Ускорение Python на графических процессорах с помощью nvc++ и Cython
Стандартная библиотека C++ содержит богатую коллекцию контейнеров, итераторов и алгоритмов, которые можно составить для получения элегантных решений сложных проблем. Что наиболее важно, они быстрые, что делает C++ привлекательным выбором для написания высокопроизводительного кода.
NVIDIA недавно представила stdpar: способ автоматического ускорения выполнения алгоритмов стандартной библиотеки C++ на графических процессорах с помощью компилятора nvc++. Это означает, что программы на C++, использующие стандартные библиотечные контейнеры и алгоритмы, теперь могут работать еще быстрее.
В этом посте я исследую способ внедрения алгоритмов C++ с ускорением на GPU в экосистему Python. Я использую Cython как способ вызвать C++ из Python и показать вам, как создавать код Cython с помощью nvc++. Я представляю два примера: простую задачу по сортировке последовательности чисел и более сложное реальное приложение, метод Якоби. В обоих случаях вы увидите впечатляющий прирост производительности по сравнению с традиционным подходом к использованию NumPy. Наконец, я обсуждаю некоторые текущие ограничения и следующие шаги.
Использование C++ из Python
Если вы никогда раньше не использовали Cython или могли бы воспользоваться обновлением, вот пример написания функции в Cython, которая сортирует набор чисел с помощью функции сортировки C++ . Поместите следующий код в файл cppsort.pyx:
# distutils: language=c++
from libcpp.algorithm cimport sort
def cppsort(int[:] x):
sort(&x[0], &x[-1] + 1)
Вот объяснение различных частей этого кода:
- Первая строка сообщает Cython использовать режим C++, а не C (по умолчанию).
- Вторая строка делает доступной функцию сортировки C++. Ключевое слово
cimportиспользуется для импорта функциональности C/C++. - Наконец, программа определяет функцию
cppsort, которая выполняет следующее:Принимает один параметрx. Предшествующиеint[:]определяет тип изx, в данном случае, одномерный массив целых чисел.Вызываетstd::sortсортировку элементовx. Аргументы&x[0]и&x[-1] + 1относятся к первому и последнему элементу массива соответственно.
Для получения дополнительных сведений о синтаксисе и функциях Cython см. Учебное пособие по Cython.
В отличие от файлов .py, файлы .pyx нельзя импортировать напрямую. Чтобы вызвать функцию из Python, необходимо встроить расширение cppsort.pyx, которое можно импортировать из Python. Выполните следующую команду:
cythonize -i cppsort.pyx
С помощью этой команды происходит несколько вещей (рисунок 1). Сначала Cython переводит код cppsort.pyx на C++ и генерирует файл cppsort.cpp. Затем компилятор C++ (в данном случае g++) компилирует этот код C++ в модуль расширения Python. Название модуля расширения примерно такое cppsort.cpython-38-x86_64-linux-gnu.so.

Модуль расширения можно импортировать из Python, как и любой другой модуль Python:
from cppsort import cppsortВ качестве проверки функции отсортируйте массив целых чисел NumPy:
import numpy as np
x = np.array([4, 3, 2, 1], dtype="int32")
print(x)
# [4 3 2 1]
cppsort(x)
print(x)
# [1 2 3 4]Фантастика! Вы эффективно отсортировали массив в Python с помощью C++ std::sort!
Ускорение графического процессора с использованием nvc++
Алгоритмы стандартной библиотеки C++, например std::sort, могут быть вызваны с дополнительным аргументом политики параллельного выполнения. Этот аргумент сообщает компилятору, что вы хотите, чтобы выполнение алгоритма было распараллелено. Компилятор, например g++, может выбрать распараллеливание выполнения с использованием потоков ЦП. Однако, если вы скомпилируете свой код с помощью компилятора nvc++ и передадите опцию -stdpar, выполнение будет ускорено графическим процессором.
Еще одно важное изменение - создание локальной копии входного массива внутри функции cppsort. Это связано с тем, что графический процессор может получить доступ только к данным, которые выделены в коде, скомпилированном с nvc++ помощью параметра -stdpar. В этом примере входной массив выделяется NumPy, который не может быть скомпилирован с использованием nvc++.
В следующем примере кода функция cppsort переписана с учетом более ранних изменений. Он включает использование вектора для управления локальной копией входного массива и функцию copy_n для копирования данных в него и из него.
from libcpp.algorithm cimport sort, copy_n
from libcpp.vector cimport vector
from libcpp.execution cimport par
def cppsort(int[:] x):
cdef vector[int] temp
temp.resize(len(x))
copy_n(&x[0], len(x), temp.begin())
sort(par, temp.begin(), temp.end())
copy_n(temp.begin(), len(x), &x[0])
Сборка расширения с помощью nvc++
Когда вы запускаете команду cythonize, для создания расширения используется обычный хост-компилятор C++ (g++) (рисунок 1). Чтобы выполнение алгоритмов, вызванных политикой выполнения par, было выгружено на GPU, вы должны построить расширение с помощью компилятора nvc++ (рисунок 2). Вы также должны передать несколько настраиваемых параметров, например -stdpar, для команд компилятора и компоновщика. Когда процесс сборки включает в себя дополнительные шаги, подобные этим, часто рекомендуется заменить использование команды cythonize сценарием setup.py. Для получения дополнительной информации о подробной реализации см. файл setup.py в репозитории shwina/stdpar-cython GitHub, который изменяет процесс сборки для использования nvc++ вместе с соответствующими флагами компилятора и компоновщика.

Используя файл setup.py, следующая команда создает модуль расширения:
CC=nvc++ python setup.py build_ext --inplace
То, как вы импортируете и используете функцию из Python, не изменилось, но теперь сортировка происходит на графическом процессоре:
x = np.array([4, 3, 2, 1], dtype="int32")
cppsort(x) # uses the GPU!
Производительность
На рисунке 3 показано сравнение функции cppsort с методом .sort NumPy. Код, используемый для генерации этих результатов, можно найти в блокноте sort.ipynb Jupyter. Представлены три версии функции:
- Последовательная версия вызывает
std::sortбез какой-либо политики выполнения. - Параллельная версия CPU использует политику параллельного выполнения и скомпилирована с помощью g++.
- Версия GPU также использует параллельную политику выполнения, но скомпилирован с
nvc++и опцией компилятора-stdpar.
Для задач большего размера версия GPU работает значительно быстрее, чем другие - примерно в 20 раз быстрее, чем NumPy .sort!
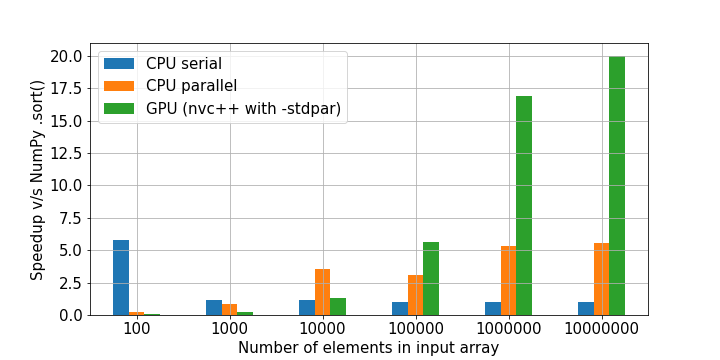
Тесты ЦП проводились на системе с ЦП Intel Xeon Gold 6128. Тесты графического процессора выполнялись на графическом процессоре NVIDIA A100.
Пример приложения: Якоби
В качестве более сложного примера рассмотрим использование метода Якоби для решения двумерного уравнения теплопроводности. Это математическое уравнение можно использовать, например, для прогнозирования установившейся температуры в квадратной пластине, которая нагревается с одной стороны.
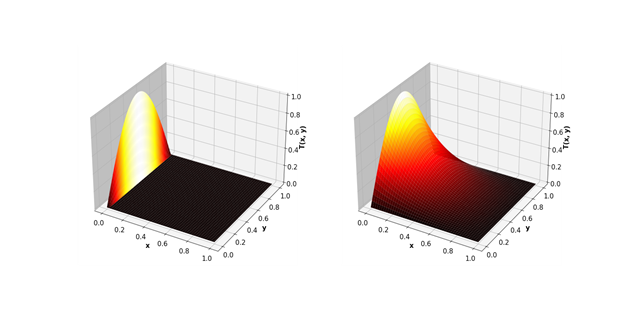
Метод Якоби состоит в аппроксимации квадратной пластины двумерной сеткой точек. Двумерный массив используется для представления температуры в каждой из этих точек. Каждая итерация обновляет элементы массива на основе значений, вычисленных на предыдущем шаге, используя следующую схему обновления:
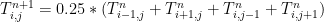
Это повторяется до тех пор, пока не будет достигнута сходимость: когда значения, полученные в конце двух последующих итераций, существенно не различаются.
С точки зрения программирования, метод Якоби может быть реализован на C++ с использованием алгоритмов стандартной библиотеки std::for_each для выполнения шага обновления и std::any_of для проверки сходимости. В следующем коде Cython эти функции C++ используются для реализации метода Якоби. Дополнительные сведения о реализации см. В jacobi.ipynb Jupyter.
# distutils: language=c++
# cython: cdivision=True
from libcpp.algorithm cimport swap
from libcpp.vector cimport vector
from libcpp cimport bool, float
from libc.math cimport fabs
from algorithm cimport for_each, any_of, copy
from execution cimport par, seq
cdef cppclass avg:
float *T1
float *T2
int M, N
avg(float* T1, float *T2, int M, int N):
this.T1, this.T2, this.M, this.N = T1, T2, M, N
inline void call "operator()"(int i):
if (i % this.N != 0 and i % this.N != this.N-1):
this.T2[i] = (
this.T1[i-this.N] + this.T1[i+this.N] + this.T1[i-1] + this.T1[i+1]) / 4.0
cdef cppclass converged:
float *T1
float *T2
float max_diff
converged(float* T1, float *T2, float max_diff):
this.T1, this.T2, this.max_diff = T1, T2, max_diff
inline bool call "operator()"(int i):
return fabs(this.T2[i] - this.T1[i]) > this.max_diff
def jacobi_solver(float[:, :] data, float max_diff, int max_iter=10_000):
M, N = data.shape[0], data.shape[1]
cdef vector[float] local
cdef vector[float] temp
local.resize(M*N)
temp.resize(M*N)
cdef vector[int] indices = range(N+1, (M-1)*N-1)
copy(seq, &data[0, 0], &data[-1, -1], local.begin())
copy(par, local.begin(), local.end(), temp.begin())
cdef int iterations = 0
cdef float* T1 = local.data()
cdef float* T2 = temp.data()
keep_going = True
while keep_going and iterations < max_iter:
iterations += 1
for_each(par, indices.begin(), indices.end(), avg(T1, T2, M, N))
keep_going = any_of(par, indices.begin(), indices.end(), converged(T1, T2, max_diff))
swap(T1, T2)
if (T2 == local.data()):
copy(seq, local.begin(), local.end(), &data[0, 0])
else:
copy(seq, temp.begin(), temp.end(), &data[0, 0])
return iterations
Производительность
На рисунке 5 показано ускорение, полученное от трех различных реализаций Cython на основе C++ по сравнению с реализацией NumPy итерации Якоби.
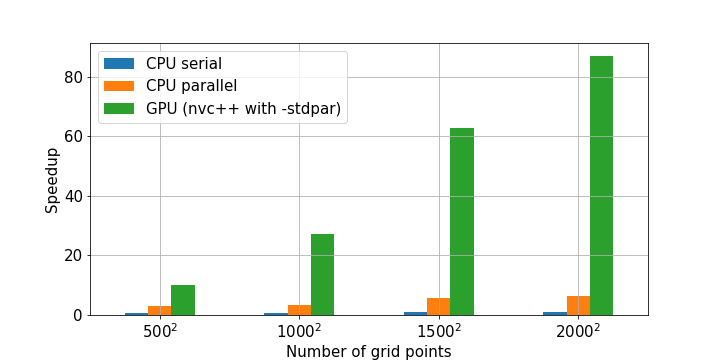
Cython и stdpar привносят в Python ускоренные алгоритмы
stdpar представил способ выполнения алгоритмов стандартной библиотеки C++, таких как подсчет, агрегирование, преобразование и поиск на графическом процессоре. С Cython вы можете использовать эти алгоритмы с ускорением на GPU из Python вообще без программирования на C++.
Cython естественным образом взаимодействует с другими пакетами Python для научных вычислений и анализа данных благодаря встроенной поддержке массивов NumPy и протокола буферов Python. Это позволяет выгружать ресурсоемкие части существующего кода Python на графический процессор с помощью Cython и nvc++. Один и тот же код может быть создан для работы на процессорах или графических процессорах, что упрощает разработку и тестирование в системе без графического процессора.
Одним из важных текущих ограничений этого подхода является то, что часто требуется копия входных данных. В Python память выделяется внутри библиотек, таких как NumPy. Такая память, выделенная извне, недоступна для GPU.