Как использовать Python и Xpath для поиска данных в html

Платформы онлайн-обучения и соревнований по Kaggle обычно предоставляют вам полный (и чистый) набор данных. На практике, первый шаг проекта машинного обучения - получить в свои руки необходимые данные. Очистка веб-страниц или извлечение данных с веб-сайтов является одним из инструментов для достижения этой цели.
XPath может использоваться для анализа содержимого с веб-сайта. Он расшифровывается как «XML Path Language». Для просмотра веб-страниц нас интересует XPath, поскольку он может использоваться для анализа HTML.
Веб-сайты используют HTML для отображения контента, который вы видите на веб-странице. HTML - это язык разметки, который использует «теги» для определения того, как веб-сайт просматривается в вашем браузере. Компоненты документа HTML, который мы ищем, называются «узлами». Выражения XPath работают путем определения «пути» для навигации по HTML-сайту и выбора нужных вам узлов.
Чтобы представить основы XPath, мы рассмотрим, как мы можем использовать его для получения цитат из «Звездных войн» с этого сайта. Могут помочь некоторые базовые знания HTML, но знать его не обязательно.
Краткое примечание об ответственном анализе и отказе от ответственности. Не следует пытаться получать данные с сайтов, которые не допускают очистку. Вы можете проверить «robots.txt» сайта, чтобы увидеть его политику в отношении очистки веб-страниц. Цель этой статьи - помочь облегчить обычно ручное исследование и сбор данных. Не пытайтесь получить доступ к данным, на которые у вас нет полномочий. Я не являюсь владельцем сайта или данных, представленных здесь - он просто используется в качестве примера.
Получение HTML сайта
Прежде чем мы сможем написать какие-либо запросы XPath, нам нужно получить HTML-документ целевого веб-сайта. Для этого мы просто напишем пару строк, которые извлекают HTML-код с сайта и сохраняют его на нашем компьютере.
# getting the data
import requests
from urllib.request import urlopen
from lxml import etree
# get html from site and write to local file
url = 'https://www.starwars.com/news/15-star-wars-quotes-to-use-in-everyday-life'
headers = {'Content-Type': 'text/html',}
response = requests.get(url, headers=headers)
html = response.text
with open ('star_wars_html', 'w') as f:
f.write(html)
# read local html file and set up lxml html parser
local = 'insert_browser_file_path_here'
response = urlopen(local)
htmlparser = etree.HTMLParser()
tree = etree.parse(response, htmlparser)
Здесь мы использовали «запросы», чтобы получить копию HTML сайта и записали ее в локальный файл «star_wars_html». Затем вам нужно открыть этот файл в браузере и скопировать увиденную там ссылку в переменную «local».
Для анализа HTML с помощью XPath мы будем использовать модуль lxml для Python. Мы создали «дерево», которое позволит нам создавать запросы XPath и получать нужные данные из сохраненного HTML-документа.
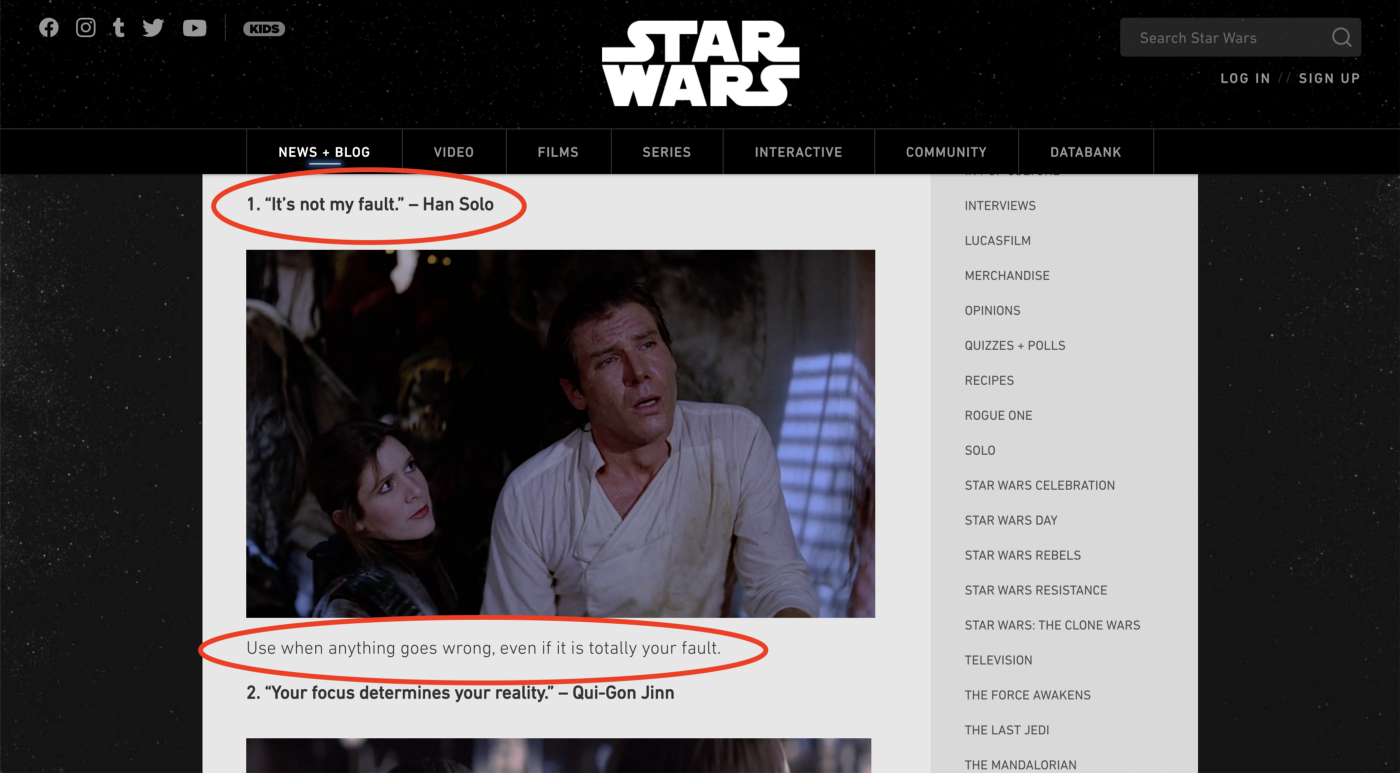
Нашей целью будет получить все цитаты и текст под каждой цитатой.
Введение в написание выражений XPath
Тестирование и объяснение простого выражения
tree.xpath('//p/strong/text()')
Мы будем помещать все наши выражения в функцию «tree.xpath». В данном случае выражение «//p/strong/text()». Вы также можете проверить эти выражения в вашем браузере. Просто перейдите к инструменту инспектора (щелкните правой кнопкой мыши и "проверить" в Chrome) и нажмите CMD + F. Вы можете ввести свое выражение XPath в появившейся строке поиска.
Чтобы найти HTML-код, соответствующий той части сайта, которую вы хотите, нажмите кнопку мыши в левом верхнем углу панели «Проверка», а затем наведите курсор мыши на нужную строку. Это выделит связанный HTML на вашей панели. Здесь мы видим, что каждая «цитата» находится внутри тега strong, который находится внутри тега р.
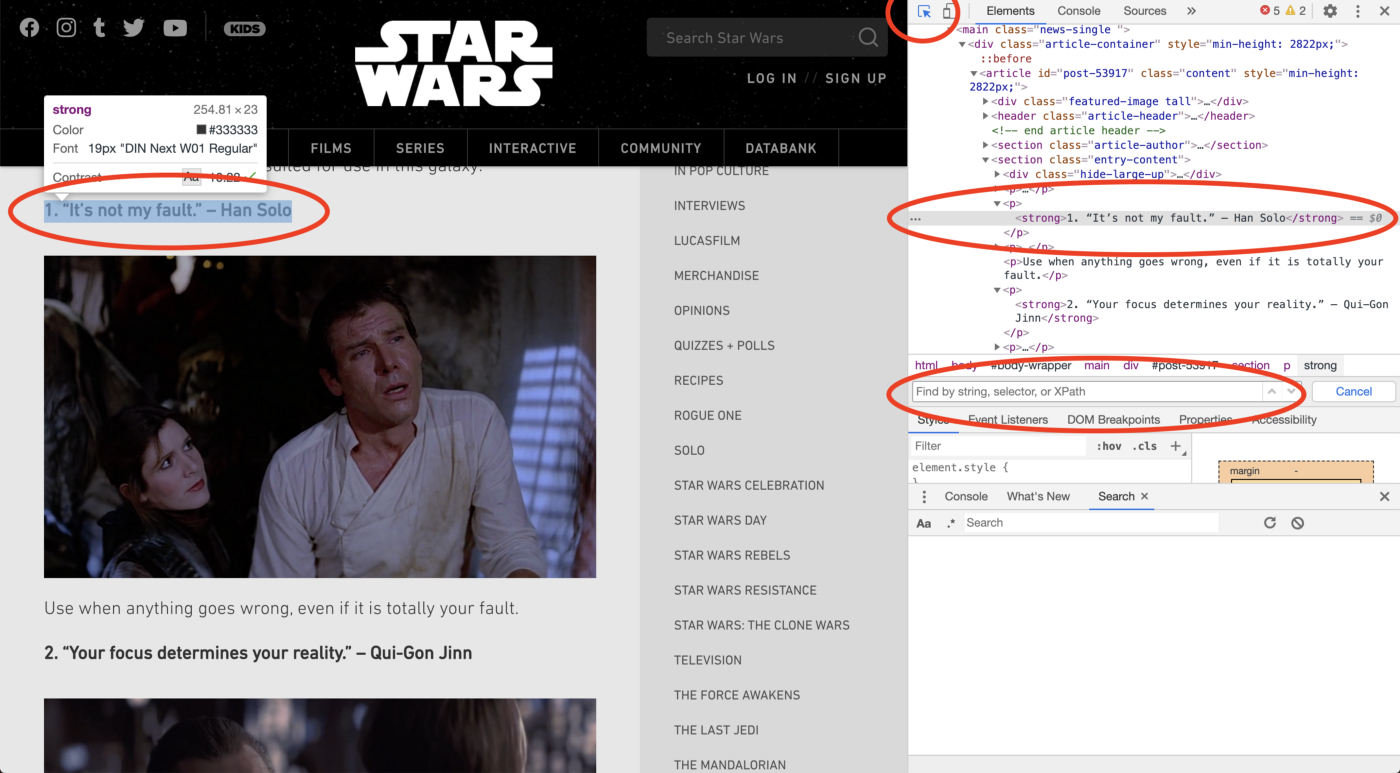
Теперь давайте разберем «//p/strong/text()»:
//- это означает поиск по всему HTML-документу (начните с корня сайта и найдите все, что соответствует искомому выражению)p- это HTML-тег, который содержит другой тег с текстом, который мы ищем.strong- это HTML-тег, который на самом деле содержит текст, который мы ищемtext()- это получение текстового узла.
Результат этого выражения выглядит так:

Ура! Мы написали наше первое выражение XPath и получили список цитат с сайта!
Фильтрация для получения контента по ключевому слову
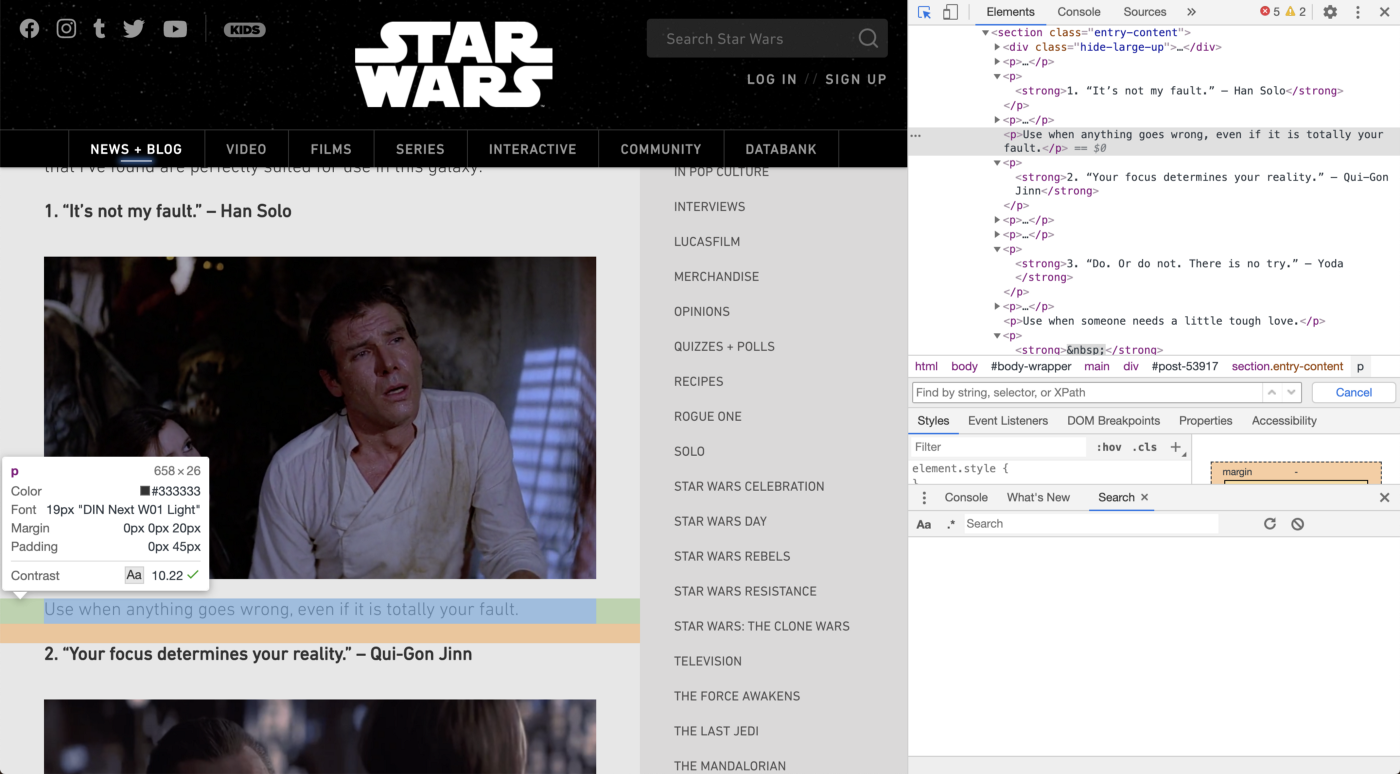
Давайте попробуем получить текст под каждой цитатой. Используя инструмент проверки, мы видим, что он попадает под тег «p». Тем не менее, нет никаких других отличительных особенностей, основанных на HTML.
В этом случае нам повезло, потому что все эти тексты содержат ключевое слово. Все они начинаются со слова «use». Чтобы захватить их, мы напишем следующее выражение:
tree.xpath('//p[contains(text(),"Use")]/text()')
Давайте разберем, что мы видим:
[]- вы можете видеть, что часть выражения заключена в квадратные скобки. Это называется «предикатом» и используется для фильтрации узлов на основе критериев, указанных внутри него. В этом случае он будет отфильтровывать узлы, которые обычно выводит «//p».contains()- это ищет первый аргумент для случаев, когда второй аргумент присутствует. В этом случае мы ищем весь текст с надписью «use».
Это выражение дает нам список всего текста в тегах «p», который содержит слово «use».

Фильтрация нежелательного контента
На первом скриншоте видно, что мы также получили «\xao» в списке результатов. Чтобы убедиться, что мы не получаем экземпляры этого, мы напишем это выражение:
tree.xpath('//p/strong[not(contains(text(),"\xa0"))]/text()')
Здесь мы используем один новый фрагмент синтаксиса XPath:
not()- принимает указанное логическое условие и возвращает значение «False».
Эта модификация позволяет нашему начальному выражению XPath отфильтровывать весь текст из узлов, возвращаемых «//p/strong» с «\xao», что дает нам чистый список.

Получение узлов, которые начинаются с ключевого слова
Допустим, мы хотели получить ссылки на все изображения, использованные в посте.
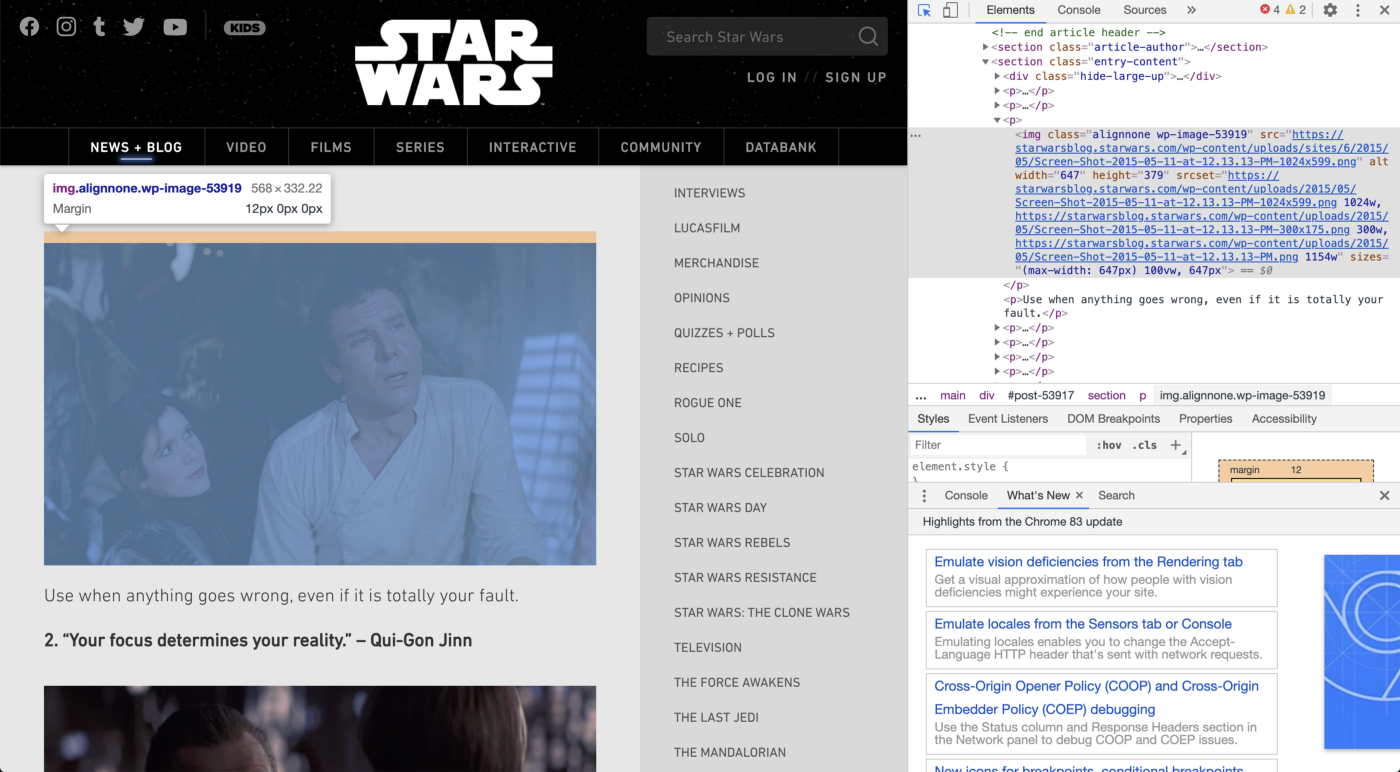
Здесь все изображения находятся в теге «img». На сайте есть другие изображения, поэтому, чтобы получить только те, которые связаны с каждой цитатой, нам нужно получить те, которые имеют значение класса, начинающееся с «alignnone».
Для этого мы пишем это выражение:
tree.xpath('//img[starts-with(@class, "alignnone")]/@src')
Что нового здесь:
starts-with- работает так же, как «contains», за исключением того, что на этот раз мы смотрим на начало узлов, указанных первым аргументом, для подстроки, предоставленной вторым аргументом.@- это как выбрать «атрибут» с помощью XPath. Атрибуты представляют собой фрагменты HTML после открывающего тега, который изменяет функцию исходного элемента.
С помощью этого выражения мы хотим найти атрибуты @class тегов «img», чтобы увидеть, есть ли у них «alignnone» в начале. Затем мы хотим вернуть атрибут «@src», который содержит URL-адрес изображения. Выражение возвращает список URL-адресов изображений, которые нам нужны.
Получение узлов на основе отношений
Теперь скажите, что мы хотим получить все метаданные для этой статьи, такие как дата публикации и категория.
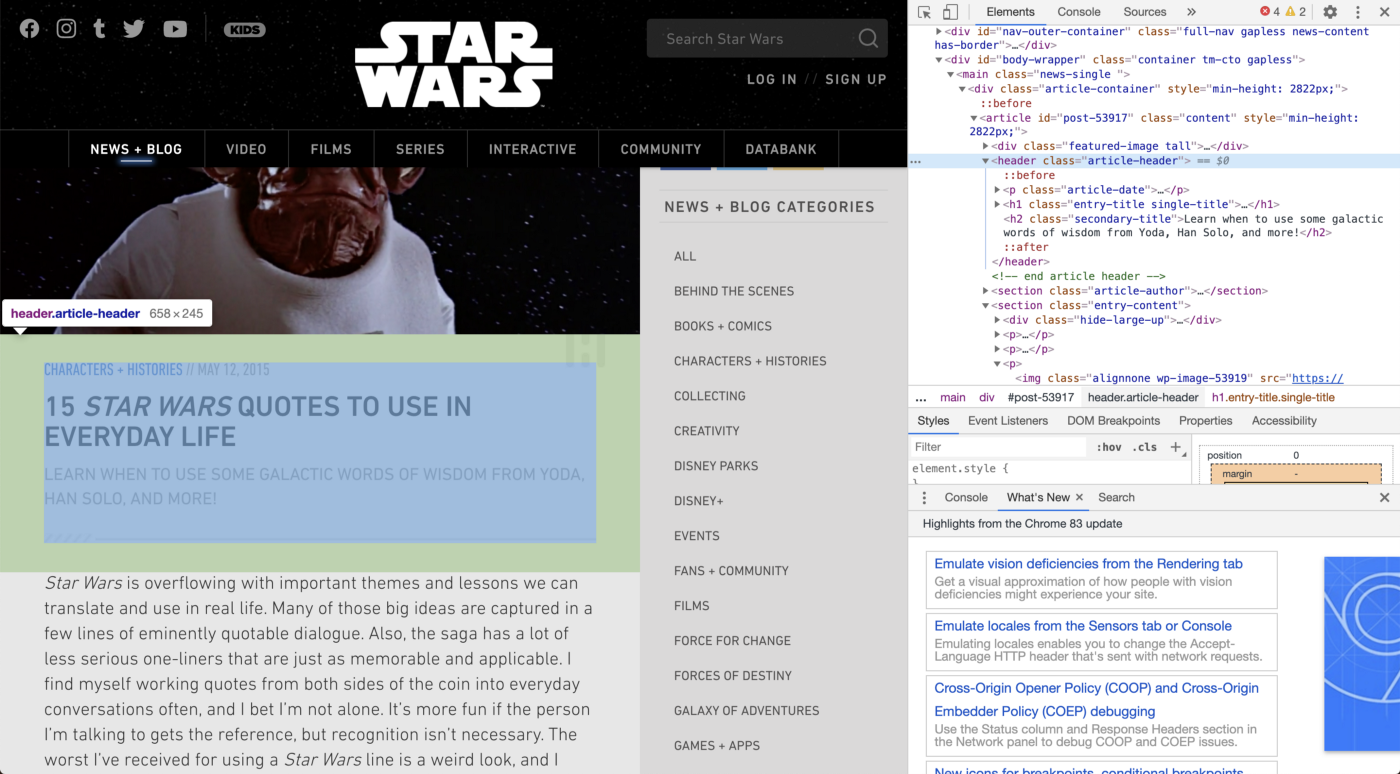
Здесь мы видим, что дата, заголовок, подзаголовок и категория попадают под тег «header» с классом «article-header». Другая особенность XPath позволяет вам перемещаться по HTML, основываясь на «осях» или на том, как соотносятся теги. Мы уже сделали это с помощью «//p/strong». Здесь «strong» является прямым потомком «р».
Но что, если мы хотим получить все виды тегов-потомков, а не только тот, который мы указываем?
Мы будем использовать это выражение:
tree.xpath('//header[@class="article header"]/descendant::node()/text()')
Две новые вещи здесь:
[@something=“something” ]- здесь вместо того, чтобы искать значение атрибута, которое содержит или начинается с чего-то, мы прямо указываем в предикате, что хотим точное совпадение.descendant::node()- позволяет нам искать все узлы, которые идут после предыдущего тега.
В этом случае выражение позволяет нам получить текст, связанный с тегами p, h1 и h2, которые идут после начального тега заголовка. Это дает нам нужные метаданные статьи.

Получение узлов на основе индекса
Теперь давайте попробуем разместить соответствующие статьи в нижней части страницы.
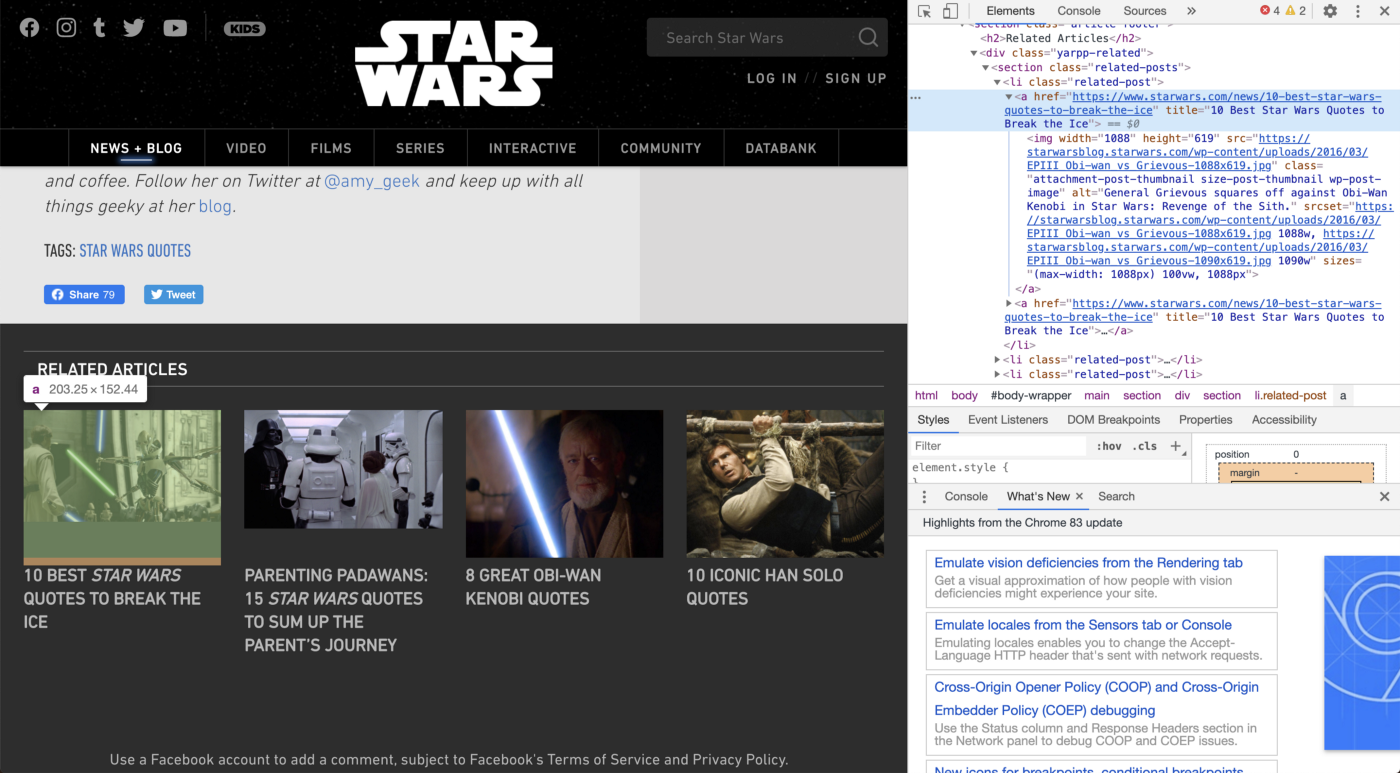
Мы видим, что ссылки на каждый связанный пост находятся в теге «a» под тегом «li» с классом «related-post». Мы попробуем это выражение:
tree.xpath('//li[@class="related-post"]/a/@href')

Мы захватили все ссылки, найдя значения «@href» в HTML, но похоже, что мы получаем дублированные данные. Выражения XPath будут захватывать каждый узел, который соответствует вашим заданным условиям, поэтому он захватывает оба значения «@href», связанные с нашим целевым элементом «li».
Чтобы исправить это, мы напишем это выражение XPath:
tree.xpath('//li[@class="related-post"]/a[1]/@href')
Все, что мы здесь сделали, это добавили значение индекса «[1]». Это изменяет выражение XPath, чтобы выбрать только первый экземпляр «a», который он находит внутри элемента «li». В отличие от Python, индекс начинается с «1» при использовании выражений XPath, поэтому не пытайтесь писать «[0]», когда вам нужен первый элемент.
XPath обладает гораздо большей функциональностью, чем описанная здесь. Вы можете проверить их полную документацию здесь и взглянуть на эту шпаргалку с devhints.io.
 Игорь Игоревич
02.11.2020 в 22:42
Игорь Игоревич
02.11.2020 в 22:42
 LegGnom
02.11.2020 в 23:23
LegGnom
02.11.2020 в 23:23
 Бабанер ка
21.02.2022 в 20:22
Бабанер ка
21.02.2022 в 20:22
 Kate Shmygol
23.02.2024 в 21:43
Kate Shmygol
23.02.2024 в 21:43