Использование Fastify для потоковой передачи данных из PostgreSQL

Визуализация информации — это ключ к быстрому и эффективному усвоению данных. Современные инструменты визуализации предлагают множество интерактивных возможностей, но за ними скрывается сложная система обработки данных. Визуализация опирается на наборы данных, хранящиеся в базах данных и доступные через API. При запросе к API, пользователи получают данные для визуализации.
Однако, что делать, если набор данных слишком большой или доступ к нему ограничен? Долгое время загрузки данных может значительно ухудшить пользовательский опыт. В этой статье мы рассмотрим, как эффективно передать огромный объем данных из базы данных PostgreSQL в клиентское приложение Reactjs, минуя проблемы производительности.
Создание базы данных
Для начала, создадим модель большой базы данных. Представим таблицу, которая хранит информацию о предметах и их местоположении на столах.
| Стол | Ряды | Описание |
| desks | 200,000 | В здании 200 тысяч рабочих столов |
| items | 10,000,000 | На столах 10 миллионов предметов |
Перед нами стает задача проанализировать следующий запрос:
WITH start_time AS (SELECT pg_sleep(1) AS start_time)
SELECT items.id, desks.name, row_number() OVER (ORDER BY items.id) AS row_number
FROM items
INNER JOIN desks ON desks.id = items.desk_id
CROSS JOIN start_timeДля моделирования реальной ситуации с медленной загрузкой данных, мы добавим искусственную задержку в 1 секунду.Вместо того, чтобы загружать весь набор данных сразу, мы воспользуемся потоковой передачей данных. Это позволит нам передавать данные по частям, не перегружая систему и не заставляя пользователей ждать долгой загрузки.
PostgreSQL предоставляет возможность использовать функцию pg_sleep() для искусственной задержки запросов. Это позволит нам смоделировать реальные ситуации с медленной загрузкой данных.
С помощью Docker мы можем быстро запустить сервер PostgreSQL и начать работу над нашим проектом.
docker run --rm -p 5432:5432 --name fastify-postgres -e POSTGRES_PASSWORD=postgres -d postgres:15-alpineДля нашего проекта нам нужна обширная база данных. Для этого мы воспользуемся скриптом node seed.js, доступным на GitHub, который заполнит таблицы тестовыми данными. Этот процесс займет несколько минут, но в результате мы получим необходимую нам базу данных.
Создание API
В качестве основы для нашего API мы выберем Fastify. Это быстрый и масштабируемый фреймворк, который позволит нам создать API в кратчайшие сроки. Однако, учитывая объем данных, с которыми мы работаем, стандартный подход к обработке запросов не подойдет. Нам нужно найти альтернативу, так как даже самый мощный сервер может столкнуться с ограничениями памяти при обработке огромного набора данных. Два возможных решения:
- Пакетирование: мы можем разбить запрос на части (пакеты) и возвращать результат поэтапно. Этот подход реализуется с помощью SQL-операторов LIMIT и OFFSET, без необходимости использования дополнительных библиотек.
- Потоковая передача: данные отправляются клиенту по мере их получения. Это более сложный, но более эффективный подход, позволяющий быстрее получать результаты.
Подход пакетирования может быть реализован с использованием предложений языка SQL LIMIT и OFFSET. Поэтому нам не нужна никакая внешняя библиотека для его реализации.
Потоковый подход сложнее, но он более эффективен и позволяет нам возвращать данные сразу после их получения. Быстрый поиск в Google покажет вам, что несколько библиотек могут помочь нам с этой задачей:
Для реализации потоковой передачи мы воспользуемся библиотекой pg-query-stream, которая обладает удобным API и хорошо зарекомендовала себя.
Настройка проекта
Теперь мы перейдем к настройке проекта. Для простоты, представленный код не оптимизирован для промышленного использования.
Далее мы покажем, как создать проект с нуля.
# Create the project
mkdir fastify-postgres-high-volume
cd fastify-postgres-high-volume
npm init -y
# Install Fastify
npm install fastify @fastify/postgres
# Install the PostgreSQL driver and utilities
npm install pg pg-query-stream JSONStreamСледующим нашим шагом будет создание файла app.js:
const fs = require('fs').promises
// Create the Fastify server
const app = require('fastify')({ logger: true })
// A simple route to serve the Reactjs application
app.get('/', async function serveUi (request, reply) {
reply.type('text/html')
return fs.readFile('./index.html')
})
// Register the PostgreSQL plugin to connect to the database
app.register(require('@fastify/postgres'), {
host: 'localhost',
port: 5432,
database: 'postgres',
user: 'postgres',
password: 'postgres',
max: 20
})
// Register some plugins to implement the API - we will see them later
app.register(require('./lib/batch'))
app.register(require('./lib/stream'))
// Start the server
app.listen({ port: 8080, host: '0.0.0.0' })Переходим к созданию основы lib/batch.js для плагина:
module.exports = async function (app, opts) {
app.get('/api/batch', queryBatch)
}
async function queryBatch (request, reply) {
const notImplemented = new Error('Not implemented')
notImplemented.statusCode = 501
throw notImplemented
}После основы потребуется создать lib/stream.js каркас платина:
module.exports = async function (app, opts) {
app.get('/api/stream', queryStream)
}
async function queryStream (request, reply) {
const notImplemented = new Error('Not implemented')
notImplemented.statusCode = 501
throw notImplemented
}В следующих разделах мы реализуем два плагина.Последним этапом нашего проекта станет создание файла `index.html`, который будет обслуживаться сервером. Пример кода простого приложения Reactjs в одном HTML-файле доступен на GitHub.
Запустим сервер с помощью команды с помощью команды:
node app.jsПосле запуска сервера, откроем браузер и перейдем по ссылке http://localhost:8080. Мы должны увидеть приложение index.html!
Теперь мы можем приступить к реализации бизнес-логики API.
Реализация подхода пакетной обработки
Подход пакетной обработки является одним из самых распространенных, так как он широко используется для разбиения результатов запроса на страницы.
Идея состоит в том, чтобы запускать запрос пакетами и возвращать фрагменты данных. Для этого нам потребуются два параметра от клиента:
limit: количество строк, возвращаемых в каждом фрагменте.offset: количество строк, которые следует пропустить перед возвратом результата пакетной обработки.
Мы можем получить эти значения из объекта request.query, добавив схему JSON к маршруту, который будет проверять входные данные.
app.get('/api/batch', {
schema: {
query: {
type: 'object',
properties: {
offset: { type: 'number', default: 0 },
limit: { type: 'number', default: 50_000 }
}
}
}
}, queryBatch)Таким образом будет выглядеть реализация queryBatch:
async function queryBatch (request, reply) {
// Get the input from the client
const offset = request.query.offset
const batchSize = request.query.limit
// The slow query we want to run
const slowQuery = `
WITH start_time AS (SELECT pg_sleep(1) AS start_time)
SELECT items.id, desks.name, row_number() OVER (ORDER BY items.id) AS row_number
FROM items
INNER JOIN desks ON desks.id = items.desk_id
CROSS JOIN start_time
OFFSET $1
LIMIT $2;
`
// Run the query and return the result
const result = await this.pg.query(slowQuery, [offset, batchSize])
return result.rows
}Когда клиент вызывает маршрут /api/batch, сервер выполнит запрос slowQuery и вернет результат.
Объект this.pg представляет собой декоратор приложения, внедренный плагином @fastify/postgres, и это пул PostgreSQL.
Теперь мы можем протестировать API, выполнив команду:
curl http://localhost:8080/api/batch?offset=0&limit=10000Сервер должен вернуть первые 10 000 строк результата slowQuery. Обратите внимание, что ответ появится в терминале не позднее, чем через 1 секунду.
Реализация потокового подхода
Потоковый подход может быть сложнее в реализации, но благодаря библиотеке pg-query-stream это не так.
Идея состоит в том, чтобы передавать результат запроса клиенту по мере получения данных. Для этого мы создадим поток, который считывает результат запроса и передает его клиенту. Единственный параметр, который нам нужен от клиента, это limit, так как мы собираемся передавать результат потоком и не должны пропускать данные.
Мы можем получить значение limit из объекта request.query, добавив схему JSON к маршруту, который проверяет входные данные:
app.get('/api/stream', {
schema: {
query: {
type: 'object',
properties: {
limit: { type: 'number', default: 50_000 }
}
}
}
}, queryStream)Теперь мы можем реализовать функцию queryStream:
const QueryStream = require('pg-query-stream')
const JSONStream = require('JSONStream')
async function queryStream (request, reply) {
// Get the PostgreSQL client from the pool
const client = await this.pg.connect()
// The slow query we want to run
const slowQuery = `
WITH start_time AS (SELECT pg_sleep(1) AS start_time)
SELECT items.id, desks.name, row_number() OVER (ORDER BY items.id) AS row_number
FROM items
INNER JOIN desks ON desks.id = items.desk_id
CROSS JOIN start_time
LIMIT $1;
`
// Create a new stream that runs the query
const query = new QueryStream(slowQuery, [request.query.limit], {
highWaterMark: 500
})
// Run the query and return the stream
const stream = client.query(query)
stream.on('end', () => { client.release() })
return stream.pipe(JSONStream.stringify())
}Давайте проанализируем код:
- Мы создаем нового клиента PostgreSQL, вызывая метод
this.pg.connect(), который возвращает доступный объектclientиз пула. - Мы создаем новую реализацию
QueryStream, которая будет работать так же, как и пакетная реализация, за исключением условияOFFSET:
- Важно отметить, что нам нужно установить опцию `highWaterMark` для чтения достаточного количества строк из базы данных. Значение по умолчанию - 16, что слишком мало для нашего случая!
- Мы создаем новый поток, вызывая
client.query(query), который выполнит запрос. - Мы должны помнить о необходимости прислушиваться к событию
end, чтобы освободитьclientобратно в пул. - Мы возвращаем поток в
JSONStream, который преобразует результат в строку JSON. Fastify автоматически управляет потоком и отправляет результат клиенту.
Теперь мы можем протестировать API, выполнив команду:
curl http://localhost:8080/api/stream?limit=10000Сервер должен вернуть первые 10 000 строк результата slowQuery.
Вы должны увидеть, как результат передается на терминал, как только сервер получает данные из базы данных. Задержек между строками нет, поэтому клиент может начать рендеринг данных, как только получит их. Эффект всплывающего окна исчез.
Создание клиента
Теперь, когда API запущен и работает, мы можем создать клиента для тестирования API и увидеть эффект двух подходов. Здесь мы воспользуемся приложением Reactjs, которое создали ранее.
Это простое приложение со следующими функциями:
- Входные данные для глобальной установки для приложения количества строк, которые необходимо извлечь из вызовов API.
- Кнопка вызова маршрута
/api/batchи отображения времени, необходимого для получения результата.
- Входные данные для установки максимального количества строк, которые нужно получить для каждого пакета: мы не можем получить все строки за один раз, иначе на сервере закончится память!
- Кнопка вызова маршрута
/api/streamи отображения времени, необходимого для получения результата.
Представляем скриншот приложения:
Давайте попробуем нажать на кнопки посмотрим, что произойдет!
Результаты
Если мы выберем кнопку со значением по умолчанию, то результат который мы увидим будет таким:

Также не выпускаем из виду количество времени, затрачиваемого на анализ данных в браузере.
Перед тем, как проанализировать результаты, попробуем изменить входные данные и просмотрим изменения результатов.
Что произойдет, если мы увеличим размер партии до 350 000?
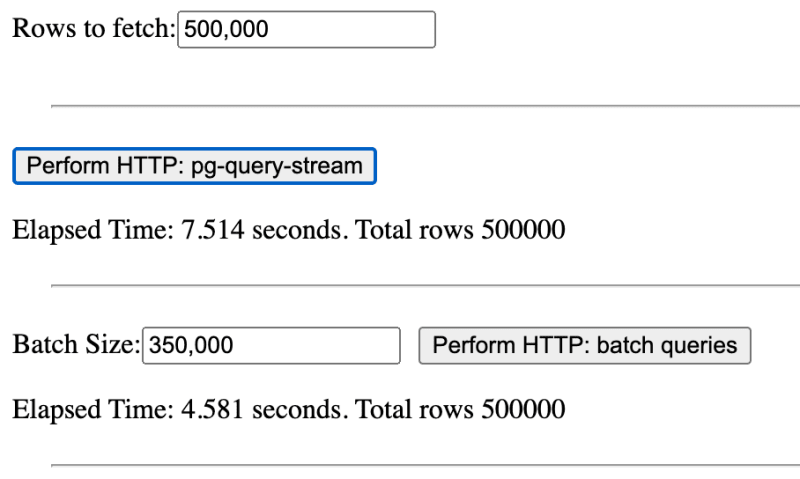
Пакетный подход намного быстрее и превосходит потоковый метод!
Перейдем к анализу результатов:
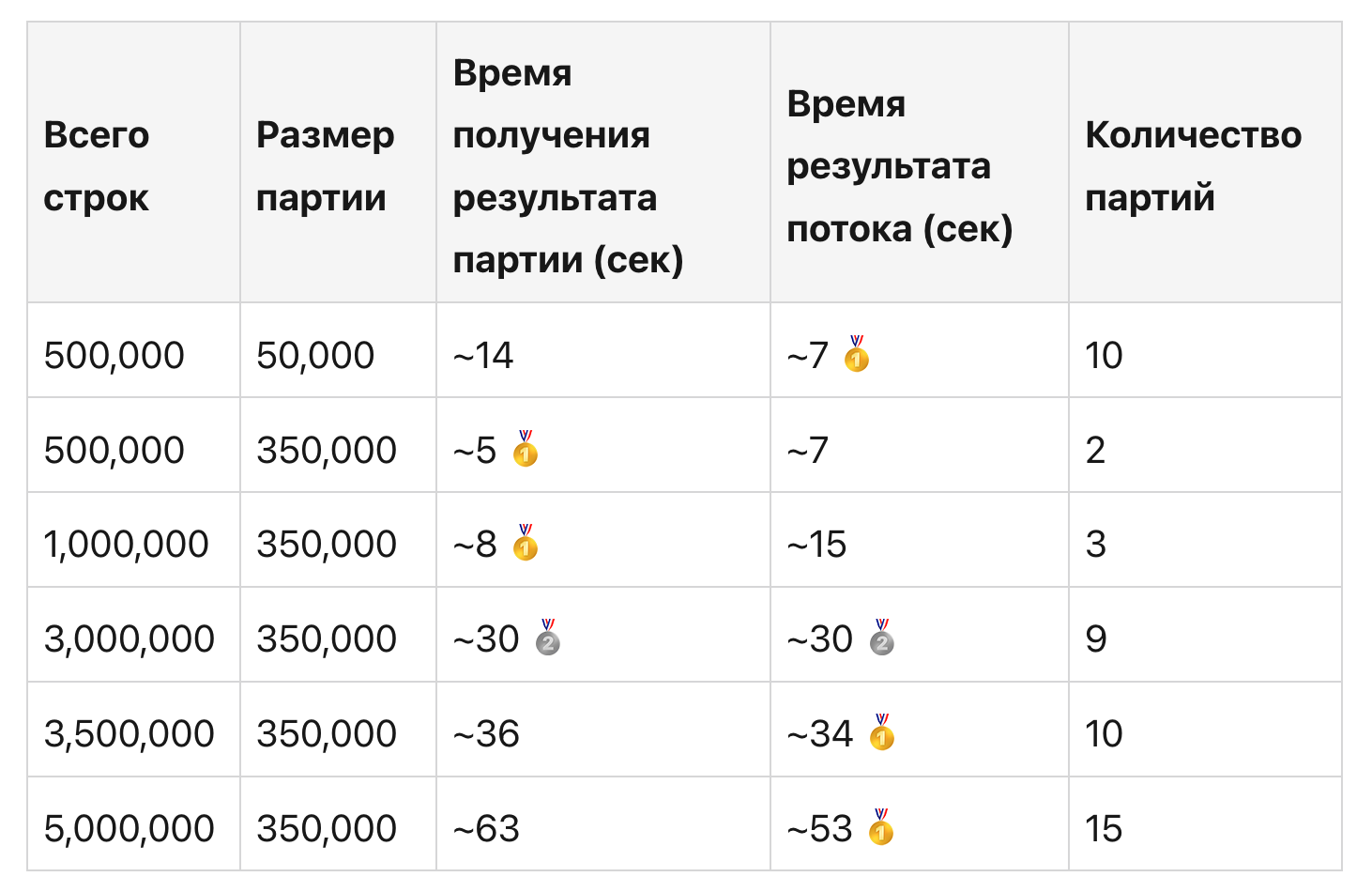
Результаты впечатляют! Потоковый подход оказывается быстрее пакетного, когда количество пакетов (рассчитывается как totalRows / batchSize) больше или равно 10.
Мы видим, что пакетный подход делает два запроса к серверу, а потоковый – только один. Но время загрузки контента (Content Download) значительно больше для потокового подхода.
Попробуем увеличить опцию highWaterMark для QueryStream до 5 МБ.
const query = new QueryStream(slowQuery, [request.query.limit], {
highWaterMark: 5e6
})Перезапустим тесты. Общее время для потокового подхода (включая разбор тела) должно сократиться до ~4/5 секунды. Время загрузки контента теперь составляет ~2 секунды, то есть мы ускорили загрузку данных в два раза!
Теперь перезапустим третий тест с новым значением highWaterMark. Потоковая передача завершится примерно за 10 секунд, сократив время на 1/3!
Это означает, что правило о 10 пакетах не является универсальным и не всегда позволяет потоковому подходу победить. Все зависит от настройки потока.
Итак, сравним скорость двух подходов:
- Пакетирование: Если у нас небольшое количество пакетов, пакетный подход быстрее в реализации и запуске. Однако мы не можем сильно увеличивать размер пакета, чтобы уменьшить количество пакетов. Пакет размером 350 000 строк извлек ~30 МБ данных - это слишком много для одного набора, но помогло нам понять принцип.
- Потоковая передача: Не всегда самый быстрый подход, если мы не настроим поток правильно. Но это самый эффективный подход, так как он не требует загрузки всех данных в память перед отправкой клиенту. Кроме того, это более стабильный подход в долгосрочной перспективе, так как он не требует изменения размера пакета при росте набора данных и позволяет создавать более отзывчивые приложения пользовательского интерфейса.
Заключение
В этой статье мы увидели, как передавать огромные объемы данных из базы данных PostgreSQL в клиент Reactjs! Мы изучили два разных подхода и увидели, как реализовать их с помощью Fastify и библиотеки pg-query-stream.
Мы провели сравнительную оценку производительности двух подходов и увидели, что потоковый подход является наиболее эффективным и стабильным в долгосрочной перспективе, даже если он не всегда самый быстрый.
Мы проанализировали результаты и нашли связь между каждым подходом и его производительностью. Теперь вы можете выбрать лучший подход для вашего варианта использования, зная плюсы и минусы каждого из них!