Python, YAML и Kubernetes — искусство освоения конфигурации

Практическое руководство по упрощению управления конфигурацией Kubernetes с помощью Python и YAML.
На прошлой неделе я столкнулся с, казалось бы, сложной задачей: обновить многочисленные файлы Kubernetes YAML для крупномасштабного приложения с несколькими микросервисами.
Задача состояла в том, чтобы изменить переменные среды и ограничения ресурсов в этих микросервисах, чтобы учесть изменения в конфигурации нашего приложения, такие как указание на новый сервер базы данных и настройка определенных параметров.
Вместо того чтобы проходить через утомительный и подверженный ошибкам процесс ручного редактирования каждого файла, я обратился к более эффективному решению.
С помощью всего нескольких строк кода на Python и библиотеки PyYAML я мог быстро и точно читать, изменять и записывать конфигурационные файлы Kubernetes, обеспечивая согласованность изменений во всех затронутых микросервисах.
В этой статье мы рассмотрим основы YAML, мощные возможности библиотеки PyYAML и то, как можно использовать Python для упрощения работы с конфигурационными файлами Kubernetes.
Мы также предоставим пошаговое руководство по созданию собственного скрипта Python для автоматизации синтаксического анализа и обновления файлов YAML, демонстрируя истинный потенциал сочетания Python и YAML при управлении сложными конфигурациями.
Как всегда, вы можете найти все примеры исходного кода в этом репозитории GitHub, который легко доступен для справки.
Понимание YAML и его роли в DevOps и Kubernetes
YAML, «YAML не язык разметки», представляет собой удобочитаемый формат сериализации данных, обычно используемый в файлах конфигурации и для обмена данными между языками программирования с различными структурами данных.
Благодаря своей удобочитаемости и простоте YAML стал предпочтительным выбором для многочисленных сервисов и инструментов DevOps для настройки и настройки конвейера.
Примеры сервисов и инструментов, использующих YAML для настройки, включают:
- Ansible
- Docker Compose
- Kubernetes
- Amazon Web Services (AWS)
- CircleCI
- GitHub Actions
- Azure DevOps создает и выпускает конвейеры
Используя YAML, эти службы и инструменты обеспечивают более упорядоченный и удобный для пользователя подход к управлению конфигурацией и процессам развертывания.
YAML также играет важную роль в Kubernetes, выступая в качестве основного формата для определения ресурсов и конфигураций Kubernetes и управления ими.
Kubernetes использует файлы YAML для декларативного указания желаемого состояния различных ресурсов внутри кластера, таких как развертывания, службы и карты конфигурации.
Библиотеки Python для работы с YAML
Для анализа, манипулирования и генерации данных YAML при работе с файлами YAML в Python можно использовать несколько библиотек.
Эти библиотеки легко обрабатывают структуры данных YAML в приложениях Python, облегчая бесшовную интеграцию с другими инструментами и сервисами.
В этом разделе будут рассмотрены некоторые из наиболее популярных и широко используемых библиотек Python для работы с YAML.
PyYAML
PyYAML — это широко используемая библиотека Python, которая позволяет анализировать, создавать и манипулировать данными YAML. Он предоставляет методы для загрузки данных YAML из файла или строки, представляя данные в виде собственных структур данных Python, таких как словари, списки и скаляры.
PyYAML также предлагает методы для преобразования структур данных Python обратно в формат YAML и записи их в файл или строку.
ruamel.yaml
ruamel.yaml - это еще одна популярная библиотека Python для работы с данными YAML, разработанная как более современная и многофункциональная альтернатива PyYAML. Он поддерживает YAML 1.2 и совместим со многими версиями Python. Библиотека предоставляет методы для загрузки, выгрузки, синтаксического анализа и передачи данных YAML с сохранением комментариев, форматирования и порядка.
В то время как PyYAML и ruamel.yaml являются наиболее часто используемыми библиотеками для работы с YAML в Python, вы можете столкнуться с другими библиотеками, которые предлагают дополнительные функции или подходят для конкретных случаев использования. При выборе библиотеки учитывайте такие факторы, как простота использования, производительность, совместимость и поддержка сообщества, чтобы убедиться, что она соответствует вашим требованиям.
Одно из ключевых различий между ruamel.yaml и PyYAML - это тот самый ruamel.yaml поддерживает спецификацию YAML 1.2, в то время как PyYAML поддерживает только YAML 1.1.
В этой статье будет использоваться библиотека PyYAML для работы с файлами YAML благодаря ее широкой поддержке и широкому использованию в сообществе Python. PyYAML стал популярным выбором для разработчиков, предоставляя простой и интуитивно понятный интерфейс для синтаксического анализа, создания данных YAML и манипулирования ими.
Хотя PyYAML может и не поддерживать последнюю спецификацию YAML 1.2, она остается надежной и хорошо зарекомендовавшей себя библиотекой, которая подходит для многих случаев использования, что делает ее отличным выбором для наших целей.
Чтение и разбор файлов Kubernetes YAML с помощью Python
Давайте воспользуемся возможностями Python и PyYAML для чтения и синтаксического анализа нашего первого файла Kubernetes YAML. Мы будем работать с примером спецификации Pod, содержащей контейнер NGINX, и использовать функцию pretty print для отображения проанализированного YAML в виде собственных объектов Python.
Вот краткий обзор примера файла NGINX Pod YAML, который мы будем использовать:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx
name: nginx
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}А скрипт Python для чтения и анализа файла YAML можно увидеть ниже. Функция load_and_print_yaml принимает имя файла в качестве аргумента, считывает данные YAML из файла и распечатывает проанализированное содержимое.
import yaml
import pprint
def load_and_print_yaml(filename):
with open(filename, "r") as file:
data = yaml.safe_load(file)
pprint.pprint(data)
def main():
example_file = "./example-k8s-files/nginx.yaml"
load_and_print_yaml(example_file)
if __name__ == "__main__":
main()Предоставленный ранее скрипт выдает следующий результат. Как показано, функция safe_load из библиотеки PyYAML считывает и анализирует файл YAML, преобразовывая его в набор вложенных словарей Python.
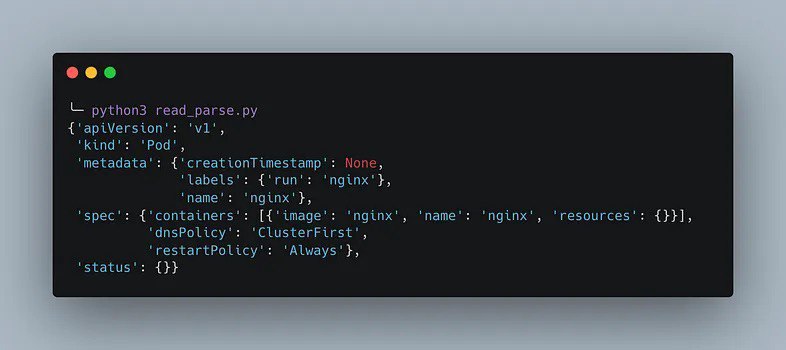
Чтобы получить доступ к одному полю, такому как поле изображения Pod, вы используете синтаксис, который можно увидеть ниже. Этот код выполняет навигацию по вложенным словарям Python, получая доступ к полю "spec", затем к полю "containers" (которое представляет собой список, поэтому мы используем индекс 0, чтобы получить первый контейнер) и, наконец, к полю "image" Pod.
image = data["spec"]["containers"][0]["image"]
print("Image: ", image)В следующем разделе мы прочитаем файл Kubernetes YAML, проанализируем его содержимое, изменим его, а затем сохраним изменения на диске.
Изменение конфигураций Kubernetes с использованием Python и PyYAML
В этом разделе мы будем использовать пример Kubernetes, который полностью соответствует сценарию, описанному во введении. Это поможет проиллюстрировать, как концепции, рассмотренные ранее, могут быть применены практически.
У нас есть YAML-файл развертывания Kubernetes, в котором указаны настройки среды нашего приложения и требования CPU.
Нам нужно увеличить уровень ведения журнала, чтобы исследовать некоторые проблемы с приложением. Однако это также увеличит загрузку процессора приложением, поэтому нам нужно обновить запрос процессора, чтобы убедиться, что приложение располагает достаточными ресурсами.
Чтобы внести эти изменения, мы модифицируем файл deployment YAML, изменив переменную среды LOG_LEVEL на 2 и обновив запрос центрального процессора с 500m до 750m. После настройки файла мы сохраним обновленный файл YAML на диск.
Файл YAML приведен ниже для справки.
apiVersion: apps/v1
kind: Deployment
metadata:
name: workflow-encoder
spec:
replicas: 3
selector:
matchLabels:
app: workflow-encoder
strategy:
type: Recreate
template:
metadata:
labels:
app: workflow-encoder
spec:
containers:
- name: workflow-encoder
image: workflowencoder:3.5.1
env:
- name: LOG_LEVEL
value: "1"
resources:
requests:
cpu: 500m
memory: 1024Mi
limits:
cpu: 8000m
memory: 2524MiСценарий Python для чтения, изменения и записи файла YAML приведен ниже. Этот код определяет функцию modify_yaml_file, которая изменяет файл YAML развертывания Kubernetes, изменяя переменную среды LOG_LEVEL и запрос CPU.
Файл YAML считывается в память с помощью функции yaml.safe_load(). Он загружает данные YAML в словарь Python. Затем он изменяет данные YAML, обращаясь к соответствующим ключам в словаре и обновляя их.
Наконец, функция записывает измененные данные YAML в новый файл с помощью функции yaml.safe_dump().
import yaml
def modify_yaml_file(source_path, destination_path, log_level, cpu_request):
with open(source_path, 'r') as input:
yaml_data = yaml.safe_load(input)
containers = yaml_data['spec']['template']['spec']['containers']
# Modify the LOG_LEVEL
containers[0]['env'][0]['value'] = str(log_level)
# Modify the CPU request
containers[0]['resources']['requests']['cpu'] = str(cpu_request)
with open(destination_path, 'w') as output:
yaml.safe_dump(yaml_data, output)
def main():
source_path = './example-k8s-files/encoder.yaml'
destination_path = './example-k8s-files/encoder_changed.yaml'
log_level = 2
cpu_request = '750m'
modify_yaml_file(source_path, destination_path, log_level, cpu_request)
if __name__ == '__main__':
main()
В предыдущем примере мы изменили существующие значения в файле Kubernetes YAML. Кроме того, в файл YAML можно добавить новые разделы. В нашем следующем примере давайте проиллюстрируем это, добавив в файл YAML раздел несуществующих ресурсов, который включает запросы к CPU и памяти.
Мы продолжим использовать тот же файл YAML, что и в предыдущем примере, но для этой демонстрации раздел resources будет удален.
apiVersion: apps/v1
kind: Deployment
metadata:
name: workflow-encoder
spec:
replicas: 3
selector:
matchLabels:
app: workflow-encoder
strategy:
type: Recreate
template:
metadata:
labels:
app: workflow-encoder
spec:
containers:
- name: workflow-encoder
image: workflowencoder:3.5.1
env:
- name: LOG_LEVEL
value: "1"Скрипт на Python для добавления раздела ресурсов приведен ниже. Функция add_resources_section добавляет раздел resources к указанным данным YAML.
Он вводит данные YAML, желаемые запросы к CPU и памяти, а также ограничения. Затем функция выполняет итерацию по контейнерам, определенным в YAML, и добавляет раздел resources с указанными запросами и ограничениями для CPU и памяти в каждый контейнер.
import yaml
def read_yaml_file(filename):
with open(filename, 'r') as file:
yaml_data = yaml.safe_load(file)
return yaml_data
def add_resources_section(yaml_data, cpu_request, memory_request, cpu_limit,
memory_limit):
containers = yaml_data["spec"]["template"]["spec"]["containers"]
for container in containers:
container["resources"] = {
"requests": {
"cpu": cpu_request,
"memory": memory_request
},
"limits": {
"cpu": cpu_limit,
"memory": memory_limit
}
}
return yaml_data
def write_yaml_file(filename, yaml_data):
with open(filename, 'w') as file:
yaml.safe_dump(yaml_data, file)
def main():
source_file = './example-k8s-files/encoder_without_requests.yaml'
destination_file = './example-k8s-files/encoder_with_requests_limits.yaml'
cpu_request = '200m'
memory_request = '512Mi'
cpu_limit = '500m'
memory_limit = '1Gi'
yaml_data = read_yaml_file(source_file)
modified_data = add_resources_section(yaml_data, cpu_request,
memory_request, cpu_limit,
memory_limit)
write_yaml_file(destination_file, modified_data)
if __name__ == "__main__":
main()PyYAML полезен при чтении и записи файлов YAML в Python, а также может использоваться для проверки файлов YAML Kubernetes. В следующем разделе показано, как проверить каталог, полный файлов YAML, с помощью PyYAML.
Проверка файлов YAML
Обычно при создании ресурса в Kubernetes с помощью kubectl сервер API Kubernetes проверяет отправленный YAML и уведомляет вас о любых проблемах.
Однако вы также можете создать скрипт Python с использованием PyYAML для проверки всех ваших файлов Kubernetes YAML. Пример ниже делает именно это, перебирая каждый файл YAML в папке и проверяя каждый из них. Если файл не проходит проверку, сценарий выводит имя файла.
Функция validate_yaml_file выполняет основную задачу проверки. Он использует функцию safe_load, чтобы попытаться загрузить файл YAML. В случае успеха возвращается None; в противном случае возвращается имя файла и соответствующее сообщение об ошибке. PyYAML генерирует сообщение об ошибке с подробностями, указывающими местонахождение ошибки в файле YAML.
import os
import yaml
import sys
def get_yaml_files_in_directory(directory):
yaml_files = []
for root, _, files in os.walk(directory):
for file in files:
if file.endswith('.yaml') or file.endswith('.yml'):
yaml_files.append(os.path.join(root, file))
return yaml_files
def validate_yaml_file(file_path):
try:
with open(file_path, 'r') as file:
yaml.safe_load(file)
return None
except yaml.YAMLError as error:
return f"Error in {file_path}: {error}"
def validate_all_yaml_files(files):
invalid_files = []
for file in files:
error_message = validate_yaml_file(file)
if error_message:
invalid_files.append((file, error_message))
return invalid_files
def main():
if len(sys.argv) < 2:
print("Usage: python validate_yaml.py <directory>")
sys.exit(1)
directory = sys.argv[1]
yaml_files = get_yaml_files_in_directory(directory)
invalid_files = validate_all_yaml_files(yaml_files)
if invalid_files:
print("\nThe following YAML files are invalid:")
for file, error_message in invalid_files:
print(f"- {file}: {error_message}")
sys.exit(2)
else:
print("All YAML files are valid.")
if __name__ == "__main__":
main()Поскольку мы изучили процесс проверки файлов YAML с помощью Python, стоит отметить, что всегда есть возможности для улучшения производительности.
В следующем разделе мы рассмотрим оптимизацию производительности Python и YAML, чтобы убедиться, что наш скрипт проверки работает эффективно и результативно.
Оптимизация производительности Python и YAML
Повышение производительности PyYAML может быть достигнуто с помощью различных подходов, таких как использование более быстрых парсеров или библиотек, кэширование и параллельная обработка. Вот некоторые предложения:
Используйте библиотеку libyaml
PyYAML может использовать библиотеку libyaml для более быстрого синтаксического анализа и отправки. Чтобы включить эту функцию, вам необходимо установить библиотеку libyaml, а затем установить PyYAML с ее поддержкой:
pip install pyyaml --global-option="--with-libyaml"После установки вы можете использовать загрузчики и дамперы на основе C для повышения производительности.
yaml.load(file, Loader=yaml.CSafeLoader)
yaml.dump(data, file, Dumper=yaml.CSafeDumper)Кэшируйте проанализированные файлы YAML
Если вы неоднократно анализируете одни и те же файлы YAML, рассмотрите возможность кэширования проанализированного содержимого, чтобы избежать повторного анализа. Вы можете использовать встроенную в Python библиотеку functools для реализации кэширования.
from functools import lru_cache
@lru_cache(maxsize=None)
def load_yaml(file_path):
with open(file_path, 'r') as file:
return yaml.safe_load(file)Параллельная обработка
Вы можете повысить производительность, обрабатывая их параллельно, если у вас есть много файлов YAML для проверки. В зависимости от вашего варианта использования и системных ресурсов вы можете использовать библиотеку concurrent.futures Python для обеспечения параллельной обработки либо с потоками, либо с процессами.
Вот пример использования ThreadPoolExecutor для параллельной проверки:
from concurrent.futures import ThreadPoolExecutor
def validate_all_yaml_files(files):
invalid_files = []
with ThreadPoolExecutor() as executor:
results = executor.map(validate_yaml_file, files)
for file, error_message in zip(files, results):
if error_message:
invalid_files.append((file, error_message))
return invalid_filesКогда мы завершаем этот последний пример повышения производительности, мы подошли к концу статьи. Давайте завершим кратким обзором ключевых тем, которые мы затронули в ходе обсуждения в Заключении.
Заключение
YAML стал неотъемлемой частью современных практик DevOps и платформ оркестрации контейнеров, таких как Kubernetes.
Его простота, удобочитаемость и адаптируемость делают его идеальным выбором для управления конфигурацией в различных инструментах и службах.
Python, универсальный и мощный язык программирования, предлагает такие библиотеки, как PyYAML и ruamel.yaml, которые делают работу с данными YAML простой и эффективной.
В этой статье рассказывается, как можно использовать Python и YAML для создания, изменения и проверки конфигураций Kubernetes.
Мы рассмотрели, как PyYAML может анализировать, изменять и генерировать данные YAML для управления ресурсами Kubernetes. Кроме того, мы продемонстрировали, как проверять и оптимизировать производительность конфигураций YAML с помощью Python.
Понимая и используя мощь Python и YAML, разработчики могут создавать более оптимизированные и удобные в сопровождении конфигурации для своих конвейеров DevOps и кластеров Kubernetes.
Использование этих методов позволит разработчикам эффективно управлять приложениями и развертывать их, обеспечивая успех и долговечность своих программных проектов.
Вы можете найти все примеры исходного кода в этом репозитории GitHub.