Создание приложения для распознавания изображений на Javascript с использованием Pinecone, Hugging Face и Vercel

Мир ИИ быстро расширяется, и теперь к нему присоединяется экосистема JavaScript/TypeScript. С появлением таких инструментов, как Pinecone, HuggingFace, OpenAI, Cohere и многих других, разработчики JavaScript могут быстрее создавать приложения ИИ, решая новые задачи, которые когда-то были доступны только инженерам по машинному обучению и специалистам по данным.
Традиционно Python был основным языком для решений AI/ML. Во многих случаях продуктом такого типа кода является блокнот Python. Но, как мы все знаем, создание полноценных приложений ИИ обычно требует больше усилий, особенно когда нам нужно, чтобы наши приложения были коммерческого уровня. Это требует, чтобы мы думали о решении гораздо более целостно.
Преимущество экосистемы Javascript в том, что она с самого начала ориентирована на приложения. Он имеет огромный набор инструментов, которые обеспечивают высокопроизводительные и масштабируемые приложения как на периферии, так и на сервере. Разработчики Javascript имеют уникальные возможности для создания решений ИИ, и теперь они могут транслировать свой набор навыков и осваивать ИИ, не отказываясь от инструментов, которые они знают и любят.
В этом посте мы увидим, как мы можем использовать известные фреймворки и инструменты Javascript для создания приложения ИИ. Как вы увидите, мы не будем обучать модель машинного обучения с нуля — и нам не нужно изучать математику, стоящую за этими алгоритмами. Но мы по-прежнему сможем использовать их для создания мощного ИИ-продукта.
Вариант использования, который мы рассмотрим, — это распознавание изображений: мы хотим, чтобы модель ИИ распознавала различные объекты, лица и т. д., и мобильное приложение, которое позволит пользователям просто наводить камеру телефона на любой объект, присваивать ему метку. и «обучить» приложение обнаруживать этот объект. Затем, после завершения обучения, каждый раз, когда пользователь наводит камеру на объект, появляется обнаруженная метка.
Нам также нужно, чтобы наше приложение поддерживало несколько пользователей, где каждый пользователь может маркировать и обучать свои собственные объекты, чтобы другие пользователи не видели эти метки. Наконец, нам нужно разрешить пользователям сбрасывать свои ярлыки и удалять свои учетные записи, если они того пожелают.
Прежде чем мы углубимся в сборку, давайте обсудим некоторые потенциальные коммерческие варианты использования этого типа приложений.
- Производство и контроль качества: это приложение может усовершенствовать системы производства и контроля качества. Например, его можно использовать для маркировки конкретных систем в различных состояниях (например, «исправное» состояние и «сломанное» состояние) и для оптимизации управления этими системами.
- Развлечения и игры: представьте себе возможности создания захватывающих и интерактивных впечатлений в мире развлечений и игр. Эта технология позволяет разработчикам указывать пользовательские метки, что позволяет распознавать и вовлекать уникальных персонажей и сцены.
- Искусство и культура. Этот тип приложений можно использовать для признания и повышения культурной и образовательной ценности произведений искусства. Указав пользовательские метки, системы, связанные с искусством и культурой, могут точно идентифицировать и отслеживать различные произведения искусства.
Сборка
В этом посте вы узнаете, как создать приложение для распознавания изображений, используя Hugging Face, Pinecone, Vercel и React Native (с Expo). Если вы не знакомы с каким-либо из них, вот краткое введение:
- Hugging Face — это платформа, которая предоставляет нам большую коллекцию предварительно обученных и готовых к использованию моделей ИИ для различных задач и областей. Это также позволяет нам размещать собственные модели и использовать их через простой API. В этом посте мы будем использовать пользовательскую модель CLIP для создания векторных вложений для любого изображения (мы поговорим о вложениях позже в этом посте) вместо того, чтобы предсказывать фиксированный набор классов.
- Pinecone — это масштабируемая и производительная база данных векторов. Это позволяет нам хранить и запрашивать многомерные векторы, такие как вложения, сгенерированные нашей моделью CLIP, и находить наиболее похожие в режиме реального времени. Pinecone также предоставляет простой и интуитивно понятный API, который хорошо интегрируется с нашей серверной частью Node.js.
- Vercel — это платформа, которая позволяет нам развертывать бессерверные функции и статические веб-сайты с минимальной настройкой и хлопотами. Vercel также предоставляет нам щедрый уровень бесплатного пользования и глобальную пограничную сеть, которая обеспечивает низкую задержку и высокую доступность для нашего приложения.
- React Native (и Expo) — это фреймворк, который позволяет нам создавать нативные мобильные приложения с использованием Javascript и React. React Native также дает нам доступ ко многим датчикам и функциям, которые существуют в телефонах, например к камере, которую мы будем использовать для захвата изображений для нашего приложения.
Приложение будет работать в два этапа: «обучение» и «обнаружение».
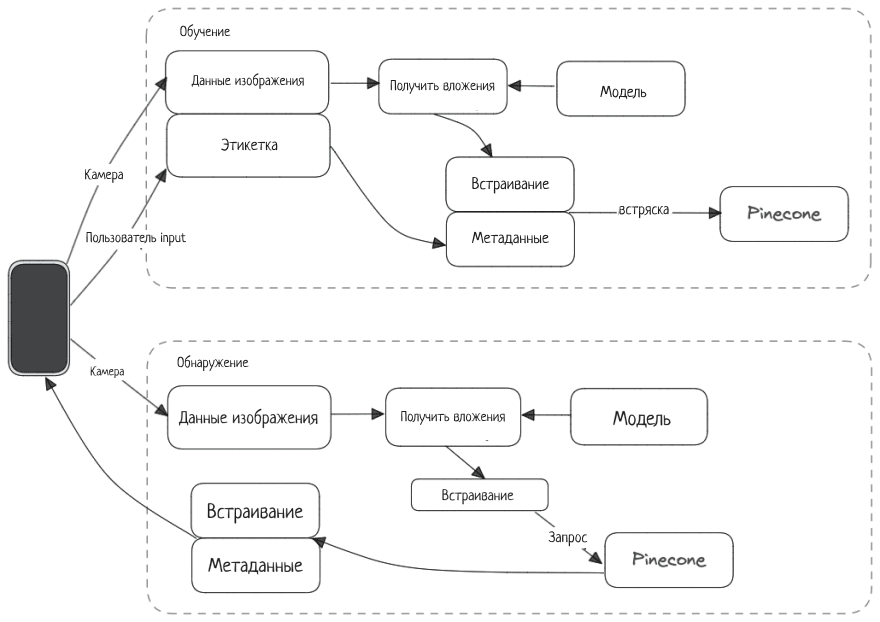
- Во время обучения устройство отправляет данные камеры и этикетки на серверную часть. Серверная часть получает вложения из модели Hugging Face, объединяет вложения и метку и отправляет их в Pinccone.
- Во время обнаружения данные изображения с камеры отправляются на серверную часть. Серверная часть получает вложения и использует их в качестве полезной нагрузки для запроса Pinecone. Pinecone возвращает результат с соответствующими вложениями и соответствующей меткой.
Мы собираемся научиться:
- Создайте пользовательскую конечную точку HuggingFace и запросите ее из бэкэнда Node.JS.
- Настройте и взаимодействуйте с Pinecone с помощью клиента Pinecone Node.JS.
- Разверните серверную часть в Vercel
Примечание. Хотя мы не будем подробно рассказывать о сборке приложения React-Native, вы можете найти код приложения в этом репозитории Github.
Создание пользовательской конечной точки вывода Hugging Face
В этом примере мы будем использовать модель CLIP, которая представляет собой мультимодальную модель компьютерного зрения. По умолчанию CLIP предоставляет нам классификацию изображений по изображению (и, возможно, тексту).
В этом случае мы будем использовать не классификации, а векторные вложения для изображений. Проще говоря, векторные вложения — это векторное представление изображения, поскольку модель «понимает» его (поэтому вместо того, чтобы говорить «лошадь» или «кошка», она выдает массив чисел — он же вектор). С технической точки зрения, модель имеет много слоев, где последним слоем является классификационный слой. Предпоследний слой модели создает векторное представление, которое мы называем «встраиванием».
Поскольку мы не пытаемся получить конкретные классификации из модели и нам нужны только векторные вложения, нам нужно создать пользовательскую конечную точку вывода. Давайте посмотрим, как это делается.
Настройка репозитория HuggingFace
Во-первых, мы инициализируем новую модель в HuggingFace:
Клонируйте репозиторий модели, выполнив следующее:
git lfs install
git clone https://huggingface.co/[your-repo]/clip-embeddingsСоздание пользовательской конечной точки вывода
В клонированном репозитории создайте новый файл requirements.txt с необходимыми зависимостями:
pillow
numpyЗатем создайте файл handler.py, который будет обрабатывать входящие запросы к конечной точке:
from typing import Dict, List, Any
import numpy as np
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
from io import BytesIO
import base64
class EndpointHandler():
def __init__(self, path=""):
# Preload all the elements you we need at inference.
self.model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
self.processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def __call__(self, data: Dict[str, Any]) -> List[Dict[str, Any]]:
inputs = data.get("inputs")
text = inputs.get("text")
imageData = inputs.get("image")
image = Image.open(BytesIO(base64.b64decode(imageData)))
inputs = self.processor(text=text, images=image, return_tensors="pt", padding=True)
outputs = self.model(**inputs)
embeddings = outputs.image_embeds.detach().numpy().flatten().tolist()
return { "embeddings": embeddings }Класс EndpointHandler инициализирует модель CLIP и процессор из модели (openai/clip-vit-base-patch32). Функция __init__ вызывается при инициализации конечной точки и делает модель и процессор доступными при вызовах конечной точки. Процессор примет наши входные данные и преобразует их в структуру данных, ожидаемую моделью (сейчас мы углубимся в подробности).
Метод __call__ — это основная функция, которая выполняется при вызове конечной точки. Этот метод принимает словарь данных в качестве входных данных и возвращает список словарей в качестве выходных данных. Словарь данных содержит ключ «входы», который, в свою очередь, содержит два ключа: «text» и «image». «text» — это массив текстовых строк, а «image» — закодированное изображение в формате base64.
Затем метод преобразует данные изображения в кодировке base64 в объект изображения PIL и использует процессор для подготовки входных данных для модели. Процессор размечает текст, преобразует его в тензоры и при необходимости выполняет заполнение.
Затем обработанные входные данные передаются в модель CLIP для логического вывода, а встраивания изображений извлекаются из выходных данных модели. Затем вложения выравниваются и преобразуются в список, который возвращается в качестве выходных данных конечной точки. На выходе получается словарь с одним ключом «вложения», содержащий список вложений.
Развертывание модели в Hugging Face
Чтобы развернуть эту конечную точку, отправьте код обратно в репозиторий HuggingFace. Затем в консоли Hugging Face нажмите кнопку развертывания по щелчку для модели.
Следуйте инструкциям и создайте «Protected» конечную точку, используя предпочитаемого облачного провайдера. После настройки конечной точки вы получите URL-адрес конечной точки. Мы будем использовать это позже на нашем сервере вместе с вашим ключом API HuggingFace.
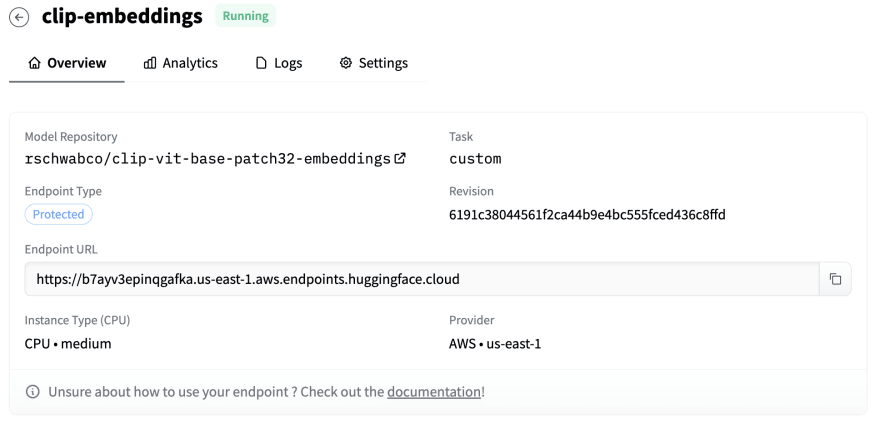
После настройки конечной точки Hugging Face пришло время перейти к настройке индекса Pinecone.
Настройте Pinecone Index
Создайте учетную запись Pinecone и нажмите кнопку «Create Index». Вы увидите следующий экран:
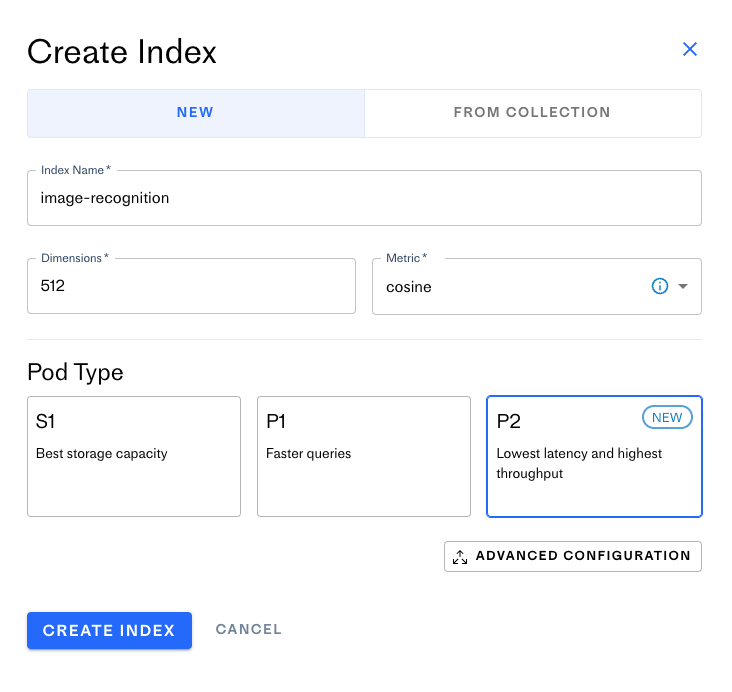
Модель CLIP имеет 512 измерений и использует метрику косинусного подобия, поэтому вы выберете те же настройки для индекса. Вы можете выбрать любой тип модуля, но для идеальной производительности выберите тип модуля P2. Нажмите «Create Index,», и инициализация индекса может занять до нескольких минут.
Находясь в консоли Pinecone, нажмите «API Keys» и получите ключ API Pinecone — он понадобится вам для настройки серверной части Node.JS.
Настройка бэкенда Node.JS
Теперь, когда вы настроили индекс, вы можете создать сервер, который будет с ним взаимодействовать. Полный код сервера доступен в этом репозитории.
Установите зависимости
Мы собираемся использовать Express и Pinecone NodeJS client. Выполните следующую команду, чтобы установить их:
npm install --save express body-parser @pinecone-database/pineconehandleImage получает изображения с мобильного устройства, выглядит так:
const handleImage = async (req, res) => {
const data = req.body;
const { data: imageData, uri, label, stage, user } = data;
const id = `${label}-${md5(uri)}`;
const userHash = md5(user);
const text = "default";
try {
const embeddings = await getEmbeddings(imageData, [text]);
const result = await handleEmbedding({
id,
embeddings,
text,
label,
stage,
user: userHash,
});
res.json(result);
} catch (e) {
const message = `Failed handling embedding: ${e}`;
console.log(message, e);
res.status(500).json({ message });
}
};Далее делаем следующее:
- Извлеките image data, label, stage, user identifier и image identifier из тела запроса.
- Создайте идентификатор для захваченного изображения
- Хэшируйте user identifier с помощью вспомогательной функции (
md5) - Вызовите функцию
getEmbeddings, чтобы получить вложения для изображения. - Вызовите
handleEmbeddings, чтобы правильно обработать этап обучения и обнаружения.
Функция getEmbeddings просто отправляет данные изображения (вместе с необязательным текстом) в конечную точку вывода Hugging Face и возвращает вложения.
const getEmbeddings = async (imageBase64, text) => {
const data = {
inputs: {
image: imageBase64,
text,
},
};
try {
const response = await fetch(inferenceEndpointUrl, {
method: "POST",
headers: {
Authorization: `Bearer ${inferenceEndpointToken}`,
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
const json = await response.json();
return json.embeddings;
} catch (e) {
console.log(e);
}
};Как мы видели выше, серверная часть Node.JS должна обрабатывать состояния «обучения» и «обнаружения», в которых находится приложение. Функция handleEmbedding делает именно это:
const handleEmbedding = async ({
id,
embeddings,
text,
label,
stage,
user,
}) => {
switch (stage) {
case "training":
return await saveEmbedding({
id,
values: embeddings,
namespace: user,
metadata: { keywords: text, label },
});
case "detecting":
return await queryEmbedding({
values: embeddings,
namespace: user,
});
}
};- В режиме «обучения» функция handleEmbeddings отправит вложения, идентификатор пользователя, а также метаданные, которые включают метку, которую пользователь предоставил для saveEmbeddings.
- В режиме «обнаружения» функция
handleEmbeddingsотправит вложения и идентификатор пользователя в функциюqueryEmbedding.
В обоих случаях мы будем использовать идентификатор пользователя для записи и чтения вложений в пространство имен в Pinecone, что обеспечит отделение данных каждого пользователя от данных всех других пользователей.
Чтобы сохранить вложения, мы выбираем индекс, в который мы будем писать, а затем используем метод index.upsert.
const saveEmbedding = async ({ id, values, metadata, namespace }) => {
const index = pineconeClient.Index(indexName);
const upsertRequest = {
vectors: [
{
id,
values,
metadata,
},
],
namespace,
};
try {
const response = await index.upsert({ upsertRequest });
return response?.upsertedCount > 0
? {
message: "training",
}
: {
message: "failed training",
};
} catch (e) {
console.log("failed", e);
}
};Чтобы запросить вложение, мы выбираем индекс, указываем количество результатов, которые мы хотим получить обратно из индекса, с помощью параметра topK (здесь нам нужен только один результат) и передаем вектор, который мы хотим использовать для запроса.
Как мы упоминали ранее, пространство имен будет идентификатором пользователя, который ограничит результаты вложениями, созданными этим пользователем. Это также повысит производительность наших запросов, поскольку запрос будет выполняться только для подмножества векторов, принадлежащих пользователю, вместо всех векторов в индексе.
Параметр includeMetadata гарантирует, что мы вернем метаданные, связанные с вектором, включая метку, которую мы в конечном итоге хотим отобразить пользователю.
const queryEmbedding = async ({ values, namespace }) => {
const index = pineconeClient.Index(indexName);
const queryRequest = {
topK: 1,
vector: values,
includeMetadata: true,
namespace,
};
try {
const response = await index.query({ queryRequest });
const match = response.matches[0];
const metadata = match?.metadata;
const score = match?.score;
return {
label: metadata?.label || "Unknown",
confidence: score,
};
} catch (e) {
console.log("failed", e);
}
};Результат запроса будет включать массив совпадений, из которого будет выбрано первое. Для этого матча мы вернем метку и показатель достоверности в качестве окончательного результата.
Наконец, у нас есть простой сервер Express, который предоставляет конечную точку /api/image:
import * as dotenv from "dotenv";
import express from "express";
import http from "http";
import bodyParser from "body-parser";
import handler from "./handler.js";
dotenv.config();
const port = process.env.PORT;
const app = express();
app.use(bodyParser.json());
const server = http.createServer(app);
app.post("/api/image", handler);
// Start the HTTP server
server.listen(port, () => console.log(`Listening on port ${port}`));Запуск сервера локально
Если вы не создавали сервер самостоятельно, вы можете клонировать репозиторий сервера, выполнив:
git@github.com:pinecone-io/pinecone-vision-server.gitУстановите зависимости (если вы еще этого не сделали):
npm installСоздайте файл .env и укажите следующие значения:
INFERENCE_ENDPOINT_TOKEN=<YOUR_HUGGING_FACE_TOKEN>
INFERENCE_ENDPOINT=<YOUR_HUGGING_ENDPOINT_URL>
PINECONE_ENVIRONMENT=<YOUR_PINECONE_ENVIRONMENT>
PINECONE_API_KEY=<YOUR_PINECONE_API>Запустите сервер, выполнив:
npm run startРазвертывание сервера в Vercel
Чтобы развернуть сервер в Vercel, нам просто нужно добавить файл vercel.json со следующим:
{
"version": 2,
"name": "pinecone-vision",
"builds": [{ "src": "src/index.js", "use": "@vercel/node" }],
"routes": [{ "src": "src/(.*)", "dest": "src/index.js" }]
}Затем внесите изменения и установите новый проект Vercel для репозитория. Следуйте этим инструкциям, чтобы импортировать ваше существующее репозиторий в проект Vercel.
Вам нужно будет настроить те же переменные среды в Vercel, о которых мы упоминали ранее.
Мобильное приложение
Мобильное приложение выполняет две задачи:
- В режиме обучения: Передача изображений с камеры устройства на серверную часть вместе с меткой, установленной пользователем.
- В режиме обнаружения: Отобразите обнаруженную метку для того, на что указывает камера.
Вот что делает функция DetectImage:
- Получите изображение с камеры, вызвав метод takePictureAsync.
- Уменьшите размер изображения, чтобы повысить скорость вывода (и общую коммуникацию).
- Отправьте изображение на сервер вместе с меткой и этапом “обучения” или “запроса”. Это подскажет серверной части, как обрабатывать входящую полезную нагрузку.
async function detectImage() {
if (!cameraReady) {
return;
}
const pic = await cameraRef.current?.takePictureAsync({
base64: true,
});
const resizedPic = await manipulateAsync(
pic.uri,
[{ resize: { width: 244, height: 244 } }],
{ compress: 0.4, format: SaveFormat.JPEG, base64: true }
);
!detecting && setNumberOfImages((prev) => prev + 1);
const payload = {
uri: pic.uri,
data: resizedPic.base64,
height: resizedPic.height,
width: resizedPic.width,
label,
user,
stage: !detecting ? "training" : "detecting",
};
try {
const result = await fetch(`${ENDPOINT}/api/image`, {
method: "POST",
headers: {
Accept: "application/json",
"Content-Type": "application/json",
},
body: JSON.stringify(payload),
});
const json = await result.json();
const { label, confidence: score } = json;
...
} catch (e) {
console.log("Failed", e);
}
}
Полный код приложения доступен в этом репозитории. Вы можете клонировать его локально и запускать с помощью Expo.
Если вы запускаете сервер локально, сначала создайте файл .env со следующим значением:
ENDPOINT=<YOUR_LOCAL_IP_ADDRESS>Если вы хотите вместо этого использовать демо-конечную точку, используйте следующее:
ENDPOINT=pinecone-vision-latest.vercel.appЗатем выполните следующую команду:
npx expo startВы должны увидеть сканируемый QR-код, который откроет приложение на вашем телефоне. Это должно выглядеть примерно так:
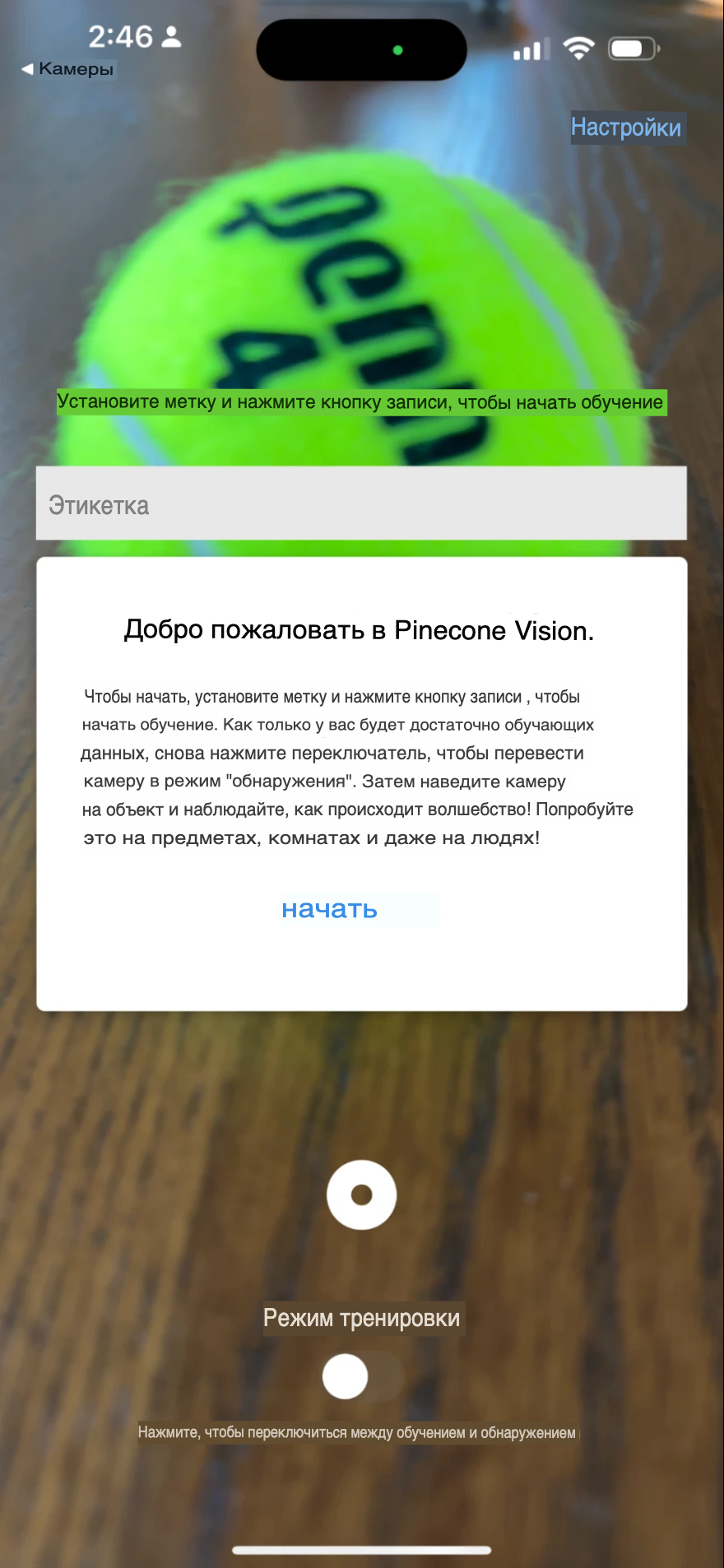


Итоги
Сочетание популярности Javascript и роста числа приложений ИИ создало большой потенциал для инноваций. Благодаря таким мощным инструментам, как Pinecone, Vercel и Hugging Face, разработчики теперь могут с легкостью создавать приложения ИИ. Это открывает перед разработчиками множество возможностей для создания приложений ИИ для более широкого круга пользователей. Если вы разработчик JS, мы надеемся, что это вдохновит вас на создание чего-то отличного!