5 признаков того, что вы стали продвинутым пользователем Pandas, даже не осознавая этого

Ловите ли вы себя на том, что мечтаете о фреймворках данных и сериалах Pandas? Проводите ли вы часы напролет, выполняя сложные манипуляции и агрегации, едва замечая боль в спине и все это время думая: “Это так весело”?
Что ж, с таким же успехом вы могли бы быть продвинутым пользователем Pandas, даже не осознавая этого. Присоединяйтесь к клубу поклонников панд, достигших этого редкого уровня, и примите тот факт, что вы официально являетесь мастером обработки данных.
Итак, давайте взглянем на пять признаков того, что вы состоите в этом клубе.
1. Знаете, когда нужно избавиться от панд
Когда вы только начинали изучать анализ данных, могло показаться, что Pandas могут делать все. Многие онлайн-курсы позиционируют Pandas как универсальный сервис для удовлетворения всех ваших потребностей, связанных с данными.
Однако с опытом вы пришли к пониманию того, что у Pandas много недостатков. Вместо того чтобы вслепую использовать его для любой задачи, связанной с данными, вы знаете, как сделать шаг назад и спросить себя: “Является ли Pandas здесь лучшим вариантом?”
Есть несколько сценариев, в которых ответом на этот вопрос будет категорическое "НЕТ". К ним относятся обработка данных в режиме реального времени, обработка массивных наборов данных, высокопроизводительные вычисления и конвейеры данных производственного уровня.
1/ Для обработки данных в реальном времени представьте себе пушку, которая выстреливает фрагменты данных в реальном времени из какого-либо процесса со скоростью 100 sph (выстрелы в час :). Кусочки разлетаются быстро и яростно, и вы должны поймать, обработать и сохранить каждый из них в воздухе.
Мягко говоря, панды будут задушены таким уровнем обработки данных. Вместо этого вам следует использовать библиотеки, такие как Apache Kafka.
2/ Когда дело доходит до массивных наборов данных, у Уэса Маккинни, создателя Pandas, было эмпирическое правило:
Оперативная память должна быть в 5–10 раз больше размера набора данных для оптимальной работы Pandas.
“Достаточно просто”, - сказали бы вы, если бы это был 2013 год, но сегодняшние наборы данных, как правило, легко нарушают это правило.
3/ Высокопроизводительные вычисления подобны дирижированию симфонией. Точно так же, как дирижеру необходимо координировать действия множества разных музыкантов для создания гармоничного исполнения, высокопроизводительные вычислительные задачи требуют координации и синхронизации множества элементов обработки и потоков для достижения наилучших результатов.
Что касается панд, то они работают в одиночку.
4/ Для конвейеров данных производственного уровня думайте о них как о системе водоснабжения. Точно так же, как конвейеры данных должны быть надежными, масштабируемыми и ремонтопригодными для обеспечения постоянного снабжения чистой водой, им нужны аналогичные качества. Хотя Pandas может позаботиться об очистке и преобразовании, для остального следует использовать другие библиотеки.
Может быть трудно покинуть пушистые руки панд, но не чувствуйте себя виноватым, изучая другие варианты, если этого недостаточно.
Лично я недавно заинтересовался Polars, библиотекой, написанной на Rust, которая была разработана с нуля, чтобы устранить все ограничения Pandas.
Вы также можете играть в комбинации с такими библиотеками, как datatable. Вот фрагмент кода, который я часто использую для загрузки больших CSV-файлов за доли секунды и выполнения анализа в Pandas:
import datatable as dt
df = dt.fread("my_large_file.csv").to_pandas()2. Жажда скорости
Pandas — это массивная библиотека с множеством различных методов для выполнения одной и той же задачи. Однако, если вы опытный пользователь, вы знаете, какой метод лучше всего работает в конкретных ситуациях.
Например, вы знакомы с различиями между функциями итерации, такими как apply, applymap, map, iterrows и itertuples. Вы также знаете о компромиссах между использованием более медленной альтернативы для лучшей функциональности и использованием лучшей альтернативы для оптимальной скорости.
Хотя некоторые люди могут назвать вас суетливым, вы осторожно используете iloc и loc, потому что знаете, что iloc быстрее индексирует строки, а loc быстрее индексирует столбцы.
Однако, когда дело доходит до индексации значений, вы избегаете этих средств доступа, потому что понимаете, что условная индексация выполняется на порядки быстрее с помощью функции query.
# DataFrame of stock prices
stocks_df = pd.DataFrame(
columns=['date', 'company', 'price', 'volume']
)
threshold = 1e5
# Rows where the average volume for a company
# is greater than some threshold
result = df.query(
'(volume.groupby(company).transform("mean") > @threshold)'
)И вы также знаете, что функция replace лучше всего подходит для query на замену значений.
df.query('category == "electronics"').replace(
{"category": {"electronics": "electronics_new"}}, inplace=True
)Кроме того, вам удобно работать с различными форматами файлов, такими как CSV, Parquets, Feathers и HDF, и вы сознательно выбираете между ними, вместо того, чтобы слепо заливать все в старые добрые CSV. Вы знаете, что выбор правильного формата может помочь сэкономить часы и ресурсы памяти в будущем.
В дополнение к форматам файлов у вас также есть мощный трюк в рукаве — векторизация!
Вместо того, чтобы рассматривать DataFrames как просто фреймы данных, вы думаете о них как о матрицах, а столбцы — как о векторах. Всякий раз, когда вам не терпится использовать функцию итерации, такую как apply или itertuples, вы сначала посмотрите, можно ли использовать векторизацию, чтобы применить функцию ко всем элементам в столбце одновременно, а не к одному.
Кроме того, вы предпочитаете использовать базовые массивы NumPy с атрибутом .values вместо Pandas Series, потому что вы из первых рук наблюдали, как векторизация выполняется намного быстрее с массивами NumPy.
Когда все остальное терпит неудачу, ты не ставишь на этом точку и не сдаешься. Нет.
Вы обращаетесь либо к Cython, либо к Numba для действительно трудоемких задач, потому что вы профессионал. В то время как большинство людей изучали основы Pandas, вы потратили несколько мучительных часов на изучение этих двух технологий. Это то, что отличает тебя от других.
Как будто всего этого было недостаточно, вы внимательно прочитали страницу "Повышение производительности" руководства пользователя Pandas.
3. Так много типов данных
Pandas предлагает очень большую гибкость в работе с типами данных. Вместо того, чтобы просто использовать обычные типы данных float, int и object, вы сделали следующие два изображения своими обоями:
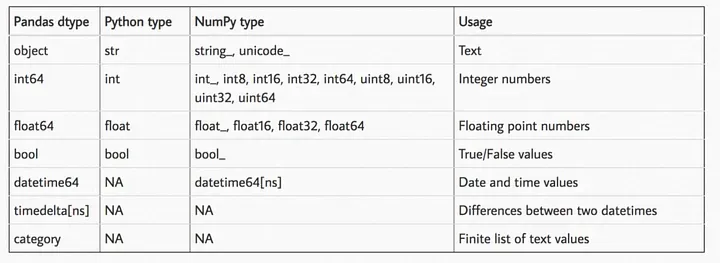

Вы намеренно выбираете наименьший возможный тип данных, потому что знаете, что он очень удобен для вашей оперативной памяти. Вы знаете, что int8 занимает гораздо меньше памяти, чем int64, и то же самое касается чисел с плавающей запятой.
Вы также избегаете object типа данных, как чумы, поскольку это худший из существующих.
Прежде чем читать файлы данных, вы просматриваете их несколько верхних строк с атрибутом cat file_name.extension, чтобы решить, какие типы данных вы хотите использовать для столбцов. Затем, при использовании функций read_*, вы заполняете параметр dtype для каждого столбца вместо того, чтобы позволить Pandas решать за себя.
Вы также как можно чаще выполняете манипуляции с данными на месте. Без него вы знаете, что Pandas порождает копии DataFrames и Series, засоряя вашу память. Кроме того, вы очень хорошо разбираетесь в классах и параметрах, таких как pd.Categorical и chunksize.
4. Дружите с пандами
Если и есть что-то, что делает Pandas королем библиотек анализа данных, так это, должно быть, ее интеграция с остальной экосистемой данных.
Например, к настоящему времени вы, должно быть, поняли, как вы можете изменить графический интерфейс Pandas с Matplotlib на Plotly, HVPlot, holoviews, Bokeh или Altair.
Да, Matplotlib - лучшие друзья Pandas, но время от времени вам хочется чего-нибудь интерактивного, например Plotly или Altair.
import pandas as pd
import plotly.express as px
# Set the default plotting backend to Plotly
pd.options.plotting.backend = 'plotly'Говоря о бэкендах, вы также заметили, что Pandas добавила полностью поддерживаемую реализацию PyArrow для своих функций read_* для загрузки файлов данных в совершенно новой версии 2.0.0.
import pandas as pd
pd.read_csv(file_name, engine='pyarrow')Когда это был только бэкэнд NumPy, было много ограничений, таких как небольшая поддержка нечисловых типов данных, почти полное игнорирование отсутствующих значений или отсутствие поддержки сложных структур данных (дат, временных меток, категорий).
До версии 2.0.0 Pandas готовила собственные решения этих проблем, но они были не так хороши, как надеялись некоторые активные пользователи. С серверной частью PyArrow загрузка данных происходит значительно быстрее, и он предоставляет набор типов данных, с которыми знакомы пользователи Apache Arrow:
import pandas as pd
pd.read_csv(file_name, engine='pyarrow', dtype_engine='pyarrow')Еще одна интересная функция Pandas, которую вы постоянно используете в JupyterLab, — это стилизация DataFrames.
Поскольку проект Jupyter такой классный, разработчики Pandas добавили немного магии HTML/CSS в атрибут .style, чтобы вы могли оживить старые простые кадры данных таким образом, чтобы они раскрывали дополнительные идеи.
df.sample(20, axis=1).describe().T.style.bar(
subset=["mean"], color="#205ff2"
).background_gradient(
subset=["std"], cmap="Reds"
).background_gradient(
subset=["50%"], cmap="coolwarm"
)
5. Скульптор данных
Поскольку Pandas - это библиотека для анализа данных и манипулирования ими, самым верным признаком того, что вы профессионал, является то, насколько гибко вы можете формировать и преобразовывать наборы данных в соответствии со своими целями.
В то время как большинство онлайн-курсов предоставляют готовые, очищенные данные в столбчатом формате, наборы данных в дикой природе бывают самых разных форм. Например, одним из наиболее раздражающих форматов данных является формат на основе строк (очень распространенный для финансовых данных).:
import pandas as pd
# create example DataFrame
df = pd.DataFrame(
{
"Date": [
"2022-01-01",
"2022-01-02",
"2022-01-01",
"2022-01-02",
],
"Country": ["USA", "USA", "Canada", "Canada"],
"Value": [10, 15, 5, 8],
}
)
df
Вы должны иметь возможность преобразовать формат на основе строк в более полезный формат, подобный приведенному ниже примеру, используя функцию pivot:
pivot_df = df.pivot(
index="Date",
columns="Country",
values="Value",
)
pivot_df
Возможно, вам также придется выполнить противоположную этой операции операцию, называемую расплавлением.
Вот пример с функцией melt Pandas, которая превращает столбцовые данные в формат на основе строк:
df = pd.DataFrame(
{
"Date": ["2022-01-01", "2022-01-02", "2022-01-03"],
"AAPL": [100.0, 101.0, 99.0],
"GOOG": [200.0, 205.0, 195.0],
"MSFT": [50.0, 52.0, 48.0],
}
)
df
melted_df = pd.melt(
df, id_vars=["Date"], var_name="Stock", value_name="Price"
)
melted_df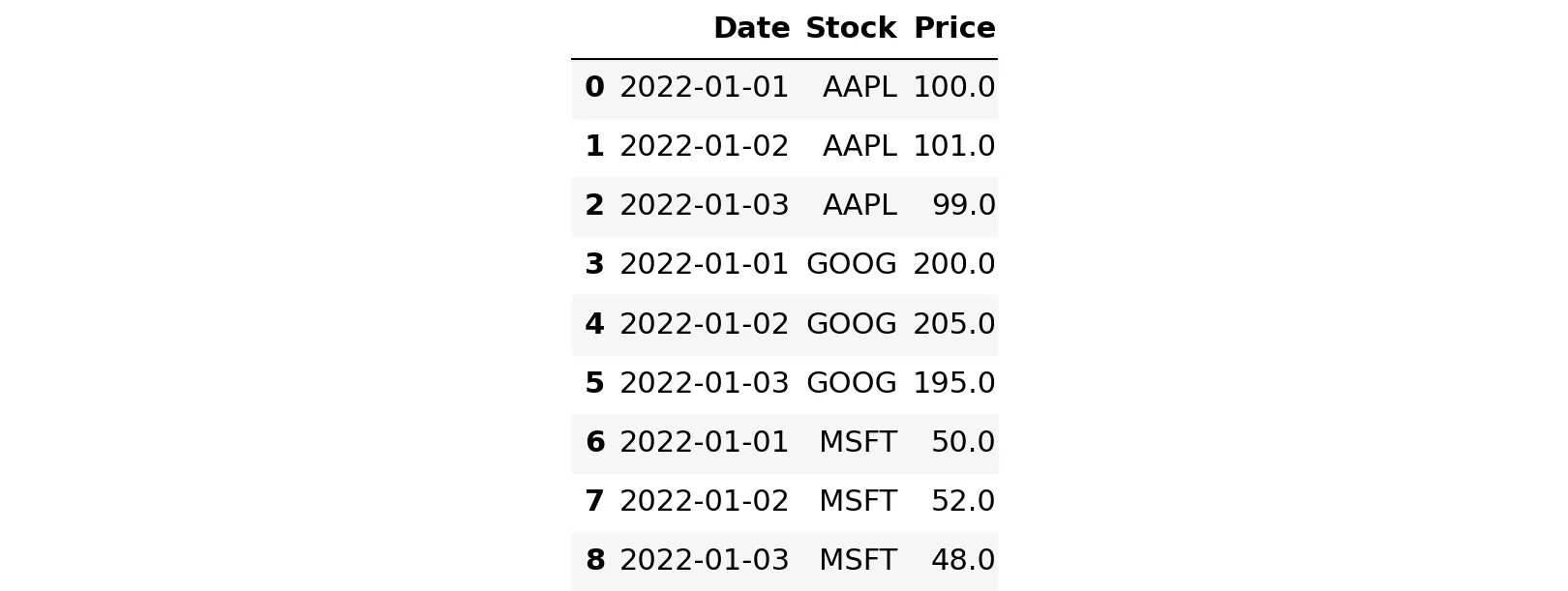
Такие функции могут быть довольно сложными для понимания и еще более сложными для применения.
Есть и другие подобные, такие как pivot_table, которая создает сводную таблицу, которая может вычислять различные типы агрегирования для каждого значения в таблице.
Другая функция — stack/unstack, которая может сворачивать/разбирать индексы DataFrame. crosstab вычисляет перекрестную таблицу двух или более факторов и по умолчанию вычисляет таблицу частот факторов, но также может вычислять другую сводную статистику.
Тогда есть groupby. Несмотря на то, что основы этой функции просты, ее более продвинутые варианты использования очень сложны в освоении. Если бы содержимое функции groupby Pandas было вынесено в отдельную библиотеку, оно было бы больше, чем большинство в экосистеме Python.
# Group by a date column, use a monthly frequency
# and find the total revenue for `category`
grouped = df.groupby(['category', pd.Grouper(key='date', freq='M')])
monthly_revenue = grouped['revenue'].sum()Умение выбирать правильную функцию для конкретной ситуации — признак того, что вы настоящий скульптор данных.
Вывод
Хотя название статьи, возможно, показалось шутливым способом распознать продвинутых пользователей Pandas, моей целью было также дать некоторые рекомендации новичкам, желающим усовершенствовать свои навыки анализа данных.
Выделив некоторые причудливые привычки продвинутых пользователей, я хотел пролить свет на некоторые менее известные, но мощные функции этой универсальной библиотеки.
Независимо от того, являетесь ли вы опытным специалистом по обработке данных или только начинаете, освоение Pandas может оказаться непростой задачей. Однако, распознав признаки продвинутого пользователя и переняв некоторые из его приемов и хитростей, вы сможете вывести свою игру в анализ данных на новый уровень.
Я надеюсь, что эта статья немного развлекла вас и вдохновила на то, чтобы исследовать глубины Pandas и стать мастером манипулирования данными.