number
"down": (0, frame_num * 5 % size[1]),
# Adjust position to the left based on frame number
"left": (-frame_num * 5 % size[0], 0),
# Adjust position to the right based on frame number
"right": (frame_num * 5 % size[0], 0),
# Adjust position diagonally up and to the right
"diagonal_up_right": (frame_num * 5 % size[0], -frame_num * 5 % size[1]),
# Adjust position diagonally down and to the left
"diagonal_down_left": (-frame_num * 5 % size[0], frame_num * 5 % size[1]),
# Adjust position diagonally up and to the left
"diagonal_up_left": (-frame_num * 5 % size[0], -frame_num * 5 % size[1]),
# Adjust position diagonally down and to the right
"diagonal_down_right": (frame_num * 5 % size[0], frame_num * 5 % size[1]),
# Rotate the image clockwise based on frame number
"rotate_clockwise": img.rotate(frame_num * 10 % 360, center=(center_x, center_y), fillcolor=(255, 255, 255)),
# Rotate the image counter-clockwise based on frame number
"rotate_counter_clockwise": img.rotate(-frame_num * 10 % 360, center=(center_x, center_y), fillcolor=(255, 255, 255)),
# Adjust position for a bouncing effect vertically
"bounce_vertical": (0, center_y - abs(frame_num * 5 % size[1] - center_y)),
# Adjust position for a bouncing effect horizontally
"bounce_horizontal": (center_x - abs(frame_num * 5 % size[0] - center_x), 0),
# Adjust position for a zigzag effect vertically
"zigzag_vertical": (0, center_y - frame_num * 5 % size[1]) if frame_num % 2 == 0 else (0, center_y + frame_num * 5 % size[1]),
# Adjust position for a zigzag effect horizontally
"zigzag_horizontal": (center_x - frame_num * 5 % size[0], center_y) if frame_num % 2 == 0 else (center_x + frame_num * 5 % size[0], center_y),
# Adjust position upwards and to the right based on frame number
"up_right": (frame_num * 5 % size[0], -frame_num * 5 % size[1]),
# Adjust position upwards and to the left based on frame number
"up_left": (-frame_num * 5 % size[0], -frame_num * 5 % size[1]),
# Adjust position downwards and to the right based on frame number
"down_right": (frame_num * 5 % size[0], frame_num * 5 % size[1]),
# Adjust position downwards and to the left based on frame number
"down_left": (-frame_num * 5 % size[0], frame_num * 5 % size[1])
}
# Check if direction is in the direction map
if direction in direction_map:
# Check if the direction maps to a position adjustment
if isinstance(direction_map[direction], tuple):
# Update position based on the adjustment
position = tuple(np.add(position, direction_map[direction]))
else: # If the direction maps to an image transformation
# Update the image based on the transformation
img = direction_map[direction]
# Return the image as a numpy array
return np.array(img)Функция выше используется для перемещения нашего круга для каждого кадра в зависимости от выбранного направления. Нам просто нужно запустить цикл поверх неё до количества видеороликов, чтобы сгенерировать все видео.
# Iterate over the number of videos to generate
for i in range(num_videos):
# Randomly choose a prompt and movement from the predefined list
prompt, shape, direction = random.choice(prompts_and_movements)
# Create a directory for the current video
video_dir = f'training_dataset/video_{i}'
os.makedirs(video_dir, exist_ok=True)
# Write the chosen prompt to a text file in the video directory
with open(f'{video_dir}/prompt.txt', 'w') as f:
f.write(prompt)
# Generate frames for the current video
for frame_num in range(frames_per_video):
# Create an image with a moving shape based on the current frame number, shape, and direction
img = create_image_with_moving_shape(img_size, frame_num, shape, direction)
# Save the generated image as a PNG file in the video directory
cv2.imwrite(f'{video_dir}/frame_{frame_num}.png', img)После выполнения приведенного выше кода будет сгенерирован весь наш обучающий набор данных. Вот как выглядит структура файлов нашего обучающего набора данных.
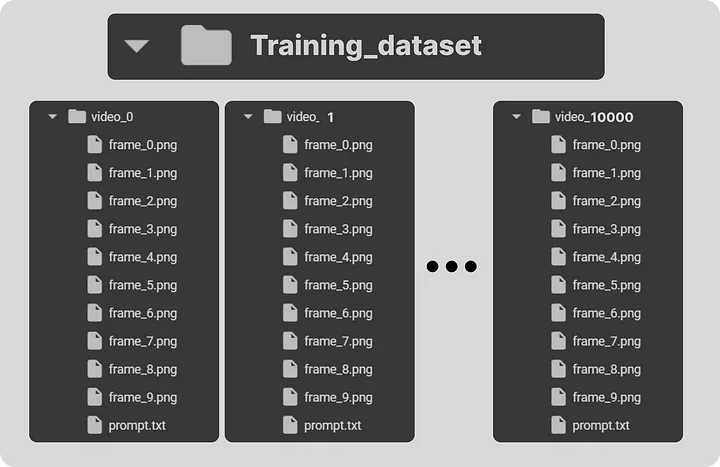
Каждая папка с обучающим видео содержит кадры и текстовую подсказку. Давайте посмотрим на образец нашего обучающего набора данных.
В нашем обучающем наборе данных мы не включили движение круга вверх, а затем вправо. Мы будем использовать его в качестве тестового, чтобы оценить нашу обученную модель на невидимых данных.
Еще один важный момент, который следует отметить, – это то, что наши обучающие данные содержат много примеров, когда объекты удаляются от сцены или частично появляются перед камерой, что похоже на то, что мы наблюдали в демонстрационных видео OpenAI Sora.

Причина включения таких образцов в наши обучающие данные заключается в том, чтобы проверить, может ли наша модель сохранять согласованность, когда круг входит в сцену из самого угла, не нарушая своей формы.
Теперь, когда обучающие данные сгенерированы, нам необходимо преобразовать обучающие видео в тензоры, которые являются основным типом данных, используемых во фреймворках глубокого обучения, таких как PyTorch. Кроме того, такие преобразования, как нормализация, помогают улучшить сходимость и стабильность обучающей архитектуры за счет масштабирования данных в меньший диапазон.
Предварительная обработка обучающих данных
Нам нужно написать класс датасета для задач "текст-видео", который может считывать видеокадры и соответствующие им текстовые подсказки из каталога обучающего датасета, делая их доступными для использования в PyTorch.
# Define a dataset class inheriting from torch.utils.data.Dataset
class TextToVideoDataset(Dataset):
def __init__(self, root_dir, transform=None):
# Initialize the dataset with root directory and optional transform
self.root_dir = root_dir
self.transform = transform
# List all subdirectories in the root directory
self.video_dirs = [os.path.join(root_dir, d) for d in os.listdir(root_dir) if os.path.isdir(os.path.join(root_dir, d))]
# Initialize lists to store frame paths and corresponding prompts
self.frame_paths = []
self.prompts = []
# Loop through each video directory
for video_dir in self.video_dirs:
# List all PNG files in the video directory and store their paths
frames = [os.path.join(video_dir, f) for f in os.listdir(video_dir) if f.endswith('.png')]
self.frame_paths.extend(frames)
# Read the prompt text file in the video directory and store its content
with open(os.path.join(video_dir, 'prompt.txt'), 'r') as f:
prompt = f.read().strip()
# Repeat the prompt for each frame in the video and store in prompts list
self.prompts.extend([prompt] * len(frames))
# Return the total number of samples in the dataset
def __len__(self):
return len(self.frame_paths)
# Retrieve a sample from the dataset given an index
def __getitem__(self, idx):
# Get the path of the frame corresponding to the given index
frame_path = self.frame_paths[idx]
# Open the image using PIL (Python Imaging Library)
image = Image.open(frame_path)
# Get the prompt corresponding to the given index
prompt = self.prompts[idx]
# Apply transformation if specified
if self.transform:
image = self.transform(image)
# Return the transformed image and the prompt
return image, promptПрежде чем приступить к кодированию архитектуры, нам необходимо нормализовать наши обучающие данные. Мы будем использовать размер партии 16 и перемешивать данные, чтобы внести больше случайности.
# Define a set of transformations to be applied to the data
transform = transforms.Compose([
transforms.ToTensor(), # Convert PIL Image or numpy.ndarray to tensor
transforms.Normalize((0.5,), (0.5,)) # Normalize image with mean and standard deviation
])
# Load the dataset using the defined transform
dataset = TextToVideoDataset(root_dir='training_dataset', transform=transform)
# Create a dataloader to iterate over the dataset
dataloader = torch.utils.data.DataLoader(dataset, batch_size=16, shuffle=True)Реализация слоя вставки текста
Вы могли видеть в архитектуре трансформатора, где отправной точкой является преобразование нашего текстового ввода в эмбеддинг для дальнейшей обработки в мультиголовом внимании, аналогично здесь мы должны закодировать слой эмбеддинга текста, на основе которого будет происходить обучение архитектуры GAN на наших данных эмбеддинга и тензоре изображений.
# Define a class for text embedding
class TextEmbedding(nn.Module):
# Constructor method with vocab_size and embed_size parameters
def __init__(self, vocab_size, embed_size):
# Call the superclass constructor
super(TextEmbedding, self).__init__()
# Initialize embedding layer
self.embedding = nn.Embedding(vocab_size, embed_size)
# Define the forward pass method
def forward(self, x):
# Return embedded representation of input
return self.embedding(x)Размер словаря будет основан на наших обучающих данных, которые мы рассчитаем позже. Размер вставки будет равен 10. Если вы работаете с большим набором данных, вы также можете выбрать модель встраивания, доступную на Hugging Face.
Реализация слоя генератора
Теперь, когда мы уже знаем, что делает генератор в GAN, давайте закодируем этот слой, а затем разберемся в его содержимом.
class Generator(nn.Module):
def __init__(self, text_embed_size):
super(Generator, self).__init__()
# Fully connected layer that takes noise and text embedding as input
self.fc1 = nn.Linear(100 + text_embed_size, 256 * 8 * 8)
# Transposed convolutional layers to upsample the input
self.deconv1 = nn.ConvTranspose2d(256, 128, 4, 2, 1)
self.deconv2 = nn.ConvTranspose2d(128, 64, 4, 2, 1)
self.deconv3 = nn.ConvTranspose2d(64, 3, 4, 2, 1) # Output has 3 channels for RGB images
# Activation functions
self.relu = nn.ReLU(True) # ReLU activation function
self.tanh = nn.Tanh() # Tanh activation function for final output
def forward(self, noise, text_embed):
# Concatenate noise and text embedding along the channel dimension
x = torch.cat((noise, text_embed), dim=1)
# Fully connected layer followed by reshaping to 4D tensor
x = self.fc1(x).view(-1, 256, 8, 8)
# Upsampling through transposed convolution layers with ReLU activation
x = self.relu(self.deconv1(x))
x = self.relu(self.deconv2(x))
# Final layer with Tanh activation to ensure output values are between -1 and 1 (for images)
x = self.tanh(self.deconv3(x))
return xЭтот класс Generator отвечает за создание видеокадров из комбинации случайного шума и текстовых вкраплений. Его целью является создание реалистичных видеокадров на основе заданных текстовых описаний. Сеть начинается с полностью связанного слоя (nn.Linear), который объединяет вектор шума и текстовые вкрапления в один вектор признаков. Затем этот вектор перестраивается и проходит через серию транспонированных конволюционных слоев (nn.ConvTranspose2d), которые постепенно увеличивают карты признаков до желаемого размера видеокадра.
Слои используют активации ReLU (nn.ReLU) для нелинейности, а последний слой использует активацию Tanh (nn.Tanh) для масштабирования выходных данных в диапазоне [-1, 1]. Таким образом, генератор преобразует абстрактный, высокоразмерный входной сигнал в связные видеокадры, которые визуально представляют входной текст.
Реализация слоя дискриминатора
После кодирования слоя генератора нам нужно реализовать вторую половину — часть дискриминатора.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# Convolutional layers to process input images
self.conv1 = nn.Conv2d(3, 64, 4, 2, 1) # 3 input channels (RGB), 64 output channels, kernel size 4x4, stride 2, padding 1
self.conv2 = nn.Conv2d(64, 128, 4, 2, 1) # 64 input channels, 128 output channels, kernel size 4x4, stride 2, padding 1
self.conv3 = nn.Conv2d(128, 256, 4, 2, 1) # 128 input channels, 256 output channels, kernel size 4x4, stride 2, padding 1
# Fully connected layer for classification
self.fc1 = nn.Linear(256 * 8 * 8, 1) # Input size 256x8x8 (output size of last convolution), output size 1 (binary classification)
# Activation functions
self.leaky_relu = nn.LeakyReLU(0.2, inplace=True) # Leaky ReLU activation with negative slope 0.2
self.sigmoid = nn.Sigmoid() # Sigmoid activation for final output (probability)
def forward(self, input):
# Pass input through convolutional layers with LeakyReLU activation
x = self.leaky_relu(self.conv1(input))
x = self.leaky_relu(self.conv2(x))
x = self.leaky_relu(self.conv3(x))
# Flatten the output of convolutional layers
x = x.view(-1, 256 * 8 * 8)
# Pass through fully connected layer with Sigmoid activation for binary classification
x = self.sigmoid(self.fc1(x))
return xКласс Discriminator работает как бинарный классификатор, различающий реальные и сгенерированные видеокадры. Его задача - оценивать подлинность видеокадров, тем самым направляя генератор на создание более реалистичных результатов. Сеть состоит из конволюционных слоев (nn.Conv2d), которые извлекают иерархические признаки из входных видеокадров, а активации Leaky ReLU (nn.LeakyReLU) добавляют нелинейность, обеспечивая небольшой градиент для отрицательных значений. Затем карты признаков сглаживаются и проходят через слой с полным подключением (nn.Linear), в результате чего формируется сигмоидальная активация (nn.Sigmoid), которая выдает оценку вероятности, указывающую на то, является ли кадр настоящим или поддельным.
Обучая дискриминатор точной классификации кадров, генератор одновременно обучается создавать более убедительные видеокадры, поскольку стремится обмануть дискриминатор.
Кодирование параметров обучения
Нам необходимо настроить базовые компоненты для обучения GAN, такие как функция потерь, оптимизатор и другие.
# Check for GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Create a simple vocabulary for text prompts
all_prompts = [prompt for prompt, _, _ in prompts_and_movements] # Extract all prompts from prompts_and_movements list
vocab = {word: idx for idx, word in enumerate(set(" ".join(all_prompts).split()))} # Create a vocabulary dictionary where each unique word is assigned an index
vocab_size = len(vocab) # Size of the vocabulary
embed_size = 10 # Size of the text embedding vector
def encode_text(prompt):
# Encode a given prompt into a tensor of indices using the vocabulary
return torch.tensor([vocab[word] for word in prompt.split()])
# Initialize models, loss function, and optimizers
text_embedding = TextEmbedding(vocab_size, embed_size).to(device) # Initialize TextEmbedding model with vocab_size and embed_size
netG = Generator(embed_size).to(device) # Initialize Generator model with embed_size
netD = Discriminator().to(device) # Initialize Discriminator model
criterion = nn.BCELoss().to(device) # Binary Cross Entropy loss function
optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999)) # Adam optimizer for Discriminator
optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999)) # Adam optimizer for GeneratorЭто та часть, где мы должны преобразовать наш код для работы на GPU, если таковой имеется. Мы написали код для нахождения размера vocab_size, и мы используем оптимизатор ADAM для генератора и дискриминатора. При желании вы можете выбрать свой собственный оптимизатор. Здесь мы установили скорость обучения на небольшое значение 0,0002, а размер вставки – 10, что гораздо меньше по сравнению с другими моделями Hugging Face, доступными для публичного использования.
Кодирование цикла обучения
Как и в случае с любой другой нейронной сетью, мы будем кодировать обучение архитектуры GAN аналогичным образом.
# Number of epochs
num_epochs = 13
# Iterate over each epoch
for epoch in range(num_epochs):
# Iterate over each batch of data
for i, (data, prompts) in enumerate(dataloader):
# Move real data to device
real_data = data.to(device)
# Convert prompts to list
prompts = [prompt for prompt in prompts]
# Update Discriminator
netD.zero_grad() # Zero the gradients of the Discriminator
batch_size = real_data.size(0) # Get the batch size
labels = torch.ones(batch_size, 1).to(device) # Create labels for real data (ones)
output = netD(real_data) # Forward pass real data through Discriminator
lossD_real = criterion(output, labels) # Calculate loss on real data
lossD_real.backward() # Backward pass to calculate gradients
# Generate fake data
noise = torch.randn(batch_size, 100).to(device) # Generate random noise
text_embeds = torch.stack([text_embedding(encode_text(prompt).to(device)).mean(dim=0) for prompt in prompts]) # Encode prompts into text embeddings
fake_data = netG(noise, text_embeds) # Generate fake data from noise and text embeddings
labels = torch.zeros(batch_size, 1).to(device) # Create labels for fake data (zeros)
output = netD(fake_data.detach()) # Forward pass fake data through Discriminator (detach to avoid gradients flowing back to Generator)
lossD_fake = criterion(output, labels) # Calculate loss on fake data
lossD_fake.backward() # Backward pass to calculate gradients
optimizerD.step() # Update Discriminator parameters
# Update Generator
netG.zero_grad() # Zero the gradients of the Generator
labels = torch.ones(batch_size, 1).to(device) # Create labels for fake data (ones) to fool Discriminator
output = netD(fake_data) # Forward pass fake data (now updated) through Discriminator
lossG = criterion(output, labels) # Calculate loss for Generator based on Discriminator's response
lossG.backward() # Backward pass to calculate gradients
optimizerG.step() # Update Generator parameters
# Print epoch information
print(f"Epoch [{epoch + 1}/{num_epochs}] Loss D: {lossD_real + lossD_fake}, Loss G: {lossG}")С помощью обратного распространения наши потери будут скорректированы как для генератора, так и для дискриминатора. Мы использовали 13 эпох для цикла обучения. Я тестировал разные значения, но результаты не показывают большой разницы, если количество эпох превышает это значение. Более того, велик риск столкнуться с чрезмерной подгонкой. Если бы у нас был более разнообразный набор данных с большим количеством движений и форм, мы могли бы рассмотреть возможность использования более высоких эпох, но не в этом случае.
Когда мы запускаем этот код, он начинает обучение и выводит потери для генератора и дискриминатора после каждой эпохи.
## OUTPUT ##
Epoch [1/13] Loss D: 0.8798642754554749, Loss G: 1.300612449645996
Epoch [2/13] Loss D: 0.8235711455345154, Loss G: 1.3729925155639648
Epoch [3/13] Loss D: 0.6098687052726746, Loss G: 1.3266581296920776
...Сохранение обученной модели
После завершения обучения нам нужно сохранить дискриминатор и генератор нашей обученной архитектуры GAN, что можно сделать с помощью всего двух строк кода.
# Save the Generator model's state dictionary to a file named 'generator.pth'
torch.save(netG.state_dict(), 'generator.pth')
# Save the Discriminator model's state dictionary to a file named 'discriminator.pth'
torch.save(netD.state_dict(), 'discriminator.pth')Генерация видео с искусственным интеллектом
Как мы уже говорили, наш подход к тестированию модели на невидимых данных сопоставим с примером, в котором наши обучающие данные включают собак, ловящих мячи, и кошек, гоняющихся за мышами. Поэтому в качестве тестовых подсказок могут использоваться сценарии, например, когда кошка ловит мяч или собака гонится за мышью.
В нашем конкретном случае движение, при котором круг движется вверх, а затем вправо, отсутствует в наших обучающих данных, поэтому модель не знакома с этим специфическим движением. Однако она была обучена другим движениям. Мы можем использовать это движение в качестве подсказки, чтобы проверить нашу обученную модель и понаблюдать за ее работой.
# Inference function to generate a video based on a given text prompt
def generate_video(text_prompt, num_frames=10):
# Create a directory for the generated video frames based on the text prompt
os.makedirs(f'generated_video_{text_prompt.replace(" ", "_")}', exist_ok=True)
# Encode the text prompt into a text embedding tensor
text_embed = text_embedding(encode_text(text_prompt).to(device)).mean(dim=0).unsqueeze(0)
# Generate frames for the video
for frame_num in range(num_frames):
# Generate random noise
noise = torch.randn(1, 100).to(device)
# Generate a fake frame using the Generator network
with torch.no_grad():
fake_frame = netG(noise, text_embed)
# Save the generated fake frame as an image file
save_image(fake_frame, f'generated_video_{text_prompt.replace(" ", "_")}/frame_{frame_num}.png')
# usage of the generate_video function with a specific text prompt
generate_video('circle moving up-right')Когда мы запустим приведенный выше код, он создаст каталог, содержащий все кадры нашего сгенерированного видео. Нам нужно использовать небольшой код, чтобы объединить все эти кадры в одно короткое видео.
# Define the path to your folder containing the PNG frames
folder_path = 'generated_video_circle_moving_up-right'
# Get the list of all PNG files in the folder
image_files = [f for f in os.listdir(folder_path) if f.endswith('.png')]
# Sort the images by name (assuming they are numbered sequentially)
image_files.sort()
# Create a list to store the frames
frames = []
# Read each image and append it to the frames list
for image_file in image_files:
image_path = os.path.join(folder_path, image_file)
frame = cv2.imread(image_path)
frames.append(frame)
# Convert the frames list to a numpy array for easier processing
frames = np.array(frames)
# Define the frame rate (frames per second)
fps = 10
# Create a video writer object
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('generated_video.avi', fourcc, fps, (frames[0].shape[1], frames[0].shape[0]))
# Write each frame to the video
for frame in frames:
out.write(frame)
# Release the video writer
out.release()Убедитесь, что путь к папке указывает на место, где находится созданное видео. После выполнения этого кода ваше AI-видео будет успешно создано. Давайте посмотрим, как оно выглядит.
Я проводил обучение несколько раз с одинаковым количеством эпох. В обоих случаях круг начинает движение с нижней половины. Хорошо то, что наша модель попыталась выполнить движение вверх-вправо в обоих случаях. Например, в попытке 1 круг двигался по диагонали вверх, а затем выполнял движение вверх, а в попытке 2 круг двигался по диагонали, уменьшаясь в размерах. Ни в одном из случаев круг не сдвинулся влево и не исчез полностью, что является хорошим знаком.
Чего не хватает?
Я протестировал различные аспекты этой архитектуры и пришел к выводу, что ключевую роль играют обучающие данные. Включив в набор данных больше движений и форм, можно увеличить вариативность и повысить производительность модели. Поскольку данные генерируются с помощью кода, создание более разнообразных данных не займет много времени; вместо этого вы сможете сосредоточиться на совершенствовании логики.
Кроме того, архитектура GAN, рассмотренная в этом блоге, относительно проста. Вы можете усложнить ее, интегрировав передовые методы или используя встраивание языковой модели (LLM) вместо базового встраивания нейронной сети. Кроме того, настройка таких параметров, как размер вставки и других, может существенно повлиять на эффективность модели.
Благодарю за прочтение!
Источник доступен по ссылке.