Совет: самый простой способ получить данные с веб-страницы в Python
Допустим, вы ищете в Интернете некоторые необработанные данные, необходимые для проекта, и наткнулись на веб-страницу такого содержания:
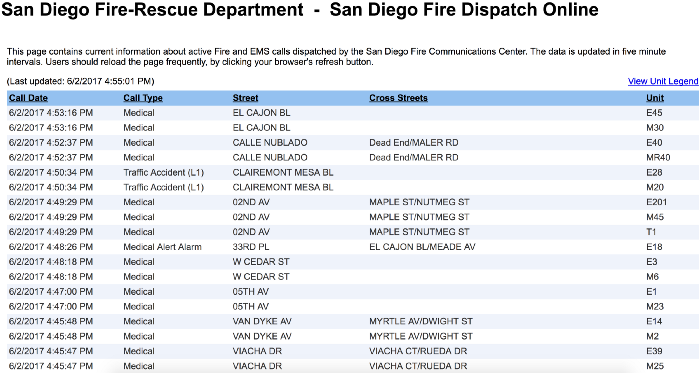
Вы нашли именно то, что вам нужно - актуальную страницу с именно теми данными, которые вам нужны!
Но плохая новость заключается в том, что данные находятся внутри веб-страницы, и нет API, который можно использовать для получения необработанных данных. Так что теперь вам придется потратить минут 30 на то, чтобы составить дрянной сценарий для очистки данных. Это не сложно, но это пустая трата времени, которое вы могли бы потратить на что-то полезное. И конечно же 30 минут легко могут превратиться в несколько часов.
Для меня такие вещи случаются постоянно.

К счастью, есть супер простой ответ. В библиотеке Pandas есть встроенный метод очистки табличных данных от html-страниц, называемый read_html():
import pandas as pd
tables = pd.read_html("https://apps.sandiego.gov/sdfiredispatch/")
print(tables[0])Это так просто! Pandas найдет любые значимые HTML-таблицы на странице и вернет каждую из них в качестве нового объекта DataFrame.
Чтобы обновить нашу программу с игрушечной до реальной, давайте скажем Pandas, что в нулевой строке таблицы есть заголовки столбцов, и попросим ее преобразовать текстовые даты в объекты времени:
import pandas as pd
calls_df, = pd.read_html("http://apps.sandiego.gov/sdfiredispatch/", header=0, parse_dates=["Call Date"])
print(calls_df)И в результате мы получим:
Call Date Call Type Street Cross Streets Unit 0 2017-06-02 17:27:58 Medical HIGHLAND AV WIGHTMAN ST/UNIVERSITY AV E17 1 2017-06-02 17:27:58 Medical HIGHLAND AV WIGHTMAN ST/UNIVERSITY AV M34 2 2017-06-02 17:23:51 Medical EMERSON ST LOCUST ST/EVERGREEN ST E22 3 2017-06-02 17:23:51 Medical EMERSON ST LOCUST ST/EVERGREEN ST M47 4 2017-06-02 17:23:15 Medical MARAUDER WY BARON LN/FROBISHER ST E38 5 2017-06-02 17:23:15 Medical MARAUDER WY BARON LN/FROBISHER ST M41
И как эти данные живут в DataFrame, мир принадлежит вам. Желаете, чтобы данные были доступны в виде записей JSON? Это просто еще одна строка кода!
import pandas as pd
calls_df, = pd.read_html("http://apps.sandiego.gov/sdfiredispatch/", header=0, parse_dates=["Call Date"])
print(calls_df.to_json(orient="records", date_format="iso"))Если запустить этот код, вы получите прекрасный вывод json (даже при правильном форматировании даты ISO 8601!):
[
{
"Call Date": "2017-06-02T17:34:00.000Z",
"Call Type": "Medical",
"Street": "ROSECRANS ST",
"Cross Streets": "HANCOCK ST/ALLEY",
"Unit": "M21"
},
{
"Call Date": "2017-06-02T17:34:00.000Z",
"Call Type": "Medical",
"Street": "ROSECRANS ST",
"Cross Streets": "HANCOCK ST/ALLEY",
"Unit": "T20"
},
{
"Call Date": "2017-06-02T17:30:34.000Z",
"Call Type": "Medical",
"Street": "SPORTS ARENA BL",
"Cross Streets": "CAM DEL RIO WEST/EAST DR",
"Unit": "E20"
}
// etc...
]Вы даже можете сохранить данные прямо в файл CSV или XLS:
import pandas as pd
calls_df, = pd.read_html("http://apps.sandiego.gov/sdfiredispatch/", header=0, parse_dates=["Call Date"])
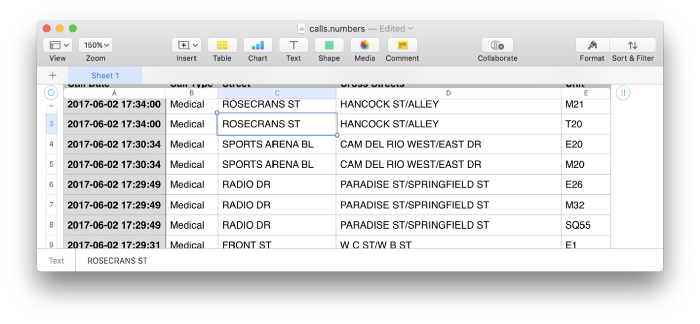
calls_df.to_csv("calls.csv", index=False)Запустите его и дважды щелкните на файле call.csv, чтобы открыть его в приложении для работы с электронными таблицами:
И, конечно же, Pandas упрощает фильтрацию, сортировку или обработку данных:
>>> calls_df.describe()
Call Date Call Type Street Cross Streets Unit
count 69 69 69 64 69
unique 29 2 29 27 60
top 2017-06-02 16:59:50 Medical CHANNEL WY LA SALLE ST/WESTERN ST E1
freq 5 66 5 5 2
first 2017-06-02 16:36:46 NaN NaN NaN NaN
last 2017-06-02 17:41:30 NaN NaN NaN NaN
>>> calls_df.groupby("Call Type").count()
Call Date Street Cross Streets Unit
Call Type
Medical 66 66 61 66
Traffic Accident (L1) 3 3 3 3
>>> calls_df["Unit"].unique()
array(['E46', 'MR33', 'T40', 'E201', 'M6', 'E34', 'M34', 'E29', 'M30',
'M43', 'M21', 'T20', 'E20', 'M20', 'E26', 'M32', 'SQ55', 'E1',
'M26', 'BLS4', 'E17', 'E22', 'M47', 'E38', 'M41', 'E5', 'M19',
'E28', 'M1', 'E42', 'M42', 'E23', 'MR9', 'PD', 'LCCNOT', 'M52',
'E45', 'M12', 'E40', 'MR40', 'M45', 'T1', 'M23', 'E14', 'M2', 'E39',
'M25', 'E8', 'M17', 'E4', 'M22', 'M37', 'E7', 'M31', 'E9', 'M39',
'SQ56', 'E10', 'M44', 'M11'], dtype=object)Ничто из этого не является ракетостроением или чем-то еще, но я использую его так часто, что я думал, что этим стоит поделиться.