Превращение текста в разговор на AWS: полифоническая симфония S3, Lambda и Amazon Polly

🎉Дорогие читатели, добро пожаловать в грандиозную оркестровку цифровой эпохи, где мы отправим вас в увлекательное путешествие из мира текста в симфонический мир произнесенных слов. В этом технологическом шедевре мы рассмотрим, как динамический квартет AWS S3, Lambda и Amazon Polly 📦🔗🧬🗣️ объединяется, чтобы превратить простой текст в аудио. Итак, будьте готовы быть ошеломленными, когда мы разгадаем «Превращение текста в разговор на AWS: Поллифоническая симфония S3, Lambda и Amazon Polly». 🎶 Это шоу, которое вы не захотите пропустить! 🚀 Приятного обучения!!
Итак, давайте теперь погрузимся в практический мир!!
Введение
В этом блоге мы собираемся разработать рабочий процесс, который сможет автоматически конвертировать текстовый файл любой расшифровки в аудиофайл MP3 без какого-либо ручного вмешательства.
Функциональный поток
Если вы видите на приведенной выше диаграмме рабочего процесса, она объясняет, как обрабатывается файл, и вы получаете желаемый файл MP3. Ниже приведены общие этапы рабочего процесса:
- Файл загружается в корзину S3. Назовем его здесь как
text2talk-source-transcript-bucket - Срабатывает уведомление о событии S3, настроенное для сегмента
text2talk-source-transcript-bucket. - Целью уведомления о событии S3 является функция Lambda (назовем ее «text2talk», которую мы будем использовать для преобразования файла текстовой расшифровки, загруженного в корзину S3 text2audio-source-transcript-bucket
- Лямбда-функция получит текст из файла расшифровки и отправит содержимое в Amazon Polly, который отправит обратно данные, преобразованные в форму данных аудиофайла.
- Аудиофайл наконец будет загружен в другую корзину S3. Давайте назовем это здесь как
text2talk-target-audio-bucket.
Построение системы
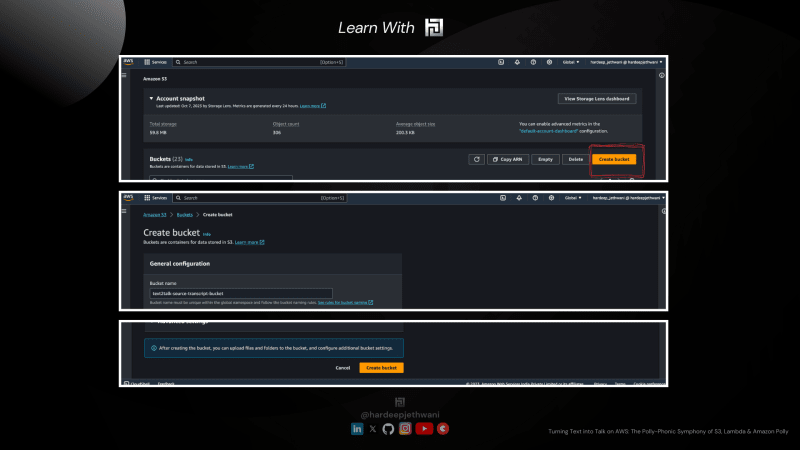
Создание сегментов S3
- Войдите в консоль AWS
- Перейдите на панель управления сервисом S3 и нажмите «Создать сегмент».
- Вы попадете на страницу, где вам нужно будет ввести имя корзины S3 по вашему выбору (здесь я использовал
text2talk-source-transcript-bucketкорзину, которая будет использоваться для текстовых файлов расшифровки, иtext2talk-target-audio-bucketкорзину, которая будет использоваться для экспорта аудио).
Важное примечание: Имена корзин S3 должны быть глобально уникальными. Если имя недоступно, вы можете соответственно использовать другое имя. - Выберите регион по вашему выбору, оставив остальную информацию как есть, и нажмите «Создать кнопку».
- Выполните одни и те же шаги для исходного и целевого сегментов, и будут созданы сегменты, которые вы можете найти на панели управления S3
Настройка лямбда-функции
- В нашем случае лямбда-функция будет обращаться к корзине S3, чтобы извлечь файл расшифровки, а также отправить аудиофайл!
- Кроме того, функция Lambda будет использовать «Синтез речи», предоставляемый Amazon Polly.
- Итак, в этом случае наша лямбда-функция должна иметь соответствующие разрешения на доступ к корзине S3 и вызовам API Polly!
- Поэтому сначала мы создадим роль IAM, которую позже нужно будет назначить функции Lambda.
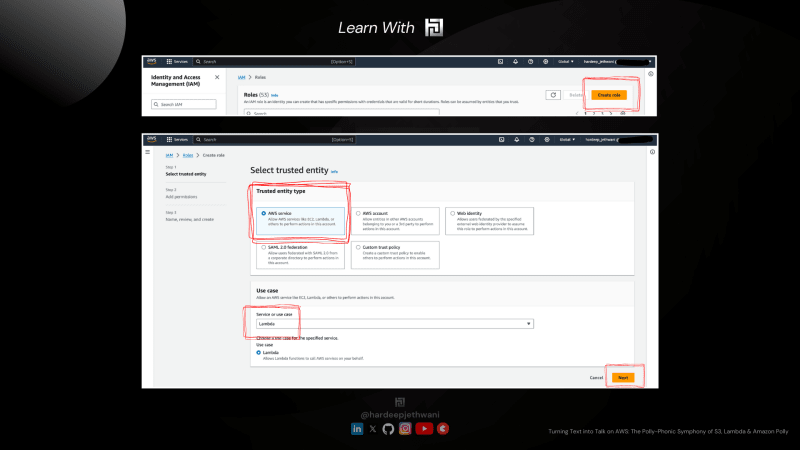
Создание роли IAM
- Перейдите к службе IAM и перейдите в раздел «Роли», чтобы создать роль.
- Нажмите «Создать роль».
- Вы попадете на страницу создания роли IAM, на которой показаны 3 шага:
- Выбор доверенного удостоверения. Мы создаем эту роль для прикрепления к сервису AWS, т. е. к Lambda здесь. Поэтому мы выберем «AWS Lambda» в доверенных типах объектов. В качестве варианта использования мы выберем «Лямбда».
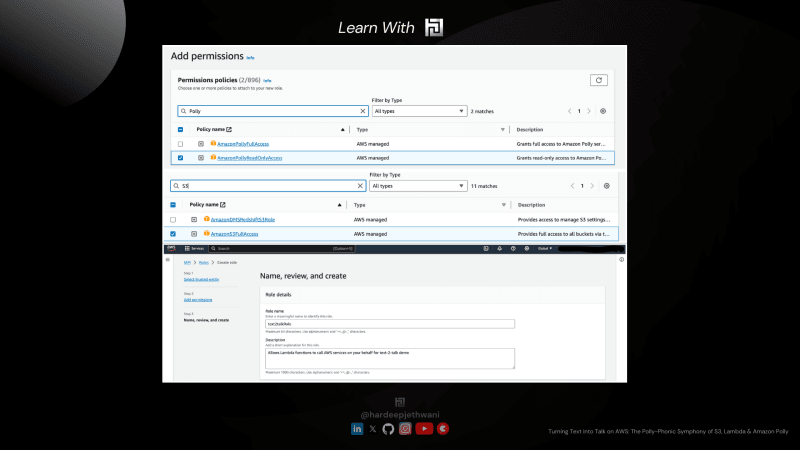
- Добавление разрешений: мы добавим политики AWS MAnaged к нашей роли с именами «AmazonPollyReadOnlyAccess» и «AmazonS3FullAccess», что позволит нашей Lambda выполнять соответствующие операции.
- Имя, просмотр и создание. На заключительном этапе вы можете добавить имя для своей роли (здесь
text2talkRole). Просмотрите разрешения и создайте роль.
Итак, теперь, когда мы создали роль IAM в соответствии с нашими потребностями, мы наконец приступим к созданию нашей функции Lambda.
Создание лямбда-функции
- Перейдите в сервис AWS Lambda в консоли AWS.
- Нажмите кнопку «Создать функцию». Вы попадете на страницу создания Lambda.
- Выберите следующие параметры: Автор с нуля, поскольку мы собираемся написать код нашей лямбда-функции. Выберите Python 3.11 в качестве среды выполнения лямбда (вы также можете использовать любую другую среду выполнения, но потребуются соответствующие изменения кода).
- Автор с нуля, поскольку мы собираемся написать код нашей лямбда-функции.
- Имя как
text2talk - Выберите Python 3.11 в качестве среды выполнения лямбда (вы также можете использовать любую другую среду выполнения, но потребуются соответствующие изменения кода)
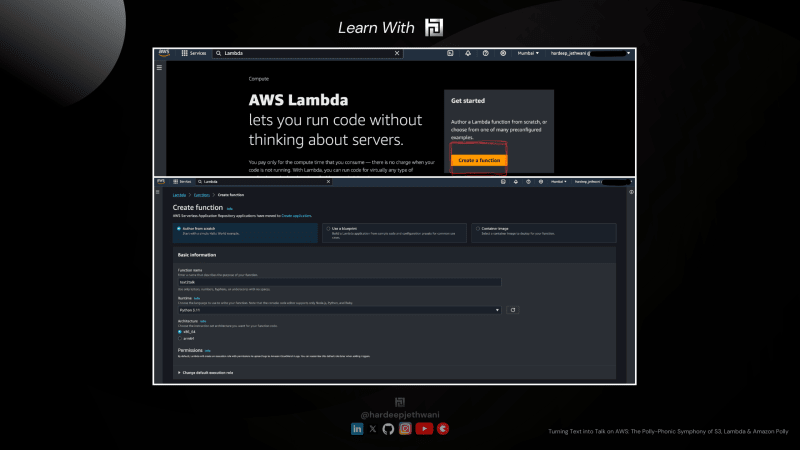
- Разверните «Изменить роль выполнения по умолчанию». Выберите «Использовать существующую роль», а затем выберите роль IAM, которую мы создали.
- Нажмите «Создать функцию», и ваша необработанная функция Lamda будет создана.
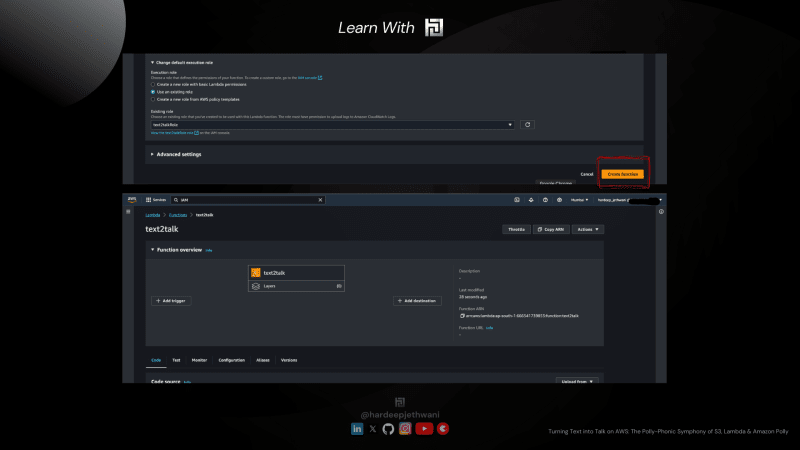
Подождите, ребята, работа еще не закончена, собственно кайф ниже!!!
- Нам нужно использовать приведенный ниже код Python, вставить его в нашу консоль Lambda и нажать «Развернуть».
- Итак, эта лямбда-функция, написанная на Python, создает
S3 client, используяboto3библиотеку. Затем клиент S3 используется для извлечения файла из исходной корзины S3. - ВАЖНО: здесь нет необходимости жестко запрограммировать имя корзины Source S3, поскольку позже мы собираемся настроить уведомление о событии S3, которое затем будет запускать функцию Lambda. Таким образом, объект Event будет содержать все сведения о сегменте и объекте, которые были загружены на S3.
- Однако нам необходимо жестко запрограммировать имя целевого сегмента (обновите имя сегмента в соответствии с именем, которое вы использовали).
- Эта функция Python также создает клиентский объект для работы с polly (
polly_client). Мы используемsynthesize_speechвызов Polly, где передаем аудиоформат, текстовый формат и параметры голосового идентификатора. - Мы передали параметр Voice ID как «Salli», но вы можете поиграть с разными голосами и обратиться к блогу Amazon Polly Voice List.
Код AWS Lambda Python
import json
import boto3
import datetime
# Get the current timestamp
current_time = datetime.datetime.now()
# Format the timestamp as "ddmmyy"
timestamp = current_time.strftime("%d%m%y")
# Initialize AWS clients
s3_client = boto3.client('s3')
polly_client = boto3.client('polly')
def lambda_handler(event, context):
# Define the source and destination S3 bucket and file names
source_bucket = str(event["Records"][0]['s3']['bucket']['name']) #These are the details received from the S3 Event and we are gathering bucket name and File name of the same
source_file_key = str(event["Records"][0]['s3']['object']['key'])
destination_bucket = 'text2talk-target-audio-bucket' ## Update the target bucket name accordingly as per bucket name in your account
destination_file_key = f"{timestamp}-audio.mp3"
# Fetch the text content from the source S3 bucket
try:
response = s3_client.get_object(Bucket=source_bucket, Key=source_file_key)
text = response['Body'].read().decode('utf-8')
except Exception as e:
print(str(e))
return {
'statusCode': 500,
'body': f'Error fetching text from S3: {str(e)}'
}
# Use Amazon Polly to synthesize speech from the text
try:
response = polly_client.synthesize_speech(
OutputFormat='mp3',
Text=text,
VoiceId='Salli' # You can choose a different voice IDs too
)
audio_data = response['AudioStream'].read()
except Exception as e:
print(str(e))
return {
'statusCode': 500,
'body': f'Error synthesizing speech with Polly: {str(e)}'
}
# Upload the MP3 audio to the destination S3 bucket
try:
s3_client.put_object(Bucket=destination_bucket, Key=destination_file_key, Body=audio_data)
except Exception as e:
print(str(e))
return {
'statusCode': 500,
'body': f'Error uploading MP3 to S3: {str(e)}'
}
print("success")
return {
'statusCode': 200,
'body': f'Successfully converted and saved text to MP3: s3://{destination_bucket}/{destination_file_key}'
}Вам необходимо скопировать приведенный выше код и вставить его в консоль Lambda, а затем нажать «Развернуть!».
И что теперь, наша лямбда-функция готова!
Теперь мы перейдем к нашему последнему шагу!! т. е. настройка уведомления о событиях S3 в нашей исходной корзине S3!
Настройка уведомления о событиях S3
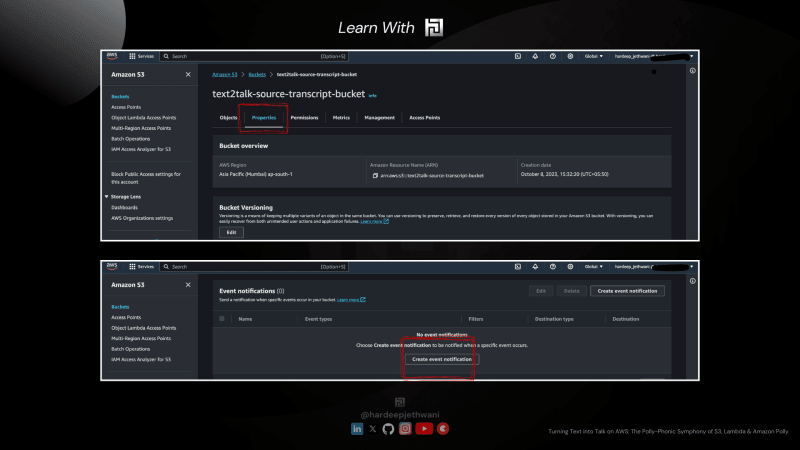
- Перейдите в консоль AWS S3.
- Нажмите на свое ведро (здесь
text2talk-source-transcript-bucket). Затем перейдите в раздел «Свойства». - Прокрутив вниз, вы найдете раздел «Уведомление о событии». Вам необходимо нажать «Создать уведомление о событии».
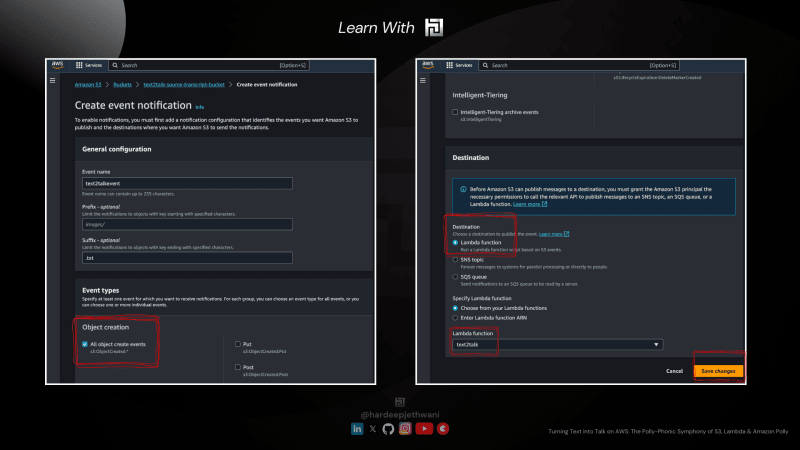
- Вы перейдете на страницу, где нужно заполнить информацию о триггерном действии события S3 и цели.
- Вы можете назвать свое событие, а затем выбрать формат файла, для которого мы хотим активировать действие преобразования аудио. Итак, здесь мы используем «
.txt» в качестве формата исходного файла. - В разделе «Типы событий» просто отметьте «Все события создания объекта», так как мы должны запускать это преобразование при каждом событии создания/обновления файла.
- Прокрутите вниз, чтобы заполнить данные о пункте назначения! В нашем случае это лямбда-функция с именем «
text2talk» (вы также можете заполнить ARN лямбда-функции) - А затем просто нажмите «Сохранить изменения».
Ураааа, мы наконец завершили этап сборки!!! Теперь пришло время протестировать нашу конструкцию....
Тестируем установку!!!!
- Вам нужно просто загрузить тестовый файл в корзину с исходным кодом (здесь
text2talk-source-transcript-bucket(я сделал образец текста, который вы можете найти ЗДЕСЬ на GitHub!!) - Затем через несколько секунд вы сможете проверить свою целевую корзину (здесь). И вы наконец увидите там аудиофайл!! (Вы можете найти мои результаты ЗДЕСЬ на GitHub)
Наконец-то мы смогли помириться!!! Поздравляю!!!