Изучение метода случайного леса используя Python

Практический пример сквозного машинного обучения
Никогда не было лучшего времени, чтобы углубиться в машинное обучение. Обилие учебных ресурсов, доступных в Интернете, в сочетании с бесплатными инструментами с открытым исходным кодом, предлагающими реализацию широкого спектра алгоритмов, и доступность вычислительной мощности через облачные сервисы, такие как AWS, действительно демократизировали область машинного обучения. Теперь любой, у кого есть ноутбук и желание учиться, может поэкспериментировать с самыми современными алгоритмами за считанные минуты. Потратив немного больше времени и усилий, вы сможете разработать практические модели, которые помогут вам в повседневной жизни или работе, и даже перейти в область машинного обучения, чтобы воспользоваться его экономическими преимуществами.
В этом блоге я проведу вас через сквозную реализацию мощной модели машинного обучения случайного леса. Хотя он дополняет мое концептуальное объяснение случайных лесов, его также можно понимать независимо, если вы понимаете основную идею решений деревьев и случайных лесов. Я предоставил полный проект, включая данные, на GitHub, и вы можете загрузить файл данных и блокнот Jupyter с Google Диска. Все, что вам нужно, — это ноутбук с установленным Python и возможность запустить блокнот Jupyter, чтобы продолжить работу. Хотя будет использоваться код Python, его цель не в том, чтобы запугать, а скорее в том, чтобы продемонстрировать, насколько доступным стало машинное обучение с доступными сегодня ресурсами! Хотя этот проект охватывает несколько важных тем машинного обучения, я постараюсь четко объяснить их и предоставить дополнительные учебные ресурсы для тех, кто заинтересован.

Введение проблемы
Задача, которую мы решаем, заключается в том, чтобы предсказать завтрашнюю максимальную температуру в нашем городе, используя исторические данные о погоде за один год. Хотя я выбрал Сиэтл, штат Вашингтон, в качестве города для этого примера, не стесняйтесь собирать данные для вашего собственного местоположения с помощью онлайн-инструмента NOAA Climate Data. Наша цель — делать прогнозы, не полагаясь на существующие прогнозы погоды, поскольку гораздо интереснее создавать собственные прогнозы. У нас есть доступ к прошлым максимальным температурам за год, а также к температурам за предыдущие два дня и оценке от друга, который утверждает, что обладает исчерпывающими знаниями о погоде. Это проблема машинного обучения с контролируемой регрессией. Это считается контролируемым, потому что у нас есть как признаки (данные по городу), так и целевые показатели (температура), которые мы хотим спрогнозировать. В процессе обучения мы предоставляем алгоритму случайного леса как признаки, так и цели, что позволяет ему научиться сопоставлять данные с прогнозом. Кроме того, эта задача подпадает под регрессию, поскольку целевое значение является непрерывным, в отличие от дискретных классов, встречающихся при классификации. Установив эту справочную информацию, давайте погрузимся в реализацию!
План
Прежде чем погрузиться в программирование, важно наметить краткое руководство, которое поможет нам сосредоточиться. Следующие шаги обеспечивают основу для любого рабочего процесса машинного обучения после того, как мы определили проблему и выбрали модель:
- Четко сформулируйте вопрос и определите необходимые данные.
- Получите данные в легкодоступном формате.
- Определите и при необходимости устраните любые отсутствующие точки данных или аномалии.
- Подготовьте данные, чтобы они подходили для модели машинного обучения.
- Установите базовую модель, которую вы стремитесь превзойти.
- Обучите модель с помощью обучающих данных.
- Используйте модель, чтобы делать прогнозы на тестовых данных.
- Сравните прогнозы модели с известными целями в тестовом наборе и рассчитайте показатели производительности.
- Если производительность модели неудовлетворительна, рассмотрите возможность корректировки модели, получения дополнительных данных или использования другого метода моделирования.
- Интерпретируйте результаты модели и сообщайте о результатах как в визуальном, так и в числовом формате.
Получение данных
Для начала нам потребуется набор данных. В качестве реалистичного примера я получил данные о погоде для Сиэтла, штат Вашингтон, за 2016 год, используя инструмент NOAA Climate Data Online. Как правило, примерно 80% времени, затрачиваемого на анализ данных, приходится на очистку и извлечение данных. Однако эту рабочую нагрузку можно свести к минимуму, выбрав высококачественные источники данных. Инструмент NOAA оказался чрезвычайно удобным для пользователя, позволяя нам загружать данные о температуре в виде чистых файлов CSV, которые можно анализировать с помощью таких языков программирования, как Python или R. Для тех, кто хочет посмотреть, доступен полный файл данных. для скачивания.
Следующий код Python загружает данные csv и отображает структуру данных:
# Pandas is used for data manipulation
import pandas as pd
# Read in data and display first 5 rows
features = pd.read_csv('temps.csv')
features.head(5)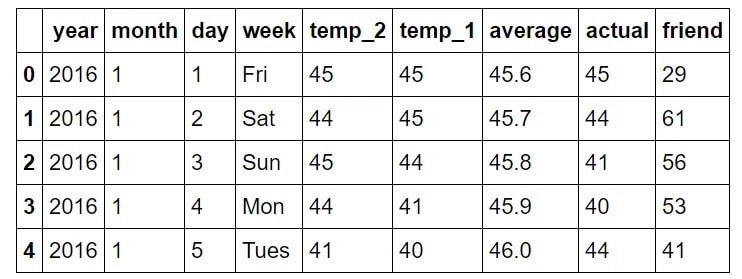
year: год, соответствующий 2016 году для всех точек данных.month: числовое представление месяца в году.day: числовое представление дня в году.week: день недели, выраженный строкой символов.temp_2: Максимальная температура, зарегистрированная двумя днями ранее.temp_1: максимальная температура, зарегистрированная за день до этого.average: историческая средняя максимальная температура.actual: фактическая измеренная максимальная температура.friend: прогноз вашего друга, представляющий собой случайное число, сгенерированное между 20 ниже среднего и 20 выше среднего.
Выявление аномалий/отсутствующих данных
Изучив размеры данных, мы заметили, что в них всего 348 строк, что не совпадает с ожидаемыми 366 днями в 2016 году. При более внимательном рассмотрении данных NOAA я обнаружил, что пропущено несколько дней. Это служит ценным напоминанием о том, что сбор данных в реальном мире никогда не бывает безупречным. Отсутствующие данные, а также неправильные данные или выбросы могут повлиять на анализ. Однако в этом случае ожидается, что влияние недостающих данных будет минимальным, а общее качество данных будет хорошим благодаря надежному источнику.
print('The shape of our features is:', features.shape)
The shape of our features is: (348, 9)Для выявления аномалий мы можем быстро вычислить сводную статистику.
# Descriptive statistics for each column
features.describe()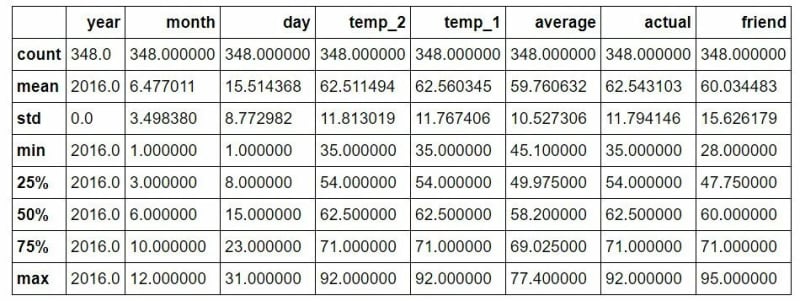
При первоначальном осмотре не обнаруживается никаких точек данных, которые сразу выделяются как аномалии, и нет нулей ни в одном из столбцов измерений. Еще одним эффективным методом оценки качества данных является создание базовых графиков. Графические представления часто облегчают выявление аномалий по сравнению с анализом только числовых значений. Я опустил здесь фактический код для построения графика, поскольку он может быть не интуитивно понятным в Python. Тем не менее, пожалуйста, не стесняйтесь обращаться к блокноту для полной реализации. В качестве хорошей практики я должен признать, что я в основном использовал существующий код построения графиков из Stack Overflow, как это делают многие специалисты по данным.
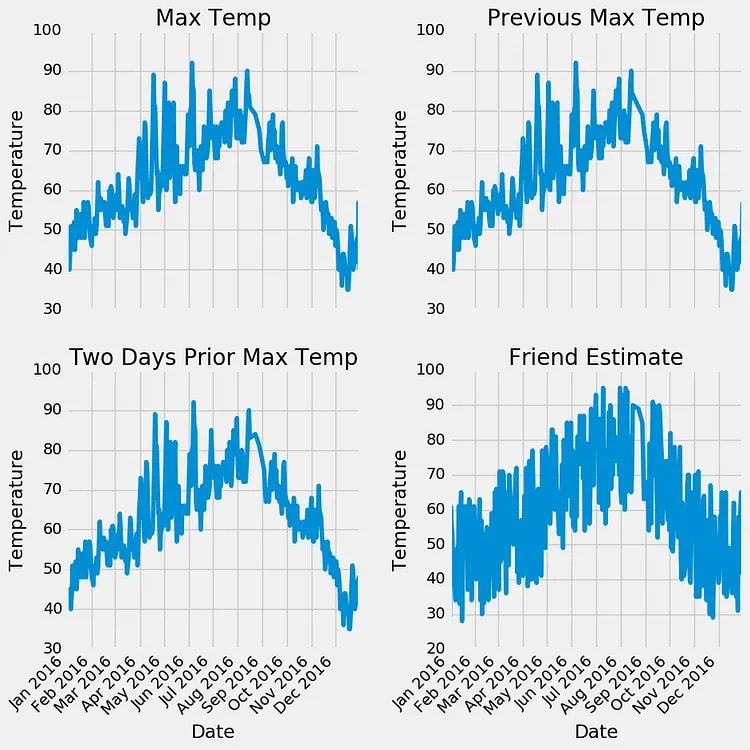
Изучая количественную статистику и графики, мы можем быть уверены в высоком качестве наших данных. Явных выбросов нет, и хотя есть несколько упущенных моментов, они не отвлекают от анализа.
Подготовка данных
Однако мы еще не достигли той стадии, когда мы можем напрямую вводить необработанные данные в модель и ожидать, что она даст точные ответы (хотя исследователи активно работают над этим!). Нам нужно выполнить некоторую предварительную обработку, чтобы сделать наши данные понятными для алгоритмов машинного обучения. Для обработки данных мы будем использовать библиотеку Python Pandas, которая предоставляет удобную структуру данных, известную как фрейм данных, напоминающую электронную таблицу Excel со строками и столбцами.
Конкретные шаги по подготовке данных будут различаться в зависимости от выбранной модели и собранных данных. Однако некоторый уровень манипулирования данными обычно необходим для любого приложения машинного обучения.
Один важный шаг в нашем случае известен как унитарное кодирование. Этот процесс преобразует категориальные переменные, такие как дни недели, в числовое представление без произвольного порядка. В то время как мы интуитивно понимаем концепцию будних дней, машинам не хватает этого врожденного знания. Компьютеры в первую очередь понимают числа, поэтому очень важно приспособить их для целей машинного обучения. Вместо того, чтобы просто сопоставлять дни недели с числовыми значениями от 1 до 7, что может привести к непреднамеренному смещению из-за числового порядка, мы используем технику, называемую унитарным кодированием. Это преобразует один столбец, представляющий дни недели, в семь двоичных столбцов. Позвольте мне проиллюстрировать это визуально:
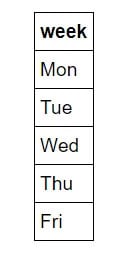
и превращает его в
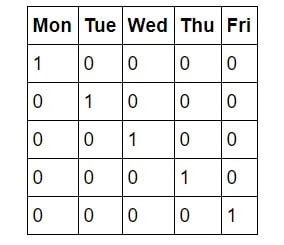
Таким образом, если точкой данных является среда, она будет иметь 1 в столбце среды и 0 во всех остальных столбцах. Этот процесс можно выполнить в Pandas в одну строку!
# One-hot encode the data using pandas get_dummies
features = pd.get_dummies(features)
# Display the first 5 rows of the last 12 columns
features.iloc[:,5:].head(5)Снимок данных после унитарного кодирования:

Размеры наших данных теперь стали 349 x 15, а все столбцы состоят из числовых значений, что идеально подходит для нашего алгоритма!
Далее нам нужно разделить данные на функции и целевые объекты. Целевой параметр, также известный как метка, представляет собой значение, которое мы хотим предсказать, которое в данном случае является фактической максимальной температурой. Признаки охватывают все столбцы, которые модель будет использовать для составления прогнозов. Кроме того, мы преобразуем фреймы данных Pandas в массивы Numpy, поскольку это ожидаемый формат для алгоритма. Чтобы сохранить заголовки столбцов, которые соответствуют названиям объектов, мы сохраним их в списке для возможных целей визуализации позже.
# Use numpy to convert to arrays
import numpy as np
# Labels are the values we want to predict
labels = np.array(features['actual'])
# Remove the labels from the features
# axis 1 refers to the columns
features= features.drop('actual', axis = 1)
# Saving feature names for later use
feature_list = list(features.columns)
# Convert to numpy array
features = np.array(features)Следующий шаг в подготовке данных включает разделение данных на наборы для обучения и тестирования. На этапе обучения мы предоставляем модели ответы (в данном случае фактические температуры), чтобы она могла научиться предсказывать температуры на основе заданных признаков. Мы ожидаем взаимосвязь между признаками и целевым значением, и задача модели состоит в том, чтобы изучить эту взаимосвязь во время обучения. Когда дело доходит до оценки производительности модели, мы просим ее делать прогнозы на отдельном наборе тестов, где у нее есть доступ только к функциям (без ответов). Поскольку у нас есть фактические ответы для тестового набора, мы можем сравнить прогнозы модели с истинными значениями, чтобы оценить ее точность.
Обычно при обучении модели мы случайным образом разбиваем данные на наборы для обучения и тестирования, чтобы обеспечить репрезентативную выборку всех точек данных. Если бы мы обучали модель исключительно на данных за первые девять месяцев года, а затем использовали последние три месяца для прогнозирования, производительность модели была бы неоптимальной, поскольку она не встречала никаких данных за последние три месяца. В этом случае я устанавливаю случайное состояние равным 42, что гарантирует, что результаты разбиения останутся согласованными при нескольких запусках, что позволит воспроизвести результаты.
Следующий код разделяет наборы данных еще одной строкой:
# Using Skicit-learn to split data into training and testing sets
from sklearn.model_selection import train_test_split
# Split the data into training and testing sets
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size = 0.25, random_state = 42)Мы можем посмотреть на форму всех данных, чтобы убедиться, что мы все сделали правильно. Мы ожидаем, что количество столбцов признаков обучения будет соответствовать количеству столбцов признаков тестирования, а количество строк будет соответствовать соответствующим признакам обучения и меткам:
print('Training Features Shape:', train_features.shape)
print('Training Labels Shape:', train_labels.shape)
print('Testing Features Shape:', test_features.shape)
print('Testing Labels Shape:', test_labels.shape)
Training Features Shape: (261, 14)
Training Labels Shape: (261,)
Testing Features Shape: (87, 14)
Testing Labels Shape: (87,)Кажется, все в порядке! Давайте вспомним шаги, которые мы предприняли для подготовки данных для машинного обучения:
- Объявили категориальные переменные используя унитарное кодирование.
- Разделили данные на признаки и метки.
- Преобразовали данные в массивы.
- Разделили данные на наборы для обучения и тестирования. В зависимости от исходного набора данных могут быть задействованы дополнительные задачи, такие как обработка выбросов, подстановка пропущенных значений или преобразование временных переменных в циклические представления. Поначалу эти шаги могут показаться произвольными, но как только вы поймете основной рабочий процесс, вы обнаружите, что он остается в значительной степени одинаковым для различных задач машинного обучения. В конечном счете, цель состоит в том, чтобы преобразовать удобочитаемые данные в формат, понятный модели машинного обучения.
Установка базиса
Прежде чем делать и оценивать прогнозы, важно установить базовый уровень — разумный эталон, который мы стремимся превзойти с помощью нашей модели. Если наша модель не улучшится по сравнению с базовой, это означает, что либо мы должны изучить альтернативные модели, либо признать, что машинное обучение может не подходить для нашей конкретной проблемы. В нашем случае базовый прогноз может быть получен из исторических средних максимальных температур. Проще говоря, наша базовая линия представляет собой ошибку, которую мы допустили бы, если бы предсказывали среднюю максимальную температуру за все дни.
# The baseline predictions are the historical averages
baseline_preds = test_features[:, feature_list.index('average')]
# Baseline errors, and display average baseline error
baseline_errors = abs(baseline_preds - test_labels)
print('Average baseline error: ', round(np.mean(baseline_errors), 2))
Average baseline error: 5.06 degrees.Теперь у нас есть цель! Если мы не можем победить среднюю ошибку в 5 градусов, нам нужно переосмыслить наш подход.
Тренировка модели
После завершения этапов подготовки данных процесс создания и обучения модели с помощью Scikit-learn становится относительно простым. Мы можем добиться этого, импортировав модель регрессии случайного леса из Scikit-learn, инициализировав экземпляр модели и подогнав (термин Scikit-learn для обучения) модели с обучающими данными. Чтобы обеспечить воспроизводимые результаты, мы можем установить случайное состояние. Примечательно, что весь этот процесс можно выполнить всего за три строки кода в Scikit-learn!
# Import the model we are using
from sklearn.ensemble import RandomForestRegressor
# Instantiate model with 1000 decision trees
rf = RandomForestRegressor(n_estimators = 1000, random_state = 42)
# Train the model on training data
rf.fit(train_features, train_labels);Сделаем прогнозы на тестовом наборе
Теперь, когда наша модель обучена изучению взаимосвязей между признаками и целями, следующим шагом является оценка ее производительности. Для этого нам нужно делать прогнозы по тестовым функциям (убедившись, что модель не имеет доступа к тестовым ответам). Впоследствии мы сравниваем эти прогнозы с известными ответами. В задачах регрессии крайне важно использовать метрику абсолютной ошибки, поскольку мы ожидаем диапазон как низких, так и высоких значений в наших прогнозах. Нас в первую очередь интересует количественная оценка средней разницы между нашими прогнозами и фактическими значениями, отсюда и использование абсолютной ошибки (как мы делали при установлении базового уровня).
В Scikit-learn делать прогнозы с помощью нашей модели так же просто, как написать одну строку кода.
# Use the forest's predict method on the test data
predictions = rf.predict(test_features)
# Calculate the absolute errors
errors = abs(predictions - test_labels)
# Print out the mean absolute error (mae)
print('Mean Absolute Error:', round(np.mean(errors), 2), 'degrees.')
Mean Absolute Error: 3.83 degrees.Наша средняя оценка отличается на 3,83 градуса. Это более чем на 1 градус в среднем выше исходного уровня. Хотя это может показаться незначительным, это почти на 25% лучше, чем базовый уровень, который, в зависимости от области и проблемы, может стоить компании миллионы долларов.
Определим показатели производительности
Чтобы представить наши прогнозы в перспективе, мы можем рассчитать точность, используя среднюю среднюю процентную ошибку, вычтенную из 100%.
# Calculate mean absolute percentage error (MAPE)
mape = 100 * (errors / test_labels)
# Calculate and display accuracy
accuracy = 100 - np.mean(mape)
print('Accuracy:', round(accuracy, 2), '%.')
Accuracy: 93.99 %.Это выглядит очень хорошо! Наша модель научилась предсказывать максимальную температуру на следующий день в Сиэтле с точностью 94%.
Улучшите модель, если необходимо
На этом этапе типичного рабочего процесса машинного обучения мы обычно переходим к настройке гиперпараметров. Этот процесс включает настройку параметров модели для повышения ее производительности. Эти настройки известны как гиперпараметры, что отличает их от параметров модели, полученных во время обучения. Наиболее распространенный подход к настройке гиперпараметров включает создание нескольких моделей с разными настройками, оценку их всех на одном и том же наборе проверки и определение того, какая конфигурация обеспечивает наилучшую производительность. Однако выполнение этого процесса вручную было бы трудоемким, поэтому в Scikit-learn доступны автоматизированные методы для упрощения задачи. Важно отметить, что настройка гиперпараметров часто является скорее инженерной практикой, чем теоретической, и я призываю тех, кто заинтересован, изучить документацию и начать экспериментировать. Достижение точности 94% считается удовлетворительным для этой задачи. Тем не менее, стоит отметить, что первоначальная построенная модель вряд ли будет той, которая будет запущена в производство, поскольку улучшение модели — это итеративный процесс.
Интерпретация модели и отчет о результатах
На данный момент мы знаем, что наша модель хороша, но это в значительной степени черный ящик. Мы загружаем несколько массивов Numpy для обучения, просим его сделать прогноз, оцениваем прогнозы и видим, что они разумны. Вопрос в том, как эта модель достигает значений? Есть два подхода к тому, чтобы проникнуть внутрь случайного леса: во-первых, мы можем посмотреть на одно дерево в лесу, а во-вторых, мы можем посмотреть на важность признаков наших независимых переменных.
Визуализация единого дерева решений
Одна из самых крутых частей реализации метода случайного леса в Skicit-learn заключается в том, что мы можем исследовать любое дерево в лесу. Мы выберем одно дерево и сохраним все дерево как изображение
Следующий код берет одно дерево из леса и сохраняет его как изображение.
# Import tools needed for visualization
from sklearn.tree import export_graphviz
import pydot
# Pull out one tree from the forest
tree = rf.estimators_[5]
# Import tools needed for visualization
from sklearn.tree import export_graphviz
import pydot
# Pull out one tree from the forest
tree = rf.estimators_[5]
# Export the image to a dot file
export_graphviz(tree, out_file = 'tree.dot', feature_names = feature_list, rounded = True, precision = 1)
# Use dot file to create a graph
(graph, ) = pydot.graph_from_dot_file('tree.dot')
# Write graph to a png file
graph.write_png('tree.png')Давайте взглянем:
Ух ты! Это похоже на довольно обширное дерево с 15 слоями (на самом деле это довольно маленькое дерево по сравнению с некоторыми, которые я видел). Вы можете скачать это изображение самостоятельно и изучить его более подробно, но для упрощения я ограничу глубину деревьев в лесу, чтобы получить понятное изображение.
# Limit depth of tree to 3 levels
rf_small = RandomForestRegressor(n_estimators=10, max_depth = 3)
rf_small.fit(train_features, train_labels)
# Extract the small tree
tree_small = rf_small.estimators_[5]
# Save the tree as a png image
export_graphviz(tree_small, out_file = 'small_tree.dot', feature_names = feature_list, rounded = True, precision = 1)
(graph, ) = pydot.graph_from_dot_file('small_tree.dot')
graph.write_png('small_tree.png');Вот дерево уменьшенного размера, аннотированное метками
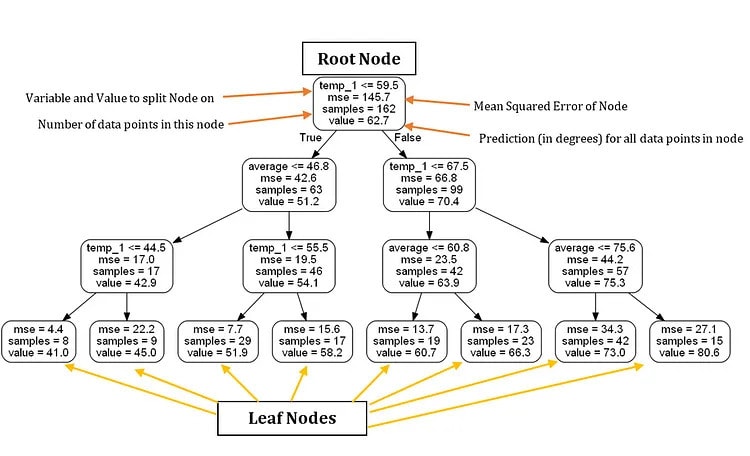
Основываясь исключительно на этом дереве решений, мы можем делать прогнозы для новых точек данных. Рассмотрим пример прогнозирования максимальной температуры на среду, 27 декабря 2017 г., со следующими значениями: temp_2 = 39, temp_1 = 35, average = 44 и friend = 30.
Начиная с корневого узла, мы сталкиваемся с первым вопросом, ответ на который равен True, поскольку temp_1 ≤ 59,5. Двигаемся налево и сталкиваемся со вторым вопросом, который также является верным, поскольку среднее значение ≤ 46,8. Продолжая движение влево, мы подходим к третьему и последнему вопросу, который снова является верным, поскольку temp_1 ≤ 44,5. В результате делаем вывод, что наша оценка максимальной температуры составляет 41,0 градус, на что указывает значение в листовом узле.
Интересным наблюдением является то, что корневой узел содержит только 162 выборки, несмотря на то, что имеется 261 точка обучающих данных. Это связано с тем, что каждое дерево в случайном лесу обучается на случайном подмножестве точек данных с заменой, метод, известный как бэггинг (bootstrap aggregating). Если мы хотим использовать все точки данных без выборки с заменой, мы можем отключить ее, установив bootstrap = False при построении леса. Благодаря сочетанию случайной выборки точек данных и подмножества признаков в каждом узле модель называется «случайным» лесом.
Кроме того, стоит отметить, что в нашем дереве решений мы использовали только две переменные для прогнозирования. Согласно этому конкретному дереву, остальные признаки, такие как месяц года, день месяца и предсказание нашего друга, считаются несущественными для предсказания завтрашней максимальной температуры. Визуальное представление нашего дерева расширило наше понимание проблемной области, позволив нам понять, какие данные следует учитывать при прогнозировании.
Значимость переменных
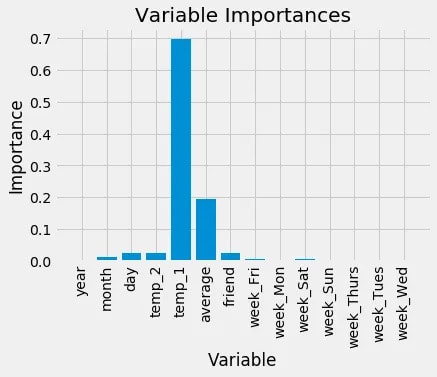
Чтобы оценить значимость всех переменных в случайном лесу, мы можем изучить их относительную важность. Важность, полученная из Scikit-learn, показывает, насколько включение конкретной переменной улучшает прогноз. Хотя точный расчет важности выходит за рамки этой статьи, мы можем использовать эти значения для относительных сравнений между переменными.
Предоставленный код использует несколько полезных методов языка Python, включая понимание списков, архивирование, сортировку и распаковку аргументов. Хотя понимание этих методов не имеет решающего значения на данный момент, они являются ценными инструментами, которые нужно иметь в своем арсенале Python, если вы стремитесь улучшить свое владение языком.
# Get numerical feature importances
importances = list(rf.feature_importances_)
# List of tuples with variable and importance
feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list, importances)]
# Sort the feature importances by most important first
feature_importances = sorted(feature_importances, key = lambda x: x[1], reverse = True)
# Print out the feature and importances
[print('Variable: {:20} Importance: {}'.format(*pair)) for pair in feature_importances];
Variable: temp_1 Importance: 0.7
Variable: average Importance: 0.19
Variable: day Importance: 0.03
Variable: temp_2 Importance: 0.02
Variable: friend Importance: 0.02
Variable: month Importance: 0.01
Variable: year Importance: 0.0
Variable: week_Fri Importance: 0.0
Variable: week_Mon Importance: 0.0
Variable: week_Sat Importance: 0.0
Variable: week_Sun Importance: 0.0
Variable: week_Thurs Importance: 0.0
Variable: week_Tues Importance: 0.0
Variable: week_Wed Importance: 0.0В верхней части списка важности находится "temp_1", максимальная температура за день до этого. Это открытие подтверждает, что лучшим предсказателем максимальной температуры для данного дня является максимальная температура, зарегистрированная в предыдущий день, что согласуется с нашей интуицией. Вторым наиболее влиятельным фактором является историческая средняя максимальная температура, что также является логичным результатом. Удивительно, но предсказание вашего друга вместе с такими переменными, как день недели, год, месяц и температура за два дня до этого, оказалось бесполезным для предсказания максимальной температуры. Эти значения имеют смысл, поскольку мы не ожидаем, что день недели будет иметь какое-либо влияние на погоду. Кроме того, год остается одинаковым для всех точек данных, что делает его бесполезным для прогнозирования максимальной температуры.
В будущих реализациях модели мы можем исключить эти переменные с незначительной важностью, и производительность не пострадает. Более того, если бы мы использовали другую модель, такую как машина опорных векторов, мы могли бы использовать важность признаков случайного леса как форму выбора признаков. Чтобы продемонстрировать это, мы можем быстро построить случайный лес, используя только две наиболее важные переменные — максимальную температуру за день до этого и историческое среднее значение — и сравнить его производительность с исходной моделью.
# New random forest with only the two most important variables
rf_most_important = RandomForestRegressor(n_estimators= 1000, random_state=42)
# Extract the two most important features
important_indices = [feature_list.index('temp_1'), feature_list.index('average')]
train_important = train_features[:, important_indices]
test_important = test_features[:, important_indices]
# Train the random forest
rf_most_important.fit(train_important, train_labels)
# Make predictions and determine the error
predictions = rf_most_important.predict(test_important)
errors = abs(predictions - test_labels)
# Display the performance metrics
print('Mean Absolute Error:', round(np.mean(errors), 2), 'degrees.')
mape = np.mean(100 * (errors / test_labels))
accuracy = 100 - mape
print('Accuracy:', round(accuracy, 2), '%.')
Mean Absolute Error: 3.9 degrees.
Accuracy: 93.8 %.Это понимание подчеркивает, что нам не обязательно нужны все собранные данные, чтобы делать точные прогнозы. На самом деле, если бы мы продолжали использовать эту модель, мы могли бы сузить сбор данных только до двух наиболее значимых переменных и достичь почти того же уровня производительности. Однако в производственных условиях нам нужно было бы рассмотреть компромисс между снижением точности и дополнительным временем и ресурсами, необходимыми для сбора дополнительной информации. Нахождение правильного баланса между производительностью и стоимостью является жизненно важным навыком для инженера по машинному обучению и в конечном итоге будет зависеть от конкретной проблемы.
На этом этапе мы рассмотрели основы реализации модели случайного леса для задачи регрессии. Мы можем быть уверены, что наша модель может предсказать максимальную температуру на завтра с точностью 94%, используя исторические данные за один год. Отсюда вы можете свободно экспериментировать с этим примером или применять модель к набору данных по вашему выбору. В заключение я углублюсь в несколько визуализаций. Как специалист по данным, я получаю огромное удовольствие от создания графиков и моделей, а визуализация не только доставляет эстетическое удовольствие, но и помогает нам диагностировать нашу модель, объединяя огромное количество числовой информации в легко понятные изображения.
Визуализации
Чтобы визуализировать расхождения в относительной важности переменных, я создам простую гистограмму важности признаков. Построение графиков в Python может быть немного неинтуитивным, и я часто ищу решения на Stack Overflow при создании графиков. Не волнуйтесь, если предоставленный код не имеет смысла — иногда понимание каждой строки кода не обязательно для достижения желаемого результата!
# Import matplotlib for plotting and use magic command for Jupyter Notebooks
import matplotlib.pyplot as plt
%matplotlib inline
# Set the style
plt.style.use('fivethirtyeight')
# list of x locations for plotting
x_values = list(range(len(importances)))
# Make a bar chart
plt.bar(x_values, importances, orientation = 'vertical')
# Tick labels for x axis
plt.xticks(x_values, feature_list, rotation='vertical')
# Axis labels and title
plt.ylabel('Importance'); plt.xlabel('Variable'); plt.title('Variable Importances');
Затем мы можем построить весь набор данных с выделенными прогнозами. Это требует небольшой обработки данных, но это не слишком сложно. Мы можем использовать этот график, чтобы определить, есть ли какие-либо выбросы в данных или в наших прогнозах.
# Use datetime for creating date objects for plotting
import datetime
# Dates of training values
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]
# List and then convert to datetime object
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# Dataframe with true values and dates
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})
# Dates of predictions
months = test_features[:, feature_list.index('month')]
days = test_features[:, feature_list.index('day')]
years = test_features[:, feature_list.index('year')]
# Column of dates
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
# Convert to datetime objects
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
# Dataframe with predictions and dates
predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predictions})
# Plot the actual values
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# Plot the predicted values
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = '60');
plt.legend()
# Graph labels
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values');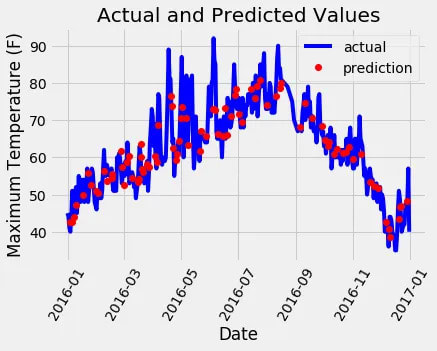
Создание визуально привлекательного графика требует некоторых усилий, но конечный результат того стоит! Судя по данным, у нас нет каких-либо заметных выбросов, которые необходимо устранить. Чтобы получить более полное представление о производительности модели, мы можем нанести на график остатки (т. е. ошибки), чтобы определить, имеет ли модель тенденцию к завышению или занижению прогноза. Кроме того, изучение распределения остатков может помочь оценить, соответствуют ли они нормальному распределению. Однако для целей этой последней диаграммы я сосредоточусь на визуализации фактических значений, температуры за день до этого, исторического среднего значения и прогноза нашего друга. Эта визуализация поможет нам увидеть разницу между полезными переменными и теми, которые предоставляют менее ценную информацию.
# Make the data accessible for plotting
true_data['temp_1'] = features[:, feature_list.index('temp_1')]
true_data['average'] = features[:, feature_list.index('average')]
true_data['friend'] = features[:, feature_list.index('friend')]
# Plot all the data as lines
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual', alpha = 1.0)
plt.plot(true_data['date'], true_data['temp_1'], 'y-', label = 'temp_1', alpha = 1.0)
plt.plot(true_data['date'], true_data['average'], 'k-', label = 'average', alpha = 0.8)
plt.plot(true_data['date'], true_data['friend'], 'r-', label = 'friend', alpha = 0.3)
# Formatting plot
plt.legend(); plt.xticks(rotation = '60');
# Lables and title
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual Max Temp and Variables');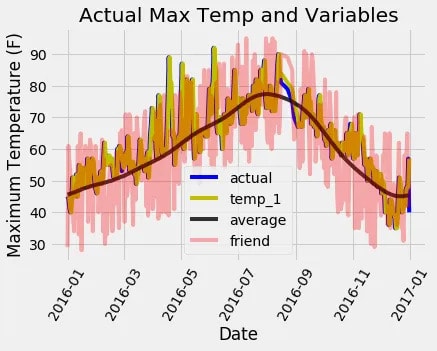
Линии на диаграмме могут показаться немного скученными, но мы все же можем наблюдать, почему максимальная температура за день до этого и средняя максимальная температура за прошлые периоды важны для прогнозирования максимальной температуры. И наоборот, очевидно, что предсказание нашего друга не обеспечивает значительной предсказательной силы (но давайте не будем полностью игнорировать вклад нашего друга, хотя мы должны проявлять осторожность, сильно полагаясь на его оценку). Создание подобных графиков заранее может помочь нам выбрать подходящие переменные для включения в нашу модель, а также они служат ценными диагностическими инструментами. Как и в случае с квартетом Энскомба, графики часто раскрывают идеи, которые могут быть упущены из виду только количественными цифрами. Настоятельно рекомендуется включать визуализации в любой рабочий процесс машинного обучения.
Выводы
С включением этих графиков мы успешно завершили пример сквозного машинного обучения! Чтобы еще больше улучшить нашу модель, мы можем изучить различные гиперпараметры, поэкспериментировать с альтернативными алгоритмами или, что наиболее эффективно, собрать больше данных. Производительность любой модели напрямую зависит от количества и качества данных, из которых она извлекает уроки, и наши обучающие данные были относительно ограничены. Я призываю всех продолжать совершенствовать эту модель и делиться своими выводами. Кроме того, для тех, кто заинтересован в более глубоком изучении теории и практического применения случайных лесов, есть множество бесплатных онлайн-ресурсов. Если вы ищете исчерпывающую книгу, которая охватывает как теорию, так и реализацию моделей машинного обучения на Python, я настоятельно рекомендую «Практическое машинное обучение с помощью Scikit-Learn и TensorFlow». Наконец, я надеюсь, что те, кто последовал этому примеру, осознали доступность машинного обучения и мотивированы присоединиться к инклюзивному и поддерживающему сообществу машинного обучения.