Введение в анализ настроений с помощью распознавания речи

В этой статье мы научимся анализировать речь с помощью анализа настроений. Анализ настроений — это процесс понимания мнения или эмоционального тона при написании предложения. Это отличная тема, обычно рассматриваемая в рамках темы «Обработка естественного языка».
С развитием моделей искусственного интеллекта методы NLP также стали более продуманными и интеллектуальными при понимании людей. Анализ настроений сейчас используется во многих отраслях, от чат-ботов до исследований отзывов о продуктах.
Начнем
Во-первых, нам нужны данные для анализа настроений. Эти данные могут быть одним предложением, которое вы пишете внутри текстового документа, или длинной речью на конференции.
В этом уроке я буду использовать аудиозапись чтения некоторых предложений. А внутри программы я буду использовать распознаватель речи для преобразования речи в текстовый формат.
Мы собираемся использовать Speech-to-Text API AssemblyAI. Это очень хорошо обученный API искусственного интеллекта. Это бесплатно. Вы получите уникальный ключ API после создания учетной записи. Мы будем использовать этот ключ API для использования услуг и функций.
Давайте начнем.
Шаг 1: Библиотеки
В качестве нашей среды кодирования я выберу Jupyter Notebook. Мне нравится использовать его для таких проектов машинного обучения, как этот. Легко отслеживать процесс и вносить определенные изменения в разные блоки, не затрагивая весь код.
Все библиотеки, которые нам нужны, являются встроенными библиотеками Python. Таким образом, нам не нужно устанавливать какие-либо библиотеки.
Давайте продолжим, откроем новый блокнот Jupyter и импортируем библиотеки.
import sys
import time
import requests
Шаг 2: Аудиоданные
Как вы можете понять из названия, на этом шаге мы будем импортировать аудиоданные. Эти данные могут быть короткой голосовой заметкой, длинной речью или чем угодно, с чем вы хотите работать. Для простоты я сделаю короткую аудиозапись.
Когда наши данные готовы, пришло время импортировать их в программу. Поскольку мы будем использовать API для транскрипции и анализа настроений, мы должны загрузить запись в облачное хранилище. Я буду использовать облако AssemblyAI для более простого доступа к данным.
Я перемещу файл записи в ту же папку, что и мой блокнот Jupyter. А затем определю его в программе.
audio_data = "review_recording.m4a"
Теперь пришло время написать функцию для чтения этого файла аудиозаписи. Кстати, формат файла должен быть аудиоформатом, чтобы наша функция чтения работала корректно.
def read_audio_file(audio_data, chunk_size=5242880):
with open(audio_data, 'rb') as _file:
while True:
data = _file.read(chunk_size)
if not data:
break
yield data
Пришло время загрузить нашу аудиозапись в облако.
headers = {
"authorization": "API key goes here"
}
response = requests.post('https://api.assemblyai.com/v2/upload', headers=headers, data=read_audio_file(audio_data))
print(response.json())
Здорово! После запуска этого блока кода. Мы получим ответ от API. Ответное сообщение будет содержать URL-адрес загруженного файла.

Шаг 3: Транскрипция аудио с анализом тональности
Почти готово! На этом этапе будет запущена модель облачной транскрипции с функцией анализа тональности. Это отличный способ получить быстрый ответ в течение нескольких секунд. Все происходит в облаках AssemblyAI, и нам не нужно беспокоиться о характеристиках нашего устройства.
Вот официальная документация, если вы хотите узнать больше.
Хорошо, давайте сделаем это.
Мы определим четыре переменные: одну строку, два словаря и один POST-запрос. Анализ настроений включается, когда мы добавляем назначенное значение True. Если False, запрос будет выполнять обычное распознавание речи.
speech_to_text_api = "https://api.assemblyai.com/v2/transcript"
data = {
"audio_url": "The upload url address from the previous step",
"sentiment_analysis": "TRUE"
}
headers = {
"authorization": "API key goes here",
"content-type": "application/json"
}
response = requests.post(speech_to_text_api, json=data, headers=headers)
print(response.json())
После запуска этого блока кода наш заказ-запрос попадет в облачную очередь и будет ждать своей очереди для обработки. Вот ответ, который я получил:
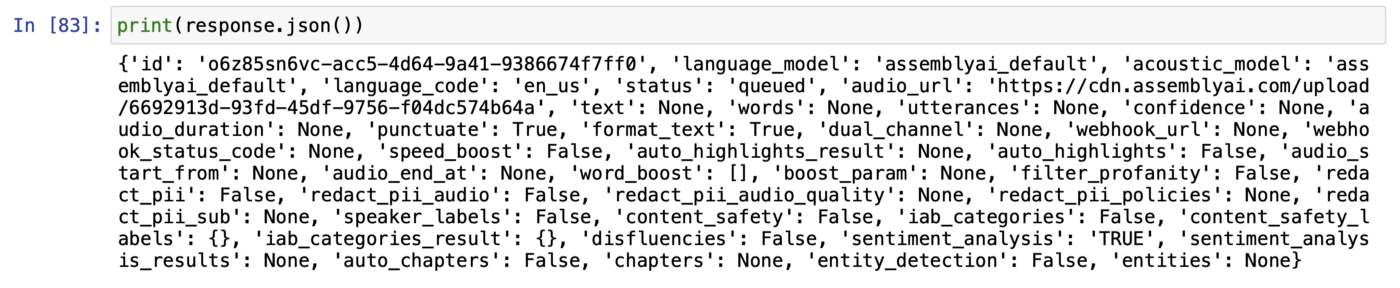
id — это идентификатор нашего запроса. Он понадобится нам для отслеживания процесса. И ключ state показывает статус нашего заказа.
Заключительный шаг: понимание результатов
На этом последнем шаге мы проверим результаты нашего запроса и проанализируем их. Давайте продолжим и проверим ответ, запустив следующий блок кода.
request_url = "https://api.assemblyai.com/v2/transcript/o6z85sn6vc-acc5-4d64-9a41-9386674f7ff0"
headers = {
"authorization": "API key goes here"
}
response = requests.get(request_url, headers=headers)
print(response.json())Вот скриншот всего ответа:

Давайте продолжим и отфильтруем ключ анализа тональности из этого длинного словаря.
sentiment_analysis_report = response.json()['sentiment_analysis_results']
sentiment_analysis_report
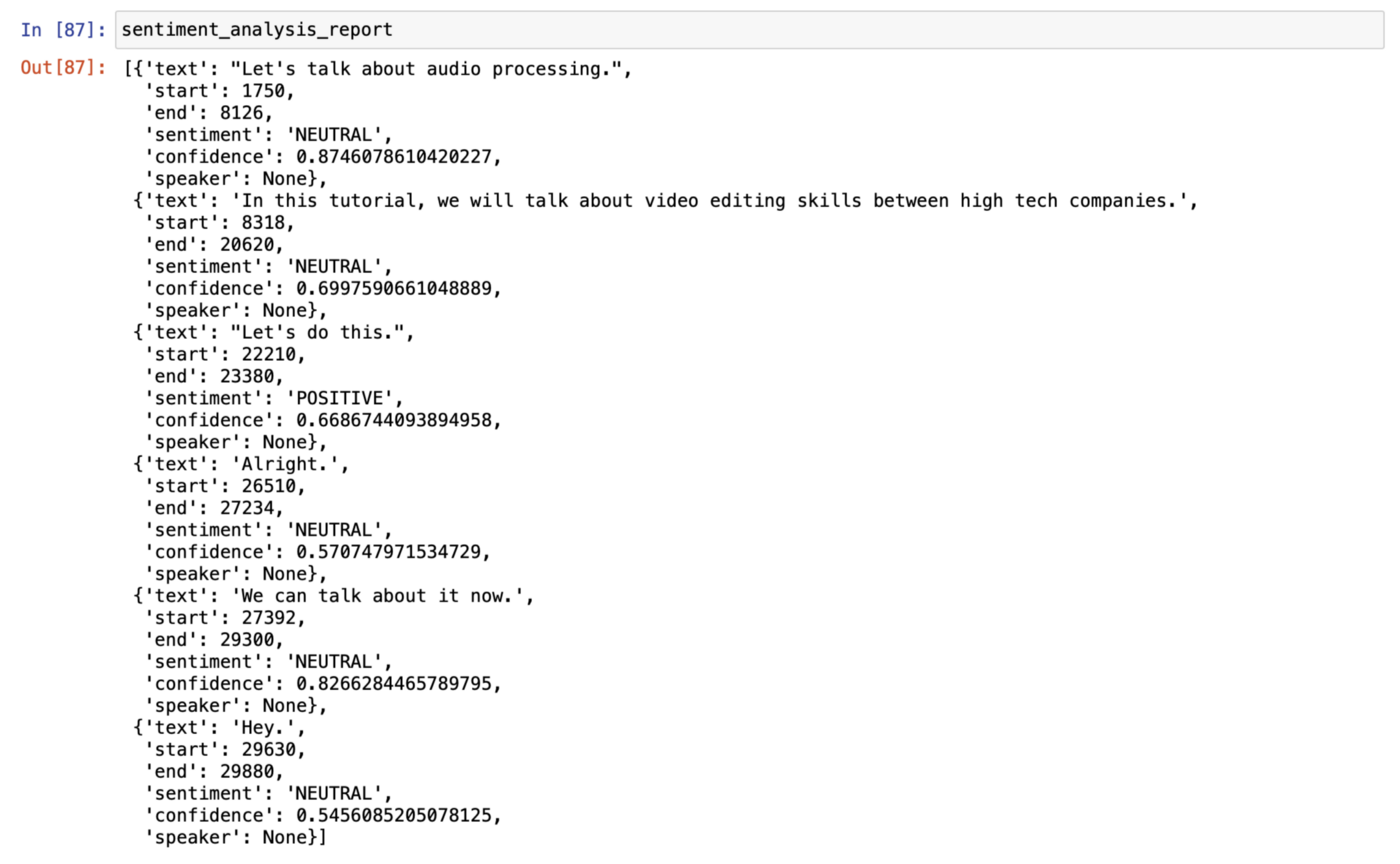
Выглядит идеально! Мы получили отчет об анализе тональности записи речи с парой строк кода. Анализ настроений разбивает каждое предложение, найденное в записи, а затем анализирует, чтобы определить, являются ли они положительными, нейтральными или отрицательными. В отчете даже указано, насколько модель уверена в своем решении. Разве это не круто?
То, что мы сделали в этом уроке, было просто простым упражнением; будет интересно посмотреть, как модель будет вести себя с более длинными записями речи. Теперь у вас есть представление о том, как анализ настроений работает в реальном проекте. Работа над практическими проектами программирования, подобными этому, — лучший способ отточить свои навыки кодирования.