AWS Personalize для рекомендации новых фильмов пользователям на основе их оценок по сравнению с другими похожими фильмами.
Amazon Personalize позволяет разработчикам, не имеющим опыта машинного обучения, легко встраивать сложные возможности персонализации в свои приложения. С помощью Personalize вы предоставляете поток действий из своего приложения, а также список элементов, которые хотите порекомендовать, и Personalize обработает данные для обучения модели персонализации, настроенной для ваших данных.
В этом уроке мы будем использовать набор данных MovieLens, который является популярным набором данных, используемым для исследования рекомендаций. Загрузите набор данных MovieLens 25M в формате zip в разделе «Рекомендуется для новых исследований». Из командной строки мы можем распаковать его, как показано ниже. Перейдите в папку, в которой хранится zip, и запустите команду unzip. Возможно, вам потребуется установить разархивированный пакет, если он еще не установлен по этой ссылке. Например на убунту sudo apt-get install -y unzip. Нам не нужны файлы genome-tags.csv и genome-scores.csv , поэтому их можно удалить .
$ cd datasets/personalize
$ unzip ml-25m.zipЗагрузка данных в S3
В этом уроке мы будем использовать полный 25-метровый набор данных MovieLens (25 миллионов оценок и один миллион приложений тегов, примененных к 62 000 фильмам 162 000 пользователей). Это может привести к большому счету при обучении персонализированному решению, в зависимости от используемого рецепта (> 100 долларов США). Таким образом, можно либо выбрать меньший набор данных из этого, либо использовать последние наборы данных MovieLens, рекомендованные для образования и развития, которые намного меньше (100 000 оценок и 3600 приложений тегов, примененных к 9000 фильмам 600 пользователями).
В следующем примере задается значение Status=Enabled, чтобы включить ускорение передачи для корзины. Вы используете Status=Suspended, чтобы приостановить ускорение переноса.
$ aws s3api put-bucket-accelerate-configuration --bucket recommendation-sample-data --accelerate-configuration Status=EnabledРекомендуется использовать команды aws s3 (например, aws s3 cp) для многокомпонентной загрузки и скачивания, поскольку эти команды aws s3 автоматически выполняют многокомпонентную загрузку и загрузку в зависимости от размера файла, как описано в документации AWS Чтобы использовать больше пропускной способности вашего хоста и ресурсы во время загрузки, увеличьте максимальное количество одновременных запросов, заданное в конфигурации интерфейса командной строки AWS. По умолчанию интерфейс командной строки AWS использует максимум 10 одновременных запросов. Эта команда устанавливает максимальное количество одновременных запросов равным 20:
Вы можете направить все запросы Amazon S3, сделанные командами командной строки AWS s3 и s3api, на конечную точку ускорения: s3-accelerate.amazonaws.com. Для этого установите для параметра use_accelerate_endpoint значение true в профиле в файле конфигурации AWS. Ускорение передачи должно быть включено в вашем сегменте, чтобы использовать конечную точку ускорения. В следующем примере файл загружается в корзину, для которой включено ускорение передачи, с использованием параметра –endpoint-url для указания конечной точки ускорения.
$ aws configure set default.s3.use_accelerate_endpoint true
$ aws configure set default.s3.max_concurrent_requests 20
$ aws s3 cp datasets/personalize/ml-25m/ s3://recommendation-sample-data/movie-lens/raw_data/ --region us-east-1 --recursive --endpoint-url https://recommendation-sample-data.s3-accelerate.amazonaws.com
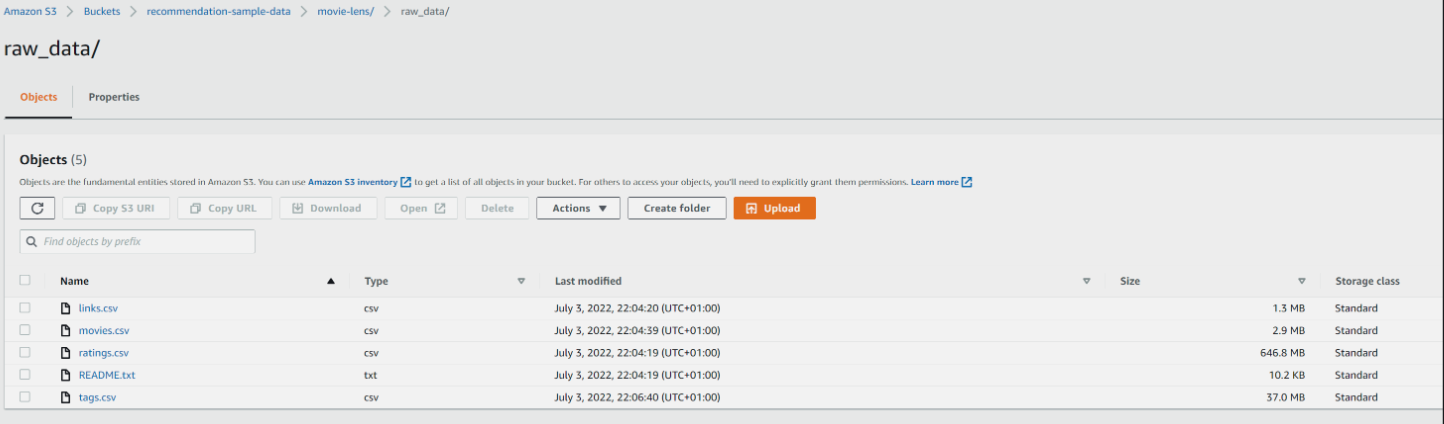
Наконец, нам нужно добавить скрипт Glue и Lambda-функцию в корзину S3. Это предполагает, что Lambda-функция заархивирована, lambdas/data_import_personalize.zip и у вас есть ведро с ключом aws-glue-assets-376337229415-us-east-1/scripts. Если нет, адаптируйте запрос соответствующим образом. Запустите следующие команды из корня репо
$ aws s3 cp step_functions/personalize-definition.json s3://recommendation-sample-data/movie-lens/personalize-definition.json
$ aws s3 cp lambdas/trigger_glue_personalize.zip s3://recommendation-sample-data/movie-lens/lambda/trigger_glue_personalize.zip
Если вы не настроили ускорение передачи для корзины клеевых ресурсов по умолчанию, вы можете установить значение false перед запуском cp команды, как показано ниже. В противном случае вы получите следующую ошибку: Произошла ошибка (InvalidRequest) при вызове операции PutObject: S3 Transfer Acceleration не настроен для этого сегмента.
$ aws configure set default.s3.use_accelerate_endpoint false
$ aws s3 cp projects/personalize/glue/Personalize_Glue_Script.py s3://aws-glue-assets-376337229415-us-east-1/scripts/Personalize_Glue_Script.py
Шаблоны CloudFormation
Шаблон cloudformation для создания ресурсов для этого примера находится в этой папке. Шаблон cloudformation personalize.yaml создает следующие ресурсы:
- Работа Glue
- Персонализируйте ресурсы (набор данных, группу наборов данных, схему) и связанные роли
- Функция шага (для запуска ETL и задания Personalize DatasetImport и создания версии решения) и связанная роль
- Lambda-функция (и связанная с ней роль) для запуска выполнения пошаговой функции с уведомлением о событии S3.
Мы можем использовать следующую команду cli для создания шаблона, при этом путь к шаблону передается в --template-body аргумент. Адаптируйте это в зависимости от того, где хранится ваш шаблон. Нам также необходимо включить CAPABILITIES_NAMED_IAM значение в --capabilities arg, так как шаблон включает ресурсы IAM, например, роль IAM, которая имеет пользовательское имя, такое как RoleName.
$ aws cloudformation create-stack --stack-name PersonalizeGlue \
--template-body file://cloudformation/personalize.yaml \
--capabilities CAPABILITY_NAMED_IAM
{
"StackId": "arn:aws:cloudformation:<region>:<account-id>:stack/PersonalizeGlue/2dc9cca0-fe63-11ec-b51b-0e44449cc4eb"
}
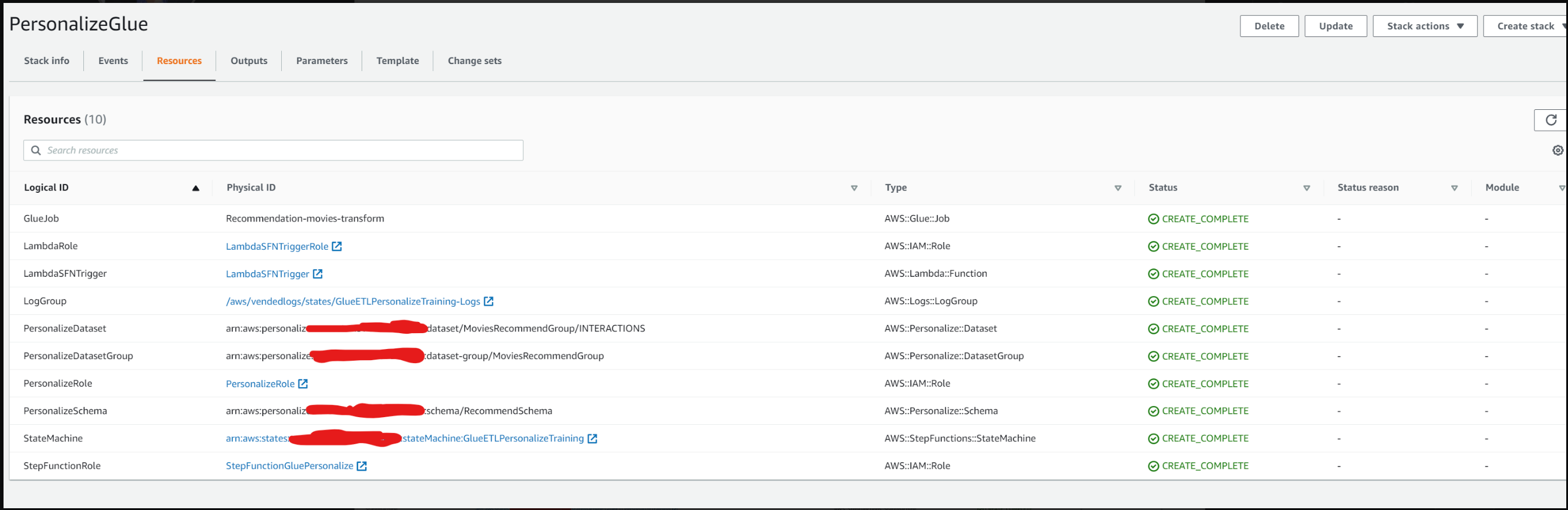
В случае успеха мы должны увидеть следующие ресурсы, успешно созданные на вкладке ресурсов.
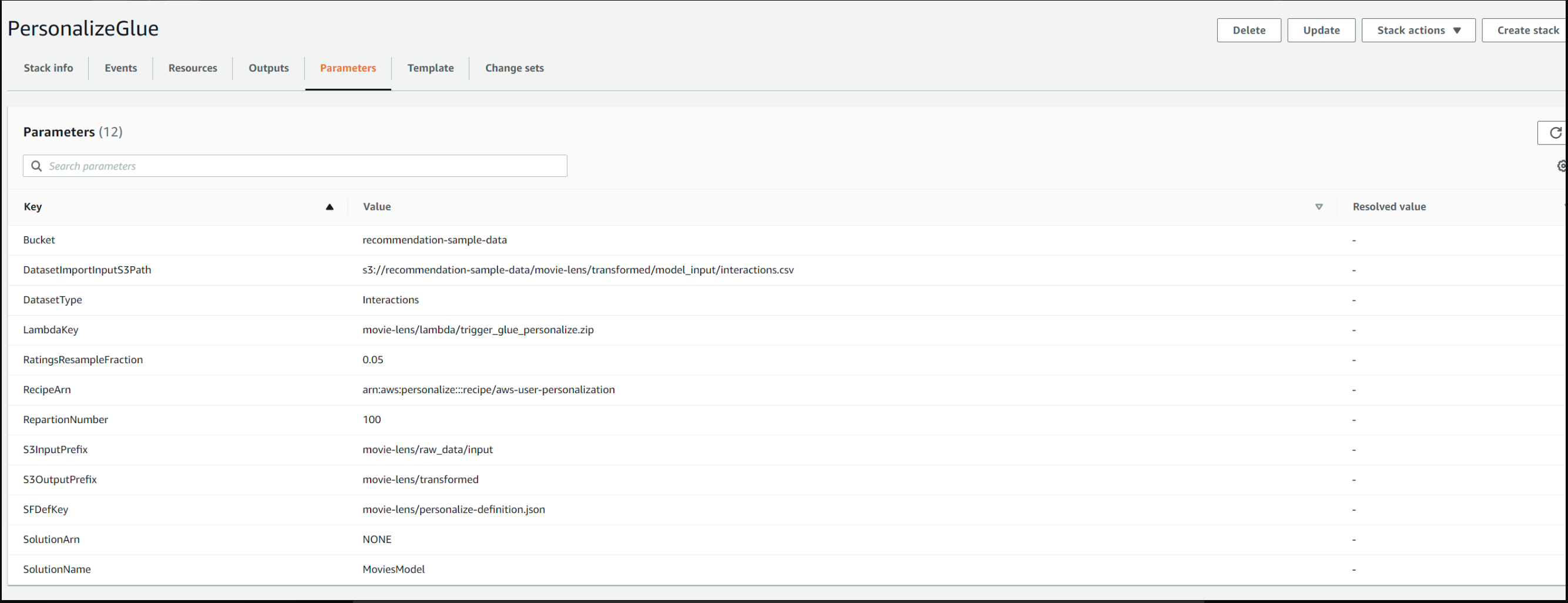
Если мы запустим команду, как указано выше, просто используя параметры по умолчанию, мы должны увидеть пары ключ-значение, перечисленные на вкладке параметров, как на снимке экрана ниже.
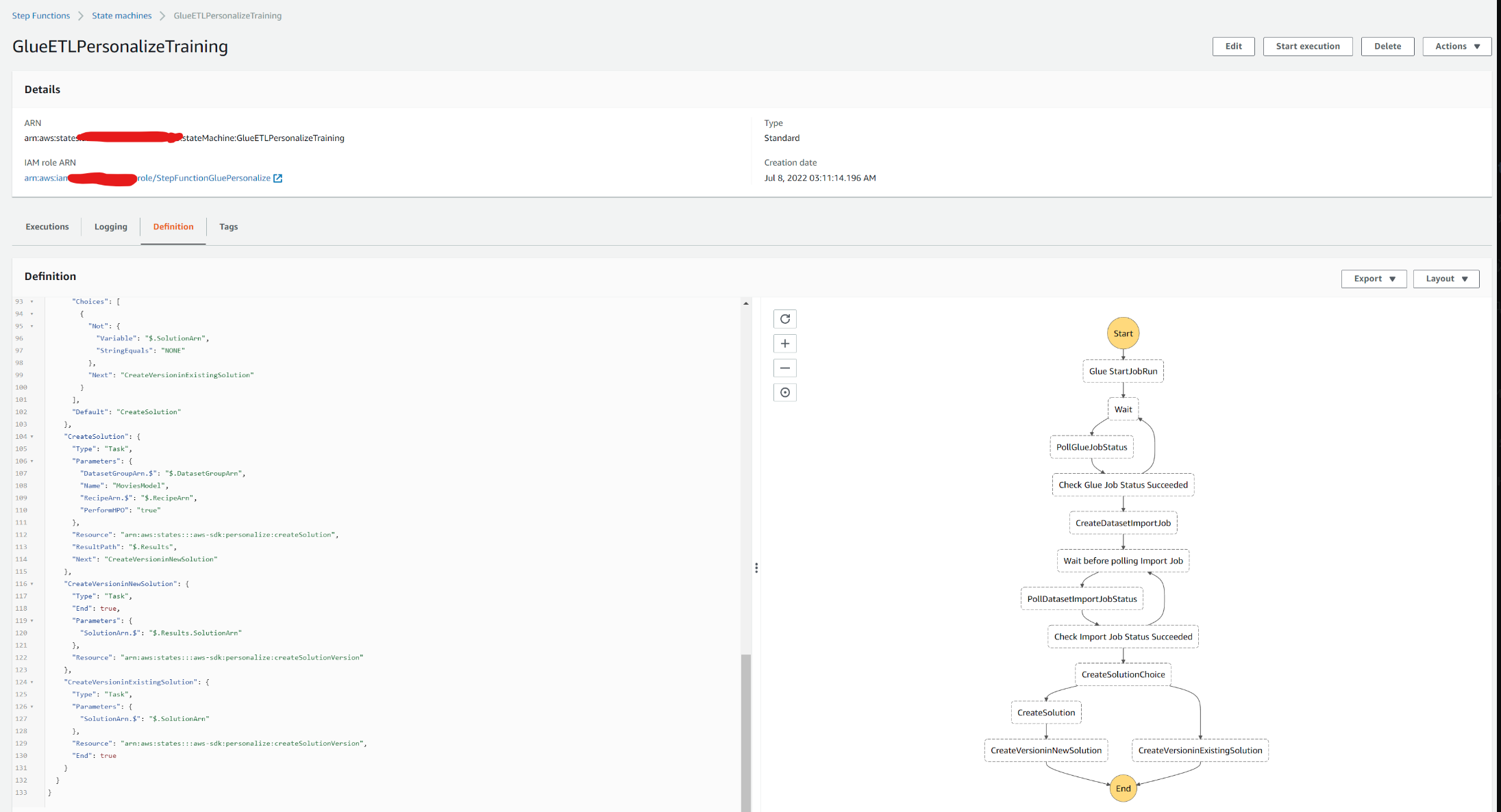
Мы должны увидеть, что все сервисы должны быть созданы. Например, перейдите к консоли функций Step и щелкните имя SFN GlueETLPersonalizeTraining
Уведомления о событиях S3
Нам нужно настроить уведомления о событиях S3 для рабочих процессов обучения и прогнозирования:
- Рабочий процесс обучения
- S3 в лямбда-уведомление (для события ввода объекта необработанных данных), чтобы инициировать выполнение пошаговой функции для рабочего процесса поезда.
- Пакетные/рекомендации в реальном времени
- Уведомление S3 to Lambda для запуска пакетного задания персонализации при пакетном образце данных объекта, но в префикс корзины S3
- Уведомление S3 в Lambda для запуска лямбды для преобразования выходных данных пакетного задания, добавленного в S3.
- Уведомление S3 в теме SNS, когда выходные данные Lambda-преобразования попадают в корзину S3. Мы настроили электронную почту в качестве подписчика на SNS через протокол, установленный в качестве конечной точки электронной почты, через облачное формирование. Сообщения SNS затем отправят электронное письмо на адрес подписчика, когда сообщение о событии будет получено от S3.
Чтобы добавить уведомление о событии корзины для запуска рабочего процесса обучения с помощью пошаговых функций, запустите собственный скрипт и передайте arg --workflow со значением train. По умолчанию это отправит событие S3, когда CSV-файл будет загружен в movie-lens/batch/results/ префикс в корзине.
$ python projects/personalize/put_notification_s3.py --workflow train
INFO:botocore.credentials:Found credentials in shared credentials file: ~/.aws/credentials
INFO:__main__:Lambda arn arn:aws:lambda:........:function:LambdaSFNTrigger for function LambdaSFNTrigger
INFO:__main__:HTTPStatusCode: 200
INFO:__main__:RequestId: X6X9E99JE13YV6RH
Чтобы добавить уведомление о событии корзины для пакетных прогнозов/прогнозов в реальном времени, запустите скрипт и передайте его --workflow со значением predict. Префиксы по умолчанию, установленные для триггеров событий объекта для уведомлений s3 to lambda и s3 to sns. Их можно переопределить, передав соответствующие имена аргументов.
$ python projects/personalize/put_notification_s3.py --workflow predict
INFO:botocore.credentials:Found credentials in shared credentials file: ~/.aws/credentials
INFO:__main__:Lambda arn arn:aws:lambda:us-east-1:376337229415:function:LambdaBatchTrigger for function LambdaBatchTrigger
INFO:__main__:Lambda arn arn:aws:lambda:us-east-1:376337229415:function:LambdaBatchTransform for function LambdaBatchTransform
INFO:__main__:Topic arn arn:aws:sns:us-east-1:376337229415:PersonalizeBatch for PersonalizeBatch
INFO:__main__:HTTPStatusCode: 200
INFO:__main__:RequestId: Q0BCATSW52X1V299
В настоящее время не поддерживаются уведомления для тем SNS типа FIFO.
Инициировать рабочий процесс для решения для обучения
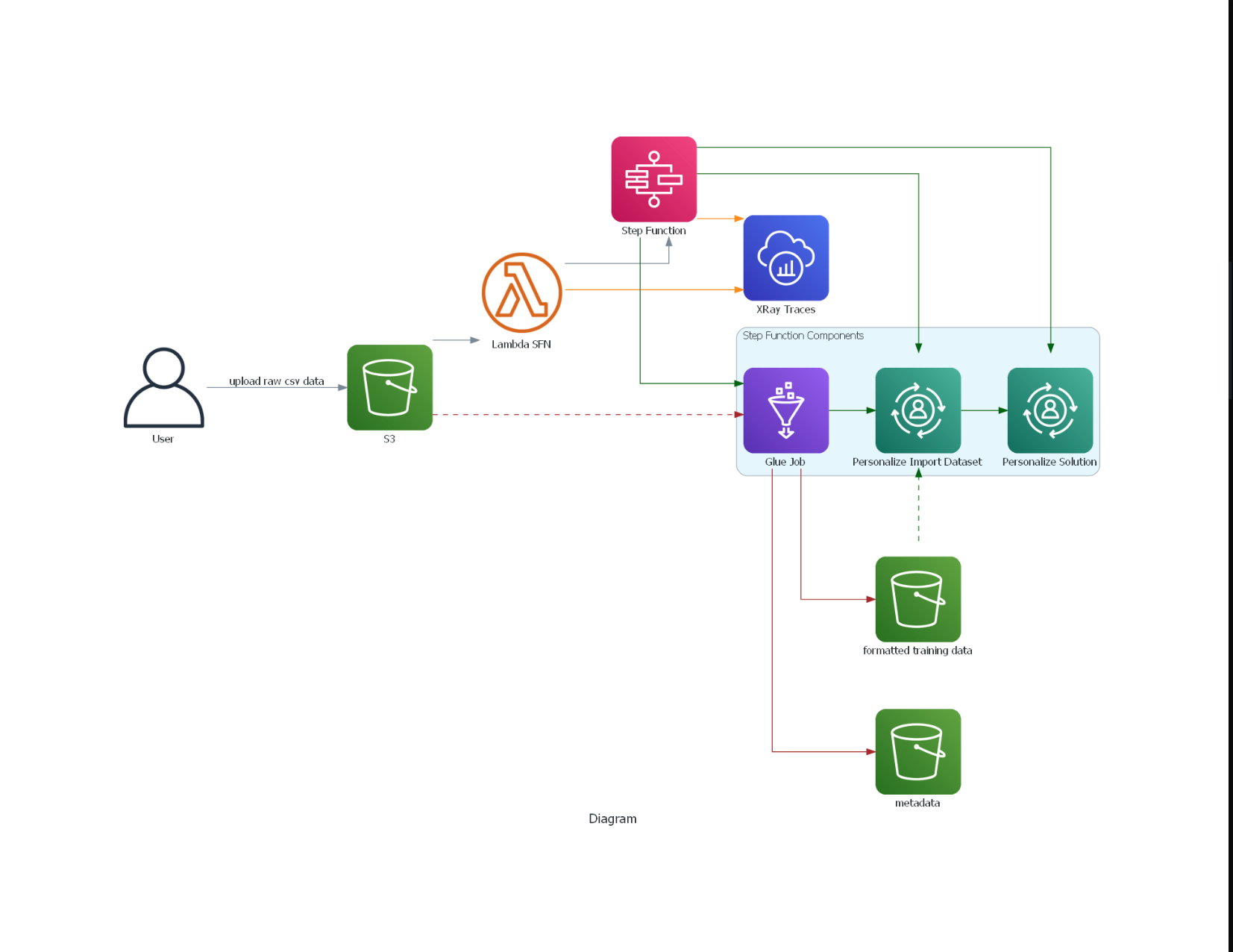
Ресурсы Lambda-функции и ступенчатой функции в рабочем процессе уже должны быть созданы с помощью облачного формирования. Мы запустим рабочий процесс, загрузив необработанный набор данных в путь S3, для которого уведомление о событии S3 настроено на запуск лямбда-выражения и вызов функции. Это запустит конечный автомат, который выполнит все шаги, определенные в файле определения.
Во-первых, он запускает склеивающее задание для преобразования необработанных данных в требуемую схему и формат для импорта набора данных о взаимодействиях в персонализацию. https://docs.aws.amazon.com/personalize/latest/dg/interactions-dataset-requirements.html Результаты работы по склеиванию хранятся в папке S3, отличной от необработанных данных.
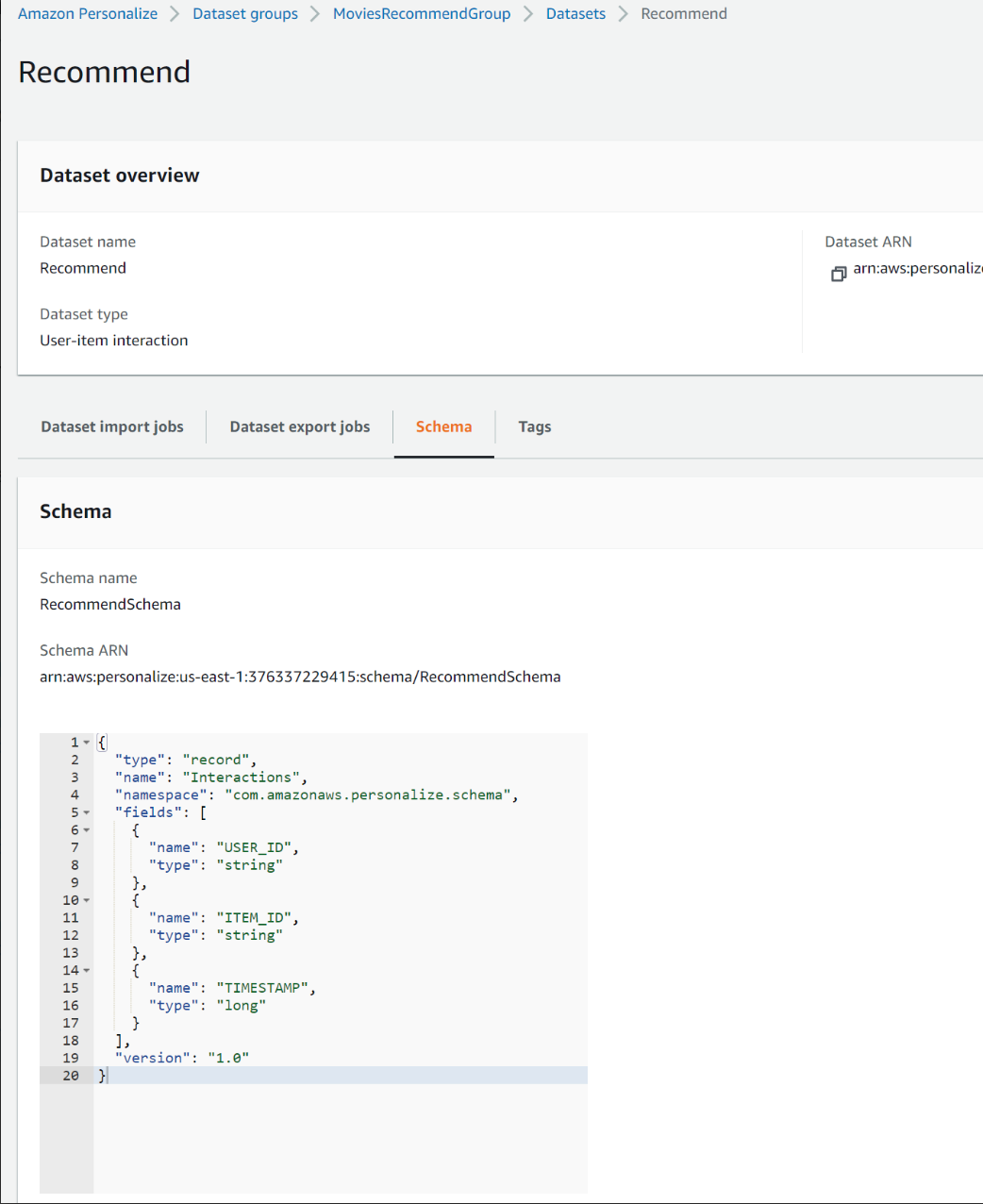
Затем он импортирует набор данных о взаимодействиях в файл personalize. Ресурс группы пользовательских наборов данных и набор данных о взаимодействиях (с ) уже созданы и определены при создании стека cloudformation.
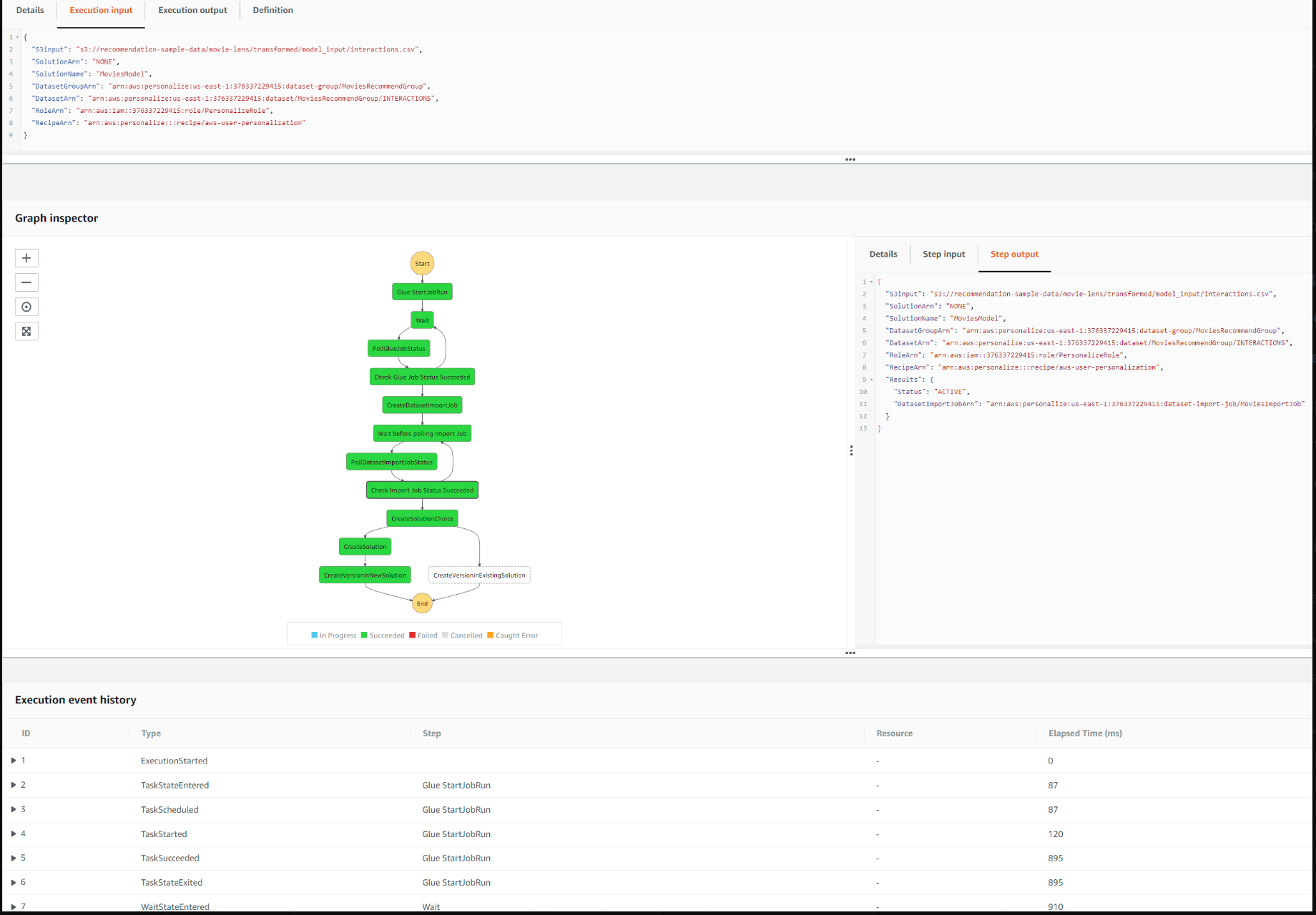
Подождите, пока версия решения напечатает статус ACTIVE. Обучение может занять некоторое время, в зависимости от размера набора данных и количества взаимодействий пользователя с элементом. При использовании AutoML это может занять больше времени. Обратите внимание, что значение времени обучения (в часах) основано на 1 часе вычислительной мощности (по умолчанию 4 ЦП и 8 ГБ памяти). Однако это можно настроить автоматически, если для обучения данных выбран более эффективный тип экземпляра, чтобы выполнить задание быстрее. В этом случае рассчитанный показатель количества часов обучения будет скорректирован и увеличен, что приведет к увеличению счета.
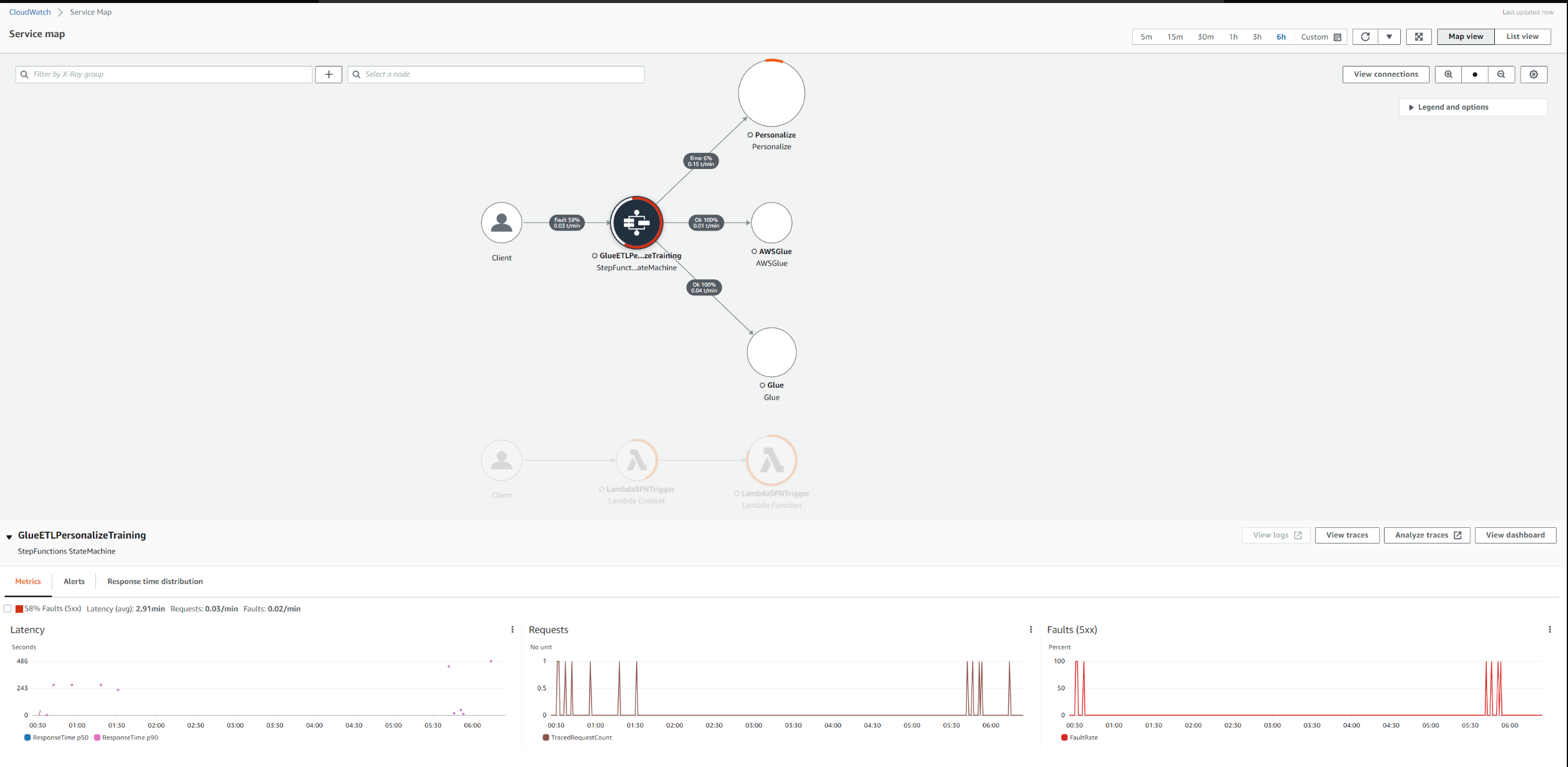
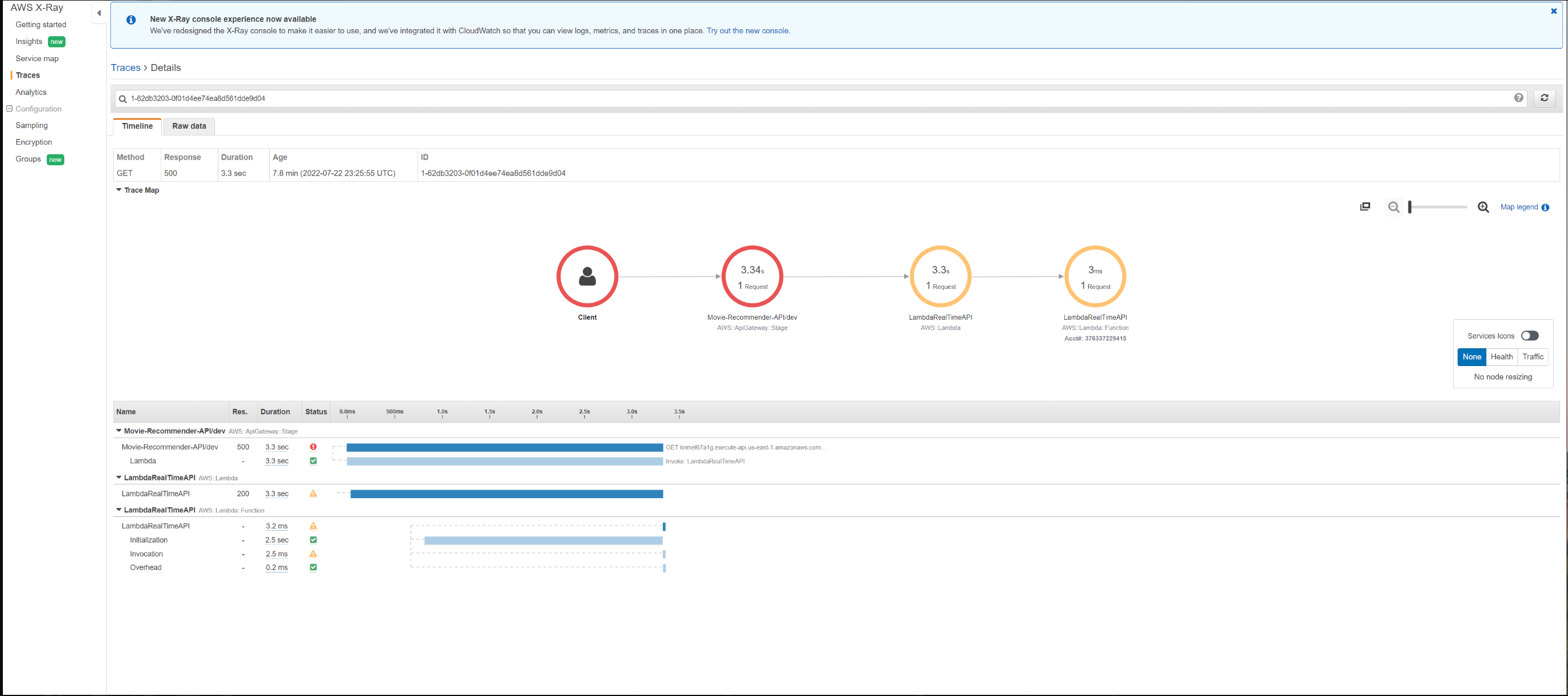
Чтобы диагностировать какие-либо ошибки в выполнении, мы можем просмотреть рентгеновские снимки и журналы. Теперь вы можете просматривать карту сервисов в консоли Amazon CloudWatch. Откройте консоль CloudWatch и выберите Service map в разделе X-Ray traces на левой панели навигации. Карта обслуживания указывает на работоспособность каждого узла, раскрашивая его в зависимости от соотношения успешных вызовов к ошибкам и сбоям. Каждый ресурс AWS, который отправляет данные в X-Ray, отображается на графике как сервис. Грани соединяют службы, которые работают вместе, для обслуживания запросов . В центре каждого узла консоль показывает среднее время ответа и количество трассировок, отправленных в минуту в течение выбранного диапазона времени. Трассировка собирает все сегменты, сгенерированные одним запросом.
Выберите сервисный узел, чтобы просмотреть запросы для этого узла, или ребро между двумя узлами, чтобы просмотреть запросы, прошедшие это соединение. Карта обслуживания разделяет рабочий процесс на два идентификатора трассировки для каждого запроса со следующими группами сегментов:
- сервисы Lambda и функциональные сегменты
- ступенчатая функция, glue, персонализация сегментов
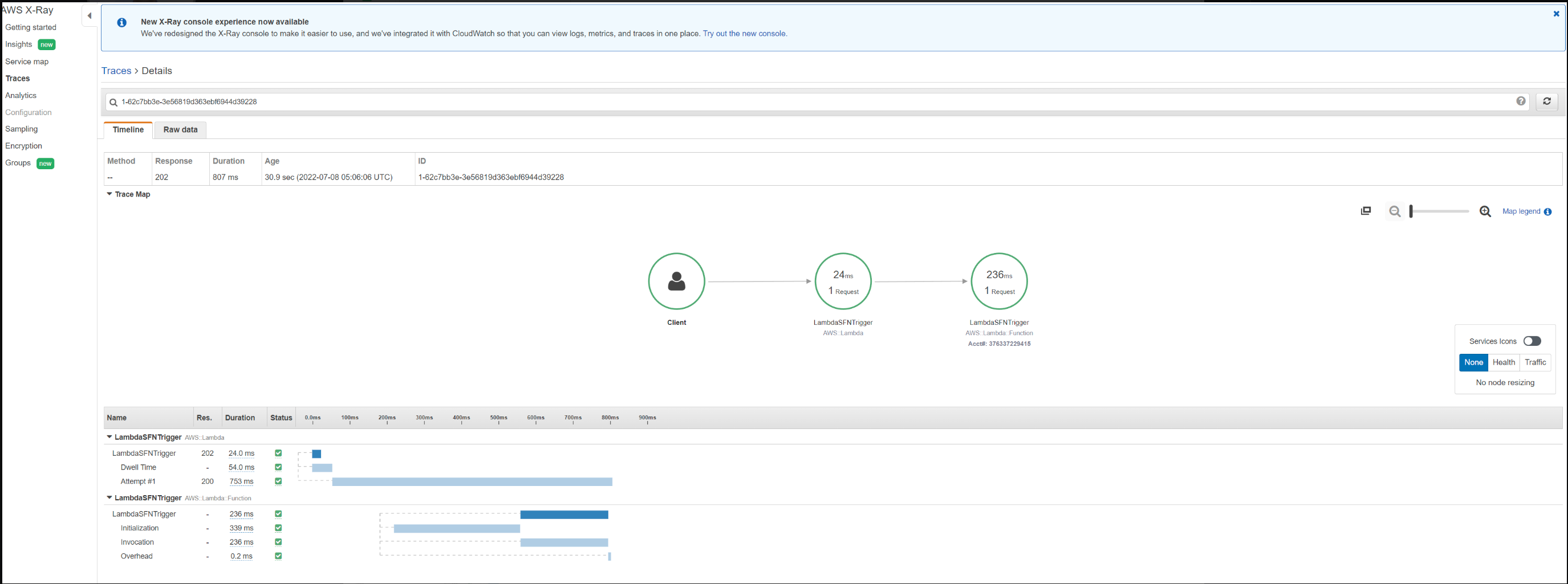
Вы также можете выбрать идентификатор трассировки, чтобы просмотреть карту трассировки и временную шкалу трассировки. Представление временной шкалы показывает иерархию сегментов и подсегментов. Первая запись в списке — это сегмент, представляющий все данные, записанные службой для одного запроса. Под сегментом находятся подсегменты. В этом примере показаны подсегменты, записанные Lambda-сегментами. Lambda записывает сегмент для службы Lambda, которая обрабатывает запрос на вызов, и один для работы, выполняемой функцией. Функциональный сегмент имеет подсегменты для фазы инициализации (инициализируется среда выполнения Lambda), фазы вызова (вызывается обработчик функции) и фазы служебной информации (время ожидания между отправкой ответа и сигналом для следующего вызова).
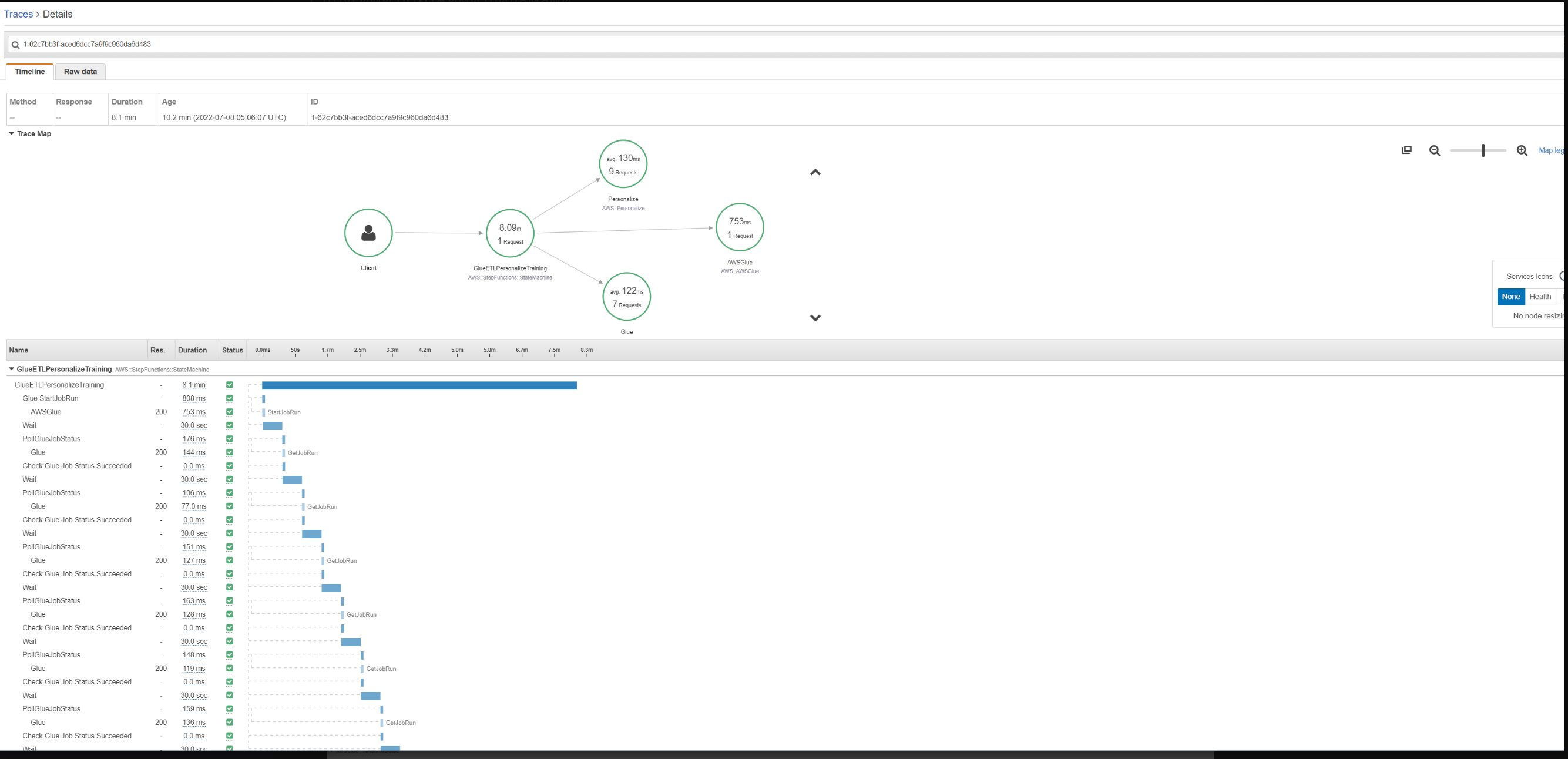
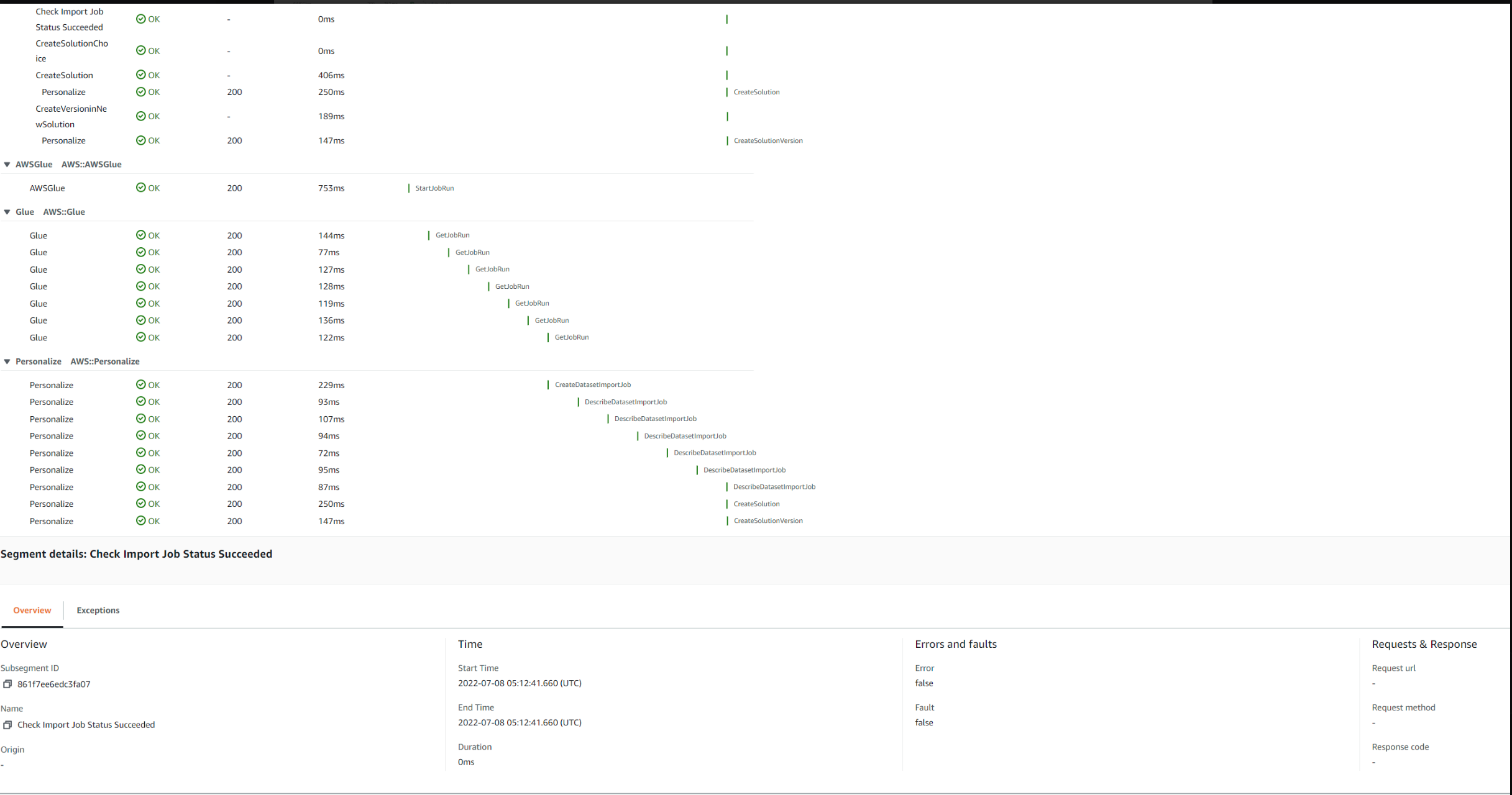
Для ступенчатых функций мы можем видеть различные подсегменты, соответствующие различным состояниям конечного автомата.
Запустите GlueJob через ноутбук и обучите решение вручную
Создайте конечную точку GlueDev с помощью стека CloudFormation. Можно найти дополнительные инструкции по использованию cloudformation.
Установите параметры
- Количество рабочих = 7
- Тип работника = G.1X
Затем создайте записную книжку, используя эту конечную точку, и загрузите записную книжку .
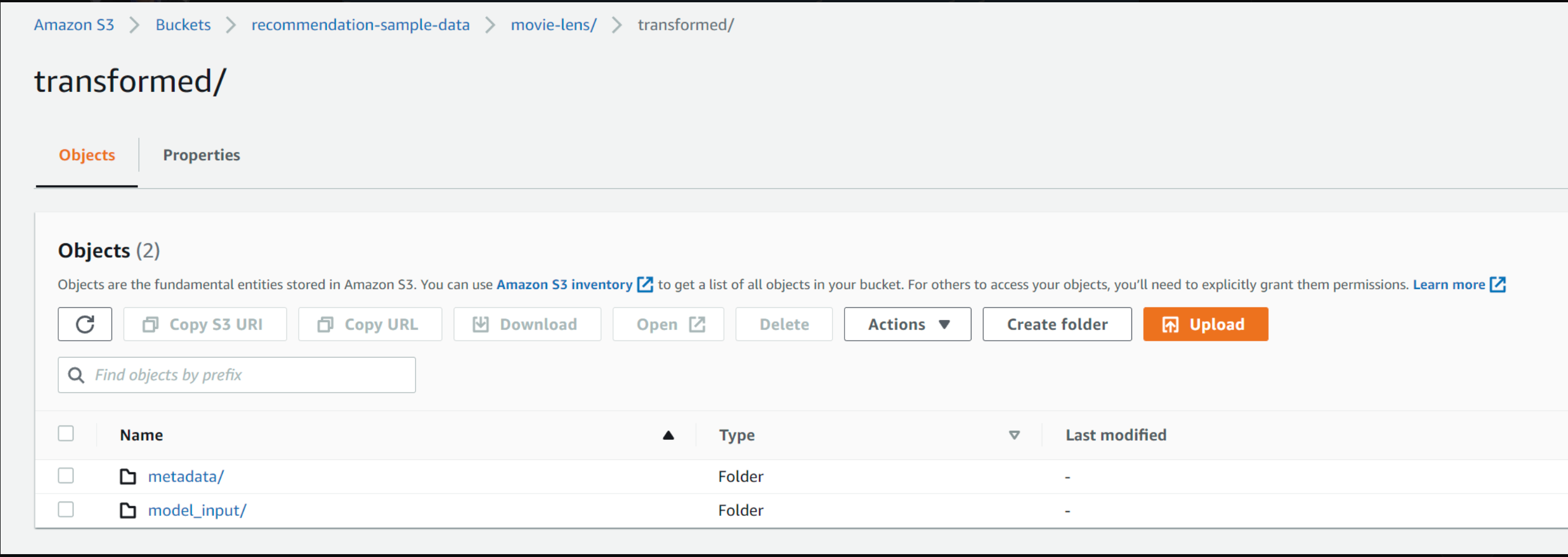
После завершения работы ноутбука вы должны увидеть две папки, s3://recommendation-sample-data/movie-lens/transformed/, как показано ниже. Каждый из них будет содержать CSV-файл, соответствующий данным о взаимодействиях (которые будут использоваться для обучения) и дополнительные метаданные (например, столбцы с жанрами фильмов, рейтингами и т. д.).
Блокнот по умолчанию отбирает половину количества строк в рейтингах csv, что по-прежнему составляет около 12,5 миллионов строк. Это может привести к большому счету при обучении модели (как упоминалось в предыдущем разделе). Возможно, вы захотите настроить параметр дроби для метода выборки на более низкое значение (например, 0,05) и впоследствии проверить количество строк рейтинга данных.
resampledratings_dyf = DynamicFrame.fromDF(
S3inputratings_node1656882568718.toDF().sample(False, 0.5, seed=0),
glueContext,
"resampled ratings",
)
resampledratings_dyf.toDF().count()Затем мы можем импортировать набор данных в персонализацию, запустив следующий скрипт:
$ python projects/personalize/import_dataset.py --dataset_arn arn:aws:personalize:us-east-1:376337229415:dataset/RecommendGroup/INTERACTIONS --role_arn arn:aws:iam::376337229415:role/PersonalizeRole
Dataset Import Job arn: arn:aws:personalize:us-east-1:376337229415:dataset-import-job/MoviesDatasetImport
Name: MoviesDatasetImport
ARN: arn:aws:personalize:us-east-1:376337229415:dataset-import-job/MoviesDatasetImport
Status: CREATE PENDING
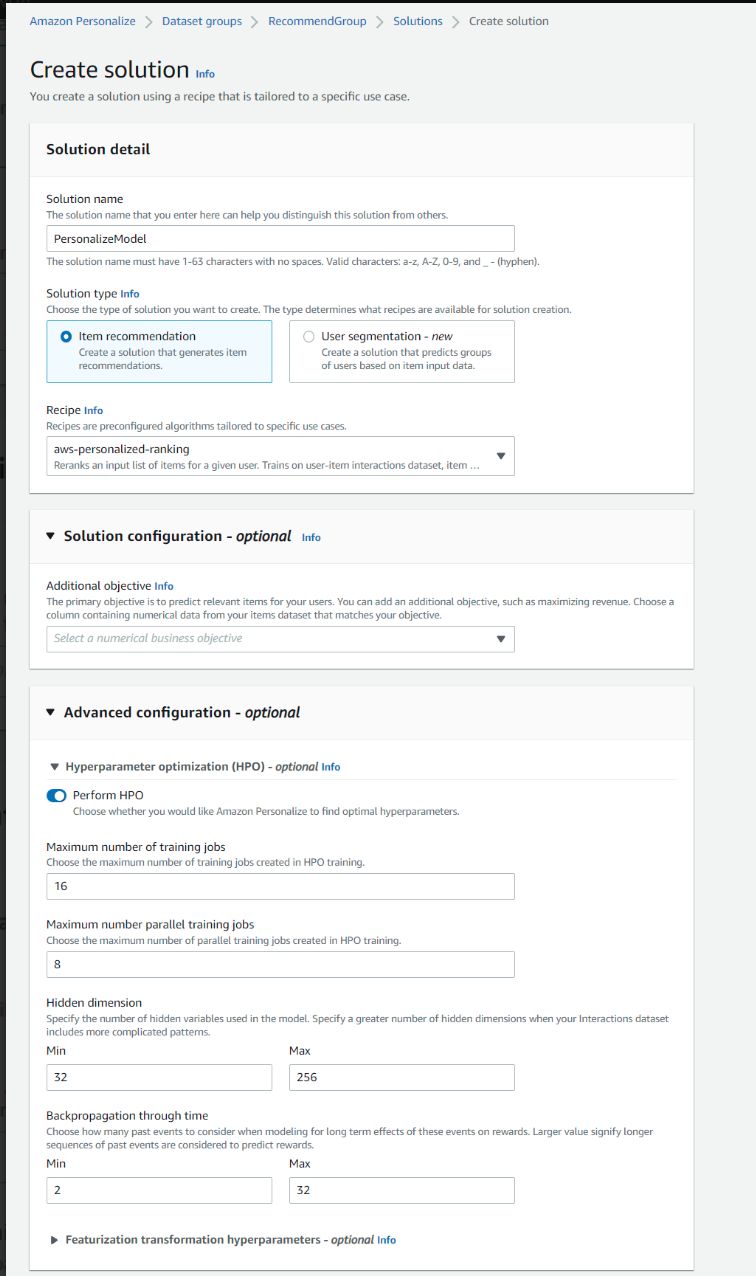
В консоли AWS создайте решение для обучения. Перейдите в Решения и рецепты -> Создать решение и заполните значения, как на скриншоте ниже, а затем нажмите Create and train solution
- Название решения: PersonalizeModel
- Тип решения: рекомендация элемента
- Рецепт: aws-user-personalization
- Расширенная конфигурация — включите «Выполнить HPO». Остальные значения параметров оставьте без изменений.
Рецепт User-Personalization (aws-user-personalization) оптимизирован для всех сценариев рекомендации User_Personalization. При рекомендации предметов этот рецепт использует автоматическое исследование предметов.
Оценка метрик решения
Вы можете использовать автономные метрики для оценки производительности обученной модели, прежде чем создавать кампанию и давать рекомендации. Автономные метрики позволяют просматривать результаты изменения гиперпараметров решения или сравнивать результаты моделей, обученных на одних и тех же данных. Ссылка Чтобы получить показатели производительности, Amazon Personalize разделяет входные данные о взаимодействиях на набор для обучения и набор для тестирования. Разделение зависит от типа выбранного вами рецепта: для рецептов USER_SEGMENTATION обучающий набор состоит из 80 % данных о взаимодействиях каждого пользователя, а тестовый набор состоит из 20 % данных о взаимодействиях каждого пользователя. Для всех других типов рецептов обучающая выборка состоит из 90 % ваших пользователей и данных об их взаимодействиях. Тестовый набор состоит из оставшихся 10% пользователей и данных об их взаимодействиях. Затем Amazon Personalize создает версию решения с использованием обучающего набора. После завершения обучения Amazon Personalize предоставляет новой версии решения самые старые 90 % данных каждого пользователя из тестового набора в качестве входных данных.
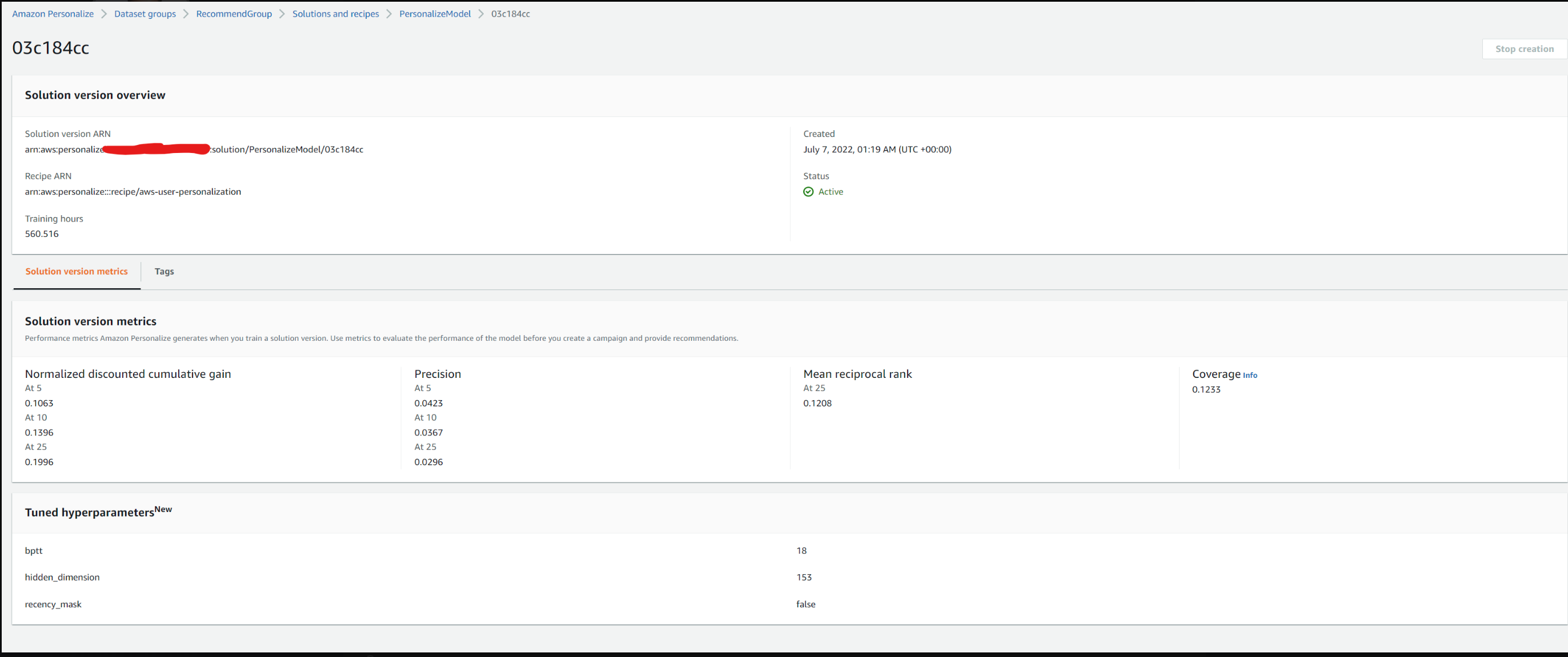
Вы получаете метрики для версии обученного решения выше, запустив следующий сценарий, который вызывает операцию GetSolutionMetrics с solutionVersionArn параметром
python projects/personalize/evaluate_solution.py --solution_version_arn <solution-version-arn>
2022-07-09 20:31:24,671 - evaluate - INFO - Solution version status: ACTIVE
2022-07-09 20:31:24,787 - evaluate - INFO - Metrics:
{'coverage': 0.1233, 'mean_reciprocal_rank_at_25': 0.1208, 'normalized_discounted_cumulative_gain_at_10': 0.1396, 'normalized_discounted_cumulative_gain_at_25': 0.1996, 'normalized_discounted_cumulative_gain_at_5': 0.1063, 'precision_at_10': 0.0367, 'precision_at_25': 0.0296, 'precision_at_5': 0.0423}
Вышеуказанные показатели описаны ниже:
coverage Метрика оценки, показывающая долю уникальных элементов, которые Amazon Personalize может порекомендовать для использования в вашей модели, от общего числа уникальных элементов в наборах данных «Взаимодействия» и «Элементы». Чтобы Amazon Personalize рекомендовал больше ваших товаров, используйте модель с более высоким показателем охвата. Рецепты, которые включают в себя исследование предметов, такие как Пользовательская персонализация, имеют более высокий охват, чем те, которые этого не делают, например, подсчет популярности означает взаимный рейтинг 25. Метрика оценки, которая оценивает релевантность рекомендации модели с наивысшим рейтингом. Amazon Personalize рассчитывает этот показатель, используя среднюю точность модели при ранжировании наиболее релевантной рекомендации из 25 лучших рекомендаций по всем запросам рекомендаций. Эта метрика полезна, если вы заинтересованы в рекомендации с наивысшим рейтингом нормализованного дисконтированного кумулятивного прироста (NCDG) в K (5/10/25). Метрика оценки, которая говорит вам об актуальности высоко оцененных рекомендаций вашей модели, где K – размер выборки из 5, 10 или 25 рекомендаций. Amazon Personalize рассчитывает это путем присвоения веса рекомендациям на основе их положения в ранжированном списке, где каждая рекомендация дисконтируется (присваивается меньший вес) с коэффициентом, зависящим от ее положения. Нормализованный дисконтированный кумулятивный выигрыш в K предполагает, что рекомендации, расположенные ниже в списке, менее релевантны, чем рекомендации, расположенные выше в списке. Amazon Personalize использует весовой коэффициент 1/log(1 + позиция), где верхняя часть списка — это позиция 1. Этот показатель вознаграждает релевантные элементы, которые появляются в верхней части списка, поскольку верхняя часть списка обычно привлекает больше внимания. Исходная точность при K Метрика оценки, которая показывает, насколько релевантны рекомендации вашей модели, исходя из размера выборки из K (5, 10 или 25) рекомендаций. Amazon Personalize рассчитывает эту метрику на основе количества релевантных рекомендаций из K лучших рекомендаций, деленного на K, где K равно 5, 10 или 25. Эта метрика вознаграждает точную рекомендацию релевантных элементов
Создание кампании для рекомендаций в реальном времени
Кампания — это развернутая версия решения (обученная модель) с выделенной выделенной емкостью транзакций для создания рекомендаций в реальном времени для пользователей вашего приложения. После завершения подготовки и импорта данных и создания решения вы готовы к развертыванию своей версии решения путем создания ссылки на кампанию AWS Personalize. Если вы получаете пакетные рекомендации, вам не нужно создавать кампанию.
$ python projects/personalize/deploy_solution.py --campaign_name MoviesCampaign --sol_version_arn <solution_version_arn> --mode create
2022-07-09 21:12:08,412 - deploy - INFO - Name: MoviesCampaign
2022-07-09 21:12:08,412 - deploy - INFO - ARN: arn:aws:personalize:........:campaign/MoviesCampaign
2022-07-09 21:12:08,412 - deploy - INFO - Status: CREATE PENDING
--config Можно передать дополнительный аргумент , чтобы установить параметры exploreWeight и exploreItemAgeCutOff для рецепта персонализации пользователя. Эти параметры по умолчанию равны 0,3 и 30,0 соответственно, если они не переданы (как в предыдущем примере). сценарий, как показано ниже:
$ python projects/personalize/deploy_solution.py --campaign_name MoviesCampaign --sol_version_arn <solution_version_arn> \
--config "{\"itemExplorationConfig\":{\"explorationWeight\":\"0.6\",\"explorationItemAgeCutOff\":\"100\"}}" --mode create
2022-07-09 21:12:08,412 - deploy - INFO - Name: MoviesCampaign
2022-07-09 21:12:08,412 - deploy - INFO - ARN: arn:aws:personalize:........:campaign/MoviesCampaign
2022-07-09 21:12:08,412 - deploy - INFO - Status: CREATE PENDING
Рекомендации
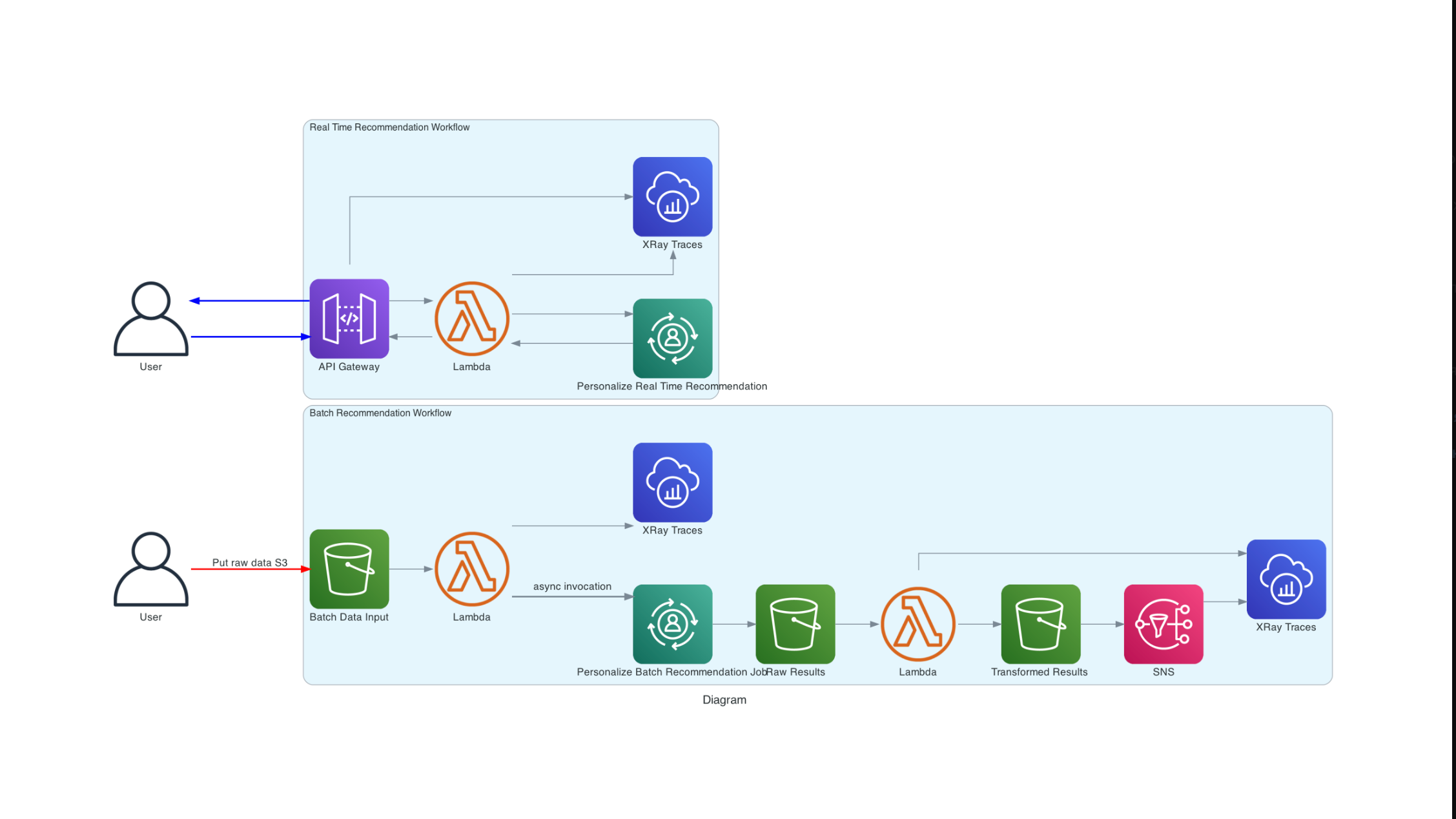
С помощью рецепта User-Personalization Amazon Personalize генерирует баллы для элементов на основе данных взаимодействия пользователя и метаданных. Эти оценки отражают относительную уверенность Amazon Personalize в том, будет ли пользователь взаимодействовать с элементом в следующий раз. Более высокие баллы означают большую уверенность.
Amazon Personalize оценивает все элементы в вашем каталоге относительно друг друга по шкале от 0 до 1 (обе включительно), так что общая сумма всех оценок равна 1. Например, если вы получаете рекомендации фильмов для пользователя и три фильма в наборе данных Items, их оценки могут быть 0,6, 0,3 и 0,1. Точно так же, если у вас есть 1000 фильмов в вашем инвентаре, у фильмов с наивысшей оценкой может быть очень низкая оценка (средняя оценка будет 0,001), но, поскольку оценка является относительной, рекомендации по-прежнему действительны.
Чтобы получить пакетные рекомендации, вы используете задание пакетного вывода. Задание пакетного вывода — это инструмент, который импортирует данные пакетного ввода из корзины Amazon S3, использует версию решения для создания рекомендаций по элементам, а затем экспортирует рекомендации в корзину Amazon S3. Входные данные могут быть списком пользователей или элементов или списком пользователей, каждый из которых содержит набор элементов в формате JSON. Используйте задание пакетного вывода, если вы хотите получить рекомендации по элементам партии для своих пользователей или найти похожие элементы в инвентаре.
Чтобы получить пользовательские сегменты, вы используете задание пакетного сегментирования. Задание пакетного сегмента — это инструмент, который импортирует ваши пакетные входные данные из корзины Amazon S3, использует вашу версию решения, обученную с помощью рецепта USER_SEGMENTATION, для создания пользовательских сегментов для каждой строки входных данных и экспортирует сегменты в корзину Amazon S3. Каждый пользовательский сегмент отсортирован в порядке убывания в зависимости от вероятности того, что каждый пользователь будет взаимодействовать с предметами в вашем инвентаре.
Входные данные в S3 должны быть файлом json с данными в определенном формате. В этом примере мы будем использовать образец, как в datasets\personalize\ml-25m\batch\input\users.json и загрузить его в корзину S3 recommendation-sample-data в формате movie-lens/batch/input/users.json.
Пакетное задание
Стек cloudformation, созданный ранее, должен был развернуть необходимые ресурсы для запуска пакетного задания, т. е. lambda-функции, которая срабатывает при добавлении входных данных в S3 и создает пакетное задание в Personalize. Lambda-функция автоматически запускает либо задание пакетного сегмента, либо задание пакетного вывода в зависимости от имени файла. Предполагается users.json, что файл имеет идентификаторы пользователей, для которых нам требуются рекомендации по элементам, и запустит задание пакетного вывода с использованием версии решения, указанной в качестве переменной среды lambda (определяемой с помощью параметров стека cloudformation). Мы будем использовать версию решения, обученную с помощью рецепта USER_PERSONALIZATION, описанного в предыдущем разделе.
С items.json другой стороны, файл запускает задание пакетного сегмента и должен иметь формат datasets/personalize/ml-25m/batch/input/items.json. Это вернет список пользователей с наивысшей вероятностью для рекомендации элементов.
Задание пакетного сегмента требует, чтобы решение было обучено с помощью рецепта USER_SEGMENTATION, и при использовании другого рецепта будет выдано сообщение об ошибке. Это потребует обучения нового решения с помощью этого рецепта и выходит за рамки этого руководства. Конфигурация лямбда должна выглядеть, как показано ниже, с триггером события, установленным как S3.
Вторая lambda-функция, которая запускает операцию преобразования, когда результаты пакетного задания добавляются в S3 из Personalize. В случае успеха в тему SNS, настроенную с использованием электронной почты в качестве конечной точки, отправляется уведомление для отправки оповещения по завершении рабочего процесса. Вывод пакетного задания из персонализации возвращает json в следующем формате:
{"input":{"userId":"1"},"output":{"recommendedItems":[....],"scores":[....]},"error":null}
{"input":{"userId":"2"},"output":{"recommendedItems":[....],"scores":[...]},"error":null}
......
.....
С преобразованием мы намерены вернуть структурированный набор данных, сериализованный в формате паркета (с быстрым сжатием), со следующей схемой:
- идентификатор пользователя: целое число
- Рекомендации: строка
Идентификатор фильма сопоставляется с названием и связанным с ним жанром и годом выпуска или с каждым пользователем, как показано ниже. Каждая рекомендация отделяется | разделителем.
userId Recommendations
0 1 Movie Title (year) (genre) | Movie Title (year) (genre) | ....
1 2 Movie Title (year) (genre) | Movie Title (year) (genre) | ....
......
При этом также используется lambda-слой со слоем DataWrangler, управляемым AWS, поэтому доступны библиотеки pandas и numpy. Конфигурация должна выглядеть, как показано ниже, с lambda-слоем и пунктом назначения в качестве SNS.
Чтобы запустить рабочий процесс задания пакетного вывода, скопируйте пример users.json пакетных данных в путь s3 ниже.
aws s3 cp datasets/personalize/ml-25m/batch/input/users.json s3://recommendation-sample-data/movie-lens/batch/input/users.json
При этом создается задание пакетного вывода с именем задания, в конец которого добавлена отметка unixtimestamp.
Мы должны получить уведомление по электронной почте, когда весь рабочий процесс завершится. Результаты пакетного задания и последующего преобразования должны быть видны в корзине с ключами movie-lens/batch/results/inference/users.json.out и movie-lens/batch/results/inference/transformed.parquet соответственно. Они также были скопированы и сохранены в репозитории в datasets/personalize/ml-25m/batch/results/users.json.out и datasets/personalize/ml-25m/batch/results/transformed.parquet
userId Recommendations
0 15000 Kiss the Girls (1997) (Crime) | Scream (1996) ...
1 162540 Ice Age 2: The Meltdown (2006) (Adventure) | I...
2 5000 Godfather, The (1972) (Crime) | Star Wars: Epi...
3 94 Jumanji (1995) (Adventure) | Nell (1994) (Dram...
4 4638 Inglourious Basterds (2009) (Action) | Watchme...
5 9000 Die Hard 2 (1990) (Action) | Lethal Weapon 2 (...
6 663 Crow, The (1994) (Action) | Nightmare Before C...
7 1030 Sister Act (1992) (Comedy) | Lethal Weapon 4 (...
8 3384 Ocean's Eleven (2001) (Crime) | Matrix, The (1...
9 34567 Lord of the Rings: The Fellowship of the Ring,...
10 50 Grand Budapest Hotel, The (2014) (Comedy) | He...
11 80000 Godfather: Part II, The (1974) (Crime) | One F...
12 110000 Manhattan (1979) (Comedy) | Raging Bull (1980)...
13 13 Knocked Up (2007) (Comedy) | Other Guys, The (...
14 20000 Sleepless in Seattle (1993) (Comedy) | Four We...Рекомендации в реальном времени
Вы также можете получать рекомендации в режиме реального времени от Amazon Personalize с помощью кампании, созданной ранее для рекомендаций фильмов. Чтобы повысить релевантность рекомендаций, включите контекстные метаданные для пользователя, такие как тип его устройства или время суток, когда вы получаете рекомендации или персонализированный рейтинг.
Интеграция шлюза API с lambda-сервером уже должна быть настроена, если облачное формирование было выполнено успешно. Мы настроили запрос метода так, чтобы он принимал параметр строки запроса user_id и определенную схему модели. Метод API можно интегрировать с Lambda, используя один из двух методов интеграции : интеграцию с прокси-сервером Lambda или интеграцию без прокси-сервера (пользовательскую) Lambda. По умолчанию мы использовали интеграцию Lambda Proxy в шаблоне cloudformation personalize_predict.yaml., что позволяет клиенту вызывать одну lambda-функцию в бэкэнде. Когда клиент отправляет запрос, API Gateway отправляет необработанный запрос в lambda-выражение, не обязательно сохраняя порядок параметров. Эти данные запроса включают заголовки запроса, параметры строки запроса, переменные URL-адреса, полезные данные и данные конфигурации API. Мы также можем использовать непрокси-интеграцию Lambda, установив для параметра шаблона APIGatewayIntegrationType значение AWS. Отличие от метода интеграции с прокси заключается в том, что, кроме того, нам также необходимо настроить шаблон сопоставления для сопоставления данных входящего запроса с запросом на интеграцию, как того требует внутренняя функция Lambda. В шаблоне cloudformation personalize_predict.yaml, это уже предопределено в свойстве RequestTemplates ресурса ApiGatewayRootMethod, которое преобразует параметр строки запроса user_id в свойство user_id полезных данных JSON. Это необходимо, потому что входные данные для лямбда-функции в лямбда-функции должны быть выражены в теле. Однако, поскольку тип по умолчанию установлен на AWS_PROXY, шаблон сопоставления игнорируется, поскольку он не требуется.
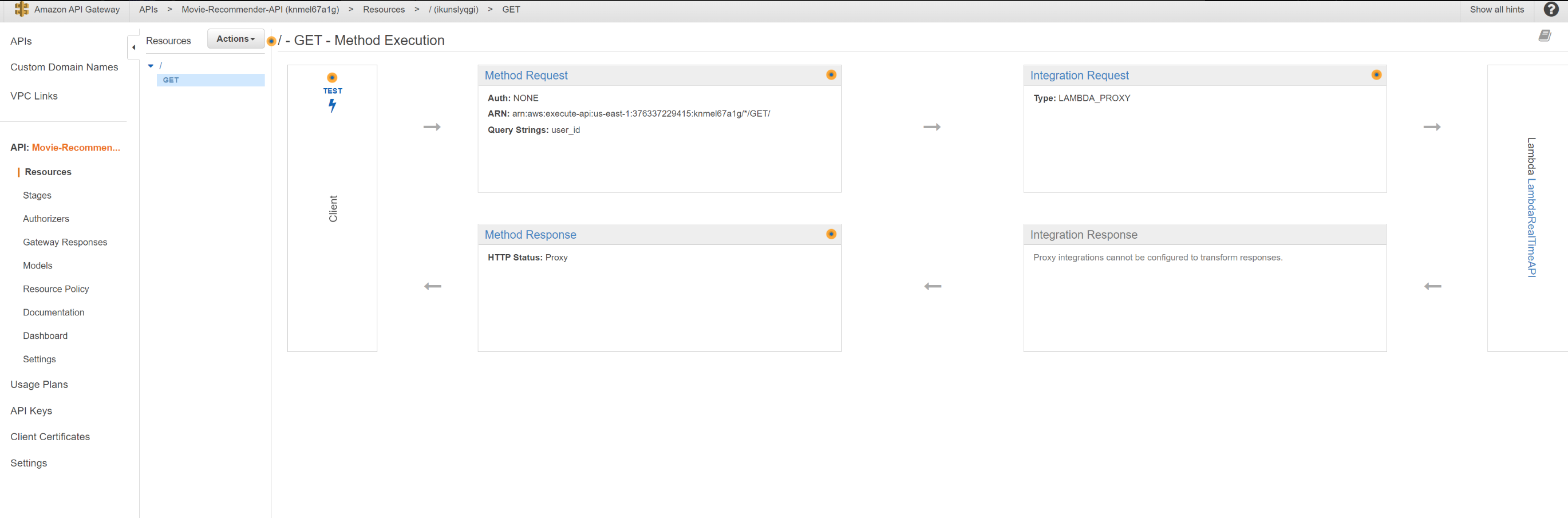
URL-адрес конечной точки API, который необходимо вызвать, должен быть виден из консоли на вкладке этапа.
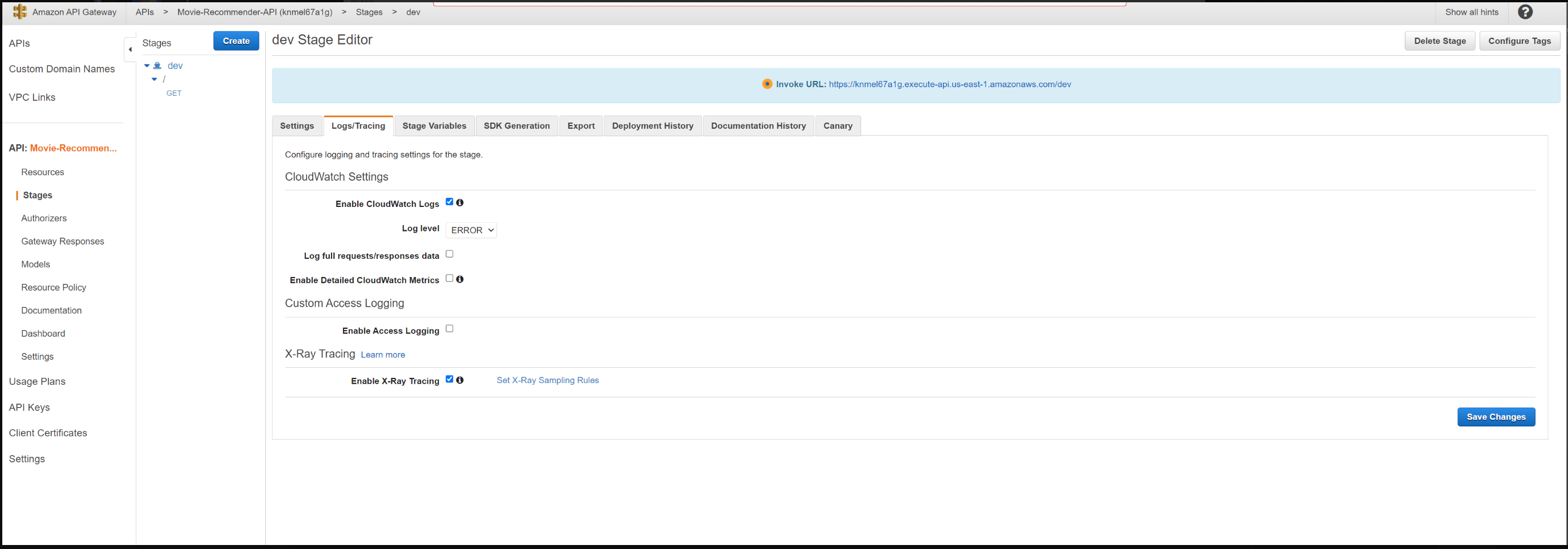
API можно протестировать, открыв браузер и введя URL-адрес в адресную строку браузера вместе с параметрами строки запроса. Например: https://knmel67a1g.execute-api.us-east-1.amazonaws.com/dev?user_id=5
Для мониторинга мы также настроили API-шлюз для отправки трассировок в XRay и журналов в Cloudwatch. Поскольку API интегрирован с одной lambda-функцией, на карте сервиса вы увидите узлы, содержащие информацию об общем затраченном времени и другие показатели производительности в сервисе шлюза API, сервисе Lambda и функции Lambda. Временная шкала показывает иерархию сегментов и подсегментов. Дополнительные сведения о времени запроса/ответа и неисправностях/ошибках можно найти, щелкнув каждый сегмент/подсегмент на временной шкале.
Запуск в локальном режиме
Мы можем запускать рекомендации локально, используя пользовательские сценарии в репозитории. Для получения рекомендаций в реальном времени запустите следующий сценарий, передав номер версии решения, номер кампании, имя роли, идентификатор пользователя и установив режим рекомендаций в режиме реального времени. Так, для пользователя 1 модель рекомендует фильмы на тему драмы/романтики.
python projects/personalize/recommendations.py --job_name Moviesrealtimerecommend --sol_arn <solution-arn> --role_name PersonalizeRole \
--campaign_arn <campaign-arn> --user_id 1 --recommendation_mode realtime
| Плохое образование (La mala educacion) (2004) | Драма | Триллер | |
| Вечное сияние чистого разума (2004) | Драма | Романтика | Научная фантастика |
| Никто не знает (Dare mo shiranai) (2004) | Драма | ||
| До свидания, Ленин! (2003) | Комедия, Драма | ||
| Человек без прошлого, The (Mies vailla menneisyyttä) (2002) | Комедия, Криминал, Драма | ||
| Амели (Fabuleux destin d'Amelie Poulain, Le) (2001) | Комедия, Романтика | ||
| Поговори с ней (Hable con Ella) (2002) | Драма, Романтика | ||
| Дневники мотоциклистов, The (Diarios de motocicleta) (2004) | Приключения, Драма | ||
| Очень долгая помолвка, A (Un long dimanche de fiancailles) (2004) | Драма, Мистика, Романтика, Военный | ||
| В настроении для любви (Фа Ён нин ва) (2000) | Драма, Романтика |
Пользователю 40 были рекомендованы криминальные/драматические фильмы.
| Убить Билла: Том. 2 (2004) | Действие | Драма, Триллер |
| Маленькая мисс Счастье (2006) | Приключения, Комедия, Драма | |
| Урвать (2000) | Комедия, Криминал, Триллер | |
| Будет кровь (2007) | Драма, Вестерн | |
| Последний король Шотландии, The (2006) | Драма, Триллер | |
| На игле (1996) | Комедия, Криминал, Драма | |
| Таинственная река (2003) | Криминал, Драма, Мистика | |
| Старикам тут не место (2007) | Криминальная драма | |
| Город грехов (2005) | Боевик, Криминал, Нуар, Мистика, Триллер | |
| Взвод (1986) | Драма, Война |
Пользователь 162540 интересен и, похоже, порекомендовал сочетание фильмов в жанрах детские/комедии и боевики/триллеры, основанные на взаимодействии с пользователями.
| Ледниковый период 2: Глобальное потепление (2006) | Приключения, Анимация, Детский, Комедия |
| Я легенда (2007) | Боевик, Ужасы, Фантастика, Триллер, IMAX |
| Шрек Третий (2007) | Приключения, Анимация, Детский, Комедия, Фэнтези |
| Форсаж 2 (Fast and the Furious 2, The) (2003) | Боевик, Криминал, Триллер |
| Пила 2 (2005) | Ужасы, Триллер |
| 300 (2007) | Боевик, Фэнтези, Война, IMAX |
| Бойцовский клуб (1999) | Боевик, Криминал, Драма, Триллер |
| Ночь в музее (2006) | Боевик, комедия, фэнтези, IMAX |
| Темный рыцарь, The (2008) | Боевик, криминал, драма, IMAX |
| Хэнкок (2008) | Боевик, Приключения, Комедия, Криминал, Фэнтези |
Мы также можем ограничить количество результатов, передав значение для arg --num_results, которое по умолчанию равно 10. Так, например, для --user_id 15000 мы можем получить 4 лучших результата.
| Поцелуй девушек (1997) | Криминал, Драма, Детектив, Триллер |
| Крик (1996) | Комедия, Ужасы, Мистика, Триллер |
| Фирма, The (1993) | Драма, Триллер |
| Дикие вещи (1998) | Криминал, Драма, Детектив, Триллер |
Для заданий пакетного вывода нам нужно запустить projects/personalize/recommendations.py скрипт. При этом используется имя корзины s3 по умолчанию recommendation-sample-data и ключ входных данных movie-lens/batch/input/users.json. Их можно переопределить, передав значение аргументам --bucket и соответственно. --batch_input_key. Вывод результатов будет сохранен movie-lens/batch/results/, но можно выбрать другой путь, передав путь в --batch_results_key аргумент
$ python projects/personalize/recommendations.py --job_name BatchInferenceMovies --num_results 25 --sol_arn arn:aws:personalize:.........:solution/PersonalizeModel/03c184cc --role_name PersonalizeRole
2022-07-10 05:50:55,409 - recommendations - INFO - Running batch inference job BatchInferenceMovies with config: {"itemExplorationConfig": {"explorationWeight": "0.3", "explorationItemAgeCutOff": "30"}}
2022-07-10 05:50:56,140 - recommendations - INFO - Response:
{
'batchInferenceJobArn': 'arn:aws:personalize:.......:batch-inference-job/BatchInferenceMovies',
'ResponseMetadata':
{
'RequestId': 'e9cf11a6-ce65-456b-b17c-a4c55d858e5a',
'HTTPStatusCode': 200,
'HTTPHeaders':
{
'date': 'Sun, 10 Jul 2022 04:50:57 GMT',
'content-type': 'application/x-amz-json-1.1',
'content-length': '110',
'connection': 'keep-alive',
'x-amzn-requestid': 'e9cf11a6-ce65-456b-b17c-a4c55d858e5a'
},
'RetryAttempts': 0
}
}
Файл результатов users.json.out должен храниться в указанной папке назначения movie-lens/batch/results/. Пример результатов хранится в atasets\personalize\ml-25m\batch\results\users.json.out формате, как описано здесь, и каждая строка содержит json с входным идентификатором пользователя и выходными идентификаторами рекомендуемых элементов, в данном случае 25 рекомендаций, поскольку мы указали это в вызове API.
Затем мы можем получить название фильма и жанры, сопоставив item_id заголовок с в файлеmovies.csv.