Практический аудит качества данных: Всеобъемлющее руководство

Изучение того, как использовать экосистему Python для аудита качества данных.
Вы не можете управлять тем, что не можете измерить — Питер Друкер
Аудит качества данных - незаменимый навык в нашем быстро развивающемся мире, наделенном возможностями искусственного интеллекта. Точно так же, как сырая нефть нуждается в переработке, данные также требуют очистки и обработки, чтобы быть полезными. Старая пословица “мусор внутрь, мусор наружу” остается столь же актуальной сегодня, как и на заре развития вычислительной техники.
В этой статье мы рассмотрим, как Python может помочь нам обеспечить соответствие наших наборов данных стандартам качества для успешных проектов. Мы углубимся в библиотеки Python, фрагменты кода и примеры, которые вы можете использовать в своих рабочих процессах.
Оглавление:
- Понимание качества данных и их измерений
- Проверка данных с помощью Pydantic и pandas_dq
- Сравнение Pydantic и pandas_dq
- Изучение точности и последовательности
- Аудит качества данных с помощью pandas_dq
- Вывод
Аудит качества данных
Прежде чем углубляться в инструменты и методы, давайте сначала рассмотрим концепцию качества данных. Согласно общепринятому отраслевому определению, качество данных относится к степени, в которой набор данных является точным, полным, своевременным, валидным, уникальным по атрибутам идентификатора и непротиворечивым.
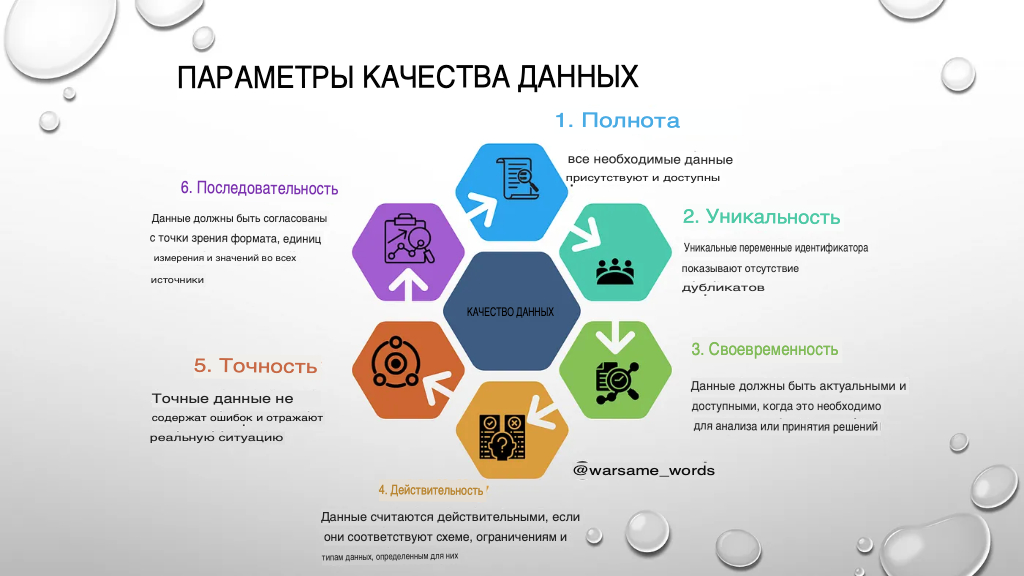
Полнота
Полнота качества данных подразумевает наличие всех жизненно важных элементов данных, необходимых для достижения конкретной цели. Возьмем, к примеру, базу данных клиентов, разработанную для маркетинговых целей; она считалась бы неполной, если бы для определенных клиентов отсутствовала необходимая контактная информация, такая как номера телефонов или адреса электронной почты.
Чтобы обеспечить полноту данных, организации могут использовать методы профилирования данных.
Профилирование данных — это систематическое изучение и оценка наборов данных для выявления закономерностей, несоответствий и аномалий.
Тщательно изучая данные, можно выявить пробелы, особенности или недостающие значения, что позволяет принять корректирующие меры, такие как поиск недостающей информации или внедрение надежных процессов проверки данных. В результате получается более надежный, полный и действенный набор данных, который позволяет принимать более эффективные решения, оптимизировать маркетинговые усилия и, в конечном счете, способствовать успеху бизнеса.
Но перед тщательным профилированием данных первым шагом в любом аудите качества данных является просмотр словаря данных: краткого описательного справочника, который определяет структуру, атрибуты и взаимосвязи элементов данных в наборе данных, служащего руководством для понимания и интерпретации значения и назначения данных.
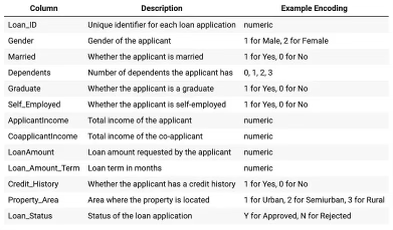
После тщательного просмотра или создания словаря данных оценка полноты становится легкой задачей, если вы используете возможности библиотек с низким кодом, таких как Sweetviz, Missingno или Pandas_DQ.
import missingno as msno
import sweetviz as sv
from pandas_dq import dq_report
# completeness check
msno.matrix(df)
# data profiling
Report = sv.analyze(df)
Report.show_notebook()Лично я тяготею к комбинации Pandas-Matplotlib-Seaborn, поскольку она обеспечивает мне гибкость, позволяющую полностью контролировать мои выходные данные. Таким образом, я могу создать увлекательный и визуально привлекательный анализ.
# check for missing values
import seaborn as sns
import matplotlib.pyplot as plt
def plot_missing_values(df: pd.DataFrame,
title="Missing Values Plot"):
plt.figure(figsize=(10, 6))
sns.displot(
data=df.isna().melt(value_name="missing"),
y="variable",
hue="missing",
multiple="fill",
aspect=1.25
)
plt.title(title)
plt.show()
plot_missing_values(df)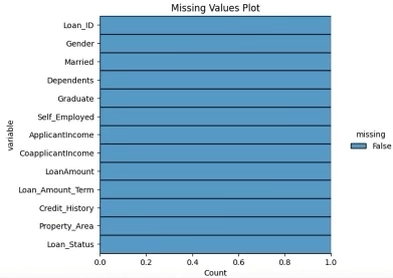
Уникальность
Уникальность - это измерение качества данных, которое подчеркивает отсутствие повторяющихся данных в столбцах с ограничением уникальности. Каждая запись должна представлять уникальную сущность без избыточности. Например, список пользователей должен иметь уникальные идентификаторы для каждого зарегистрированного пользователя; несколько записей с одинаковым идентификатором указывают на отсутствие уникальности.
В приведенном ниже примере я имитирую этап интеграции данных, заключающийся в объединении двух идентично структурированных наборов данных. Аргумент функции Pandas concat verify_integrity выдает ошибку, если уникальность нарушена:
# verify integrity check
df_loans = pd.concat([df, df_pdf], verify_integrity=True)
# check duplicated ids
df_loans[df_loans.duplicated(keep=False)].sort_index()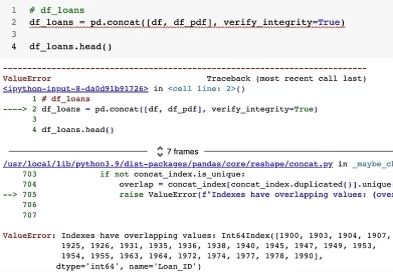
В идеале вы должны проверить наличие дублирования в рамках аудита качества ваших данных.
def check_duplicates(df, col):
'''
Check how many duplicates are in col.
'''
# first step set index
df_check = df.set_index(col)
count = df_check.index.duplicated().sum()
del df_check
print("There are {} duplicates in {}".format(count, col))Своевременность
Своевременность — это аспект качества данных, который фокусируется на доступности и частоте данных. Актуальные и легкодоступные данные необходимы для точного анализа и принятия решений. Например, своевременный отчет о продажах должен включать самые свежие данные, а не только данные за несколько месяцев до этого. Набор данных, который мы использовали до сих пор для примеров, не имеет временного измерения, чтобы мы могли более глубоко изучить каденцию.
Допустимость
При переходе к концепции достоверности следует признать ее роль в обеспечении соответствия данных установленным правилам, форматам и стандартам. Валидность гарантирует соответствие схеме, ограничениям и типам данных, назначенным для набора данных. Для этого мы можем использовать мощную библиотеку Python Pydantic:
# data validation on the data dictionary
from pydantic import BaseModel, Field, conint, condecimal, constr
class LoanApplication(BaseModel):
Loan_ID: int
Gender: conint(ge=1, le=2)
Married: conint(ge=0, le=1)
Dependents: conint(ge=0, le=3)
Graduate: conint(ge=0, le=1)
Self_Employed: conint(ge=0, le=1)
ApplicantIncome: condecimal(ge=0)
CoapplicantIncome: condecimal(ge=0)
LoanAmount: condecimal(ge=0)
Loan_Amount_Term: condecimal(ge=0)
Credit_History: conint(ge=0, le=1)
Property_Area: conint(ge=1, le=3)
Loan_Status: constr(regex="^[YN]$")
# Sample loan application data
loan_application_data = {
"Loan_ID": 123456,
"Gender": 1,
"Married": 1,
"Dependents": 2,
"Graduate": 1,
"Self_Employed": 0,
"ApplicantIncome": 5000,
"CoapplicantIncome": 2000,
"LoanAmount": 100000,
"Loan_Amount_Term": 360,
"Credit_History": 1,
"Property_Area": 2,
"Loan_Status": "Y"
}
# Validate the data using the LoanApplication Pydantic model
loan_application = LoanApplication(**loan_application_data)После тестирования на примере мы можем запустить весь набор данных через проверку проверки, которая в случае успеха должна вывести “проблем с проверкой данных нет”:
# data validation on the data dictionary
from pydantic import ValidationError
from typing import List
# Function to validate DataFrame and return a list of failed LoanApplication objects
def validate_loan_applications(df: pd.DataFrame) -> List[LoanApplication]:
failed_applications = []
for index, row in df.iterrows():
row_dict = row.to_dict()
try:
loan_application = LoanApplication(**row_dict)
except ValidationError as e:
print(f"Validation failed for row {index}: {e}")
failed_applications.append(row_dict)
return failed_applications
# Validate the entire DataFrame
failed_applications = validate_loan_applications(df_loans.reset_index())
# Print the failed loan applications or "No data quality issues"
if not failed_applications:
print("No data validation issues")
else:
for application in failed_applications:
print(f"Failed application: {application}")Мы можем сделать то же самое с pandas_dq, используя гораздо меньше кода:
from pandas_dq import DataSchemaChecker
schema = {
'Loan_ID': 'int64',
'Gender': 'int64',
'Married': 'int64',
'Dependents': 'int64',
'Graduate': 'int64',
'Self_Employed': 'int64',
'ApplicantIncome': 'float64',
'CoapplicantIncome': 'float64',
'LoanAmount': 'float64',
'Loan_Amount_Term': 'float64',
'Credit_History': 'int64',
'Property_Area': 'int64',
'Loan_Status': 'object'
}
checker = DataSchemaChecker(schema)
checker.fit(df_loans.reset_index())Это возвращает удобный для чтения отчет в стиле фрейма данных Pandas, в котором подробно описываются все возникающие проблемы с проверкой. Я предоставил неправильную схему, в которой сообщалось, что переменные int64 являются переменными float64. Библиотека правильно идентифицировала эти:
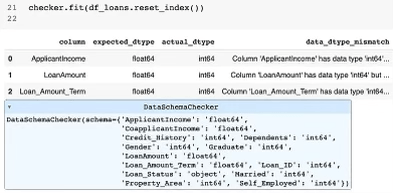
Несоответствие типов данных устраняется одной строкой кода с использованием объекта проверки, созданного из класса DataSchemaChecker:
# fix issues
df_fixed = checker.transform(df_loans.reset_index())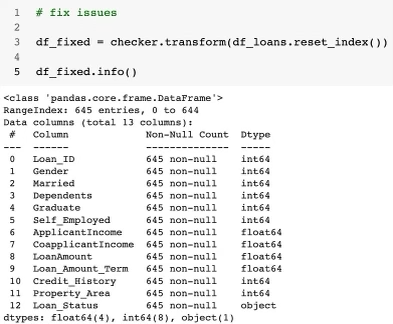
Pydantic или pandas_dq?
Есть некоторые различия между Pydantic и pandas_dq:
- Декларативный синтаксис: возможно, Pydantic позволяет вам определять схему данных и правила проверки, используя более краткий и читаемый синтаксис. Это может облегчить понимание и поддержку вашего кода. Я нахожу очень полезным иметь возможность определять диапазоны возможных значений, а не просто тип данных.
- Встроенные функции проверки: Pydantic предоставляет различные мощные встроенные функции проверки, такие как
conint,condecimalиconstr, которые позволяют вам применять ограничения к вашим данным без необходимости написания пользовательских функций проверки. - Комплексная обработка ошибок: При использовании Pydantic, если входные данные не соответствуют определенной схеме, возникает
ValidationErrorс подробной информацией об ошибках. Это может помочь вам легко выявить проблемы с вашими данными и предпринять необходимые действия. - Сериализация и десериализация: Pydantic автоматически обрабатывает сериализацию и десериализацию данных, что делает удобной работу с различными форматами данных (например, JSON) и преобразование между ними.
В заключение, Pydantic предлагает более лаконичный, многофункциональный и удобный подход к проверке данных по сравнению с классом DataSchemaChecker из pandas_dq.
Pydantic, вероятно, является лучшим выбором для проверки вашей схемы данных в производственной среде. Но если вы просто хотите быстро приступить к работе с прототипом, вы можете предпочесть низкокодовую природу DataSchemaChecker.
Точность и согласованность
Есть еще 2 аспекта качества данных, которые мы до сих пор не изучали:
- Точность - это измерение качества данных, которое учитывает корректность данных, гарантируя, что они отражают реальные ситуации без ошибок. Например, точная база данных клиентов должна содержать правильные и актуальные адреса всех клиентов.
- Согласованность связана с единообразием данных из различных источников или наборов данных внутри организации. Данные должны быть согласованы с точки зрения формата, единиц измерения и значений. Например, многонациональная компания должна представлять данные о доходах в единой валюте, чтобы поддерживать согласованность в своих офисах в разных странах.
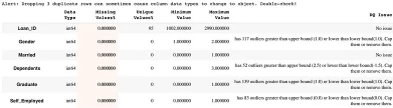
Вы можете проверить все проблемы с качеством данных, присутствующие в наборе данных, с помощью функции dq_report:
from pandas_dq import dq_report
dq_report(df_loans.reset_index(), target=None, verbose=1)Он обнаруживает следующие проблемы с качеством данных:
- Сильно связанные переменные (мультиколлинеарность)
- Столбцы без отклонений (избыточные функции)
- Асимметричное распределение данных (аномалии, выбросы и т.д.)
- Нечастые случаи в категории
Вывод
Проведение аудита качества данных имеет решающее значение для поддержания высококачественных наборов данных, что, в свою очередь, способствует более эффективному принятию решений и успеху бизнеса. Python предлагает множество библиотек и инструментов, которые делают процесс аудита более доступным и эффективным.
Понимая и применяя концепции и методы, рассмотренные в этой статье, вы будете хорошо подготовлены к тому, чтобы ваши наборы данных соответствовали необходимым стандартам качества для ваших проектов.
Ссылка на полный код: https://github.com/mohwarsame273/Medium-Articles/blob/main/DataQualityAudit.ipynb