5 мощных библиотек Python для EDA

Очень важно обеспечить хорошее качество данных перед запуском моделей машинного обучения. Если мы введем некачественные данные в эти модели, это может привести к неожиданным или непреднамеренным последствиям. Однако проведение подготовительной работы с данными и попытка понять, что у вас есть, а чего нет, отнимают очень много времени. Часто этот процесс может занимать до 90% времени, доступного для проектов.
Если вы выполняете исследовательский анализ данных (EDA) в Python, вам будут известны такие распространенные библиотеки, как pandas, matplotlib и seaborn. Все это отличные библиотеки, но у каждой есть свои нюансы, на изучение или запоминание которых может потребоваться время.
В последние годы появилось несколько мощных библиотек python с низким уровнем кода, которые значительно ускоряют и упрощают этап исследования данных и анализа проектов.
В этой статье мы познакомим вас с 5 из этих библиотек python, которые улучшат ваш рабочий процесс анализа данных. Все это может быть запущено в среде Jupyter notebook.
1. YData Profiling (Ранее Pandas Profiling)
Библиотека YData Profiling, ранее известная как Pandas Profiling, позволяет создавать подробные отчеты на основе фрейма данных pandas. Он очень прост в навигации и предоставляет информацию об отдельных переменных, анализе отсутствующих данных, корреляции данных и взаимодействиях.
Одна небольшая проблема с YData Profiling заключается в возможности обработки больших наборов данных, что может замедлить создание отчетов.
Как использовать библиотеку YData Profiling
YData Profiling можно установить через терминал с помощью pip:
pip install ydata-profilingПосле того, как библиотека будет установлена в вашей среде Python, мы можем просто импортировать модуль ProfileReport из библиотеки вместе с pandas. Pandas используется для загрузки наших данных из файла CSV или другого формата.
import pandas as pd
from ydata_profiling import ProfileReport
df = pd.read_csv('Data/Xeek_Well_15-9-15.csv')
ProfileReport(df)Как только данные будут прочитаны, мы можем передать наш фрейм данных в ProfileReport, и отчет начнет генерироваться.
Время, необходимое для создания отчета, будет зависеть от размера вашего набора данных. Чем больше набор данных, тем больше времени потребуется для его создания.
После создания отчета вы можете начать прокручивать отчет, как показано ниже.
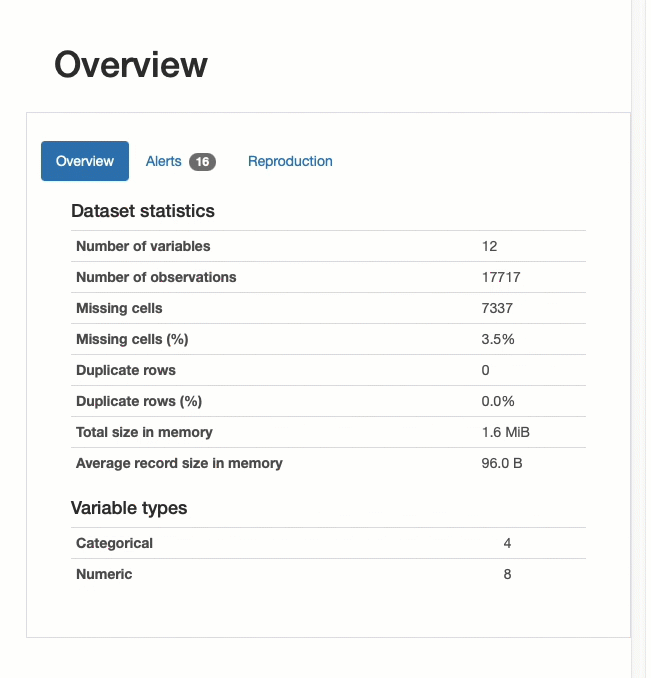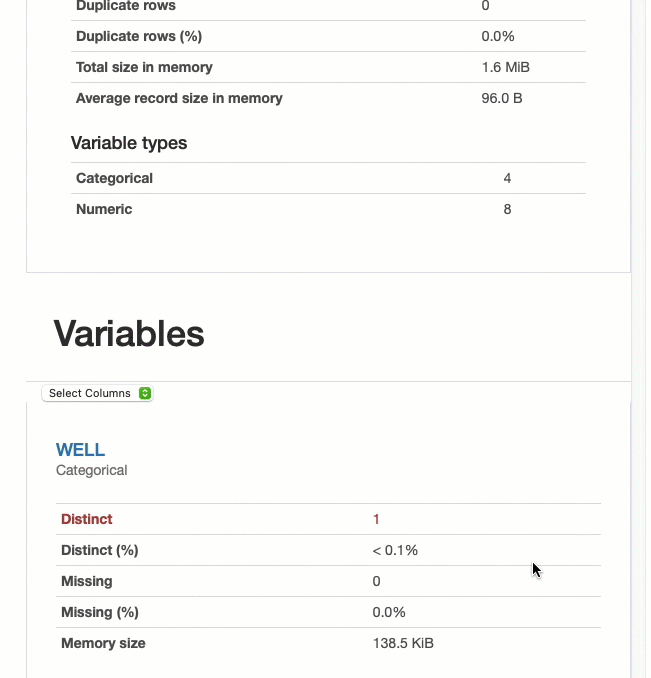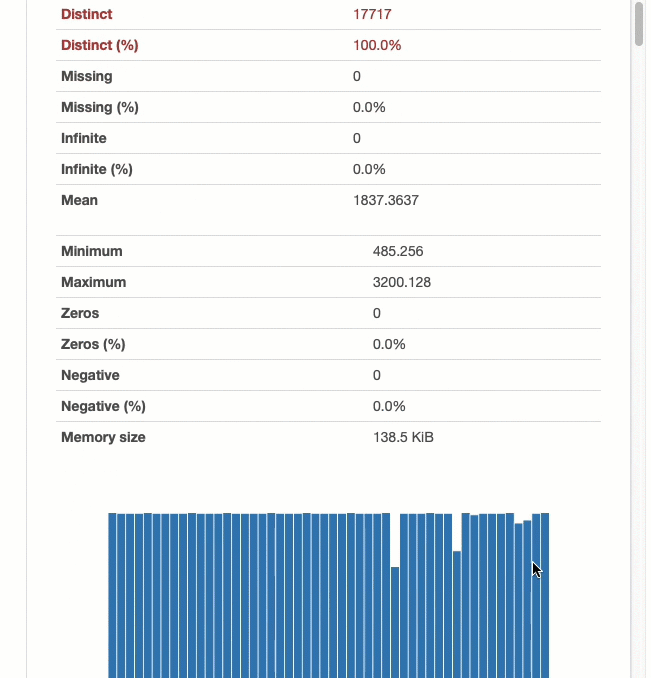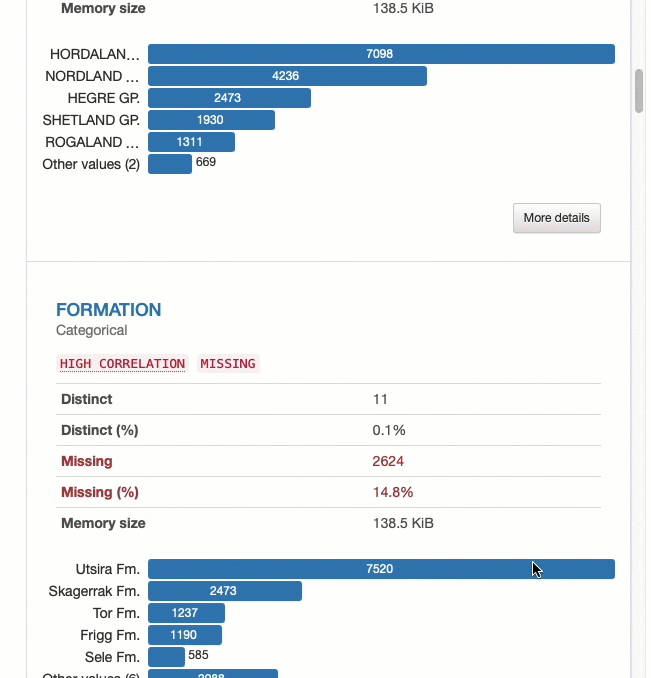
Мы можем изучить каждую переменную в наборе данных и просмотреть информацию о полноте данных, статистике и типах данных.

Мы также можем создавать визуализации полноты данных. Это позволяет нам понять, какие данные отсутствуют и как отсутствие связано между различными переменными.
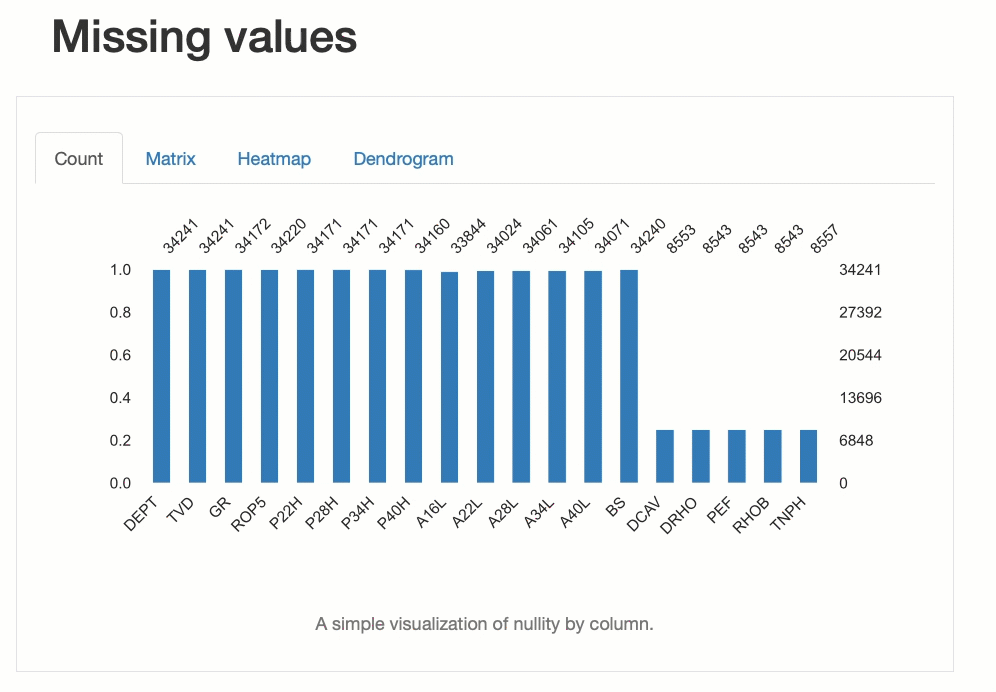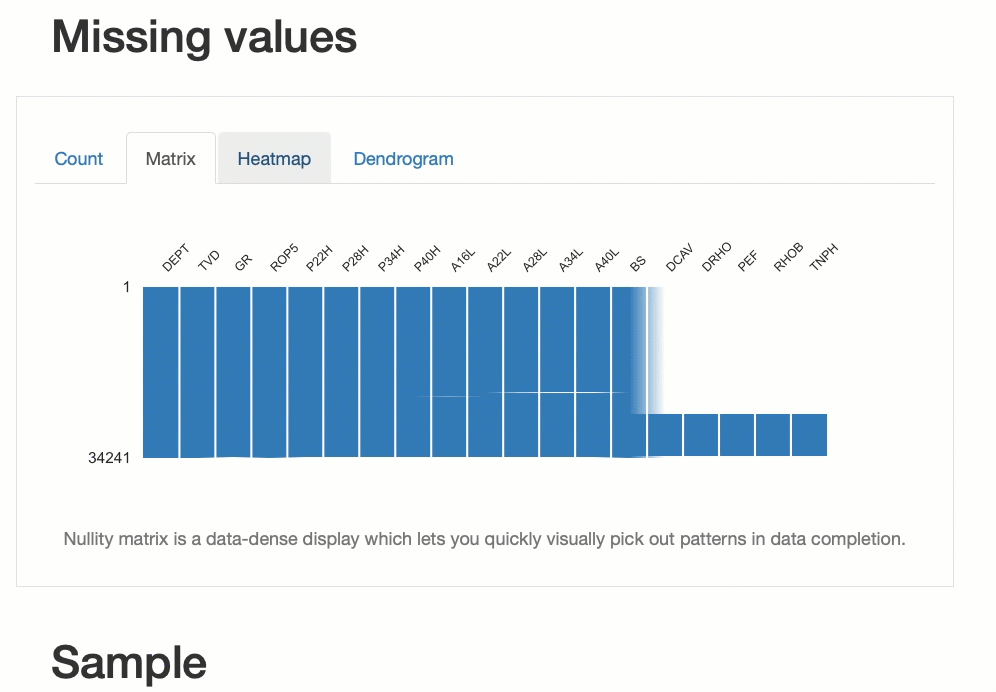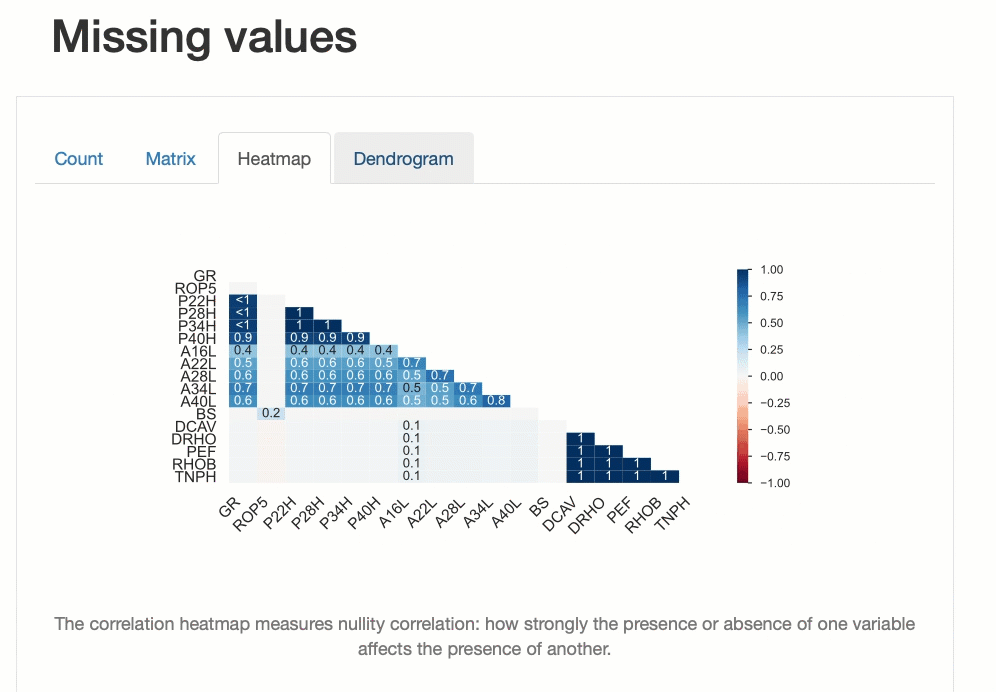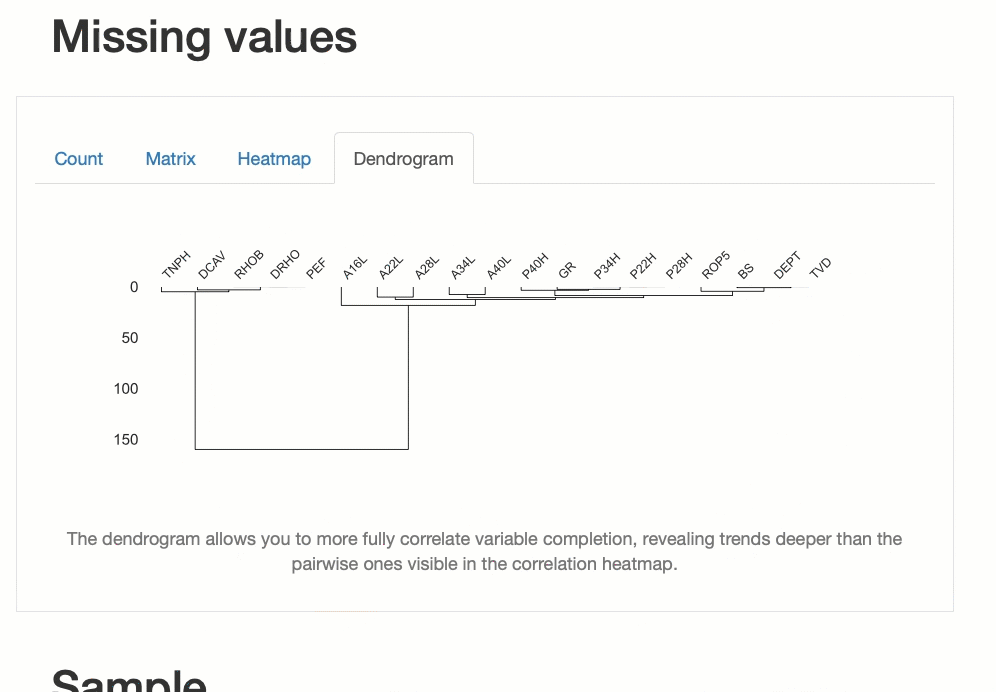
2. D-Tale
D-Tale выводит ваш фрейм данных Pandas на совершенно новый уровень. Эта мощная и быстрая библиотека позволяет очень легко взаимодействовать с вашими данными, выполнять базовый анализ и даже редактировать их.
Если вы хотите попробовать библиотеку перед ее загрузкой, авторы библиотеки предоставили живой пример.
Как использовать D-Tale
D-Tale можно установить через терминал с помощью pip:
pip install dtaleЗатем его можно импортировать вместе с pandas, как показано ниже. Как только данные будут прочитаны pandas, результирующий кадр данных может быть передан в dtale.show().
import pandas as pd
import dtale
df = pd.read_csv('Data/Xeek_Well_15-9-15.csv')
dtale.show(df)После небольшого ожидания появится интерактивная таблица D-Tale со всеми данными, содержащимися во фрейме данных.
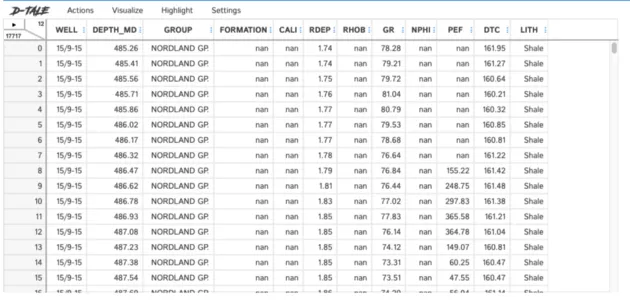
D-Tale поставляется с большим количеством функций, которые позволяют вам запрашивать данные, визуализировать их полноту, редактировать данные и многое другое.
Когда мы изучаем отдельные переменные, такие как столбец DTC в этом наборе данных, мы можем визуализировать его распределение с помощью гистограмм:
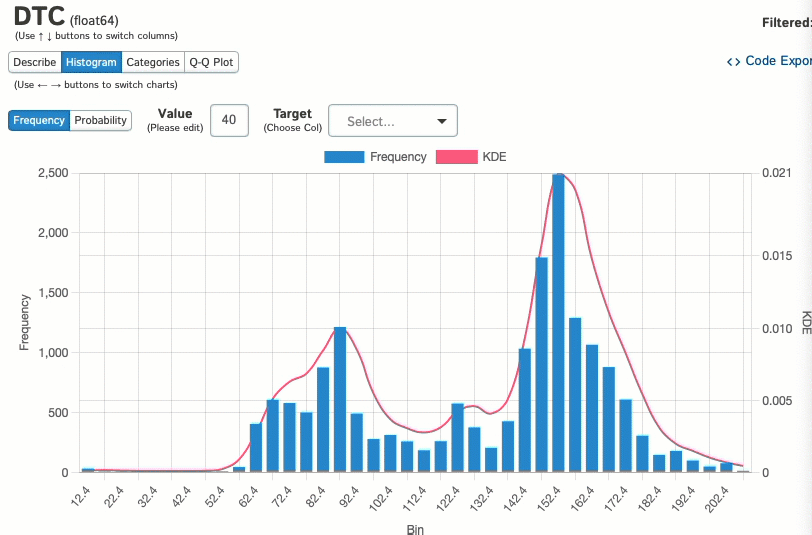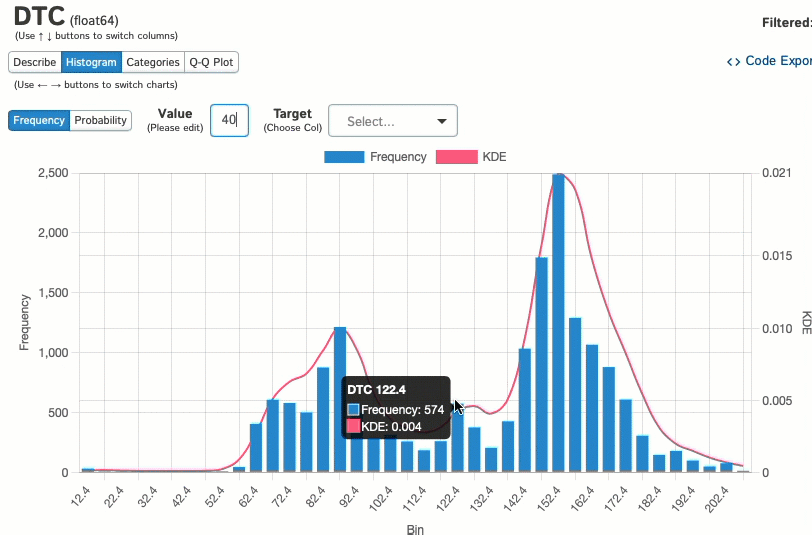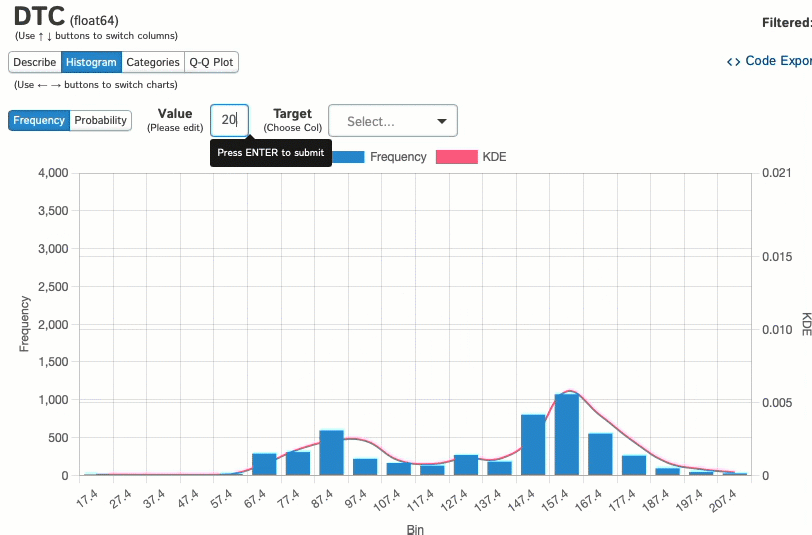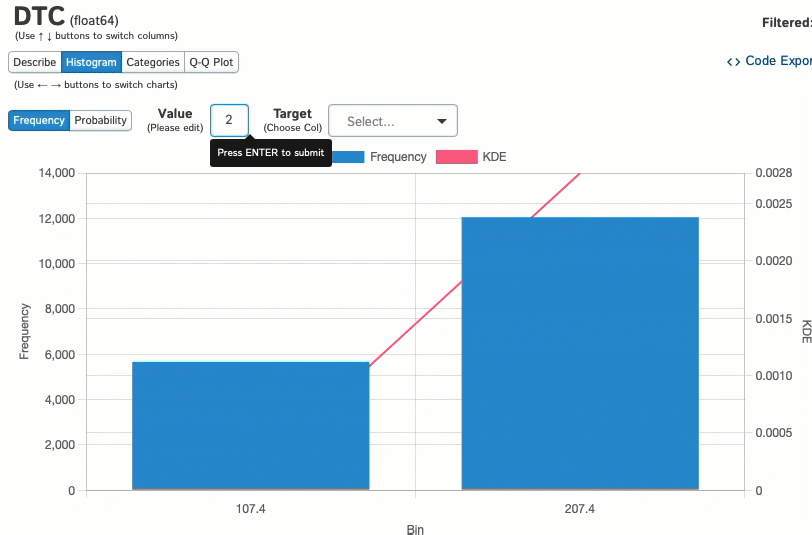
И посмотреть, как эти данные распределяются между категориальной переменной:
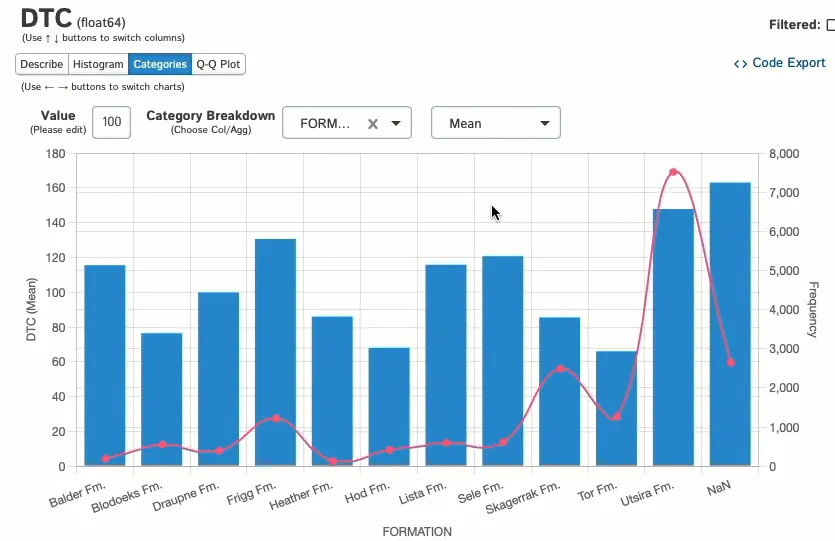
3. SweetViz
SweetViz — еще одна интерактивная библиотека визуализации и исследования данных с низким кодом. Из пары строк кода мы можем создать интерактивный HTML-файл для изучения наших данных.
Как использовать SweetViz
Sweetviz можно установить через терминал с помощью pip:
pip install sweetvizПосле того, как он будет установлен, мы можем импортировать его в нашу записную книжку и загрузить наши данные с помощью pandas.
import sweetviz as sv
import pandas as pd
df = pd.read_csv('Data/Xeek_Well_15-9-15.csv')Затем нам нужно вызвать еще две строки кода, чтобы иметь возможность получить наш отчет:
report = sv.analyze(df)
report.show_html()Затем откроется новая вкладка браузера со следующей настройкой.
После открытия вкладки браузера вы можете просмотреть каждую из переменных во фрейме данных и просмотреть ключевую статистику и полноту каждой переменной. Когда вы нажимаете на любую из переменных, она открывает гистограммы распределения данных, если это числовые данные, или количество значений, если это категориальные данные.
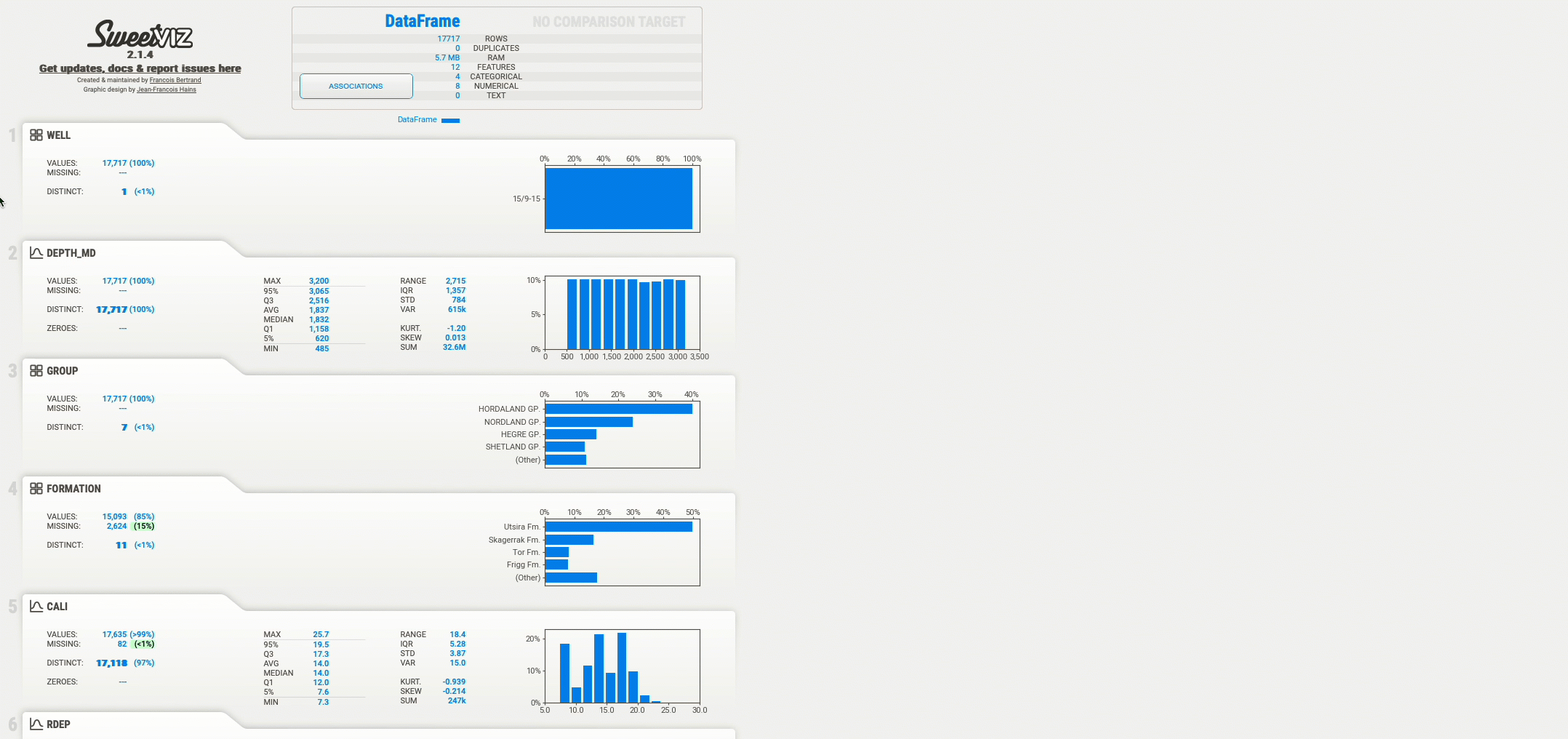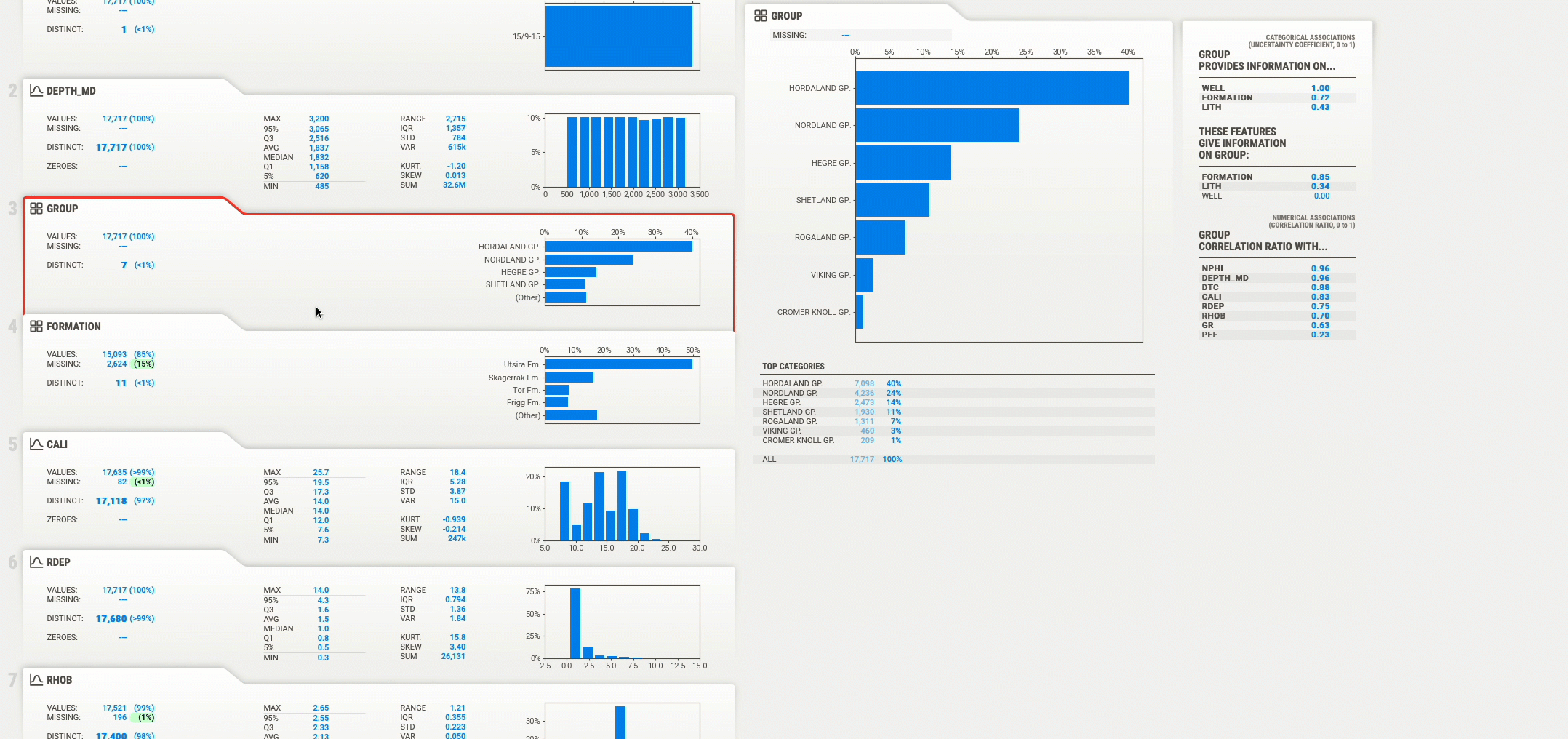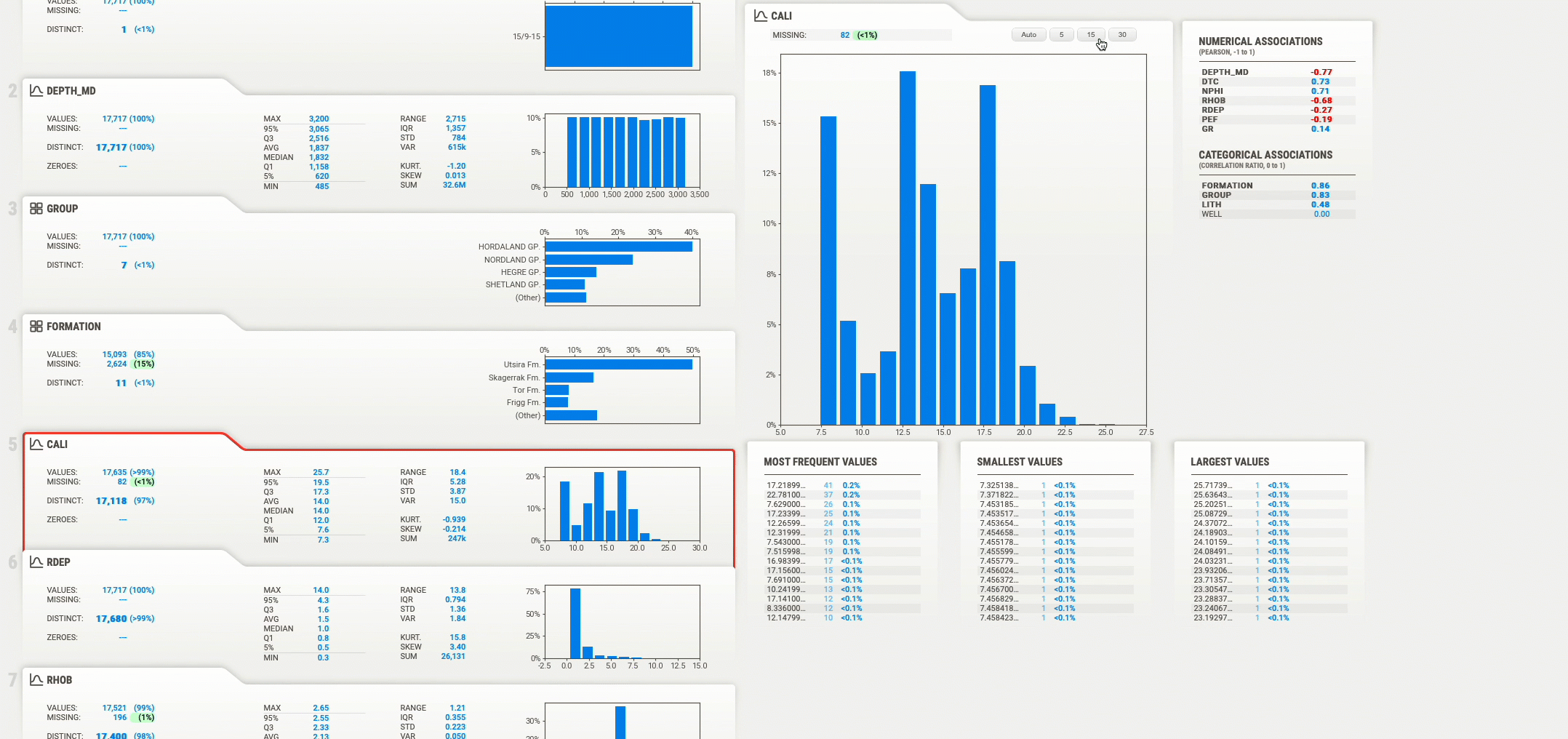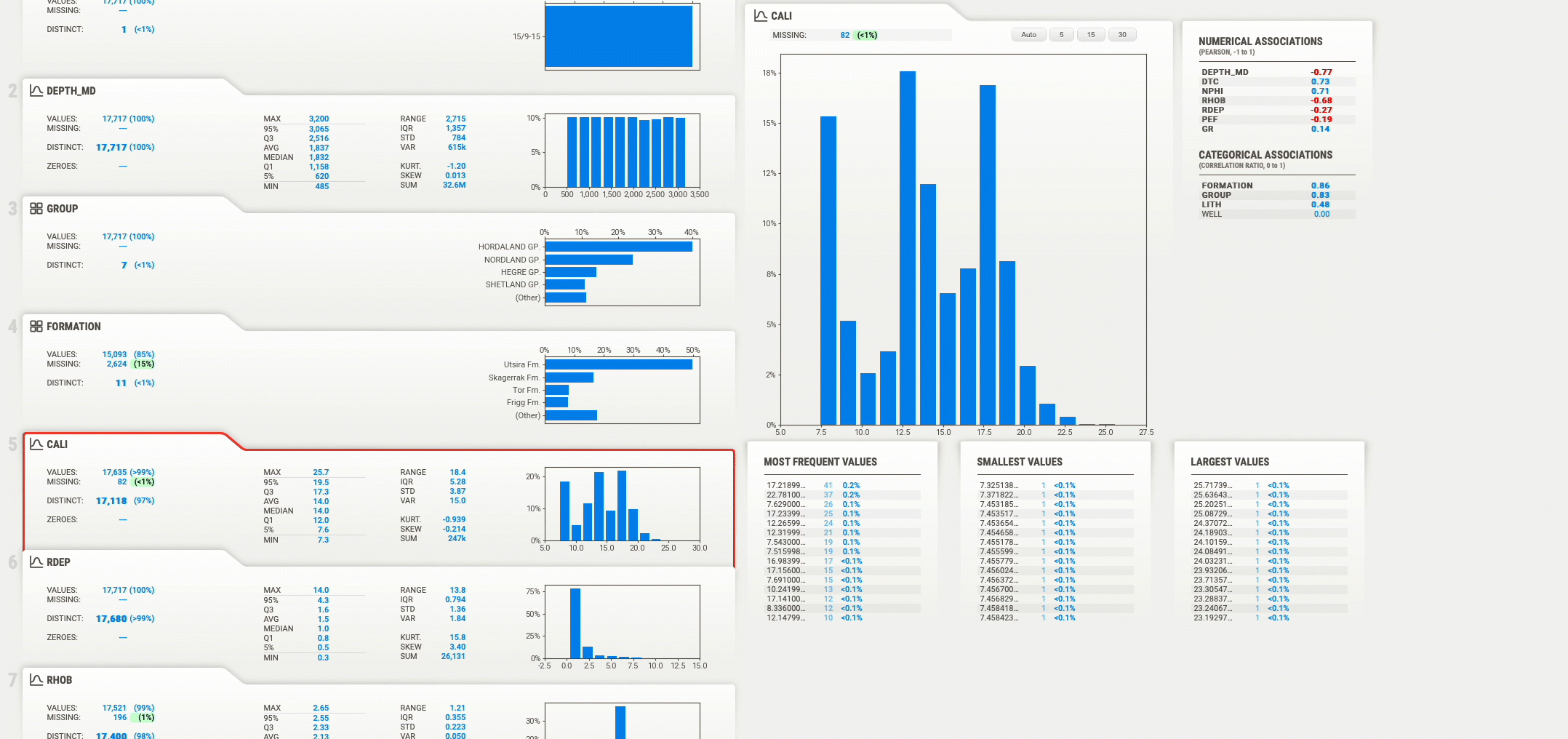
Кроме того, он покажет числовое отношение этой переменной к другим переменным в наборе данных.
Если вы хотите увидеть это визуально, вы можете нажать кнопку «Associations» в верхней части панели инструментов, чтобы открыть графический график корреляции. На изображении ниже мы видим смесь квадратов и кружков, которые представляют категориальные переменные и числовые переменные соответственно.
Размер квадрата/круга представляет силу связи, а цвет представляет значение коэффициента корреляции Пирсона. Это должно быть одна из лучших визуализаций взаимосвязей между переменными в Python.
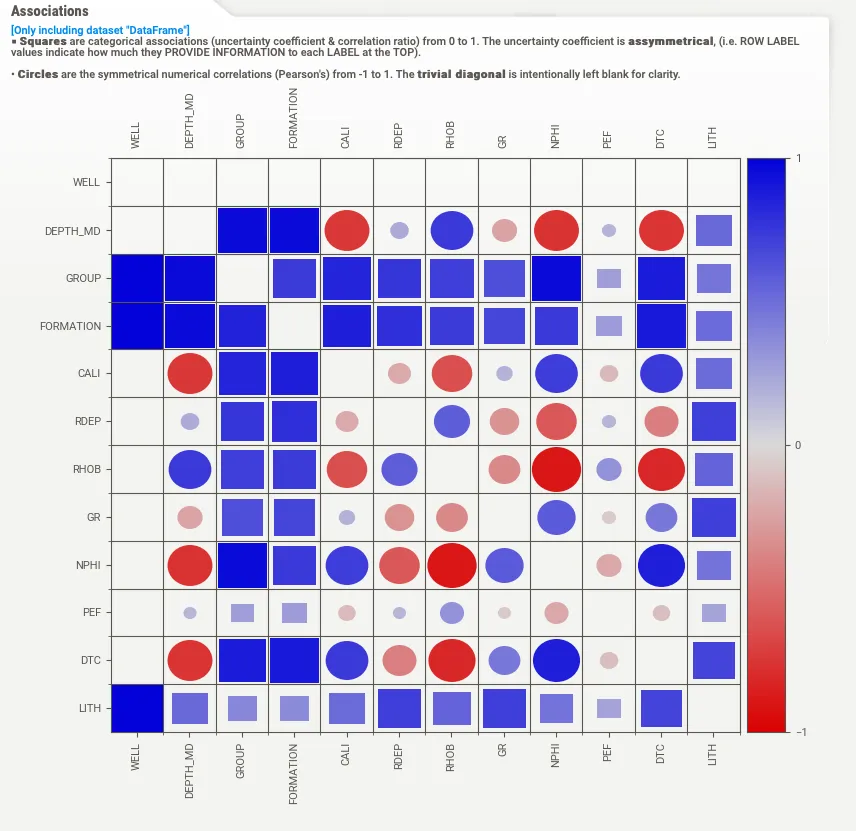
Одна из небольших проблем, которые обнаружились в этой библиотеке, заключается в том, что вам нужен широкий экран, чтобы иметь возможность просматривать весь горизонтальный контент без прокрутки. Однако не позволяйте этому отвлекать вас от возможностей, которые эта библиотека может привнести в ваш EDA.
4. Missingno
Если вы заинтересованы в использовании облегченной библиотеки для изучения полноты ваших данных, то Missingno — это то, что вам обязательно следует рассмотреть для своего набора инструментов EDA.
Это библиотека Python, которая предоставляет серию визуализаций для понимания наличия и распределения отсутствующих данных в кадре данных pandas. Библиотека предоставляет вам небольшое количество графиков (гистограмма, матричный график, тепловая карта или дендрограмма), чтобы визуализировать, какие столбцы в вашем фрейме данных содержат пропущенные значения и как степень пропущенности связана между переменными.
Как использовать MissingNo
Missingno можно установить через терминал с помощью pip:
pip install missingnoПосле установки библиотеки мы можем импортировать ее вместе с pandas и загрузить наши данные в фреймворк данных.
import pandas as pd
import missingno as msno
df = pd.read_csv('xeek_train_subset.csv')Затем мы можем вызвать желаемый сюжет из доступных:
msno.bar(df)
msno.matrix(df)
msno.denrogram(df)
msno.heatmap(df)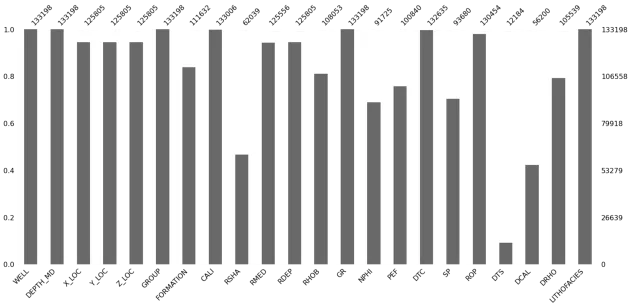
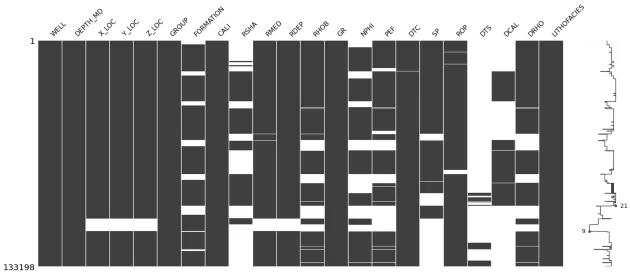
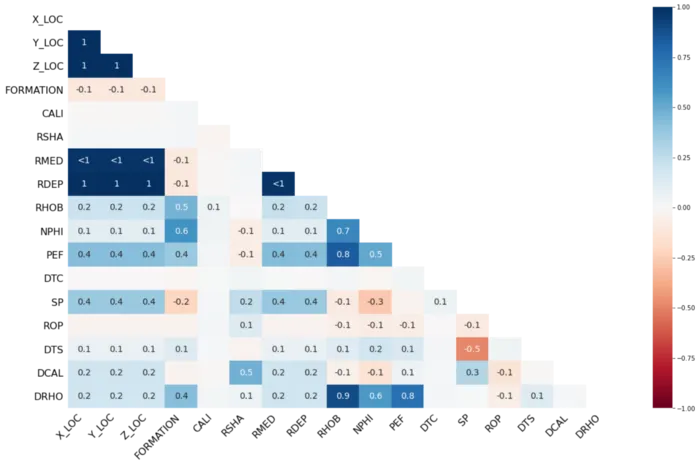
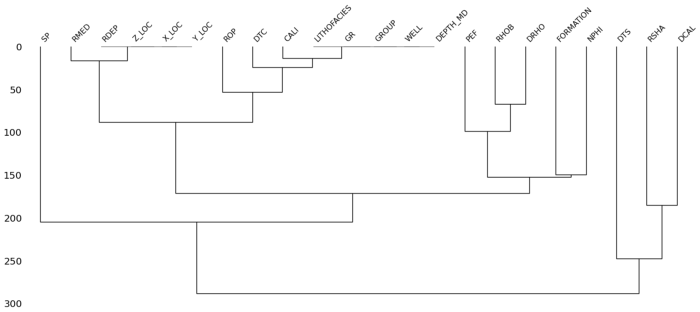
Приведенные выше четыре графика дают нам представление о:
- Насколько заполнен каждый столбец в кадре данных —
msno.bar() - Где возникают отсутствующие данные —
msno.matrix() - Насколько коррелированы пропущенные значения —
msno.heatmap()иmsno.dendrogram()
Хорошая вещь в этой библиотеке заключается в том, что графики четкие, простые для понимания и могут быть быстро включены в отчет в том виде, в котором они есть.
5. Sketch
Sketch — это очень новая (по состоянию на февраль 2023 года) библиотека, которая использует возможности ИИ, чтобы помочь вам понять ваши dataframes pandas, используя вопросы на естественном языке непосредственно в Jupyter. Вы также можете использовать его для создания примера кода, например, как построить график x и y в dataframes, а затем использовать этот код для создания необходимого графика.
Библиотека в основном автономна, где она использует алгоритмы машинного обучения, чтобы понять контекст вашего вопроса по отношению к вашему набору данных. Есть функция, которая опирается на API OpenAI, но это не умаляет возможности использования библиотеки.
У Sketch есть большой потенциал, чтобы быть мощным, особенно если вы хотите предоставить интерфейс для клиентов с очень ограниченными знаниями в области кодирования на Python.
Как использовать Sketch
Sketch можно установить через терминал с помощью pip:
pip install sketchЗатем мы импортируем pandas и sketch в нашу записную книжку, а затем загружаем данные из нашего CSV-файла.
import sketch
import pandas as pd
df = pd.read_csv('Data/Xeek_Well_15-9-15.csv')После импорта sketch для нашего фрейма данных будут доступны три новых метода.
Первый — это метод .ask, который позволяет вам задавать вопросы — используя естественный язык — о содержимом фрейма данных.
df.sketch.ask('What are the max values of each numerical column?')Это возвращает следующую строку с максимальными значениями каждого из числовых столбцов в dataframe.

Мы также можем спросить его, насколько полным является фрейм данных:
df.sketch.ask('How complete is the data?')И он вернет следующий ответ в человеческом письменном виде, а не в виде таблиц или графиков.

Очень впечатляюще. Но это еще не все.
Мы даже можем запросить библиотеку о том, как отображать данные, содержащиеся в кадре данных, с помощью .sketch.howto().
df.sketch.howto("""How do I plot RHOB against DEPTH_MD
using a line plot and have the line coloured in red?""")И он вернет фрагмент кода, как это сделать:

Который при запуске вернет следующий сюжет:
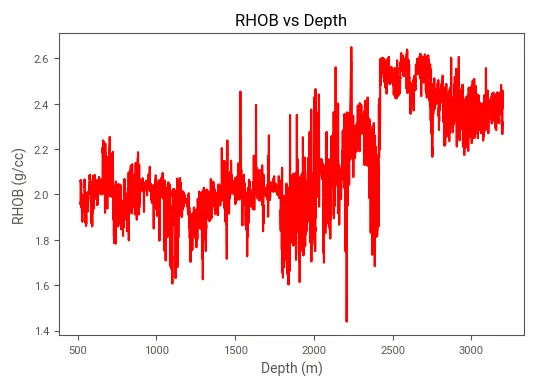
Третий вариант, доступный в Sketch, — это метод .apply, для запуска которого требуется API OpenAI. Эта функция удобна, когда мы хотим создать новые функции из существующих или сгенерировать новые.
Итоги
В этой статье мы рассмотрели пять мощных библиотек Python, которые можно использовать для ускорения и улучшения этапа исследовательского анализа данных в проекте. Они варьировались от простой графики до взаимодействия с данными с использованием возможностей обработки естественного языка.
Мы рекомендуем вам проверить эти библиотеки и изучить их возможности. Вы никогда не знаете, вы можете просто найти свою новую любимую библиотеку Python.