TensorFlow-GNN: комплексное руководство по графовым нейронным сетям

Графические данные есть везде. Исследование графов находится в зачаточном состоянии, и инструменты для моделирования графических данных только начинают появляться. Это делает его идеальным временем для того, чтобы включиться в работу, если вы специалист по обработке данных, стремящийся выделиться. К сожалению, быть на переднем крае может быть трудно из-за отсутствия руководств и поддержки. Данное руководство надеется значительно уменьшить эту болевую точку.
TensorFlow-GNN
TF-GNN был недавно выпущен Google для графических нейронных сетей с использованием TensorFlow. Хотя существуют и другие библиотеки GNN, гибкость моделирования TF-GNN, производительность на крупномасштабных графиках благодаря распределенному обучению и поддержке Google означают, что она, скорее всего, станет отраслевым стандартом. В этом руководстве предполагается, что вы уже понимаете достоинства этой библиотеки, но, пожалуйста, ознакомьтесь с этой статьей для получения дополнительной информации и сравнения производительности. Кроме того, ознакомьтесь с документацией для TF-GNN. Если вы новичок в GNN в целом, ознакомьтесь с этим руководством для концептуального понимания.
Недостатки
Поскольку эта библиотека в настоящее время находится на стадии альфа-тестирования, код очень точен в отношении структур, входных форм и форматов, необходимых для успешного моделирования. Это очень затрудняет навигацию без гида. К сожалению, существует не так много информации об использовании TF-GNN. Руководства, которые мы смогли найти, сосредоточены на том же сценарии использования прогнозирования на уровне контекста с использованием предварительно созданного набора данных TensorFlow. На момент написания этой статьи не существует ни одного пошагового руководства для:
- Предсказание ребер или узлов
- Начиная с ваших собственных Pandas или сетевых наборов данных
- Создание резервных наборов данных
- Настройка модели
- Устранение ошибок, с которыми вы можете столкнуться
После целого месяца перечитывания документации, кодирования методом проб и ошибок и некоторой прямой помощи от разработчиков TensorFlow в Google/DeepMind мы решили собрать это руководство воедино.
“Многие [часы] погибли, чтобы донести до нас эту информацию”.
Охват этого руководства
Во-первых, мы начнем очень просто с того, что разберем строительные блоки. Затем мы перейдем к более продвинутому примеру — прогнозам студенческой футбольной конференции. Вот в общих чертах то, что будет рассмотрено:
- Элементы TF-GNN
- Построение блоков
- Тензор графа из Pandas
- Настройка данных
- Тензор графа от NetworkX
- Разработка функций
- Создание тестовых сплитов
- Создание набора данных графа TensorFlow
- Построение модели
- Модель узла
- Модель ребра
- Контекстная модель
- Устранение ошибок
- Настройка параметров
Элементы TF-GNN
Граф состоит из узлов и ребер. Вот пример простого графика, показывающего людей (узлы), которые недавно контактировали друг с другом (ребра):
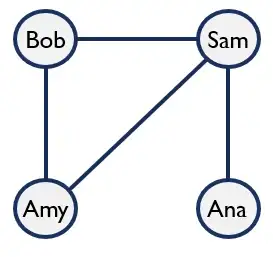
Этот же граф также может быть представлен в виде таблиц узлов и ребер. Мы также можем добавлять объекты к этим узлам и ребрам. Например, мы можем добавить "age" в качестве функции узла и индикатор "is-friend" в качестве функции ребра.

Когда мы добавляем ребра в TF-GNN, нам нужно индексировать по номеру, а не по имени. Мы можем сделать это так:
node_df = node_df.reset_index()
merge_df = node_df.reset_index().set_index('Name').rename(
columns={'index':'Name1_idx'})
edge_df = pd.merge(edge_df,merge_df['Name1_idx'],
how='left',left_on='Name1',right_index=True)
merge_df = merge_df.rename(columns={'Name1_idx':'Name2_idx'})
edge_df = pd.merge(edge_df,merge_df['Name2_idx'],
how='left',left_on='Name2',right_index=True)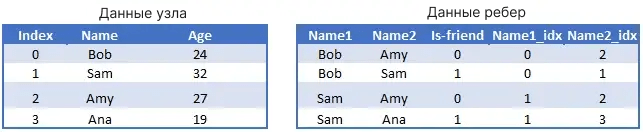
Наконец, у нас может быть значение контекста для графа. Например, возможно, эта группа друзей набрала в среднем 84% в определенном тесте. Это не будет иметь большого значения для этого примера с одним графом. Если бы у нас были другие графы друзей, мы, возможно, могли бы предсказать баллы для новых групп друзей на основе изученной групповой динамики.
Тензор графа из pandas
С помощью этих элементов мы теперь можем построить основу для нашего GNN: тензор графа.
import tensorflow_gnn as tfgnn
graph_tensor = tfgnn.GraphTensor.from_pieces(
node_sets = {
"People": tfgnn.NodeSet.from_fields(
sizes = [len(node_df)],
features ={
'Age': np.array(node_df['Age'],
dtype='int32').reshape(len(node_df),1)})},
edge_sets ={
"Contact": tfgnn.EdgeSet.from_fields(
sizes = [len(edge_df)],
features = {
'Is-friend': np.array(edge_df['Is-friend'],
dtype='int32').reshape(len(edge_df),1)},
adjacency = tfgnn.Adjacency.from_indices(
source = ("People", np.array(edge_df['Name1_idx'], dtype='int32')),
target = ("People", np.array(edge_df['Name2_idx'], dtype='int32'))))
})Обратите внимание, как созданные нами объекты вписываются в узлы и ребра. Структура с отступами упрощает добавление дополнительных узлов, ребер и объектов. Например, мы могли бы легко добавить узлы и ребра для фильмов, которые смотрел каждый друг, и на этот раз включить значение контекста графа.
graph_tensor = tfgnn.GraphTensor.from_pieces(
context_spec = tfgnn.ContextSpec.from_field_specs(
features_spec ={
"score": [[0.84]]
}),
node_sets = {
"People": tfgnn.NodeSet.from_fields(
sizes = [len(node_df)],
features ={
'Age': np.array(node_df['Age'],
dtype='int32').reshape(len(node_df),1)}),
"Movies": tfgnn.NodeSet.from_fields(
sizes = [len(movie_df)],
features ={
'Name': np.array(movie_df['Name'],
dtype='string').reshape(len(movie_df),1),
'Length': np.array(movie_df['Length'],
dtype='float32').reshape(len(movie_df),1)})},
edge_sets ={
"Contact": tfgnn.EdgeSet.from_fields(
sizes = [len(edge_df)],
features = {
'Is-friend': np.array(edge_df['Is-friend'],
dtype='int32').reshape(len(edge_df),1)},
adjacency = tfgnn.Adjacency.from_indices(
source = ("People", np.array(edge_df['Name1_idx'], dtype='int32')),
target = ("People", np.array(edge_df['Name2_idx'], dtype='int32')))),
'Watched': tfgnn.EdgeSet.from_fields(
sizes = [len(watched_df)],
features = {},
adjacency = tfgnn.Adjacency.from_indices(
source = ("People", np.array(watched_df['Name_idx'], dtype='int32')),
target = ("Movies", np.array(watched_df['Movie_idx'], dtype='int32'))))
})Будьте очень осторожны с вашими типами и формами. Любые отклонения приведут к ошибкам или проблемам с обучением. Единственными поддерживаемыми типами d являются «int32», «float32» и «string». Если у вас возникли проблемы, см. раздел об устранении неполадок в конце этой статьи.
Возможно, вы заметили, что тензор графика направлен с источником и целью. Это может быть хорошо для Sam, смотрящего фильм, но общение является двунаправленным. Когда Sam разговаривает с Amy, Amy тоже разговаривает с Sam. Для двунаправленных данных вы захотите дублировать эти ребра (с обратным расположением источника и цели), чтобы указать оба направления потока данных.
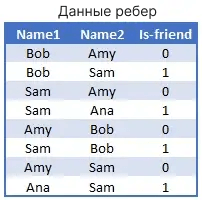
Имея этот фундамент, мы теперь готовы перейти к составлению прогнозов на основе реального набора данных.
Настройка данных
Данные о тренировках представляют собой сеть игр по американскому футболу между колледжами дивизиона IA в течение регулярного сезона осенью 2000 года, составленную М. Гирваном и М. Ньюманом. Данные узла включают названия колледжей и индекс конференции, к которой они принадлежат (например, конференция 8 = Pac 10). Края включают названия двух колледжей, указывающие на то, что между ними была сыграна игра. Данные могут быть извлечены следующим образом (смотрите Google Colab, чтобы следовать дальше):
import urllib.request
import io
import zipfile
import networkx as nx
url = "http://www-personal.umich.edu/~mejn/netdata/football.zip"
sock = urllib.request.urlopen(url) # open URL
s = io.BytesIO(sock.read()) # read into BytesIO "file"
sock.close()
zf = zipfile.ZipFile(s) # zipfile object
txt = zf.read("football.txt").decode() # read info file
gml = zf.read("football.gml").decode() # read gml data
# throw away bogus first line with # from mejn files
gml = gml.split("\n")[1:]
G = nx.parse_gml(gml) # parse gml data
print(txt)Тензор графа от NetworkX
Наши данные теперь представлены на графе NetworkX. Давайте посмотрим, как это выглядит с узлами, окрашенными в зависимости от того, к какой конференции они принадлежат.
cmap = {0:'#bd2309', 1:'#bbb12d',2:'#1480fa',3:'#14fa2f',4:'#faf214',
5:'#2edfea',6:'#ea2ec4',7:'#ea2e40',8:'#577a4d',9:'#2e46c0',
10:'#f59422',11:'#8086d9'}
colors = [cmap[G.nodes[n]['value']] for n in G.nodes()]
pos = nx.spring_layout(G, seed=1987)
nx.draw_networkx_edges(G, pos, alpha=0.2)
nx.draw_networkx_nodes(G, pos, nodelist=G.nodes(),
node_color=colors, node_size=100)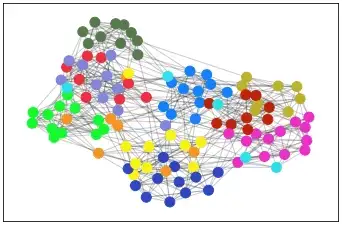
Для нашей узловой модели мы попытаемся предсказать конференцию, к которой принадлежит школа. Для нашей модели edge мы попытаемся предсказать, была ли игра игрой в конференции. Оба прогноза будут оценены на основе несогласованного набора данных. Как мы можем сделать это из сети? Можно построить тензор графа непосредственно из графика, используя эти функции для извлечения данных:
node_data = G.nodes(data=True)
edge_data = G.edges(data=True)Проблема в том, что мы все еще хотим провести некоторую разработку функций, и у нас еще нет нашего набора данных для несогласия. По этим причинам я настоятельно рекомендую использовать подход преобразования ваших графических данных в Pandas. Позже мы сможем подключить наши данные к тензору графов, используя метод, показанный в нашем первом примере.
node_df = pd.DataFrame.from_dict(dict(G.nodes(data=True)), orient='index')
node_df.index.name = 'school'
node_df.columns = ['conference']
edge_df = nx.to_pandas_edgelist(G)
Разработка функций
Используя базовый график, модель может определить, участвуют ли два колледжа в одной конференции на основе сети. Но как он узнает, какая конкретно конференция? Как он мог бы узнать различия между конференциями без каких-либо данных об узле или границе? Для выполнения этой задачи нам нужно будет добавить дополнительные функции.
Какие функции мы должны собрать? Мы не эксперты в студенческом футболе, но можги бы предположить, что конференции составляются на основе близости и ранга. Это руководство ориентировано на TF-GNN, поэтому я добавлю эти новые функции с помощью magic, но вы можете найти конкретный код в связанной Google Colab.
Для узлов мы добавим latitude/longitude и rank предыдущего года (1999), wins и conference wins. Мы также преобразуем столбец conference в 12 столбцов фиктивных переменных для прогнозирования softmax.
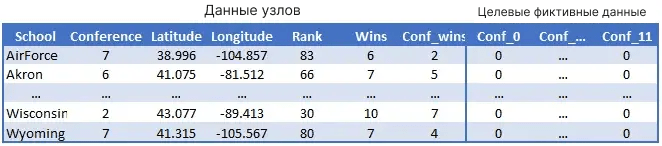
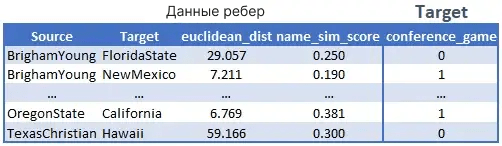
Для edges мы рассчитаем расстояние между школами, добавим оценку сходства названий (возможно, школы с одинаковым штатом в названии с большей вероятностью будут участвовать в одной конференции) и целевое значение для игр, являющихся игрой внутри конференции.
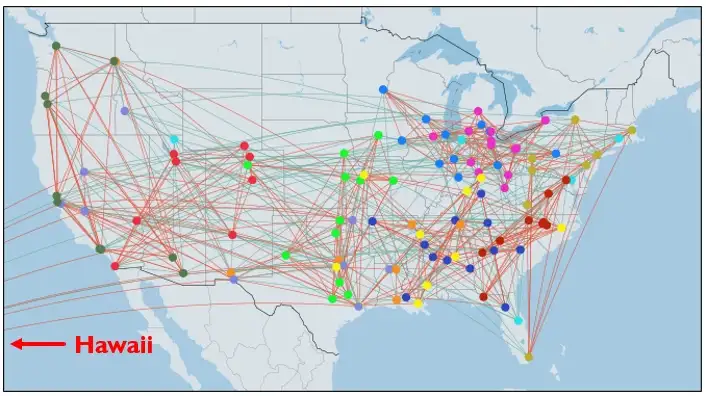
Давайте визуализируем наши данные с нашей новой информацией (оранжевые края указывают на конференц-игру). Определенно кажется, что география, по крайней мере, играет определенную роль в выборе конференции.
Создание тестовых сплитов
Создание тренировочного разделения несложно; исключите несогласованные узлы и ребра так же, как вы обычно это делаете. Однако несогласованные данные немного отличаются от вашего обычного приложения для машинного обучения. Поскольку общие связи важны для точного прогнозирования, окончательный прогноз должен быть на всем графе. Как только прогноз сделан, результаты могут быть отфильтрованы до несогласованных данных для окончательной оценки. Мы покажем этот процесс более подробно на этапе прогнозирования; вот как мы создадим расколы на данный момент:
from sklearn.model_selection import train_test_split
node_train, node_test = train_test_split(node_df,test_size=0.15,random_state=42)
edge_train = edge_df.loc[~((edge_df['source'].isin(node_test.index)) | (edge_df['target'].isin(node_test.index)))]
edge_test = edge_df.loc[(edge_df['source'].isin(node_test.index)) | (edge_df['target'].isin(node_test.index))]С нашими новыми разделениями мы теперь можем вносить двунаправленные корректировки и добавлять столбцы индекса ребер.
def bidirectional(edge_df):
reverse_df = edge_df.rename(columns={'source':'target','target':'source'})
reverse_df = reverse_df[edge_df.columns]
reverse_df = pd.concat([edge_df, reverse_df], ignore_index=True, axis=0)
return reverse_df
def create_adj_id(node_df,edge_df):
node_df = node_df.reset_index().reset_index()
edge_df = pd.merge(edge_df,node_df[['school','index']].rename(columns={"index":"source_id"}),
how='left',left_on='source',right_on='school').drop(columns=['school'])
edge_df = pd.merge(edge_df,node_df[['school','index']].rename(columns={"index":"target_id"}),
how='left',left_on='target',right_on='school').drop(columns=['school'])
edge_df.dropna(inplace=True)
return node_df, edge_df
edge_full_adj = bidirectional(edge_df)
edge_train_adj = bidirectional(edge_train)
node_full_adj,edge_full_adj = create_adj_id(node_df,edge_full_adj)
node_train_adj,edge_train_adj = create_adj_id(node_train,edge_train_adj)Создание набора данных TensorFlow
Теперь мы готовы создать наши тензоры графов, которые мы преобразуем в наборы данных TensorFlow.
def create_graph_tensor(node_df,edge_df):
graph_tensor = tfgnn.GraphTensor.from_pieces(
node_sets = {
"schools": tfgnn.NodeSet.from_fields(
sizes = [len(node_df)],
features ={
'Latitude': np.array(node_df['Latitude'], dtype='float32').reshape(len(node_df),1),
'Longitude': np.array(node_df['Longitude'], dtype='float32').reshape(len(node_df),1),
'Rank': np.array(node_df['Rank'], dtype='int32').reshape(len(node_df),1),
'Wins': np.array(node_df['Wins'], dtype='int32').reshape(len(node_df),1),
'Conf_wins': np.array(node_df['Conf_wins'], dtype='int32').reshape(len(node_df),1),
'conference': np.array(node_df.iloc[:,-12:], dtype='int32'),
}),
},
edge_sets ={
"games": tfgnn.EdgeSet.from_fields(
sizes = [len(edge_df)],
features = {
'name_sim_score': np.array(edge_df['name_sim_score'], dtype='float32').reshape(len(edge_df),1),
'euclidean_dist': np.array(edge_df['euclidean_dist'], dtype='float32').reshape(len(edge_df),1),
'conference_game': np.array(edge_df['conference_game'], dtype='int32').reshape(len(edge_df),1)
},
adjacency = tfgnn.Adjacency.from_indices(
source = ("schools", np.array(edge_df['source_id'], dtype='int32')),
target = ("schools", np.array(edge_df['target_id'], dtype='int32')),
)),
})
return graph_tensor
full_tensor = create_graph_tensor(node_full_adj,edge_full_adj)
train_tensor = create_graph_tensor(node_train_adj,edge_train_adj)Перед созданием набора данных нам нужна функция, которая разделит наш график на наши обучающие данные и цель, которую мы будем прогнозировать (показано в виде метки ниже). Для нашей задачи прогнозирования узлов мы сделаем "conference" нашей меткой. Нам также необходимо удалить функцию ‘conference_game’ из набора данных, поскольку это создало бы проблему утечки данных (т.е. обмана).
def node_batch_merge(graph):
graph = graph.merge_batch_to_components()
node_features = graph.node_sets['schools'].get_features_dict()
edge_features = graph.edge_sets['games'].get_features_dict()
label = node_features.pop('conference')
_ = edge_features.pop('conference_game')
new_graph = graph.replace_features(
node_sets={'schools':node_features},
edge_sets={'games':edge_features})
return new_graph, label
Мы сделаем обратное для нашей модели edge: отбросим функцию "conference" и выделим "conference_game" в качестве нашей цели (метки).
def edge_batch_merge(graph):
graph = graph.merge_batch_to_components()
node_features = graph.node_sets['schools'].get_features_dict()
edge_features = graph.edge_sets['games'].get_features_dict()
_ = node_features.pop('conference')
label = edge_features.pop('conference_game')
new_graph = graph.replace_features(
node_sets={'schools':node_features},
edge_sets={'games':edge_features})
return new_graph, labelТеперь мы можем создать наш набор данных и сопоставить его с помощью приведенной выше функции.
def create_dataset(graph,function):
dataset = tf.data.Dataset.from_tensors(graph)
dataset = dataset.batch(32)
return dataset.map(function)
#Node Datasets
full_node_dataset = create_dataset(full_tensor,node_batch_merge)
train_node_dataset = create_dataset(train_tensor,node_batch_merge)
#Edge Datasets
full_edge_dataset = create_dataset(full_tensor,edge_batch_merge)
train_edge_dataset = create_dataset(train_tensor,edge_batch_merge)Порядок выполнения этих процедур чрезвычайно важен:
- Мы создаем наш набор данных из тензора графа.
- Мы разделяем наш набор данных на пакеты (ознакомьтесь с размерами пакетов).
- В функции map мы объединяем эти пакеты обратно в один график.
- Мы разделяем/удаляем функции по мере необходимости.
Модель не будет тренироваться (или неправильно), если вы не будете точно следовать этому порядку.
Построение модели
У нас есть наши наборы данных, теперь самое интересное! Сначала мы определяем входные данные, используя нашу спецификацию набора данных.
graph_spec = train_node_dataset.element_spec[0]
input_graph = tf.keras.layers.Input(type_spec=graph_spec)Теперь нам нужно инициализировать наши функции. Мы создадим функции для инициализации узлов и ребер. Затем мы сопоставляем наши возможности с помощью этих функций. Чтобы упростить задачу, мы создадим плотный слой для каждого объекта.
def set_initial_node_state(node_set, node_set_name):
features = [
tf.keras.layers.Dense(32,activation="relu")(node_set['Latitude']),
tf.keras.layers.Dense(32,activation="relu")(node_set['Longitude']),
tf.keras.layers.Dense(32,activation="relu")(node_set['Rank']),
tf.keras.layers.Dense(32,activation="relu")(node_set['Wins']),
tf.keras.layers.Dense(32,activation="relu")(node_set['Conf_wins'])
]
return tf.keras.layers.Concatenate()(features)
def set_initial_edge_state(edge_set, edge_set_name):
features = [
tf.keras.layers.Dense(32,activation="relu")(edge_set['name_sim_score']),
tf.keras.layers.Dense(32,activation="relu")(edge_set['euclidean_dist'])
]
return tf.keras.layers.Concatenate()(features)
graph = tfgnn.keras.layers.MapFeatures(
node_sets_fn=set_initial_node_state,
edge_sets_fn=set_initial_edge_state
)(input_graph)На этом предыдущем шаге может произойти множество настроек. Например, мы могли бы создать вложения word для строковых объектов. Вероятно, мы могли бы добиться некоторой точности, хэшируя сетку latitude/longitude, а не просто используя плотный слой. У TensorFlow есть много доступных нам опций.
Несколько вещей, на которые следует обратить внимание:
- Если у вас есть несколько узлов или ребер, вам нужно будет добавить "if statements", чтобы применить объекты к правильному узлу/ребру.
- Узлы или ребра без объектов также могут быть инициализированы с помощью функции ‘MakeEmptyFeature’.
- Для задачи, ориентированной на узел, инициализация ребер необязательна (подробнее читайте о node vs edge centric).
- Первый узел должен иметь по крайней мере одну функцию. Возможно, вам придется создать вложение в индекс, если у вас нет функций (результаты, скорее всего, будут не очень хорошими).
# Examples, do not use for this problem
def set_initial_node_state(node_set, node_set_name):
if node_set_name == "node_1":
return tf.keras.layers.Embedding(115,3)(node_set['id'])
elif node_set_name == "node_2":
return tfgnn.keras.layers.MakeEmptyFeature()(node_set)
graph = tfgnn.keras.layers.MapFeatures(
node_sets_fn=set_initial_node_state)(input_graph)Прежде чем мы разработаем наш цикл обновления, нам понадобится еще одна вспомогательная функция. Поскольку мы добавляем плотные слои, нам нужно убедиться, что мы используем регулирование L2 и/или отсев (L1 также подойдет).
def dense_layer(self,units=64,l2_reg=0.1,dropout=0.25,activation='relu'):
regularizer = tf.keras.regularizers.l2(l2_reg)
return tf.keras.Sequential([
tf.keras.layers.Dense(units,
kernel_regularizer=regularizer,
bias_regularizer=regularizer),
tf.keras.layers.Dropout(dropout)])Модель узла
Существует несколько архитектур моделей, но сверточные сети графов, безусловно, являются наиболее распространенными (см. Другие подходы, описанные здесь). Свертки графов похожи на свертки, обычно используемые в задачах компьютерного зрения. Основное отличие заключается в том, что свертки графа работают с нерегулярными данными, которые вы находите с помощью структур графа. Давайте перейдем к фактическому коду.
graph_updates = 3 # tunable parameter
for i in range(graph_updates):
graph = tfgnn.keras.layers.GraphUpdate(
node_sets = {
'schools': tfgnn.keras.layers.NodeSetUpdate({
'games': tfgnn.keras.layers.SimpleConv(
message_fn = dense_layer(32),
reduce_type="sum",
receiver_tag=tfgnn.TARGET)},
tfgnn.keras.layers.NextStateFromConcat(
dense_layer(64)))})(graph) #start here
logits = tf.keras.layers.Dense(12,activation='softmax')(graph.node_sets["schools"][tfgnn.HIDDEN_STATE])
node_model = tf.keras.Model(input_graph, logits)Приведенный выше код может показаться немного запутанным из-за того, как работает укладка TensorFlow. Помните, что (граф) с надписью "#start here" в конце функции "GraphUpdate" на самом деле является вводом для кода, который находится перед ней. Сначала этот (граф) равен инициализированным объектам, которые мы сопоставили ранее. Входные данные поступают в функцию ‘GraphUpdate’, становясь новыми (graph). С каждым циклом ‘graph_updates’ предыдущее ‘GraphUpdate’ становится входом для нового ‘GraphUpdate’ вместе с плотным слоем, указанным с помощью функции ‘NextStateFromConcat’. Эта диаграмма должна помочь объяснить:
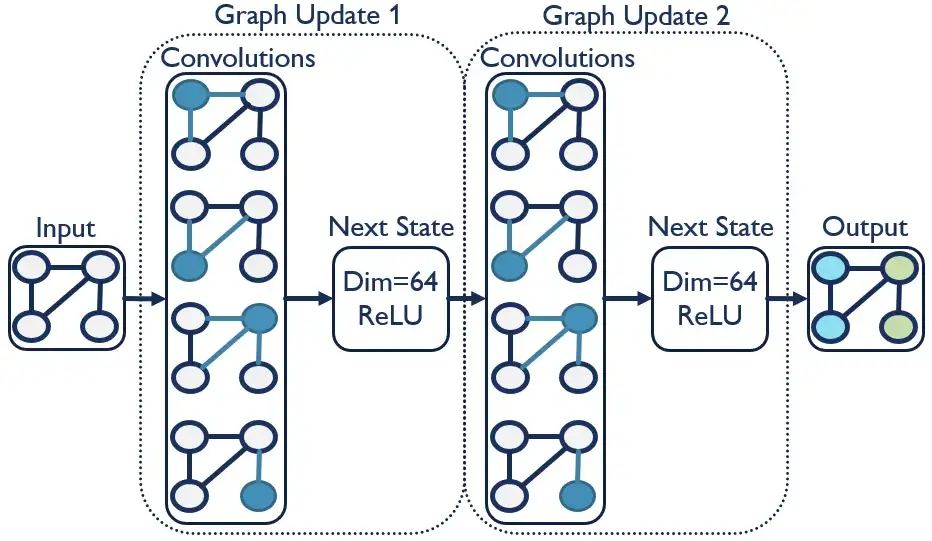
Функция ‘GraphUpdate’ просто обновляет указанные состояния (узел, ребро или контекст) и добавляет следующий уровень состояния. В этом случае мы только обновляем состояния узлов с помощью ‘NodeSetUpdate’, но мы рассмотрим подход, ориентированный на границы, когда будем работать над нашей моделью границ. С этим обновлением узла мы применяем сверточный слой вдоль ребер, позволяя передавать информацию в узел из соседних узлов и ребер. Количество обновлений графика является настраиваемым параметром, при этом каждое обновление позволяет передавать информацию с других узлов. Например, три обновления, указанные в нашем случае, позволяют передавать информацию с расстояния до трех узлов. После обновления нашего графика конечное состояние узла становится входными данными для нашей главы прогнозирования с пометкой "logits". Поскольку мы прогнозируем 12 различных конференций, у нас есть плотный слой из 12 блоков с активацией softmax. Теперь мы можем скомпилировать модель.
node_model.compile(
tf.keras.optimizers.Adam(learning_rate=0.01),
loss = 'categorical_crossentropy',
metrics = ['categorical_accuracy']
)
node_model.summary()И, наконец, мы обучаем модель. Мы используем обратный вызов, чтобы остановить обучение, когда набор данных проверки перестает повышать точность. Это не идеально, так как мы должны использовать полный набор данных (объяснено выше). Это приведет к тому, что наш номер точности будет включать утечку данных. Идеальным решением было бы написать пользовательскую функцию оценки, которая возвращает точность только для узлов проверки данных проверки и обучающих узлов для обучающих данных. Это большая работа (само по себе заняло бы целый учебник), чтобы приблизиться на пару эпох к наиболее точной точке остановки. Мы же предпочитаем, чтобы все было просто, и живем с немного менее точной моделью.
es = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',mode='min',verbose=1,
patience=10,restore_best_weights=True)
node_model.fit(train_node_dataset.repeat(),
validation_data=full_node_dataset,
steps_per_epoch=10,
epochs=1000,
callbacks=[es])Пришло время посмотреть, как мы это сделали, используя node_model.predict(full_node_dataset) и распечатав результаты на карте с помощью magic (см. Google Colab).
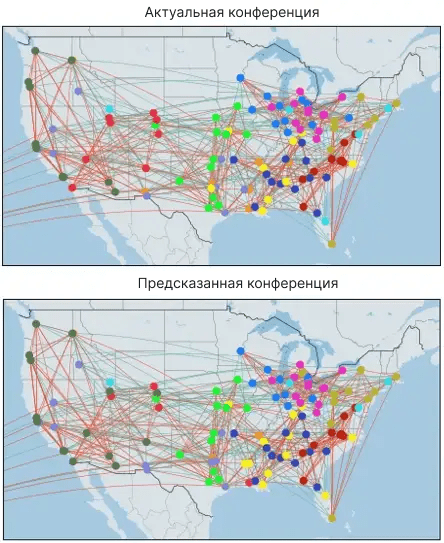
В целом, у нас была приличная точность в 88% (параметры модели см. в Google Colab). Модель, похоже, переживает более трудные времена для горных штатов. Погружение поглубже дает некоторые интересные идеи. Например, модель ложно предсказала, что Юта будет участвовать в конференции Pac 10. Однако в следующем году Юта действительно присоединилась к Pac 10. Вполне возможно, что модель правильно определяет, как все должно быть, и ошибка ~ 12% на самом деле является показателем человеческой непоследовательности при создании конференций. Другой способ подумать об этом - с помощью социальной сети друзей. Если сеть предсказывает, что два человека являются друзьями, хотя они никогда не встречались, является ли модель неверной или они подходят друг другу? Для многих (или большинства) графических задач эти “errors” - это то, что вы действительно пытаетесь найти. Затем их можно использовать, чтобы рекомендовать товары для покупки, фильмы для просмотра, людей, с которыми вам следует связаться, и т.д.
В этом случае давайте предположим, что данные идеальны, и мы заинтересованы в точности классификации. Чтобы действительно знать, насколько хорошо мы справились, нам нужно будет проверить точность наших данных о несогласии. Чтобы сделать это, мы сделаем прогноз по полному набору данных и отфильтруем его до несогласованных узлов.
def evaluate_node():
### Add raw prediction ####
yhat = node_model.predict(full_node_dataset)
yhat_df = node_full_adj.set_index('school').iloc[:,-12:].copy()
yhat_df.iloc[:,:] = yhat
### Classify max of softmax output ###
yhat_df = yhat_df.apply(lambda x: x == x.max(), axis=1).astype(int)
### Merge output back to single column ###
yhat_df = yhat_df.dot(yhat_df.columns).to_frame().rename(columns={0:'conf_yhat'})
yhat_df = yhat_df['conf_yhat'].str.replace('conf_', '').astype(int).to_frame()
yhat_df['conf_actual'] = node_full_adj['conference']
### Filter down to test nodes ###
yhat_df = yhat_df.loc[yhat_df.index.isin(params['testset'].index)]
### Calculate accuracy ###
yhat_df['Accuracy'] = yhat_df['conf_yhat']==yhat_df['conf_actual']
return yhat_df['Accuracy'].mean()Для этой модели точность падает до ~ 72% (не паникуйте, ожидается снижение для несогласованного набора данных). Учитывая ограниченную разработку функций, данные только за один год и 12 прогнозов выходных данных — эти результаты являются разумными. При визуальном осмотре приведенных ниже карт (и сравнении с полной картой выше) большинство ошибок кажутся приличными догадками.
Модель ребра
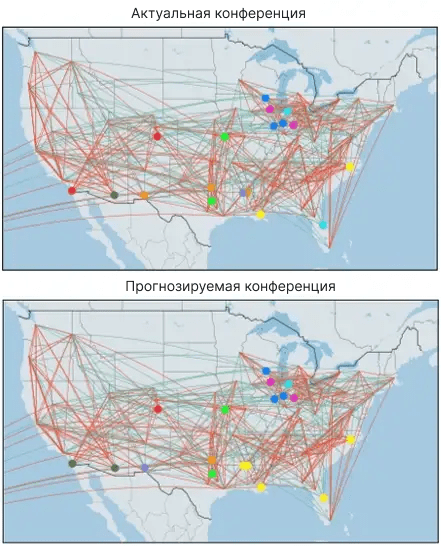
Теперь мы попытаемся предсказать, является ли конкретная игра игрой в конференции. Мы уже определили наши граничные наборы данных выше, и большинство шагов можно использовать повторно только с одним изменением:
### Change to train_edge_dataset ###
graph_spec = train_edge_dataset.element_spec[0]
input_graph = tf.keras.layers.Input(type_spec=graph_spec)
graph = tfgnn.keras.layers.MapFeatures(
node_sets_fn=set_initial_node_state,
edge_sets_fn=set_initial_edge_state
)(input_graph)Однако нам нужно внести несколько изменений в обновления графика. Во-первых, нам нужно добавить обновление ‘edge_sets’ к нашей функции ‘GraphUpdate’. Оставлять в обновлении ‘node_sets’ необязательно, но модель, похоже, работает для нас лучше, когда мы сохраняем ее. Затем нам нужно обновить "logits", чтобы он был плотным слоем активации сигмовидной мышцы на одну единицу, поскольку мы прогнозируем фиктивную переменную.
graph_updates = 3
for i in range(graph_updates):
graph = tfgnn.keras.layers.GraphUpdate(
edge_sets = {'games': tfgnn.keras.layers.EdgeSetUpdate(
next_state = tfgnn.keras.layers.NextStateFromConcat(
dense_layer(64,activation='relu')))},
node_sets = {
'schools': tfgnn.keras.layers.NodeSetUpdate({
'games': tfgnn.keras.layers.SimpleConv(
message_fn = dense_layer(32),
reduce_type="sum",
receiver_tag=tfgnn.TARGET)},
tfgnn.keras.layers.NextStateFromConcat(
dense_layer(64)))})(graph)
logits = tf.keras.layers.Dense(1,activation='sigmoid')(graph.edge_sets['games'][tfgnn.HIDDEN_STATE])
edge_model = tf.keras.Model(input_graph, logits)На этот раз мы компилируем модель, используя ‘binary_crossentropy’.
edge_model.compile(
tf.keras.optimizers.Adam(learning_rate=0.01),
loss = 'binary_crossentropy',
metrics = ['Accuracy']
)
edge_model.summary()И мы подгоняем модель, используя тот же обратный вызов, определенный в нашей задаче с узлом.
edge_model.fit(train_edge_dataset.repeat(),
validation_data=full_edge_dataset,
steps_per_epoch=10,
epochs=1000,
callbacks=[es])
yhat = edge_model.predict(full_edge_dataset)
yhat_df = edge_full_adj.copy().set_index(['source','target'])
yhat_df['conf_game_yhat'] = yhat.round(0)
yhat_df = yhat_df.loc[yhat_df.index.isin(
edge_test.set_index(['source','target']).index)]
yhat_df['loss'] = abs(yhat_df['conference_game'] - yhat_df['conf_game_yhat'])
loss = yhat_df['loss'].mean()
print("edge accuracy:",1 - loss)При оценке по набору данных holdout мы получаем точность 85% по сравнению со средним значением 56%. Модель выполнила свою работу, и мы довольны этими результатами.
Модель контекста
Эта конкретная проблема не имеет контекстного значения. Давайте представим, что мы разрезали приведенный выше график так, чтобы у нас был отдельный график для каждой конференции. Эти новые графики будут показывать каждую игру, сыгранную командами в конференции, и игнорировать все остальные игры. Затем мы могли бы иметь значения для каждого графика для того, как была ранжирована конференция. Теперь мы можем обучить модель делать прогнозы на уровне контекста.
Во-первых, нам нужно добавить наши контекстные значения к графу.
graph_tensor = tfgnn.GraphTensor.from_pieces(
context = tfgnn.Context.from_fields(
features ={
<context_feature>
}),
node_sets = {
...Далее нам нужно создать новый набор данных с контекстом, сопоставленным с меткой.
def node_batch_merge(graph):
graph = graph.merge_batch_to_components()
context_features = graph.context.get_features_dict()
label = context_features.pop('<context_feature>')
new_graph = graph.replace_features(
context=context_features)
return new_graph, labelУ нас есть возможность установить наше начальное состояние контекста. В данном случае мы прогнозируем эту функцию, поэтому она будет отсутствовать в наших обучающих данных. Для других моделей контекст может быть обучаемой функцией и может быть установлен следующим образом:
def set_initial_context_state(context):
return tf.keras.layers.Dense(32,activation="relu")(context['<context_feature>'])
graph = tfgnn.keras.layers.MapFeatures(
context_fn=set_initial_context_state,
node_sets_fn=set_initial_node_state,
edge_sets_fn=set_initial_edge_state
)(input_graph)Опять же, мы можем дополнительно добавить обновление контекста к ‘GraphUpdate’ (см. ниже). Мы не тестировали этот метод, так что смело экспериментируйте.
graph = tfgnn.keras.layers.GraphUpdate(
node_sets ={...},
context = tfgnn.keras.layers.ContextUpdate({
'schools': tfgnn.keras.layers.Pool(tfgnn.CONTEXT, "mean")},
tfgnn.keras.layers.NextStateFromConcat(tf.keras.layers.Dense(128))))Наконец, мы обновляем наши "logits" для контекстного прогнозирования
logits = tfgnn.keras.layers.Pool(tfgnn.CONTEXT, "mean",
node_set_name="schools")(graph)Устранение ошибок
Мы столкнулись со многими ошибками и плохо обученными моделями, пытаясь разобраться в приведенном выше коде. Хотя мы старались придерживаться достаточно общих принципов, чтобы их можно было применять ко многим различным проблемам, вы, несомненно, столкнетесь с ошибками при внесении изменений в свои данные. Хитрость заключается в том, чтобы определить источник вашей ошибки. Лучший способ, который мы нашли для диагностики ошибок, заключался в создании графовой схемы.
В нашем коде выше мы извлекли схему графа из нашего набора данных. Однако вы можете построить схему графа напрямую. Для нашего футбольного примера схема графа будет выглядеть следующим образом:
graph_spec = tfgnn.GraphTensorSpec.from_piece_specs(
context_spec = tfgnn.ContextSpec.from_field_specs(
features_spec ={
#Added as an example for context problems
#"conf_rank": tf.TensorSpec(shape=(None,1), dtype=tf.float32),
}),
node_sets_spec={
'schools':
tfgnn.NodeSetSpec.from_field_specs(
features_spec={
'Latitude': tf.TensorSpec((None, 1), tf.float32),
'Longitude': tf.TensorSpec((None, 1), tf.float32),
'Rank': tf.TensorSpec((None, 1), tf.int32),
'Wins': tf.TensorSpec((None, 1), tf.int32),
'Conf_wins': tf.TensorSpec((None, 1), tf.int32),
'conference': tf.TensorSpec((None, 12), tf.int32)
},
sizes_spec=tf.TensorSpec((1,), tf.int32))
},
edge_sets_spec={
'games':
tfgnn.EdgeSetSpec.from_field_specs(
features_spec={
'name_sim_score': tf.TensorSpec((None, 1), tf.float32),
'euclidean_dist': tf.TensorSpec((None, 1), tf.float32),
'conference_game': tf.TensorSpec((None, 1), tf.int32)
},
sizes_spec=tf.TensorSpec((1,), tf.int32),
adjacency_spec=tfgnn.AdjacencySpec.from_incident_node_sets(
'schools', 'schools'))
})Мы можем проверить, является ли наш ‘graph_spec’, по крайней мере, действительным, попытавшись построить и скомпилировать модель. Если вы получаете сообщение об ошибке, скорее всего, проблема с вашими формами объектов или вашими функциями ‘set_initial_...’. Если это сработает, вы можете убедиться, что созданная вами схема совместима с вашим ‘graph_tensor’.
graph_spec.is_compatible_with(full_tensor)Если значение false, вы можете распечатать ‘full_tensor.spec’ и ‘graph_spec’, чтобы сравнить каждую деталь, чтобы убедиться, что формы и dtypes точно совпадают. Вы также можете создать случайно сгенерированный тензор графика непосредственно из ‘graph_spec’.
random_graph = tfgnn.random_graph_tensor(graph_spec)С помощью этого ‘random_graph’ вы можете попытаться обучить модель. Это должно помочь вам определить, связана ли ваша ошибка со спецификацией или кодом модели. Если вы не получаете никаких ошибок, вы можете распечатать значения ‘random_graph’, чтобы увидеть, как выходные данные сравниваются с вашим ‘graph_tensor’.
print("Nodes:",random_graph.node_sets['schools'].features)
print("Edges:",random_graph.edge_sets['games'].features)
print("Context:",random_graph.context.features)Эти шаги должны позволить вам отследить большинство проблем, с которыми вы сталкиваетесь.
Настройка параметров
Мы успешно исправили все ошибки, которые у нас были, и обучили модель. Теперь мы хотим настроить наши гиперпараметры для точной модели. Мой любимый тюнер - библиотека Hyperopt из-за ее простоты использования и встроенной байесовской оптимизации. Но сначала мы хотим преобразовать наш код моделирования, приведенный выше, в класс с переменными.
class GCNN:
def __init__(self,params):
self.params = params
def set_initial_node_state(self, node_set, node_set_name):
features = [
tf.keras.layers.Dense(self.params['feature_dim'],activation="relu")(node_set['Latitude']),
tf.keras.layers.Dense(self.params['feature_dim'],activation="relu")(node_set['Longitude']),
tf.keras.layers.Dense(self.params['feature_dim'],activation="relu")(node_set['Rank']),
tf.keras.layers.Dense(self.params['feature_dim'],activation="relu")(node_set['Wins']),
tf.keras.layers.Dense(self.params['feature_dim'],activation="relu")(node_set['Conf_wins'])
]
return tf.keras.layers.Concatenate()(features)
def set_initial_edge_state(self, edge_set, edge_set_name):
features = [
tf.keras.layers.Dense(self.params['feature_dim'],activation="relu")(edge_set['name_sim_score']),
tf.keras.layers.Dense(self.params['feature_dim'],activation="relu")(edge_set['euclidean_dist'])
]
return tf.keras.layers.Concatenate()(features)
def dense_layer(self,units=64):
regularizer = tf.keras.regularizers.l2(self.params['l2_reg'])
return tf.keras.Sequential([
tf.keras.layers.Dense(units,
kernel_regularizer=regularizer,
bias_regularizer=regularizer,
activation='relu'),
tf.keras.layers.Dropout(self.params['dropout'])])
def build_model(self):
input_graph = tf.keras.layers.Input(type_spec=self.params['trainset'].element_spec[0])
graph = tfgnn.keras.layers.MapFeatures(
node_sets_fn=self.set_initial_node_state,
edge_sets_fn=self.set_initial_edge_state
)(input_graph)
if self.params['loss']=='categorical_crossentropy':
for i in range(self.params['graph_updates']):
graph = tfgnn.keras.layers.GraphUpdate(
node_sets = {
'schools': tfgnn.keras.layers.NodeSetUpdate({
'games': tfgnn.keras.layers.SimpleConv(
message_fn = self.dense_layer(self.params['message_dim']),
reduce_type="sum",
receiver_tag=tfgnn.TARGET)},
tfgnn.keras.layers.NextStateFromConcat(
self.dense_layer(self.params['next_state_dim'])))})(graph)
logits = tf.keras.layers.Dense(12,activation='softmax')(graph.node_sets['schools'][tfgnn.HIDDEN_STATE])
else:
for i in range(self.params['graph_updates']):
graph = tfgnn.keras.layers.GraphUpdate(
edge_sets = {'games': tfgnn.keras.layers.EdgeSetUpdate(
next_state = tfgnn.keras.layers.NextStateFromConcat(
self.dense_layer(self.params['next_state_dim'])))},
node_sets = {
'schools': tfgnn.keras.layers.NodeSetUpdate({
'games': tfgnn.keras.layers.SimpleConv(
message_fn = self.dense_layer(self.params['message_dim']),
reduce_type="sum",
receiver_tag=tfgnn.TARGET)},
tfgnn.keras.layers.NextStateFromConcat(
self.dense_layer(self.params['next_state_dim'])))})(graph)
logits = tf.keras.layers.Dense(1,activation='sigmoid')(graph.edge_sets['games'][tfgnn.HIDDEN_STATE])
return tf.keras.Model(input_graph, logits)
def train_model(self,trial=True):
model = self.build_model()
model.compile(tf.keras.optimizers.Adam(learning_rate=self.params['learning_rate']),
loss=self.params['loss'],
metrics=['Accuracy'])
callbacks = [tf.keras.callbacks.EarlyStopping(monitor='val_loss',
mode='min',
verbose=1,
patience=self.params['patience'],
restore_best_weights=True)]
model.fit(self.params['trainset'].repeat(),
validation_data=self.params['full_dataset'],
steps_per_epoch=self.params['steps_per_epoch'],
epochs=self.params['epochs'],
verbose=0,
callbacks = callbacks)
loss = self.evaluate_model(model,trial=trial)
if trial == True:
sys.stdout.flush()
hypt_params = {
'graph_updates':self.params['graph_updates'],
'feature_dim':self.params['feature_dim'],
'next_state_dim':self.params['next_state_dim'],
'message_dim':self.params['message_dim'],
'l2_reg':self.params['l2_reg'],
'dropout':self.params['dropout'],
'learning_rate':self.params['learning_rate']}
print(hypt_params,'loss:',loss)
return {'loss': loss, 'status': STATUS_OK}
else:
print('loss:',loss)
return model
def evaluate_model(self,model,trial=True):
if self.params['loss'] == 'categorical_crossentropy':
yhat = model.predict(full_node_dataset)
yhat_df = node_full_adj.set_index('school').iloc[:,-12:].copy()
yhat_df.iloc[:,:] = yhat
yhat_df = yhat_df.apply(lambda x: x == x.max(), axis=1).astype(int)
yhat_df = yhat_df.dot(yhat_df.columns).to_frame().rename(columns={0:'conf_yhat'})
yhat_df = yhat_df['conf_yhat'].str.replace('conf_', '').astype(int).to_frame()
yhat_df['conf_actual'] = node_full_adj.set_index('school')['conference']
yhat_df = yhat_df.loc[yhat_df.index.isin(node_test.index)]
yhat_df['Accuracy'] = yhat_df['conf_yhat']==yhat_df['conf_actual']
loss = 1 - yhat_df['Accuracy'].mean()
else:
yhat = model.predict(full_edge_dataset)
yhat_df = edge_full_adj.copy().set_index(['source','target'])
yhat_df['conf_game_yhat'] = yhat.round(0)
yhat_df = yhat_df.loc[yhat_df.index.isin(
edge_test.set_index(['source','target']).index)]
yhat_df['loss'] = abs(yhat_df['conference_game'] - yhat_df['conf_game_yhat'])
loss = yhat_df['loss'].mean()
return lossТеперь мы определяем наши параметры. Для наших параметров настройки мы можем либо явно определить значение (например, ‘dropout’: 0.1), либо определить пространство для экспериментов с Hyperopt, как мы сделали ниже. ‘hp.choice’ выберет один из указанных вами вариантов, в то время как ‘hp.uniform’ выберет варианты между двумя значениями. В документации Hyperopt доступно множество других опций.
params = {
### Tuning parameters ###
'graph_updates': hp.choice('graph_updates',[2,3,4]),
'feature_dim': hp.choice('feature_dim',[16,32,64,128]),
'message_dim': hp.choice('message_dim',[16,32,64,128]),
'next_state_dim': hp.choice('next_state_dim',[16,32,64,128]),
'l2_reg': hp.uniform('l2_reg',0.0,0.3),
'dropout': hp.choice('dropout',[0,0.125,0.25,0.375,0.5]),
'learning_rate': hp.uniform('learning_rate',0.0,0.1),
### Static parameters ###
'loss': 'categorical_crossentropy',
'epochs': 1000,
'steps_per_epoch':10, ### This could also be a tuned parameter
'patience':10,
'trainset':train_node_dataset,
'full_dataset':full_node_dataset
}Далее мы определяем вспомогательную функцию и подключаем ее к ‘fmin’ вместе с нашими параметрами. Каждая оценка представляет собой обученную модель, поэтому это может занять некоторое время в зависимости от вашего оборудования. Подумайте о том, чтобы делать меньше "max_evals", если это слишком медленно для вас. Наше личное эмпирическое правило - ~ 15 оценок на каждый настроенный параметр, поэтому мы бы четко определили некоторые параметры в связи с уменьшением количества оценок.
from hyperopt import fmin, tpe, hp, STATUS_OK, Trials
def tune_model(params):
return GCNN(params).train_model()
best = fmin(tune_model, params, algo=tpe.suggest,
max_evals=100, trials=Trials())Теперь, когда у нас есть наши лучшие гиперпараметры, мы можем обучить нашу окончательную модель (ПРИМЕЧАНИЕ: ваша точность будет немного отличаться из-за того, как TensorFlow случайным образом инициализирует свои веса).
### Perameters from my hyperopt run ###
best = {'graph_updates': 4,
'feature_dim': 64,
'next_state_dim': 32,
'message_dim': 128,
'l2_reg': 0.095,
'dropout': 0,
'learning_rate': 0.0025
}
node_params = params
for param, value in best.items():
node_params[param] = value
node_model = GCNN(node_params).train_model(trial=False)Мы можем настроить и обучить нашу модель edge с помощью нескольких незначительных корректировок:
params['loss'] = 'binary_crossentropy'
params['trainset'] = train_edge_dataset
params['full_dataset'] = full_edge_dataset
best = fmin(tune_model, params, algo=tpe.suggest,
max_evals=100, trials=Trials())### Perameters from my hyperopt run ###
best = {'graph_updates': 4,
'feature_dim': 64,
'next_state_dim': 32,
'message_dim': 128,
'l2_reg': 0.095,
'dropout': 0,
'learning_rate': 0.0025
}
edge_params = params
for param, value in best.items():
edge_params[param] = value
edge_model = GCNN(edge_params).train_model(trial=False)Заключительные мысли
Исследования GNN все еще находятся в зачаточном состоянии. Вероятно, будут открыты новые методы моделирования. Поскольку TF-GNN все еще находится в альфа-состоянии, есть большая вероятность, что с годами в коде могут произойти некоторые изменения.