Профилирование Pandas в Python

Позвольте мне дать вам настолько мощный инструмент, что он изменит способ, которым вы начинаете анализировать свои наборы данных - профилирование Pandas. Больше не нужно искать способы описать свой набор данных с помощью функций max() и min().
Что такое профилирование Pandas?
В Python библиотека профилирования Pandas содержит метод ProfileReport(), который создает простой входной отчет фрейма данных.
Библиотека pandas_profiling состоит из следующей информации:
- Обзор DataFrame,
- Атрибуты, указанные в DataFrame,
- Связи атрибутов (корреляция Пирсона и корреляция Спирмена) и
- Исследование DataFrame.
Базовый синтаксис библиотеки pandas_profiling
import pandas as pd
import pandas_profiling
df = pd.read_csv(#file location)
pandas_profiling.ProfileReport(df, **kwargs)
Работа с профилированием Pandas
Для начала работы с модулем pandas_profiling возьмем набор данных:
!wget "https://archive.ics.uci.edu/ml/machine-learning-databases/00528/dataset.csv"
Используемые данные были получены из ГИС и спутниковой информации, а также из информации, собранной из природных кадастров, которые были подготовлены для отчетов об оценке воздействия на окружающую среду (ОВОС) для двух запланированных дорожных проектов (Дорога A и Дорога B) в Польше.
Эти отчеты в основном использовались для сбора информации о размере популяции амфибий на каждом из 189 участков.
Использование модуля профилирования Pandas
Давайте воспользуемся Pandas для чтения только что загруженного CSV-файла:
data = pd.read_csv("dataset.csv",delimiter = ";")
Нам нужно импортировать пакет ProfileReport:
from pandas_profiling import ProfileReport
ProfileReport(data)
Функция генерирует отчеты профиля из фрейма данных pandas. Функция pandas df.describe() прекрасна, но немного проста для серьезного исследовательского анализа данных.
Модуль pandas_profiling расширяет фрейм данных pandas с помощью df.profile_report() для быстрого анализа данных.
Для каждого столбца в интерактивном HTML-отчете представлена следующая статистика, если она актуальна для данного типа столбца:
- Тип интерфейса: определение типов столбцов во фрейме данных.
- Основное: тип, уникальные значения, отсутствующие значения
- Квантильная статистика, такая как минимальное значение, Q1, медиана, Q3, максимум, диапазон, межквартильный размах
- Описательная статистика, такая как среднее значение, режим, стандартное отклонение, сумма, среднее абсолютное отклонение, коэффициент вариации, эксцесс, асимметрия
- Наиболее частые значения
- Гистограмма
- Выделение корреляций сильно коррелированных переменных, матриц Спирмена, Пирсона и Кендалла
- Матрица отсутствующих значений, количество, тепловая карта и дендрограмма пропущенных значений
- Анализ текста узнает о категориях (прописные буквы, пробел), сценариях (латиница, кириллица) и блоках (ASCII) текстовых данных.
- Анализ файлов и изображений извлекает размеры файлов, даты создания и размеры и просматривает усеченные изображения или изображения, содержащие информацию EXIF.
1. Опишите набор данных
Это то же самое, что и команда data.describe:

Он также дает нам типы переменных и подробную информацию о них, включая описательную статистику, которая суммирует центральную тенденцию, дисперсию и форму распределения набора данных (за исключением значений NaN).
Анализирует как числовые, так и объектные серии, а также наборы столбцов DataFrame смешанных типов данных. Результат будет зависеть от того, что предоставлено.
2. Корреляционная матрица
Еще у нас есть корреляционная матрица:
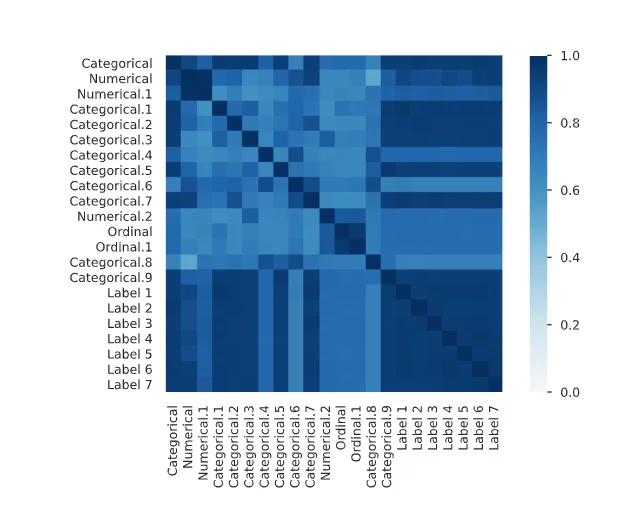
Это похоже на использование функций np.corrcoef(X, Y) или data.corr(). Pandas dataframe.corr() используется для нахождения попарной корреляции всех столбцов в кадре данных. Любые значения NaN автоматически исключаются. Для столбцов любого нечислового типа данных во фрейме данных он игнорируется.
3. Просмотр набора данных
И, наконец, у нас есть часть самого набора данных: