Практическое руководство по обнаружению объектов в видео за 5 шагов

Методы обнаружения объектов являются сегодня тенденцией в области компьютерного зрения. Есть много методов, которые используются для обнаружения объектов в изображениях сцены и видео. Каждый из этих методов имеет свои преимущества и ограничения с точки зрения ресурсов и времени выполнения. Обнаружение объектов в видео также требует много технических знаний и ресурсов.
Таким образом, всегда есть поиск простого и быстрого метода обнаружения объекта. В этой статье мы покажем, как обнаружить объекты, видимые в видео, всего за 5 шагов. В этой задаче мы будем использовать библиотеку pixellib, которая обнаруживает объекты с помощью сегментации экземпляра. Мы также будем использовать предварительно обученную модель Mask R-CNN для идентификации объектов, видимых на видео. В этой реализации мы будем обнаруживать объекты транспортных средств в дорожном видео.
Сегментация экземпляра
Сегментация экземпляров - это метод компьютерного зрения, который используется для обнаружения объектов с использованием метода сегментации изображений. Он идентифицирует каждый экземпляр объектов, присутствующих в изображениях или видео на уровне пикселей. В сегментации изображения визуальный ввод разделяется на сегменты для представления объекта или части объектов путем формирования набора пикселей. Сегментация экземпляров идентифицирует каждый экземпляр каждого объекта, представленного в изображении, вместо категоризации каждого пикселя, как при семантической сегментации.
Mask R-CNN
Mask R-CNN - это вариант Deep Neural Network, предложенный Kaiming He и др. В Facebook AI Research. Эта модель используется для решения проблемы сегментации экземпляра объекта в компьютерном зрении. Он обнаруживает объекты на изображении, одновременно генерируя высококачественную маску сегментации для каждого экземпляра. Это расширение Faster R-CNN путем добавления ветви для предсказания маски объекта параллельно существующей ветви для распознавания ограничивающего прямоугольника. Структура mask R-CNN для сегментации экземпляра приведена ниже.
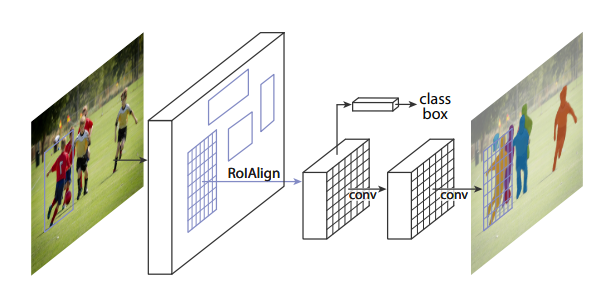
Реализация
Теперь мы обсудим шаги, с помощью которых мы будем обнаруживать объекты в видео.
1. Установите библиотеку и зависимости
На первом этапе нам нужно установить библиотеку pixellib и ее зависимости
pip install pixellib
2. Загрузите предварительно обученные веса Mask-RCNN.
Поскольку мы будем использовать модель Mask R-CNN для обнаружения объектов, мы будем загружать предварительно обученные веса.
wget --quiet https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5
3. Импорт библиотек
Теперь мы импортируем установленную библиотеку pixellib. Мы также импортируем класс instance_segmentation, потому что мы собираемся обнаружить объекты, используя метод сегментации экземпляра.
import pixellib
from pixellib.instance import instance_segmentation
4. Создание экземпляра модели сегментации и загрузка весов Mask-RCNN.
На этом шаге мы создадим экземпляр класса сегментации экземпляра, предоставляемого pixellib, и загрузим модель Mask R-CNN с предварительно подготовленными весами.
segment_video = instance_segmentation()
segment_video.load_model("mask_rcnn_coco.h5")
5. Обнаружить объекты
На этом этапе мы обработаем задачу обнаружения объекта с помощью маски R-CNN в видео. Используется случайное видео трафика, в котором мы хотим обнаружить объекты транспортного средства.
В этом методе мы устанавливаем количество кадров в секунду, то есть количество кадров в секунду, которое будет иметь выходное видео.
segment_video.process_video("traffic_vid2.mp4", show_bboxes = True, frames_per_second= 15, output_video_name="object_detect.mp4")




Наконец, мы получим выходное видео в рабочем каталоге. Время в этом процессе зависит от длины и размера видео. Вы должны использовать графический процессор для повышения скорости обработки. Для вышеупомянутого видео о трафике мы получили следующее видео с обнаруженными объектами.
Вы можете определить функцию для получения видео с YouTube и передачи их непосредственно вышеупомянутой функции. Таким образом, используя описанные выше шаги, мы могли бы обсудить очень простой способ реализации задачи обнаружения объектов в видео. Человек с очень маленьким знанием глубокого обучения и компьютерного зрения может обнаружить объекты с помощью этого способа.