Подсказки типов и строки документации Python
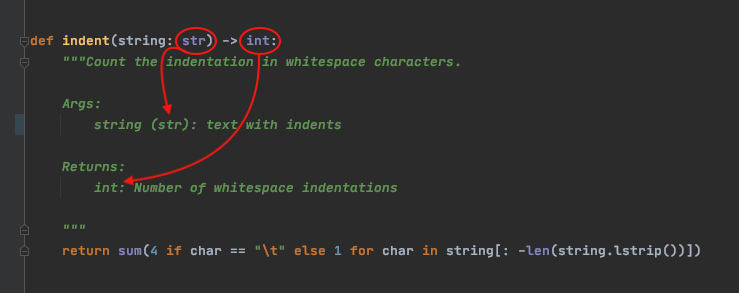
В этой статье вы будете сопровождать меня в путешествии по автоматической генерации строк документации в стиле Google из подсказок типов Python. Мы рассмотрим следующие элементы.
- Подсказки типов Python
- Вставка подсказки типа в строки документации функции
- Автоматизация с помощью хуков Git перед фиксацией
Виртуальные среды для абсолютных новичков - что это такое и как создать (+ примеры)

Если вы работаете над множеством разных проектов, вы узнаете ад зависимости множества проектов, требующих нескольких версий, нескольких пакетов. Вы не можете просто установить все пакеты глобально, как вы отслеживаете? Также что происходит, когда projectA требуется PackageX_version1, а ProjectB - PackageX_version2? Как оставаться в здравом уме, когда все представляет собой один большой беспорядок взаимозависимости, похожий на спагетти?
{kind=link}
В этой статье я попытаюсь убедить, что использование venv (виртуальной среды) - это способ отделить зависимости от других проектов. Мы начнем с определения, что такое venv, для чего он нужен и зачем он вам нужен. Затем мы создадим его и увидим все его преимущества. В конце у нас будет несколько основных правил, позволяющих сохранять зависимости в наших проектах как можно более чистыми.
Создайте свой MEAN-проект с помощью автоматического управления Express.js

Привет, некоторые из вас, возможно, уже знают, что мы ранее создали шаблон стека MERN, который поможет вам пропустить Express.js.
Что касается некоторых ваших запросов, мы хотели бы предложить вам новый шаблон с открытым исходным кодом. И на этот раз для стека MEAN 😉
Как включить мощный полнотекстовый поиск для ваших приложений - MySQL против Elasticsearch

Вы когда-нибудь ходили в супермаркет или универмаг, но не могли найти то, что искали? Вы можете испытать то же самое, когда дело доходит до покупок в Интернете. Хотя большинство веб-сайтов упорядочивают продукты по категориям, просмотр категорий по-прежнему является утомительной работой, если вы не имеете представления о категории ваших целевых продуктов. Панель поиска экономит нам много времени, поскольку мы можем просто ввести ключевые слова или текстовые фразы, и тогда она покажет нам все соответствующие элементы. Без сомнения, полнотекстовый поиск - важная функция для всех веб-сайтов электронной коммерции.
Полнотекстовый поиск - популярная функция, поддерживаемая многими базами данных, такими как MySQL и Elasticsearch. Однако в чем разница между MySQL и Elasticsearch в отношении возможности полнотекстового поиска? Вы не можете принять правильное решение, не понимая различий, если ищете решение для реализации полнотекстового поиска. В этой статье я покажу вам использование полнотекстового поиска в MySQL и Elasticsearch и выделю различия.
Увеличьте «мощность» обработки Golang с помощью контролируемого рабочего пула

Это будет краткое описание, если вы не использовали возможности go-рутины, чтобы сделать процесс вашего приложения «быстрее». В этом примере мы сделаем простую симуляцию выполнения функции, которая имитирует «медленный процесс», выполнение которого занимает 1 секунду, и мы собираемся вызвать эту функцию несколько раз с другим параметром (для имитации другого ввода / обработки).
Операторы switch в Python 3.10

Python 3.10 все еще находится на стадии альфа-тестирования, но в нем появятся некоторые новые интересные функции. В этой статье мы рассмотрим один из них - операторы switch, официально известные как сопоставление структурных шаблонов.
Оператор switch обычно встречается в большинстве языков программирования и обеспечивают более аккуратный способ реализации условной логики. Он пригодятся, когда нужно оценить множество условий.
Сегодня мы увидим, как его использовать, и сравним различия кода с более традиционным подходом.
🚀 API для получения информации о приложениях в PlayStore

Недавно мне было интересно, есть ли способ очистить данные из элементов HTML DOM с помощью node и всех других собственных функций javascript, таких как getElementByClassName, innerText и так далее. После большого количества поисков я наткнулся на JSDOM.
Затем я начал его использовать и нашел это впечатляющим. Поэтому я написал скрипт для извлечения деталей приложения для Android из Google Play Store в режиме реального времени и получения необходимой информации в хорошо отформатированном виде.
Коварный SQL: запуск одного и того же запроса к таблицам с разными столбцами

Мы проводим время изо дня в день, отвечая на важные вопросы и придумывая наиболее разумные решения. Однако иногда возникает вопрос, который настолько чертовски… интересен, что даже если есть разумные решения или обходные пути, все равно кажется сложной задачей просто воспринимать запрос буквально.
Как протестировать несколько конвейеров машинного обучения с помощью всего нескольких строк Python

На этапе исследования проекта специалист по обработке данных пытается найти оптимальный конвейер для своего конкретного случая использования. Поскольку заранее узнать, какие преобразования принесут наибольшую пользу модели, практически невозможно, этот процесс обычно включает опробование различных подходов. Например, если мы имеем дело с несбалансированным набором данных, должны ли мы производить избыточную выборку для класса меньшинства или занижать выборку для класса большинства? В этой истории я объясню, как использовать пакет ATOM, чтобы быстро помочь вам оценить производительность модели, обученной на разных конвейерах. ATOM - это пакет Python с открытым исходным кодом, разработанный, чтобы помочь специалистам по обработке данных ускорить исследование конвейеров машинного обучения.
Задача сверхвысокого разрешения для одного изображения

Цель этой мини-задачи - увеличить разрешение отдельного изображения (в четыре раза). Данные для этой задачи взяты из набора данных DIV2K [1]. Для этой задачи мы подготовили мини-набор данных, который состоит из 500 обучающих и 80 проверочных пар изображений, где изображения HR имеют разрешение 2K, а изображения LR субдискретизированы в четыре раза.
Присоединяйся в тусовку
Поделитесь своим опытом, расскажите о новом инструменте, библиотеке или фреймворке. Для этого не обязательно становится постоянным автором.