Регулярное выражение: пример Python с использованием просмотра назад и вперед
Все еще в вибрациях регулярных выражений, я собираюсь поделиться решением для простой задачи кода HackerRank, которую я принял на прошлой неделе. Я использовал регулярные выражения, чтобы решить эту проблему, и я опишу решение, объяснив две групповые конструкции, которые я использовал как часть решения: просмотр назад и просмотр вперед.
Соревнование
Задача дает нам строку S, состоящую из буквенно-цифровых символов, пробелов и символов (+,-). Наша задача — найти все подстроки S, содержащие 2 и более гласных. Кроме того, эти подстроки должны находиться между двумя согласными и содержать только гласные.
Итак, гласные определяются как: AEIOU и aeiou.
Согласные определяются как: QWRTYPSDFGHJKLZXCVBNM и qwrtypsdfghjklzxcvbnm.
Если подстроки не найдены, вы просто печатаете -1.
Пример:
Таким образом, вы получаете строку S = 'rabcdeefgyYhFjkIoomnpOeorteeeet'.
Вы должны вернуть все подстроки, соответствующие описанным выше требованиям. Подстроки должны быть:
'ee', Ioo, Oeo, eeeee, когда все они состоят из двух или более гласных, расположенных между согласными.
Обсуждение решения
Сначала цель этой задачи — узнать, когда использовать findall() и finditer() из модуля regex re.
Но вам все равно нужно написать шаблон регулярного выражения, соответствующий требованиям задачи, чтобы найти подстроки.
Итак, начнем с основной идеи: экранирование строки от первого символа до последнего. В этом случае шаблон должен не только соответствовать двум или более гласным, но также смотреть на то, что идет до и после каждой из этих подстрок.
И именно тогда мы используем просмотр назад и просмотр вперед.
Просмотр назад
Ретроспективный просмотр может быть положительным (?<=) или отрицательным (?<!). Первый используется, чтобы «гарантировать, что данный шаблон будет соответствовать, заканчиваясь в текущей позиции в выражении. Шаблон должен иметь фиксированную ширину. Не использует никаких символов».
Таким образом, в основном то, что делает положительный взгляд назад, находит выражение X, которому предшествует другое заданное выражение Y: (?<=Y)Х
В то время как отрицательный просмотр назад отрицал бы данное выражение Y, это находит X, когда ему не предшествует Y: (?<!Y)Х
Просмотр вперед
Как и просмотр назад, просмотр вперед также может быть положительным (?=) или отрицательным (?!).
Положительный «утверждает, что данный подшаблон может быть сопоставлен здесь без использования символов», в то время как отрицательный «начинается с текущей позиции в выражении, гарантируя, что данный шаблон не будет совпадать. Не использует никаких символов».
Поведение очень похоже на то, что мы уже видели для просмотра назад, но теперь смотрим на то, что следует за данным выражением.
Таким образом, положительный просмотр находит X, когда за ним следует Y: X(?=Y)
В то время как отрицательный находит X, если за ним не следует Y: X(?!Y)
Решение
Теперь мы знаем, что делают эти группы, вот возможный шаблон регулярного выражения для решения, использующего их обе:
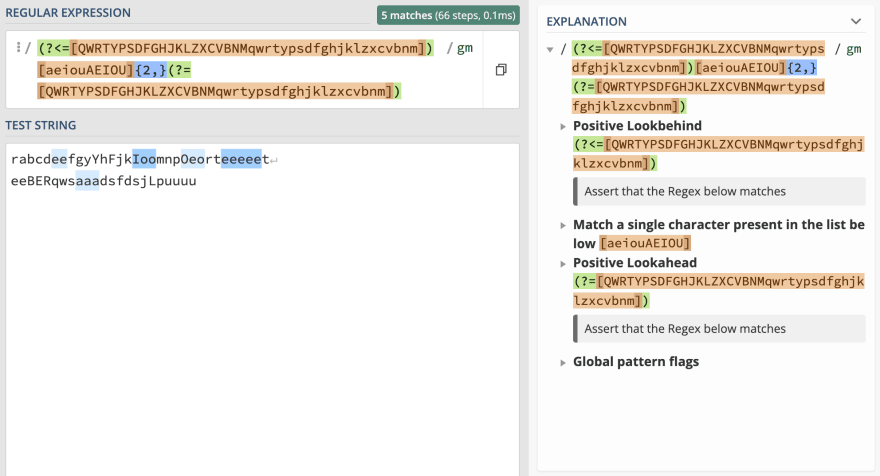
Итак, сначала мы используем группу положительного просмотра назад (?<=[QWRTYPSDFGHJKLZXCVBNMqwrtypsdfghjklzxcvbnm]), ища любые согласные, содержащиеся в группе, за которыми следуют две или более гласных [aeiouAEIOU]{2,}. Наконец, группа положительного прогноза для поиска любых следующих согласных (?=[QWRTYPSDFGHJKLZXCVBNMqwrtypsdfghjklzxcvbnm]).
Обратите внимание, что в первом примере строки он соответствует ожидаемым подстрокам, отвечающим требованиям задачи. И во втором примере строки он не соответствует гласным в начале и в конце строки (если они не находятся между согласными), что является ожидаемым поведением.
Тот факт, что эти группы не потребляют никаких символов, очень важен для нашего решения. Это означает, что наши согласные не будут потребляться при нахождении двух или более гласных между ними, и мы все еще можем найти другие гласные, соответствующие тому же шаблону, вместо того, чтобы останавливать поиск, когда группа будет найдена в соответствии с условиями шаблона.
Например, если бы наши согласные были поглощены, при наличии строки, подобной этой baabaaab, она соответствовала бы только первой подстроке гласных aa, останавливающейся там, не находя вторую подстроку гласных aaa, которые также находятся между согласными.
И вот полное решение с использованием re.findall(), которое «возвращает все непересекающиеся совпадения шаблонов в строке в виде списка строк» (ссылка на HackerRank):
import re
s = input()
lst = re.findall(r'(?<=[QWRTYPSDFGHJKLZXCVBNMqwrtypsdfghjklzxcvbnm])[aeiouAEIOU]{2,}(?=[QWRTYPSDFGHJKLZXCVBNMqwrtypsdfghjklzxcvbnm])', s)
if len(lst) > 0:
for element in lst:
print(element)
else:
print(-1)