Введение в Apache Hudi с PySpark

Чтобы преодолеть проблему удаления одной строки из системы больших данных, на рынке доступно множество решений, например, от транзакционных свойств Hive до функций Delta блоков данных. Сегодня мы узнаем об Apache Hudi и сделаем несколько практических шагов по удалению записей из наборов данных.
Среды: AWS EMR 5.32 (включая Spark 2.4.3)
В AWS EMR 5.32 по умолчанию мы получили jar-файлы apache hudi, для их использования нам просто нужно предоставить некоторые аргументы:

Давайте углубимся и посмотрим, как Insert / Update и Deletion работают с Hudi при использовании Apache Spark (pyspark).
Набор данных:
Для демонстрации мы используем образец данных пользователя и его пароль восстановления.

Прежде чем мы продолжим прием этих данных, давайте сначала создадим таблицу в spark / hive.
CREATE TABLE `user_password_info`(
`timestamp` STRING,
`username` STRING,
`identifier` STRING,
`otp` STRING,
`code` STRING,
`first_name` STRING,
`last_name` STRING,
`department` STRING,
`location` STRING)
STORED AS
INPUTFORMAT 'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat';
После создания таблицы мы прочитаем наборы данных и попытаемся вставить их в приведенную выше таблицу hudi.
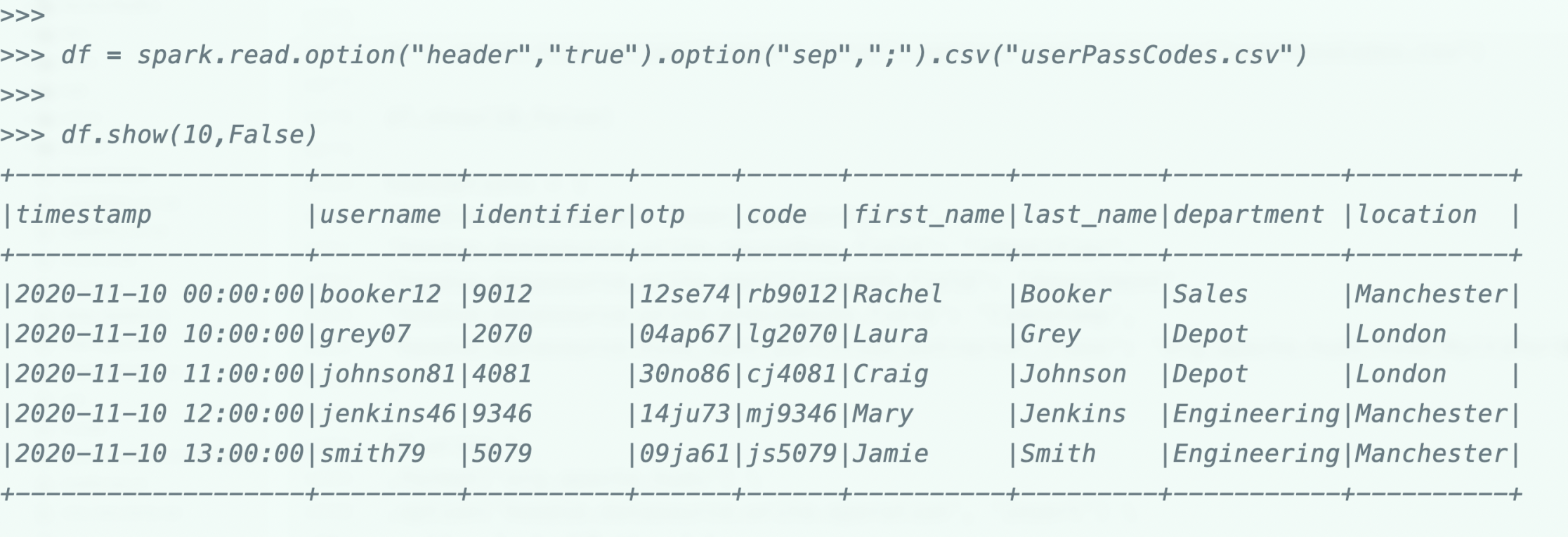

мы закончили с записью данных и выберем одного пользователя и попытаемся обновить соответствующее ему значение.
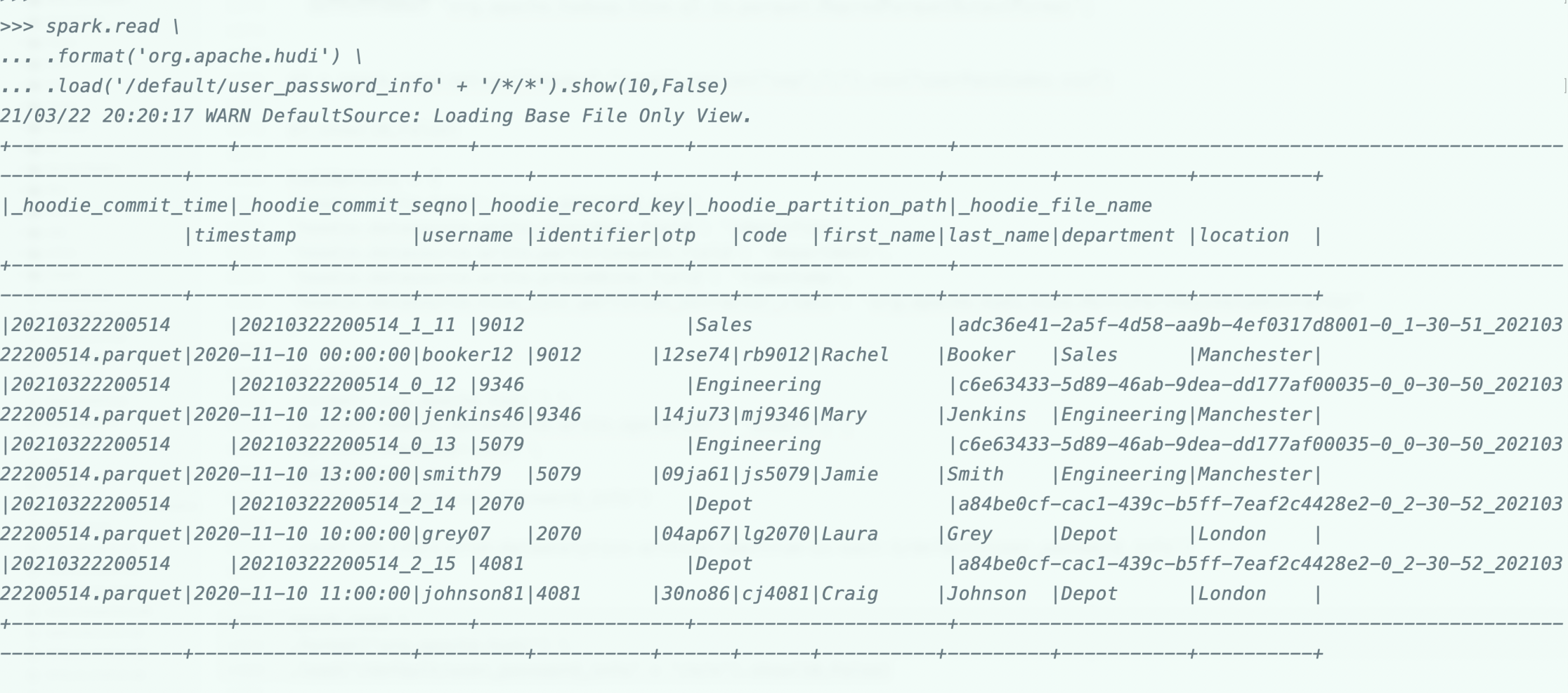
В приведенной выше ячейке мы можем видеть некоторые дополнительные столбцы, это столбцы метаданных hudi. Если мы непосредственно читаем таблицу и не сохранили эти столбцы в схеме, то они не будут отображаться при запросе.
Давайте возьмем пример для пользователя Rachel, и мы попытаемся обновить имя пользователя для Rachel.
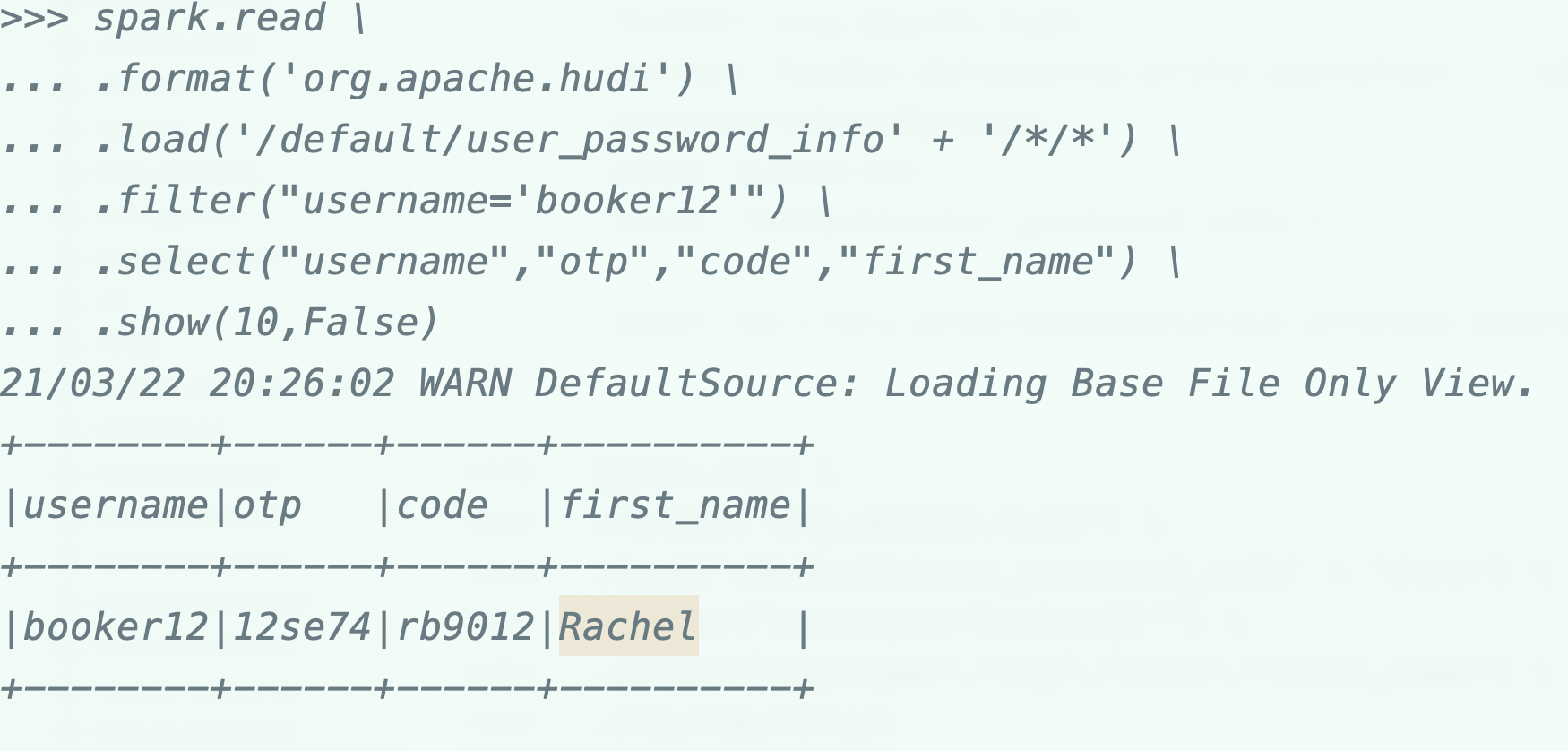
мы хотим обновить имя пользователя Rachel с «booker12» -> «rachel12»
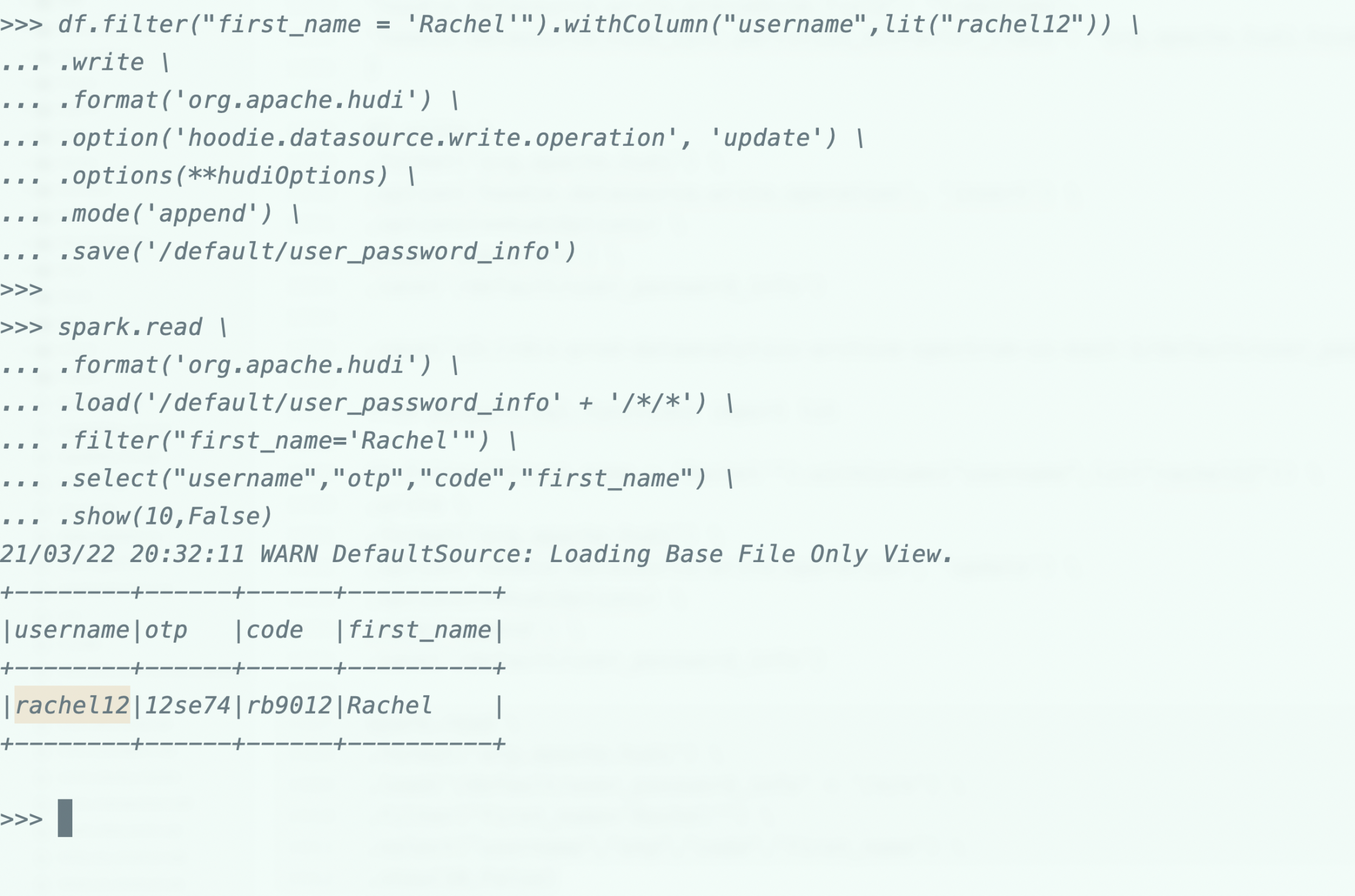
Итак, мы видим, что имя пользователя, соответствующее «Рэйчел», обновлено. Теперь удалим самого пользователя из таблицы.

Мы видим, что пользователя «Rachel» в таблице больше нет.
На практике Apache Spark поддерживает hudi, просто помещая библиотеки hudi в путь к классам Spark, и это, безусловно, очень поможет в управлении соблюдением конфиденциальности пользователя или изменением размеров.