Трассировка Python — объяснение

Мы редко получаем скрипт, работающий без каких-либо ошибок с первой попытки, что абсолютно нормально при написании кода. Важной и иногда сложной частью является исправление этих ошибок.
Процесс исправления ошибок и обеспечения ожидаемой работы скрипта может занять много итераций в зависимости от опыта программиста и имеющейся у нас информации об ошибке. Языки программирования дают нам некоторые подсказки относительно того, что может быть причиной ошибки, что в основном и делает трассировка Python.
Трассировку в Python можно рассматривать как отчет, который помогает нам понять и устранить проблему в коде. В этой статье мы узнаем, что такое обратная трассировка в Python, как читать сообщения обратной трассировки, чтобы иметь возможность использовать их более эффективно, и различные типы ошибок.
Обратная трассировка в Python
Программа на Python останавливает выполнение, когда она сталкивается с ошибкой, которая может быть в форме синтаксической ошибки или исключения. Синтаксические ошибки возникают, когда интерпретатор обнаруживает недопустимый синтаксис, и их относительно легче исправить.
Примером синтаксической ошибки может быть несоответствующая скобка. С другой стороны, исключение возникает, когда синтаксис правильный, но программа выдает ошибку.
Обратная трассировка - это отчет, который помогает нам понять причину исключения. Он содержит вызовы функций, выполненные в коде, вместе с номерами их строк, чтобы мы не были в неведении о проблеме, вызывающей сбой кода.
Давайте рассмотрим простой пример.
Приведенный ниже фрагмент кода создает функцию, которая складывает два числа и умножает сумму на первое число. Затем он вызывает функцию с аргументами 5 и 4. Однако 4 передается как строка, так что на самом деле это не число.
def add_and_multiply(x, y):
return (x + y) * x
add_and_multiply(5, "4")Когда этот код выполняется, Python вызывает следующее исключение:
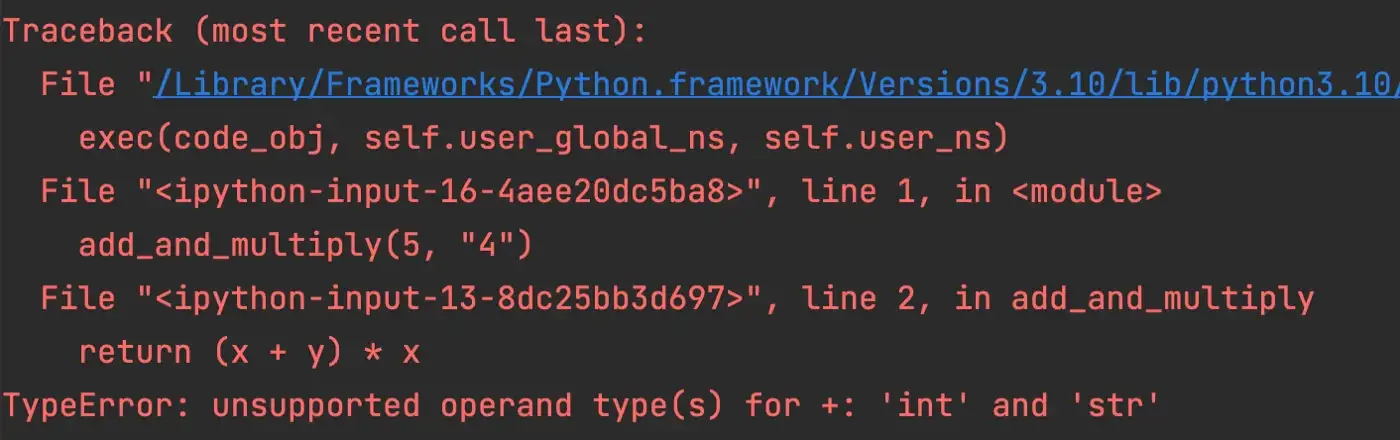
В последней строке показан тип ошибки вместе с кратким объяснением. Ошибка в этом случае - это ошибка типа, вызванная неподдерживаемым операндом между целыми числами и строками. Оператор плюс не может быть использован для добавления строки к целому числу, поэтому код приводит к исключению.
Строки над последней сообщают нам, где произошло исключение, с точки зрения имени функции и номера строки. Приведенный здесь пример очень прост, но при работе с очень длинными сценариями или программой с несколькими сценариями информация об именах функций и номерах строк весьма полезна для диагностики и устранения проблемы.
Обратная трассировка также показывает имена модулей и файлов, что очень полезно при работе со сценариями, которые импортируют модули из других файлов или скриптов. Способ отображения имен файлов и модулей немного меняется в зависимости от вашей рабочей среды (например, терминала или ОТВЕТА).
Например, когда я сохраняю приведенный выше фрагмент кода как «sample_script.py» и пытаюсь запустить его в терминале, я получаю следующую трассировку:
Traceback (most recent call last):
File "/Users/sonery/sample_script.py", line 6, in <module>
add_and_multiply(5, "6")
File "/Users/sonery/sample_script.py", line 2, in add_and_multiply
print((x + y) * x)
TypeError: unsupported operand type(s) for +: 'int' and 'str'В любом случае, мы получаем информативную зацепку в сообщениях обратной связи.
Распространенные типы обратной трассировки
Значительное количество времени при создании эффективных программ и поддержании их в рабочем состоянии тратится на отладку ошибок. Следовательно, крайне важно использовать обратные трассировки Python.
В противном случае на поиск и устранение неполадок могут потребоваться часы, что может иметь серьезные последствия, если программа уже запущена в производство.
Наиболее важной частью сообщения об обратном отслеживании является тип ошибки, поскольку он дает нам подсказки о том, какая ошибка приводит к остановке выполнения скрипта.
Давайте рассмотрим некоторые из часто встречающихся типов ошибок в сообщениях обратной трассировки.
TypeError
Ошибка типа возникает, когда тип данных объекта несовместим с определенной операцией. Пример, который мы сделали в начале, где добавляются целое число и строка, является примером этой ошибки.
AttributeError
В Python все является объектом с таким типом, как целое число, строка, список, кортеж, словарь и так далее. Типы определяются с помощью классов, которые также имеют атрибуты, используемые для взаимодействия с объектами класса.
Классы могут иметь атрибуты данных и процедурные атрибуты (т.е. методы):
- Атрибуты данных: что необходимо для создания экземпляра класса
- Методы (т.е. процедурные атрибуты): Как мы взаимодействуем с экземплярами класса.
Предположим, у нас есть объект типа list. Мы можем использовать метод append для добавления нового элемента в список. Если у объекта нет атрибута, который мы пытаемся использовать, возникает исключение ошибки атрибута.
Вот пример:
mylist = [1, 2, 3, 4, 5]
mylist.add(10)
# output
Traceback (most recent call last):
File "<file>", line 3378, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-25-4ad0ec665b52>", line 3, in <module>
mylist.add(10)
AttributeError: 'list' object has no attribute 'add'Поскольку класс list не имеет атрибута с именем “add”, мы получаем трассировку, показывающую ошибку атрибута.
ImportError и ModuleNotFoundError
Python имеет огромный выбор сторонних библиотек (т.е. модулей), что позволяет выполнять множество задач за несколько строк кода.
Чтобы использовать такие библиотеки, а также встроенные библиотеки Python (например, ОС, запросы), нам необходимо их импортировать. Если при их импорте возникает проблема, возникает исключение importerror или module not found error.
Например, в следующем фрагменте кода мы пытаемся импортировать класс логистической регрессии из Scikit-learn.
from sklearn import LogisticRegression
# output
Traceback (most recent call last):
File "<file>", line 3378, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-22-b74afc1ba453>", line 1, in <module>
from sklearn import LogisticRegression
ImportError: cannot import name 'LogisticRegression' from 'sklearn' (/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/sklearn/__init__.py)Возникает исключение ошибки импорта, поскольку класс логистической регрессии доступен в модуле линейной модели. Правильный способ импорта следующий.
from sklearn.linear_model import LogisticRegressionИсключение ошибки модуля не найдено возникает, если модуль недоступен в рабочей среде.
import openpyxl
# output
Traceback (most recent call last):
File "<file>", line 3378, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-23-f5ea1cbb6934>", line 1, in <module>
import openpyxl
File "/Applications/PyCharm CE.app/Contents/plugins/python-ce/helpers/pydev/_pydev_bundle/pydev_import_hook.py", line 21, in do_import
module = self._system_import(name, *args, **kwargs)
ModuleNotFoundError: No module named 'openpyxl'IndexError
Некоторые структуры данных имеют индекс, который можно использовать для доступа к их элементам, таким как списки, кортежи и кадры данных Pandas. Мы можем получить доступ к определенному элементу, используя индекс последовательности.
names = ["John", "Jane", "Max", "Emily"]
# Get the third item
names[2]
# output
"Max"Если индекс выходит за пределы допустимого диапазона, возникает исключение ошибки индекса.
names = ["John", "Jane", "Max", "Emily"]
# Get the sixth item
names[5]
# output
Traceback (most recent call last):
File "<file>", line 3378, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-30-3033b2837dcd>", line 3, in <module>
names[5]
IndexError: list index out of rangeПоскольку список содержит 4 элемента, возникает исключение, когда мы пытаемся получить доступ к шестому элементу, которого не существует.
Давайте рассмотрим другой пример, используя фрейм данных Pandas.
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(10, size=(5, 2)), columns=["A", "B"])
df
# output
A B
0 1 6
1 6 3
2 8 8
3 3 5
4 5 6Переменная df представляет собой DataFrame с 5 строками и 2 столбцами. Следующая строка кода пытается получить значение в третьем столбце первой строки.
df.iloc[0, 3]
# output
Traceback (most recent call last):
File "<file>", line 3378, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<file>", line 1, in <module>
df.iloc[0, 3]
File "<file>", line 960, in __getitem__
return self.obj._get_value(*key, takeable=self._takeable)
File "<file>", line 3612, in _get_value
series = self._ixs(col, axis=1)
File "<file>", line 3439, in _ixs
label = self.columns[i]
File "<file>", line 5039, in __getitem__
return getitem(key)
IndexError: index 3 is out of bounds for axis 0 with size 2Как мы видим в последней строке трассировки, это сообщение об ошибке говорит само за себя.
NameError
Исключение ошибки имени возникает, когда мы ссылаемся на переменную, которая не определена в нашем коде.
Вот пример:
members = ["John", "Jane", "Max", "Emily"]
member[0]
# output
Traceback (most recent call last):
File "<file>", line 3378, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-35-9fcefb83a26f>", line 3, in <module>
name[5]
NameError: name 'member' is not definedИмя переменной — члены, поэтому мы получаем ошибку, когда пытаемся использовать член вместо членов.
ValueError
Исключение ошибки значения возникает, когда мы пытаемся присвоить неправильное значение переменной. Вспомните наш DataFrame с 5 строками и 2 столбцами.
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(10, size=(5, 2)), columns=["A", "B"])
df
# output
A B
0 1 6
1 6 3
2 8 8
3 3 5
4 5 6Допустим, мы хотим добавить новый столбец в этот DataFrame.
df["C"] = [1, 2, 3, 4]
# output
Traceback (most recent call last):
File "<file>", line 3378, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<file>", line 1, in <module>
df["C"] = [1, 2, 3, 4]
File "<file>", line 3655, in __setitem__
self._set_item(key, value)
File "<file>", line 3832, in _set_item
value = self._sanitize_column(value)
File "<file>", line 4535, in _sanitize_column
com.require_length_match(value, self.index)
File "<file>", line 557, in require_length_match
raise ValueError(
ValueError: Length of values (4) does not match length of index (5)Как объясняется в сообщении об ошибке, фрейм данных содержит 5 строк, поэтому каждый столбец имеет 5 значений. Когда мы пытаемся создать новый столбец со списком из 4 элементов, мы ошибку значения.
Заключительные мысли
Сообщения об ошибках очень полезны при отладке кода или его правильном выполнении в первый раз. К счастью, трассировка Python имеет четкие и поясняющие сообщения об ошибках.
В этой статье мы узнали, что такое обратная трассировка, как ее читать и некоторые из распространенных типов обратных трассировок.