Руководство по Comprehensions в Python

Comprehensions представляют собой, пожалуй, самый популярный синтаксический сахар в Python. Первый раз когда вы видите comprehensions, они не кажутся такими уж читабельными. Многие люди, делающие свои первые шаги в Python, не находят их ни ясными, ни понятными. Некоторые могут предпочесть циклы for; некоторые другие могут предпочесть функцию map(); третьи могут предпочесть все, что еще будет работать — только не comprehensions.
Если вы относитесь к их числу, будем надеяться, что эта статья убедит вас в том, что comprehensions может пригодиться в различных ситуациях, иногда будучи гораздо более читабельным, чем любой другой инструмент, который предлагает Python. Если вы не относитесь к их числу, эта статья поможет вам узнать больше о том, как работают comprehensions; это может помочь вам понять и создать как простые, так и расширенные comprehensions. Кроме того, мы обсудим важный аспект comprehensions: когда comprehensions переходит слишком трудную черту, в этом случае вам следует отказаться от его использования. Иногда, чтобы сделать это, вы должны быть в состоянии убедить себя отказаться от определенного comprehensions, настолько продвинутого, что его использование может показать вас как опытного программиста на Python.
Это связано с тем, что в некоторых ситуациях другой инструмент может работать лучше. Мы углубимся в практические аспекты comprehensions, и, что вы не только изучите эту статью, но и получите удовольствие от ее чтения. В этой статье постараемся осветить всю информацию, что вам нужно знать о них, но это не значит, что будет о них все. Но как только вы поймете их основы и захотите узнать больше, у вас будет достаточно знаний для этого.
Таким образом, цель этой статьи - объяснить, что такое понимание (comprehensions) Python, а также как и когда их использовать. Это также обеспечивает некоторые существенные тонкости понимания и их использования.
Я также будет введен новый термин - incomprehension (непонимание) Python. В то время как общая кодовая база, основанная на Python, полна как понимания, так и непонимания, вы должны стремиться к разумному количеству первых и ни к одному из последних.
Введение
Первое, что нам необходимо, чтобы вы поняли относительно понимания, — это значение слова «понимание». Кембриджский словарь дает следующее определение слова «понимание»:
способность полностью понимать и быть знакомым с ситуацией, фактами…
Хотелось бы, чтобы вы помнили об этом — это именно то, что делают включения Python: они помогают понять действие, которое выполняет код. Итак, вы можете сделать это действие по-другому, но это действие делается через осмысление, оно помогает понять, что происходит. Это помогает и их автору, и читателю.
Тем не менее, помните слово непонимание, антоним понимания. В то время как Python не предлагает непостижения, когда мы переусердствуем с пониманием и сделаем их нечитаемыми, они станут непостижимыми. Изображение ниже представляет термин «непонимание Python», которое представляет собой понимание Python, превращенное во что -то непостижимое; То есть к чему-то, что противоречит тому, для чего существуют понимание: чтобы помочь понять действие, которое делает код. Вместо этого непонимания затрудняют понимание того, что должен делать код.

Мы обсудим, как сохранить наши понимания понятными, вместо того, чтобы сделать их непостижимыми; Как не превратить их в непостижимость в Python; И так, в свою очередь, как сделать свой код Pythonic, простым и понятным.
Мы рассмотрим comprehensions как синтаксический сахар, который позволяет нам использовать более чистый и короткий код вместо другого инструмента кодирования, такого как цикл for, для создания списка, словаря, набора или выражения генератора. Как видите, вы можете использовать comprehensions для создания объектов четырех разных типов. Прежде чем идти дальше, давайте разберем простой пример, похожий на те, что вы наверняка видели на многих других ресурсах.
В первом примере покажем вам, как использовать простейший тип понимания для создания списка, множества, генераторного выражения и словаря. Позже мы будем работать в основном со списками или словарями, в зависимости от того, что мы будем обсуждать.
List comprehensions (он же listcomps)
Представьте, что в Python нет комплементов, и мы хотим сделать следующее. У нас есть список числовых значений, скажем, x, и мы хотим создать список, содержащий квадраты значений x. Давай сделаем это:
>>> x = [1, 2, 3]
>>> x_squared = []
>>> for x_i in x:
... x_squared.append(x_i**2)
>>> x_squared
[1, 4, 9]Теперь давайте вернемся к реальности: Python предлагает понимание списка. Мы можем достичь того же с гораздо короче и, в этом отношении, гораздо более понятным кодом:
>>> x = [1, 2, 3]
>>> x_squared = [x_i**2 for x_i in x]
>>> x_squared
[1, 4, 9]Понимание списка здесь: [x_i**2 for x_i in x]. Вы можете прочитать его следующим образом: Рассчитайте x_i**2 для каждого значения в x и вернуть новые значения в списке.
Чтобы сравнить длину обоих подходов, позвольте нам определить коэффициент понимания:
n_for / n_comprehensionгде n_for обозначает количество символов в цикле for, а n_comprehension - количество символов в соответствующем понимании. Чтобы сделать это справедливым, мы будем использовать только односимвольные имена. Соотношение может быть указано в процентах.
Коэффициент понимания показывает, насколько короче код для понимания по сравнению с кодом цикла for. Предупреждение: Это отражает только один аспект истории: краткость понимания. В то время как для некоторых примеров такая краткость хороша, в некоторых других это не так, поскольку код может стать слишком сложным для понимания. Мы все равно будем использовать это соотношение, чтобы у вас было представление о том, насколько короче понимание по сравнению с аналогом цикла for. Кроме того, иногда другой инструмент кодирования может работать лучше, чем цикл for, например, функция map().
В этом простом примере исходный цикл for требовал 26 символов (без пробелов); list comprehension - 15 символов. Просто чтобы внести ясность, подсчитаем символы в следующих текстах:
for loop:
y=[]foriinx:y.append(i**2)
list comprehension:
y=[i**2foriinx]В этом самом примере коэффициент понимания составил 173%.
Set comprehensions (он же setcomps)
>>> x = [1, 2, 3]
>>> x_squared = set()
>>> for x_i in x:
... x_squared.add(x_i**2)
>>> x_squared
{1, 4, 9}Вот соответствующее понимание набора:
>>> x = [1, 2, 3]
>>> x_squared = {x_i**2 for x_i in i}
>>> x_squared
{1, 4, 9}Коэффициент понимания составляет 186%.
Dictionary comprehensions (он же dict comprehensions, dictcomps)
>>> x = [1, 2, 3]
>>> x_squared = {}
>>> for x_i in x:
... x_squared[x_i] = x_i**2
>>> x_squared
{1: 1, 2: 4, 3: 9}Понимание dict становится теперь:
>>> x = [1, 2, 3]
>>> x_squared = {x_i: x_i**2 for x_i in x}
>>> x_squared
{1: 1, 2: 4, 3: 9}Его коэффициент понимания меньше, чем у listcomps и setcomps, так как он составляет 124%.
Generator expressions (выражения генератора)
Вы можете задаться вопросом, какое отношение выражение генератора термина имеет к пониманию? Должно ли это быть что-то вроде понимания генератора?
Вот как мы это называем: выражения генератора. Они здесь потому, что выражения генератора создаются с использованием того же синтаксического сахара, что и другие понимания, хотя их поведение сильно отличается. Мы не будем обсуждать эту разницу в поведении, поскольку эта тема слишком важна, чтобы скрывать ее в общем тексте о понимании. Следовательно, мы покажем здесь только выражения генератора.
Чтобы создать выражение генератора, этого достаточно, чтобы взять код в квадратных скобках ([]), окружающих код ListComp, и окружить его скобками (()):
>>> x = [1, 2, 3]
>>> x_squared = (x_i**2 for x_i in x)Здесь x_squared - это выражение генератора, созданное на основе списка. Легко видеть, что коэффициент понимания выражения генератора такой же, как и коэффициент понимания соответствующего списка.
Расширение comprehensions
Приведенные выше понимания были самыми простыми, поскольку они включали операцию, выполняемую для каждого элемента iterable. Под операцией подразумевалась та часть понимания: x_i**2; и все остальное, что мы делаем с x_i — смотрите изображение ниже, которое объясняет, что такое операция. Мы можем расширить эту часть, но не только это; существует довольно много возможностей для расширения понимания Python, и именно в этом заключается мощь этого инструмента.
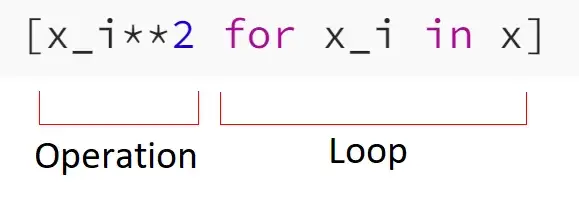
Следующий список показывает, как мы можем расширить простейшие понимания. Мы можем сделать это, используя:
- одна или несколько функций в операции
- один или несколько фильтров для исходных данных с использованием инструкции
if - один или несколько фильтров для вывода операции с использованием инструкции
if - используя условное выражение в операции, использовать один или несколько фильтров для исходных данных; или использовать один или несколько фильтров для выходных данных операции
- использование расширенного зацикливания
- комбинации вышеперечисленных
Вот тут-то все и может усложниться, и наша задача - сделать так, чтобы наше понимание не превратилось в непонимание. Прежде чем обсуждать, почему, давайте перейдем к примерам приведенных выше сценариев. Проанализируйте каждый пример и, если возможно, запустите его в своем интерпретаторе Python, особенно если вы новичок в понимании Python.
Приведенная выше классификация призвана помочь вам понять, как работают понимания. Это не формально, и, честно говоря, вам даже не нужно это запоминать. Использован он, чтобы показать вам, насколько разными и насколько мощными могут быть понимания. Итак, проанализируйте примеры, поймите их, и если вы считаете, что они могут вам помочь, постарайтесь их запомнить.
Использование function(s) в операции
>>> def square(x):
... return x**2
>>> x = [1, 2, 3]
>>> x_squared_list = [square(x_i) for x_i in x]
>>> x_square_list
[1, 4, 9]
>>> x_squared_dict = {x_i: square(x_i) for x_i in x}
{1: 1, 2: 4, 3: 9}Прочтите понимание [square(x_i) for x_i in x], например, как: вычислите square(x_i) для каждого значения в x и верните результаты в виде списка.
Выше мы использовали одну function. Мы можем использовать больше:
>>> def multiply(x, m):
... return x*m
>>> def square(x):
... return x**2
>>> x = [1, 2, 3]
>>> x_squared_list = [multiply(square(x_i), 3) for x_i in x]
>>> x_squared_dict = {x_i: multiply(square(x_i), 3) for x_i in x}
>>> x_square_list
[3, 12, 27]
>>> x_squared_dict = {x_i: square(x_i) for x_i in x}
{1: 3, 2: 12, 3: 27}С этого момента будут представляться только списковые включения. Будем надеяться, что к этому моменту вы уже знаете, как работают различные типы комплаенсов, поэтому нет смысла повторять их снова и снова и таким образом загромождать код.
Фильтрация исходных данных
>>> x = [1, 2, "a", 3, 5]
>>> integers = [x_i for x_i in x if isinstance(x_i, int)]
>>> integers
[1, 2, 3, 5]Мы создаем здесь список из x, принимая только целые числа (поэтому, когда x_i имеет тип int, то есть, if isinstance(x_i, int)).
Видите ли вы, насколько эта версия похожа на предыдущую? Это потому, что оба они используют оператор if для фильтрации исходных данных; они просто делают это немного по-другому. Ранее мы добавляли его к операции; здесь мы добавили его после цикла.
Эта и предыдущие версии фильтруют исходные данные, в отличие от того, что мы будем делать в следующем пункте, то есть фильтровать результаты операции. Другими словами, здесь вы могли бы достичь того же самого, сначала отфильтровав данные и применив понимание списка для отфильтрованных данных. В приведенной ниже версии вы бы сначала использовали понимание списка, а затем отфильтровали его значения.
Фильтрация выходных данных операции
>>> x = [1, 2, 3, 4, 5, 6]
>>> x_squared = [x_i**2 for x_i in x if x_i**2 % 2 == 0]Здесь мы сохраняем только те результаты, которые являются четными, и отбрасываем нечетные.
Обратите внимание, что этот код не идеален: мы выполняем одну и ту же операцию дважды, сначала в операции, а затем в условном выражении (которое начинается с if). Начиная с версии Python 3.8, мы можем улучшить этот код, используя оператор walrus:
>>> x = [1, 2, 3, 4, 5, 6]
>>> x_squared = [y for x_i in x if (y := x_i**2) % 2 == 0]Как видите, оператор walrus позволяет нам сэкономить половину вычислений в этом включении списка. Вот почему, если вы хотите использовать более продвинутые понимания, чем самые простые, вам следует подружиться с оператором walrus.
Для развлечения и чтобы чему-то научиться, мы можем использовать timeit для сравнения этих двух понятий, чтобы увидеть, действительно ли оператор walrus помогает нам улучшить производительность listcomp. Для тестов мы используем код, представленный в разделе производительности ниже, со следующими фрагментами кода:
setup = """x = list(range(1000))"""
code_comprehension = """[x_i**2 for x_i in x if x_i**2 % 2 == 0]"""
code_alternative = """[y for x_i in x if (y := x_i**2) % 2 == 0]"""Это то, что получилось на компьютере (32 ГБ оперативной памяти, Windows 10, WSL 1):
Time for the comprehension : 26.3394
Time for the alternative : 31.1244
comprehension-to-alternative ratio: 0.846Очевидно, что определенно стоит использовать оператор walrus — хотя прирост производительности не приближается к 50%, как можно было бы ожидать и надеяться. Как только вы узнаете, как работает этот оператор и эта версия понимания, вы сможете сделать код не только более производительным, но и более понятным.
Это понимание немного сложнее для чтения, чем предыдущие, хотя смысл так же прост: вычислите x_i**2 для каждого значения в x и отклоните все четные значения выходных данных (x_i**2); верните результаты в виде списка.
Как вы видите, вам нужно разобраться в тонкостях понимания, чтобы прочитать это, но как только они не создают для вас проблем, такое понимание становится легким для чтения. Однако, как вы увидите позже, некоторые понимания совсем не просты для чтения.
Фильтрация данных с использованием условного выражения в операции
>>> x = [1, 2, "a", 3, 5]
>>> res = [x_i**2 if isinstance(x_i, int) else x_i for x_i in x]
>>> res
[1, 4, 'a', 9, 25]Это понимание списка следует понимать следующим образом: Для каждого значения в x используйте следующий алгоритм: когда это целое число, квадрат его; оставить это нетронутым иначе; Соберите результаты в списке.
Эта версия очень похожа на фильтрацию данных; на самом деле, это особый тип фильтрации данных, который реализован в виде условного выражения (x if condition else y) внутри операции (а не вне ее). Честно говоря, вы можете легко переписать понимание этого списка, используя фильтрацию данных, как представлено выше. Мы не будем показывать это здесь, чтобы избежать путаницы. Но вы можете считать это хорошим упражнением: перепишите это понимание, используя фильтрацию данных, используя условие if вне операции, то есть после цикла понимания.
Смотрите также блок примечаний в следующем подразделе, чтобы узнать, когда можно использовать условное выражение, а когда его лучше избегать.
Фильтрация результатов с использованием условного выражения в операции
Вышеупомянутый ListComp отфильтровал данные; Мы также можем использовать условное выражение для фильтрации результатов операции, как здесь:
>>> x = [1, 2, 70, 3, 5]
>>> res = [y if (y := x_i**2) < 10 else 10 for x_i in x]
>>> res
[1, 4, 10, 9, 10]Мы снова использовали оператор walrus, чтобы избежать повторного использования одного и того же вычисления, как здесь:
>>> res = [x_i**2 if x_i**2 < 10 else 10 for x_i in x]Хотя эта версия не является неверной (особенно для Python 3.7 и более ранних версий), она не является производительной.
Поскольку в код операции добавляется условное выражение, оно может быть полезно, когда условие короткое. В противном случае это приведет к загромождению кода операции. В таком случае лучше использовать обычную фильтрацию с условием if, представленным после цикла понимания.
Использование расширенного цикла
Вам не обязательно использовать только простое зацикливание, как мы делали до сих пор. Например, мы можем использовать enumerate() в цикле понимания, так же, как вы сделали бы это в цикле for:
>>> texts = ["whateveR! ", "\n\tZulugula RULES!\n", ]
>>> d = {i: txt for i, txt in enumerate(texts)}
>>> d
{1: "whateveR! ", 2: "\n\tZulugula RULES!\n"}Теперь давайте пройдёмся по парам ключ-значение словаря d:
>>> [(k, v.lower().strip()) for k, v in d.items()]
[(1, 'whatever!'), (2, 'zulugula rules!')]В принципе, вы можете использовать любой подход к циклированию, который будет работать в цикле for.
Комбинации вышеперечисленных сценариев
Приведенные выше сценарии были базовыми, и обычно вам не нужно думать, являются ли такие понимания слишком сложными или нет; это не так. Тем не менее, ситуация может стать намного сложнее, особенно когда она включает в себя более одной простой операции или фильтрации; другими словами, когда она сочетает в себе вышеупомянутые сценарии (включая использование одного и того же сценария дважды или даже больше в одном понимании).
Если вы слышали, что понимание Python может стать слишком сложным, вы не ослышались. Вот почему вы часто можете прочитать, что вам не следует злоупотреблять пониманием; и это также более чем верно. Это то, для чего я предложил термин "непонимание". Вам определенно следует избегать использования непонятностей в вашем коде Python.
Давайте рассмотрим пару примеров, чтобы вы могли сами убедиться, что понимание может быть трудным. Однако не все из этих примеров будут слишком сложными, но некоторые определенно будут.
Рассмотрим этот listcomp, который сочетает в себе фильтрацию данных с фильтрацией выходных данных:
>>> x = range(50)
>>> [y for x_i in x if x_i % 4!= 0 if (y := x_i**2) % 2 == 0]
[4, 36, 100, 196, 324, 484, 676, 900, 1156, 1444, 1764, 2116]Посмотрите, что мы здесь делаем: вычисляем x_i**2 для всех значений x, которые делятся на 4, и берем только те результирующие выходные значения, которые делятся на 2.
Здесь у нас есть два условия if. В этом случае мы можем попытаться упростить понимание, объединив два условия, используя and:
>>> [y for x_i in x if x_i % 4!= 0 and (y := x_i**2) % 2 == 0]
[4, 36, 100, 196, 324, 484, 676, 900, 1156, 1444, 1764, 2116]Честно говоря, два условия, представленные в двух блоках if, кажутся более понятными, чем один блок if с двумя условиями, соединенными с оператором and.
Независимо от того, что вы думаете об использовании and, мы можем улучшить читаемость этого понимания, разделив его на несколько строк, каждая строка которых представляет блок, который что-то означает и/или что-то делает:
>>> [y for x_i in x
... if x_i % 4 != 0
... and (y := x_i**2) % 2 == 0]
[4, 36, 100, 196, 324, 484, 676, 900, 1156, 1444, 1764, 2116]Или
>>> [
... y for x_i in x
... if x_i % 4 != 0
... and (y := x_i**2) % 2 == 0
... ]
[4, 36, 100, 196, 324, 484, 676, 900, 1156, 1444, 1764, 2116]или даже
>>> [
... y
... for x_i in x
... if x_i % 4 != 0
... and (y := x_i**2) % 2 == 0
... ]
[4, 36, 100, 196, 324, 484, 676, 900, 1156, 1444, 1764, 2116]Эта последняя версия более полезна, когда мы применяем одну или несколько функций в первой строке, поэтому строка длиннее, чем просто одно имя, как здесь.
Как уже упоминалось два блока if для нас более удобочитаемы:
>>> [
... y for x_i in x
... if x_i % 4 != 0
... if (y := x_i**2) % 2 == 0
... ]
[4, 36, 100, 196, 324, 484, 676, 900, 1156, 1444, 1764, 2116]Особенно нравится в этой версии, так это визуальная симметрия блоков if с левой стороны. Заметили? Если нет, вернитесь к предыдущему блоку кода и обратите внимание на разницу между этой частью:
... if x_i % 4 != 0
... if (y := x_i**2) % 2 == 0и эта часть:
... if x_i % 4 != 0
... and (y := x_i**2) % 2 == 0Хотя эти аспекты не слишком важны, они помогают. Имеется в виду, что когда работаете над более глубоким пониманием, принимайте их во внимание — вы также принимайте во внимание эти аспекты. Когда вы будете обращать внимание даже на такие незначительные аспекты вашего понимания, вы почувствуете, что знаете их очень хорошо; вы почувствуете, что они (или не являются, когда они не готовы) готовы, закончены, завершены.
В конце концов, это понимание было не таким уж трудным, не так ли? Итак, давайте сделаем ситуацию — и, следовательно, понимание списка — немного более сложной:
>>> [
... y for x_i in x
... if x_i % 4 != 0 and x_i % 5 != 0
... if (y := square(multiply(x_i, 3))) % 2 == 0
... ]
[36, 324, 1764, 2916, 4356, 6084, 10404, 12996, 15876, 19044]Это более сложно, выражаясь таким образом, даже это понимание вполне читаемо. Тем не менее, с добавлением все большего количества условий это становилось бы все более и более сложным — в конечном счете, в какой-то момент, перейдя черту слишком сложного.
Альтернативы и примеры
Иногда цикл for будет более читабельным, чем понимание. Однако есть и другие альтернативы, такие как функции map() и filter().
Эти функции могут быть даже быстрее, чем соответствующие понимания, поэтому всякий раз, когда важна производительность, вы можете захотеть проверить, не работает ли код на основе map() и filter() лучше, чем понимание, которое вы использовали.
В простых сценариях понимание обычно лучше; в сложных сценариях это не обязательно так. Лучше всего показать это на примерах. Таким образом, ниже продемонстрируем пару примеров понимания (включая выражения генератора) и соответствующее альтернативное решение.
Пример 1. Функция map() вместо простого выражения генератора.
>>> x = range(100)
>>> gen = (square(x_i) for x_i in x)
>>> other = map(square, x)В этой ситуации обе версии кажутся одинаково читаемыми, но понимание выглядит несколько более знакомым. Функция map() - это абстракция: вам нужно знать, как она работает, какой аргумент должен быть первым (вызываемый), а какой должен быть затем (повторяемый)¹.
В отличие от map(), простые понимания, подобные приведенному выше, не выглядят абстрактными. Можно прочитать их напрямую, слева направо, чтобы записать: применяем функцию square() к x_i, а x_i - это последующие элементы x; сохраняем результаты в объекте generator.
Звучит просто для такого понимания, вам нужно знать этот специфический синтаксический сахар Python. Вот почему для продвинутых (даже промежуточных) программистов Python, это выражение генератора (и другие подобные простые понимания) выглядят простыми, но они редко выглядят простыми для начинающих разработчиков Python. Итак, понимания тоже могут быть абстрактными. Однако, как мы скоро увидим, этот синтаксис может быть намного понятнее, чем его прямые альтернативы.
Использование функции map() становится менее ясным, когда вы используете функцию lambda внутри map(). Сравним:
>>> x = range(100)
>>> gen = (x_i**2 for x_i in x)
>>> other = map(lambda x_i: x_**2, x)Хотя lambda действительно имеют свое место в Python и могут быть очень полезными, в некоторых ситуациях они могут снизить удобочитаемость — и это такая ситуация. Здесь определенно предпочитаются выражение генератора версии map().
Пример 2: Функция filter(), используемая вместо выражения генератора с блоком if для фильтрации данных.
>>> x = range(100)
>>> gen = (x_i for x_i in x if x_i % 5 == 0)
>>> other = filter(lambda x_i: x_i % 5 == 0, x)Все вышеприведенные комментарии для map() применимы к функции filter(). Как и map(), его можно использовать с (как здесь) или без lambda. Здесь, опять же, я предпочитаю выражение генератора.
Пример 3: Объединение map() и filter() вместо выражения генератора, которое использует функцию для обработки элементов и блок if для фильтрации данных.
>>> x = range(100)
>>> gen = (square(x_i) for x_i in x if x_i % 5 == 0)
>>> other = map(square, filter(lambda x_i: x_i % 5 == 0, x))Вы можете сделать то же самое в два этапа:
>>> x_filtered = filter(lambda x_i: x_i % 5 == 0, x)
>>> other = map(square, x_filtered)Это одна из ситуаций, когда вы объединяете функции map() и filter() для обработки данных и их фильтрации. Но это также одна из тех ситуаций, в которых мне нужно некоторое время, чтобы понять, что делает этот код, в то же время будучи в состоянии понять соответствующие понимания (здесь, выражение генератора) почти сразу. Здесь мы бы определенно выбрали версию выражения генератора.
Пример 4: Использование map() с функцией-оболочкой вместо понимания по словарю.
Понимание словаря делает создание словарей довольно простым. Рассмотрим этот пример:
>>> def square(x):
... return x**2
>>> y = {x: square(x) for x in range(5)}
>>> y
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16}Теперь попробуйте добиться того же с помощью map().
Проблема в том, что вам нужно создать пары ключ-значение, поэтому, если мы хотим использовать map(), недостаточно, чтобы функция возвращала выходные данные; она также должна возвращать ключ. Хорошим решением является использование функции-оболочки вокруг square():
>>> def wrapper_square(x):
... return x, square(x)
>>> y = dict(map(wrapper_square, range(5)))
>>> y
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16}Согласитесь ли вы, что приведенное выше понимание диктовки было намного более читабельным, намного проще в написании и намного легче для чтения, чем эта версия на основе map()? Здесь цикл for было бы легче понять, чем версию map():
>>> y = {}
>>> for x in range(5):
... y[x] = square(x)
>>> y
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16}Пример 5: Цикл for для фильтрации данных в сочетании с фильтрацией выходных данных.
Давайте вернемся к примеру, в котором мы реализовали довольно сложный listcomp:
>>> [
... y for x_i in x
... if x_i % 4 != 0 and x_i % 5 != 0
... if (y := square(multiply(x_i, 3))) % 2 == 0
... ]
[36, 324, 1764, 2916, 4356, 6084, 10404, 12996, 15876, 19044]Вот как выглядит здесь соответствующий цикл for:
>>> output = []
>>> for x_i in x:
... y = square(multiply(x_i, 3))
... if y % 2 == 0 and x_i % 4 != 0 and x_i % 5 != 0:
... output.append(y)
>>> output
[36, 324, 1764, 2916, 4356, 6084, 10404, 12996, 15876, 19044]На самом деле все не так уж плохо. Это пограничная ситуация, в которой некоторые по-прежнему будут выбирать версию listcomp, в то время как другие сочтут ее нечитаемой и вместо этого выберут цикл for. Составление списка по-прежнему прекрасно и для некоторых оно уже перешло черту слишком сложного.
Пример 6: Разделение listcomp.
Давайте воспользуемся тем же примером, что и выше. Давайте попробуем разделить это сложное понимание на несколько, в надежде, что это упростит код:
>>> y_1 = [x_i for x_i in x]
>>> y_2 = [
... y_1_i
... for y_1_i in y_1
... if y_1_i % 4 != 0 and y_1_i% 5 != 0
... ]
>>> y = [
... y_final
... for y_2_i in y_2
... if (y_final := square(multiply(y_2_i, 3))) % 2 == 0
... ]
>>> y
[36, 324, 1764, 2916, 4356, 6084, 10404, 12996, 15876, 19044]Несмотря на разделение, эта версия, еще менее читабельна, чем предыдущая. Это не только намного длиннее, но и менее читабельно. Сложно выбрать этот вариант, но хотелось показать его вам, просто на случай, если вам интересно, сработает ли подобный подход. На этот раз этого не произойдет.
Пример 7: Упрощение операций и фильтров с помощью функций.
Иногда вы можете упростить понимание, экспортировав часть работы, которую необходимо выполнить, во внешние функции. В нашем случае мы можем сделать это как с помощью операций, так и с помощью фильтров:
>>> def filter_data(x_i):
... return x_i % 4 != 0 and x_i % 5 != 0
>>> def filter_output(y_i):
... return y_i % 2 == 0
>>> def pipeline(x_i):
... return square(multiply(x_i, 3))
>>> def get_generator(x):
... return (
... y for x_i in x
... if filter_output(y := pipeline(x_i))
... and filter_data(x_i)
.. )
>>> list(get_generator(x))
[36, 324, 1764, 2916, 4356, 6084, 10404, 12996, 15876, 19044]Это значительно упрощает понимание прочитанного. Однако мы можем сделать то же самое с циклом for:
>>> output = []
>>> for x_i in x:
... y = pipeline(x_i)
... if filter_output(y) and filter_data(x_i):
... output.append(y)
>>> output
[36, 324, 1764, 2916, 4356, 6084, 10404, 12996, 15876, 19044]Но действительно ли этот цикл for лучше, чем соответствующий генератор ниже (скопирован из приведенного выше фрагмента)?
>>> (
... y for x_i in x
... if filter_output(y := pipeline(x_i))
... and filter_data(x_i)
... )Выбор падает на listcomp. Он более лаконичен и выглядит более читабельным.
Присвоение имен
Это хороший момент, чтобы упомянуть об именовании. Посмотрите еще раз на имена функций, используемые в приведенном выше понимании: filter_data, filter_output и pipeline. Это четкие имена, которые сообщают о том, за что они отвечают; таким образом, они должны помочь нам понять, что происходит внутри понимания.
Возможно, кто-то скажет, что это плохой выбор для функций, поскольку описания должны быть короткими, а более короткие названия функций помогли бы нам написать более краткие описания. Они были бы правы только в одном: в том, что понимание было бы более кратким. Но написание кратких объяснений не означает написание хороших, потому что удобочитаемых объяснений. Сравните приведенное выше понимание с приведенным ниже, в котором использованы более короткие, но в то же время гораздо менее значимые имена:
>>> def fd(x_i):
... return x_i % 4 != 0 and x_i % 5 != 0
>>> def fo(y_i):
... return y_i % 2 == 0
>>> def pi(x_i):
... return square(multiply(x_i, 3))
>>> def g_g(x):
... return (y for x_i in x if fo(y := pi(x_i)) and fd(x_i))
>>> list(get_generator(x))
[36, 324, 1764, 2916, 4356, 6084, 10404, 12996, 15876, 19044]Определенно короче — и определенно хуже.
Обратите внимание, что, хотя автор такого понимания будет знать, что fd означает filter_data, в то время как pi означает pipeline, будет ли кто-нибудь еще знать это? Вспомнит ли автор об этом через месяц? Или год?Думается, что нет. Таким образом, это плохое именование, которое не несет никакой реальной коннотации с тем, за что отвечают функции, и чей секретный код (fo расшифровывается как filter_output) будет быстро забыт.
Если вы решите использовать внешние функции для понимания, не забудьте использовать хорошие имена — хорошие, то есть короткие и осмысленные. То же самое относится ко всем именам, используемым в понимании. Здесь, однако, мы должны использовать имена, которые должны быть как можно короче, а не длиннее. Существует неписаное правило, согласно которому, когда переменная имеет узкую область видимости, ей не нужно длинное имя. Хотя это правило не всегда является разумным, оно часто имеет смысл для понимания. Например, рассмотрим эти составы списков:
>>> y = [square(x_i) for x_i in x if x_i % 2 == 0]
>>> y = [square(xi) for xi in x if xi % 2 == 0]
>>> y = [square(p) for p in x if p% 2 == 0]
>>> y = [square(element_of_x) for element_of_x in x if element_of_x % 2 == 0]Первые два работают почти одинаково хорошо, хотя выбор пал бы на первый. Это потому, что x_i выглядит как x с индексом i; xi выглядит по-другому. Итак, мы готовы использовать дополнительный символ _ для соединения x и i, чтобы передать это дополнительное значение. Таким образом, x_i выглядит математически как x_i, что означает, что x_i принадлежит x. Хотя версия xi выглядит довольно похожей, в ней отсутствует это приятное сходство математических уравнений. Отсюда мой выбор в пользу первого.
Зачем использовать в третьей версии p в качестве имени циклической переменной? Что означает p? Если это что-то значит с точки зрения реализуемого нами алгоритма, то прекрасно. Но в остальном это не очень хорошо. В принципе, хорошо использовать имена, которые что-то значат, но помните, что при понимании вы должны использовать короткие имена, которые что-то значат.
В пояснениях вы должны использовать короткие имена, которые что-то значат.
То же самое и в четвертой версии. Хотя имя element_of_x действительно имеет правильное значение, оно излишне длинное. Не используйте длинное имя, когда короткое будет столь же информативным. Так обстоит дело и здесь: x_i намного короче и, по крайней мере, так же информативен, как element_of_x, если не больше — благодаря тому, как x_i резонирует с математическими уравнениями.
Если вы не используете циклическую переменную, используйте _ в качестве ее имени. Например:
>>> template = [(0, 0) for _ in range(10)]Нет необходимости использовать i или что бы мы здесь ни хотели.
Сложно или понятно
Со временем и опытом вы узнаете, что иногда бывает трудно решить, является ли конкретное понимание по-прежнему понятным или достигло, если не перешло, слишком трудной границы. Если вы в растерянности, безопаснее выбрать цикл for, потому что он будет понятен почти всем — в то время как не каждый сможет понять сложный listcomp.
Помните, однако, о том, чтобы сделать понимание как можно более легким. Например, мы сделали это, переместив некоторые или все вычисления во внешние функции с правильными именами (в приведенном выше примере это были pipeline(), filter_data() и filter_output()). Однако не злоупотребляйте этим подходом, поскольку он более многословен, чем чистое понимание. Что еще более важно, редко бывает хорошей идеей определять функции, которые используются в коде только один раз.
Суть в том, что всякий раз, когда вы пишете понимание, которое выглядит сложным, вы должны проанализировать его и решить, достаточно ли оно просто для понимания или нет. Если нет, замените его другим подходом. Иногда конвейеры генератора, основанные на функциональном составе, могут быть хорошим решением.
Не всегда легко решить, какое понимание является слишком сложным. Количество операций не обязательно должно быть хорошим показателем, так как иногда длинное понимание может быть намного легче понять, чем более короткое, в зависимости от того, чего оно направлено на достижение и используемого наименования.
Еще одна вещь, которую следует помнить, - это то, что трудное понимание означает трудность для среднего разработчика, а не для вас. Итак, если вы написали чрезвычайно сложное понимание, которое вы понимаете без проблем, это не значит, что вы должны пойти на это. Возможно, это тот случай, когда вы понимаете это, потому что потратили три часа на написание этих двух строк кода. Итак, не забудьте сделать свое понимание — и код, если уж на то пошло, — понятным и для других.
Переменная scope
То, как переменная scope работает в понимании, отличает их от циклов for — отличается в хорошем смысле: переменная цикла, используемая в понимании, не видна во внешних областях понимания и не перезаписывает переменные из внешних областей.
Будет легче объяснить это на примере:
>>> x = [i**2 for i in range(10)]
>>> x
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> i
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'i' is not definedХотя мы использовали i в качестве циклической переменной внутри понимания списка, она активна только в рамках этого понимания. Он не виден за пределами этой области — он был удален, как только понимание завершило создание списка.
Циклическая переменная, используемая в понимании, не видна во внешних областях понимания и не перезаписывает переменные из внешних областей.
Как показано в приведенном ниже фрагменте, вы можете использовать имя внутри понимания, даже если переменная с тем же именем используется во внешней области. Таким образом, одновременно будут существовать два разных объекта с одинаковым именем. Но эти имена будут видны только в их областях видимости².
>>> i = "this is i"
>>> x = [i**2 for i in range(10)]
>>> x
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> i
'this is i'Конечно, вы не можете использовать переменную внешней области внутри понимания, если циклическая переменная имеет то же имя. Другими словами, у вас нет доступа к внешней области i из понимания списка, который использует переменную внутренней области i для зацикливания (или для чего-либо еще).
Предупреждение: Помните, что это правило не работает с переменными, назначаемыми с помощью оператора walrus:
>>> i = "this is i"
>>> x = [i for j in range(10) if (i := j**2) < 10]
>>> x
[0, 1, 4, 9]
>>> i
81Как вы видите, использование оператора walrus помещает назначенную переменную (здесь, i) во внешнюю область понимания.
Еще одно предупреждение. Не злоупотребляйте этой функцией, так как результирующий код может стать трудным для чтения, как здесь:
>>> x = range(10)
>>> x = [x**2 for x in range(10)]
>>> x
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]Такой подход к областям переменных делает использование понимания безопасным, поскольку вам не нужно беспокоиться о том, что циклическая переменная понимания перезапишет важную переменную. Как упоминалось выше, это не так, как работают циклы for:
>>> i = "this is i"
>>> for i in range(3):
... print(i)
...
0
1
2
>>> i
2Как вы видите, если вы используете то же имя в цикле for, переменная, которая была названа таким же образом во внешней области видимости, будет перезаписана текущим значением переменной цикла; в конечном итоге, с ее последним значением.
Производительность
Одним из аспектов, который многие разработчики учитывают при принятии решения об использовании синтаксического сахара, является производительность. Некоторые говорят, что это не так уж важно; другие говорят, что это так.
производительность имеет значение, когда… когда важна производительность.
Даже если это может показаться немного забавным, если не глупым, в этом есть полный смысл. Если не имеет значения, является ли ваше приложение быстрым или нет, то почему вы должны беспокоиться о производительности? В такой ситуации лучше использовать другие факторы для выбора стиля кодирования, такие как краткость и удобочитаемость. Однако, когда производительность действительно имеет значение, и особенно когда это имеет большое значение (например, в информационных панелях), вы можете оптимизировать свой код за счет удобочитаемости.
Еще одна вещь, которая имеет значение, - это время разработки. Если это имеет значение, то, возможно, вам не стоит тратить два полных дня на оптимизацию кода, которая позволила бы вам сэкономить две секунды времени выполнения приложения.
Хорошо, теперь, когда мы знаем, когда следует учитывать производительность, давайте обсудим, насколько эффективны понимания. Как правило, производительность сильно зависит от данных и самого понимания, поэтому, если производительность имеет значение для конкретного понимания, вам следует сравнить это самое понимание (если это возможно).
Здесь вы увидите, как выполнить такой бенчмаркинг с помощью встроенного модуля timeit. Вы можете использовать приведенный ниже фрагмент в качестве шаблона для проведения собственных тестов.
# benchmark_comprehension.py
import timeit
def benchmark(code_comprehension: str,
code_alternative: str,
setup: str,
n: int,
rep: int) -> None:
t_comprehension = timeit.repeat(
code_comprehension,
setup=setup,
number=n,
repeat=rep
)
t_alternative = timeit.repeat(
code_alternative,
setup=setup,
number=n,
repeat=rep
)
print(
"Time for the comprehension :"
f" {round(min(t_comprehension), 4)}"
"\nTime for the alternative : "
f"{round(min(t_alternative), 4)}"
"\ncomprehension-to-alternative ratio: "
f"{round(min(t_comprehension)/min(t_alternative), 3)}"
)
# timeit settings
n = 100
rep = 7
# code
setup = """pass"""
code_comprehension = """
for _ in [x**2 for x in range(1_000_000)]:
pass
"""
code_alternative = """
for _ in map(lambda x: x**2, range(1_000_000)):
pass
"""
if __name__ == "__main__":
benchmark(code_comprehension, code_alternative, setup, n, rep)Чтобы запустить этот код, используйте следующую команду оболочки (работает как в Windows, так и в Linux):
$ python benchmark_comprehension.pyЭто позволит запустить тесты и вывести результаты на консоль. Этот, например, предоставил следующий вывод:
Time for the comprehension : 20.3807
Time for the alternative : 19.9166
comprehension-to-alternative ratio: 1.023Вы можете изменить следующие части фрагмента:
- Установочный код → изменить
setup; это код, который выполняется перед запуском эталонного кода. - Код → измените
code_comprehensionиcode_alternative; обратите внимание, что код написан в тройных кавычках, поэтому вы можете разделить его на большее количество строк; однако вы также можете использовать однострочные символы. - Количество повторов, переданное в
timeit.repeat()→ изменитьrep. - Количество раз для запуска кода, переданного в
timeit.repeat()→ изменитьn.
Код настолько простой, насколько это было возможно, именно поэтому не использованы аргументы командной строки; просто простое приложение для бенчмаркинга. Вы, конечно, можете улучшить его так, как вам захочется.
Cравнение пониманий
Это, пожалуй, самый важный вопрос, который мы должны задать, прежде чем проводить такие контрольные показатели. Очевидный, но неудовлетворительный ответ противоречит наилучшему соответствующему подходу; он неудовлетворителен, потому что на самом деле не отвечает на вопрос. Давайте подумаем об этом.
- Generator expressions
Легко решить, с чем мы должны сравнивать выражения генератора: map() и filter() и/или их комбинации, или с любым другим подходом, возвращающим генератор. Две функции возвращают объекты map и filter соответственно, и они являются генераторами, точно так же, как выражения генератора.
- List comprehensions
Одним из очевидных подходов для сравнения является цикл for. Нам нужно помнить, что в простых сценариях понимание списка будет более читабельным, чем соответствующие циклы for; однако в сложных сценариях обычно будет верно обратное.
Другим подходом может быть использование map() и/или filter() с последующим использованием list(). В этом случае, однако, имейте в виду, что это не естественное сравнение, поскольку, когда вам нужен список, вы используете понимание списка, а не понимание генератора.
- Dictionary comprehensions
Как и выше, у нас есть две наиболее естественные версии: цикл for и функции map() и/или filter(). Однако на этот раз использовать эти две функции немного сложнее, так как нам нужно использовать пары ключ-значение, поэтому функция также должна возвращать их. Мы показали, как это сделать выше, используя функцию-оболочку. Истина, тем не менее, заключается в том, что в этом отношении здесь гораздо проще использовать понимание dict.
- Set comprehensions
С наборами ситуация почти такая же, как и со списками, поэтому используйте для них приведенные выше предложения.
Некоторые контрольные показатели
Как уже упоминалось, мы даже не будем пытаться анализировать эффективность понимания здесь, поскольку нет простого ответа на вопрос о том, являются ли они более эффективными, чем их альтернативы. Ответ зависит от контекста. Однако хотелось бы пролить некоторый свет на этот аспект использования понятий — по крайней мере, показать вам основы.
В следующих примерах мы приведем
- аргументы
nиrepдолжны быть переданы вtimeit.repeat()какnumberиrepeatсоответственно; setup,code_comprehensionиcode_alternativeиз фрагмента теста, предоставленного выше;- выходные данные, отформатированные в приведенном ранее примере.
Benchmark 1
n = 1_000_000
rep = 7
# code
length = 10
setup = """pass"""
code_comprehension = f"""y = [x**2 for x in range({length})]"""
code_alternative = f"""
y = []
for x_i in range({length}):
y.append(x_i**2)
"""Time for the comprehension : 1.6318
Time for the alternative : 1.7296
comprehension-to-alternative ratio: 0.943Результаты для length = 100 (то есть для списков из 100 элементов) и n = 100_000:
Time for the comprehension : 1.4767
Time for the alternative : 1.6281
comprehension-to-alternative ratio: 0.907Теперь для length = 1000 (списки из 1000 элементов) и n = 10_000:
Time for the comprehension : 1.5612
Time for the alternative : 1.907
comprehension-to-alternative ratio: 0.819И, в конечном счете, для length = 10_000 (списки из 10_000 элементов) и n = 1000:
Time for the comprehension : 1.5692
Time for the alternative : 1.9641
comprehension-to-alternative ratio: 0.799В выходных данных наиболее важным элементом, на который следует обратить внимание, является соотношение, поскольку оно не содержит единиц измерения, в то время как времена в первых двух строках - нет, в зависимости от number (в нашем случае n). Как вы видите, длина построенного списка имеет значение: чем он длиннее, тем относительно медленнее выполняется цикл for.
Benchmark 2
Мы определим функцию length(x: Any) -> int, которая
- возвращает
0, когдаxявляется пустым итерируемым илиNone; - возвращает длину объекта, когда она может быть определена;
- в противном случае возвращает
1.
Следовательно, например, число будет иметь длину 1. Мы будем использовать эту функцию для создания словаря, который имеет
- ключи, являющиеся значениями из итерируемого;
- значения, являющиеся кортежем длины объекта, как определено выше; и количества этого элемента в итерируемом
x.
setup = """
def length(x):
if not x:
return 0
try:
return len(x)
except:
return 1
x = [1, 1, (1, 2, 3), 2, "x", "x", 1, 2, 1.1,
"x", 66, "y", 34, 34, "44", 690.222, "bubugugu", "44"]
"""
code_comprehension = """
y = {el: (length(el), x.count(el)) for el in set(x)}
"""
code_alternative = """
y = {}
for el in set(x):
y[el] = (length(el), x.count(el))
"""Time for the comprehension : 0.5727
Time for the alternative : 0.5736
comprehension-to-alternative ratio: 0.998Когда мы создали x, состоящий из 100 списков x, мы получили comprehension-to-alternative ratio: 1.009. Как мы видим, длина списка в данном случае не имеет значения: оба метода одинаково эффективны — хотя понимание dict намного короче и элегантнее, но нам нужно знать понимание Python, чтобы быть в состоянии оценить их.
Вам нужно знать основы Python, чтобы быть в состоянии оценить их по достоинству.
Используйте понимание, когда оно вам нужно
Это может показаться странным, но может возникнуть соблазн использовать понимания, даже если вам не нужен результирующий объект. Это один из примеров этого:
>>> def get_int_and_float(x):
... [print(i) for i in x]
... return [i for i in x if isinstance(i, (int, float))]
>>> y = get_int_and_float([1, 4, "snake", 5.56, "water"])
1
4
snake
5.56
water
>>> y
[1, 4, 5.56]Обратите внимание, что делает эта функция: она принимает iterable и фильтрует данные, удаляя те, которые не относятся к типам int и float. Такое использование понимания списка, которое мы видим в строке return, просто прекрасно. Тем не менее, мы можем видеть также другое понимание списка, используемое в функции: [print(i) for i in x]. Это понимание списка выводит только все элементы, и результирующий список никак не сохраняется и не используется. Итак, для чего он был создан? Нужно ли нам это? Конечно нет. Вместо этого мы должны использовать цикл for:
>>> def get_int_and_float(x):
... for i in x:
... print(i)
... return [i for i in x if isinstance(i, (int, float))]
>>> y = get_int_and_float([1, 4, "snake", 5.56, "water"])
1
4
snake
5.56
water
>>> y
[1, 4, 5.56]В этом примере цикл for является естественным подходом.
Это очень простой пример, и он может показаться немного слишком простым. Тогда давайте рассмотрим другой пример. Представьте себе функцию, которая считывает текст из файла, каким-то образом обрабатывает текст и записывает выходные данные (обработанный текст) в другой файл:
import pathlib
def process_text_from(input_path: pathlib.Path
output_path: pathlib.Path) -> None:
# text is read from input_path, as string;
# it is then processed somehow;
# the resulting processed_text object (also string)
# is written to an output file (output_path)
def make_output_path(path: pathlib.Path):
return path.parent / path.name.replace(".", "_out.")Важно: Обратите внимание, что функция process_text_from() ничего не возвращает.
Далее нам нужно реализовать функцию, которая запускает process_text_from() для каждого элемента повторяющегося набора путей, input_paths:
from typing import List
def process_texts(input_paths: List[pathlib.Path]) -> None:
[process_text_from(p, make_output_path(p)) for p in input_paths]Опять же, это не полностью функциональное понимание списка: мы создаем список, который не сохраняется и не используется. Если вы видите что-то подобное, это намек на то, что вам вряд ли следует использовать понимание. Подумайте о другом подходе.
Здесь, опять же, цикл for кажется лучшим выбором:
def process_texts(input_paths: List[pathlib.Path]) -> None:
for p in input_paths:
process_text_from(p, make_output_path(p))Вывод
Python прост и удобочитаем, или, по крайней мере, так нам говорят — и это то, что думает о нем большинство питонистов. Как простота, так и удобочитаемость являются результатом, по крайней мере частично, синтаксического сахара, который предлагает язык. Возможно, наиболее важным элементом этого синтаксического сахара является понимание.
Понимания позволяют нам писать лаконичный и читаемый код — и элегантный код. Иногда код сложный, но обычно он прост — по крайней мере, для тех, кто знает Python. Вот почему у начинающих Python возникают проблемы с пониманием понятий и, следовательно, с их оценкой; и именно поэтому они начинают изучать их, как только могут.
Понимания позволяют нам писать лаконичный и читаемый код — и элегантный код.
Это хорошая идея, потому что понимание присутствует повсюду в коде Python. Сложно представить себе разработчика на Python среднего уровня, не говоря уже о продвинутом разработчике на Python, который не пишет понимания. Они настолько естественны для Python, что не существует Python без понимания.
Цель этой статьи - познакомить с понятиями Python: понятиями списка, словаря и набора; и выражениями генератора. Последний тип сильно отличается от других, так что, возможно, именно поэтому его название так отличается. Выражения генератора имеют синтаксис, аналогичный синтаксису других типов, но они создают генераторы.
Вот краткое изложение вместе с несколькими дополнительными мыслями на вынос о понимании:
- Используйте пояснения, чтобы облегчить пользователю понимание того, за что отвечает код.
- Когда вам нужно создать список, используйте понимание списка, а не другой тип понимания. Точно так же, когда вам нужно создать объект определенного типа, используйте соответствующее понимание списка: dictcomp для словаря, setcomp для набора и generator expression для генератора.
- Иногда может возникнуть соблазн использовать особенно сложное понимание. Некоторые поддаются этому искушению, надеясь, что таким образом они покажут, что могут писать сложный и продвинутый код на Python. Сопротивляйтесь такому искушению любой ценой. Вместо того чтобы выпендриваться, напишите понятный код; когда понимание неясно, не поддавайтесь искушению сохранить его в коде в любом случае. Никогда не превращайте свое понимание в непонимание, точно так же, как никогда не поворачивайтесь спиной к удобочитаемости.
- Когда вы видите, что понимание становится более сложным, чем читабельным, пришло время подумать об упрощении кода — либо путем упрощения кода понимания, либо с помощью альтернативного решения. Может быть, лучшие имена справятся с этой задачей? Или разбить понимание на несколько строк? Или, если вы уже сделали это, может быть, вы могли бы попытаться изменить это разделение? Если ничего не помогает, попробуйте другое решение. Иногда цикл
forбудет работать лучше всего; иногда что-то еще. - Если вы решите использовать понимание, даже если знаете, что это слишком сложно, имейте в виду, что большинство продвинутых программистов подумают, что вы хотели покрасоваться. Если только вы осознаете эту проблему и попытаетесь бороться с ней, со временем и опытом вы заметите, что противостоять искушению становится легче.
- В некоторых случаях вы можете заменить чрезмерно сложное понимание конвейером генератора; именно в этой ситуации вы продемонстрируете довольно глубокое понимание программирования на Python, в отличие от предыдущего.
- Помните, как работает область понимания. Используйте его в своих целях — но не злоупотребляйте им чрезмерно.
- Работая над пониманием, обращайте внимание на каждую его деталь. Это включает в себя, разделяете ли вы его на большее количество строк; количество строк, на которые его нужно разделить, и как это сделать; следует ли использовать
ifилиand; выглядит ли понимание визуально хорошо; и тому подобное. Рассмотрение каждой мельчайшей детали ваших представлений может помочь вам понять их гораздо лучше. - Присвоение имен важно по нескольким причинам: понимания кратки и, следовательно, деликатны, одна ошибка может испортить все понимание; они часто несут большую ответственность, например, за применение одной или нескольких функций, фильтрацию данных и/или выходных данных и циклический перебор итераций; и они должны использовать по крайней мере одна переменная локальной области видимости (т.е. та, которая ограничена областью понимания). Таким образом, имеет значение, как вы называете свои объекты внутри понимания и за его пределами. Используйте следующую рекомендацию для присвоения имен переменным внутри представлений: используйте короткие и осмысленные имена.
- Не используйте понимания, когда вам не нужен результирующий объект.
Никогда не превращайте свое понимание в непонимание, точно так же, как никогда не поворачивайтесь спиной к удобочитаемости.
Сноски
¹ В R ситуация немного хуже. Встроенная функция Map() (из базы R) принимает функцию в качестве первого аргумента и вектор в качестве второго:
> Map(function(x) x^2, 1:3)
[[1]]
[1] 1
[[2]]
[1] 4
[[3]]
[1] 9Однако функция purrr::map(), гораздо более популярная, особенно среди пользователей dplyr, принимает те же аргументы, но в обратном порядке:
> purrr::map(1:3, function(x) x^2)
[[1]]
[1] 1
[[2]]
[1] 4
[[3]]
[1] 9Это связано с тем, что когда вы используете оператор pip, %>%, вы используете вектор для конвейера:
> library(dplyr)
> 1:3 %>% purrr::map(function(x) x^2)Теоретически, вы можете сделать это в обратном порядке, используя Map():
> (function(x) x^2) %>% Map(1:3)
[[1]]
[1] 1
[[2]]
[1] 4
[[3]]
[1] 9но это кажется неестественным.
² Если вы знакомы с Go, то, вероятно, заметили сходство, поскольку именно так работают области видимости в Go.