Как визуализировать модели причинно-следственных связей с помощью интуитивно понятных таблиц условной вероятности
В этой статье мы рассмотрим, как создать интуитивно понятные и полные таблицы условной вероятности для визуализации и понимания моделей причинно-следственных связей в 1 строке кода Python.
К концу этой статьи вы сможете генерировать визуально богатые таблицы условной вероятности всего за одну строку Python, и у вас будет полный доступ к исходному коду и документации.
Причинно-следственный вывод является горячей темой на данный момент, но различные существующие библиотеки могут быть усложнены противоречивой документацией и примерами, и большинство доступных статей и сообщений сосредоточены на конкретном аспекте причинно-следственного вывода, не охватывая все, что нужно знать специалисту по данным.
Краткий обзор моделей причинно-следственных связей
Модель причинного вывода состоит из двух ключевых компонентов:
- «Направленный ациклический граф» (DAG), который описывает, что вызывает то, что иногда называют диаграммой причинного вывода.
- Набор «Таблиц условной вероятности» (CPT), которые описывают вероятности перехода от одного узла к другому.
Вот пример, который показывает, как оба компонента работают вместе в модели причинного вывода (числа в ячейках — это вероятности).
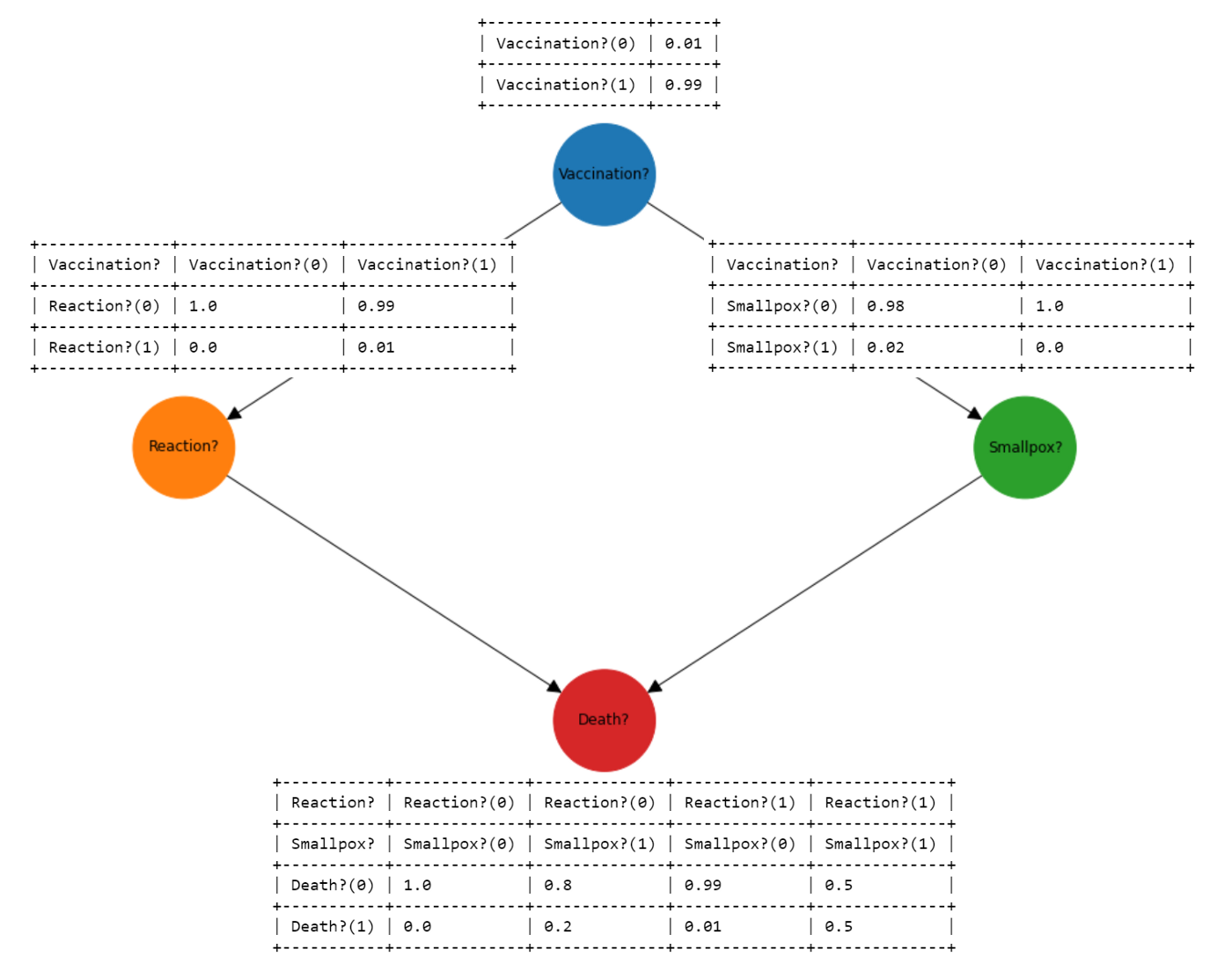
Начало работы
Начнем с выбора некоторых данных для моделирования.
Выбранные мной данные относятся к влиянию наличия диплома на заработную плату и были получены из бесплатного репозитория машинного обучения UCI (https://archive.ics.uci.edu/ml/datasets/census+income).
import pandas as pd
from IPython.display import display
df_census = pd.read_excel("data/census_income.xlsx")
display(df_census.head())
display(df_census.describe().T)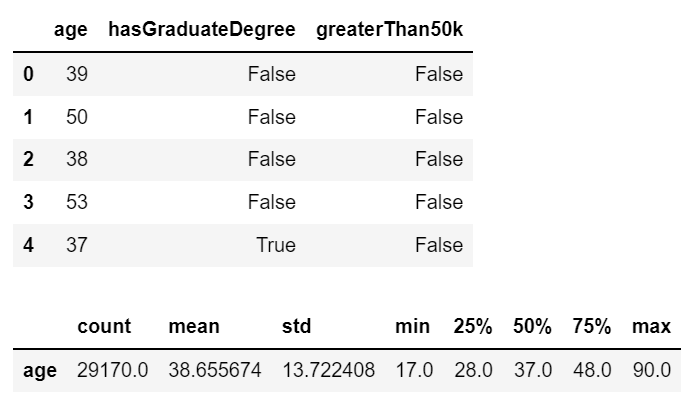
Построение причинно-следственной модели
Я решил построить причинно-следственную модель с использованием pgmpy библиотеки (https://pgmpy.org/) следующим образом
from pgmpy.models import BayesianNetwork
census_model = BayesianNetwork([('age', 'hasGraduateDegree'),
('age', 'greaterThan50k'),
('hasGraduateDegree', 'greaterThan50k')])Очень полезно визуализировать причинно-следственные связи и структуру
dag_tools.display_pyvis_model(census_model, figsize=(400,400))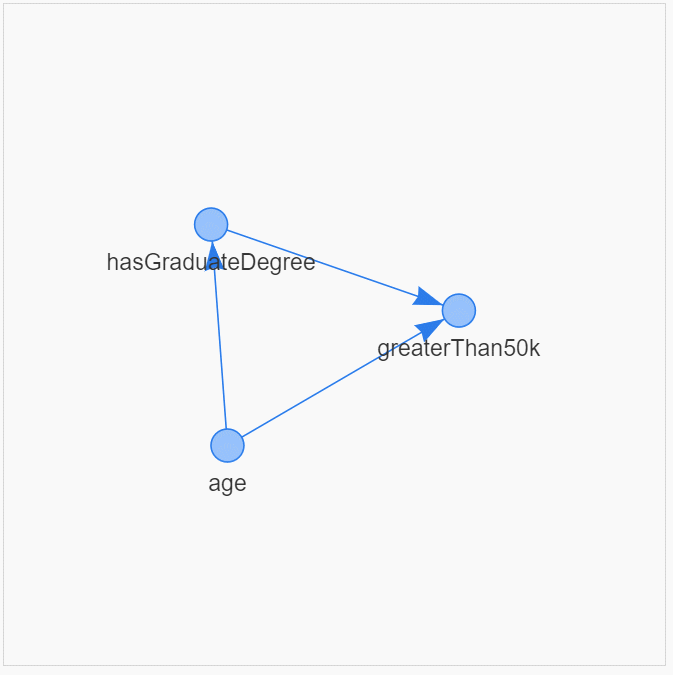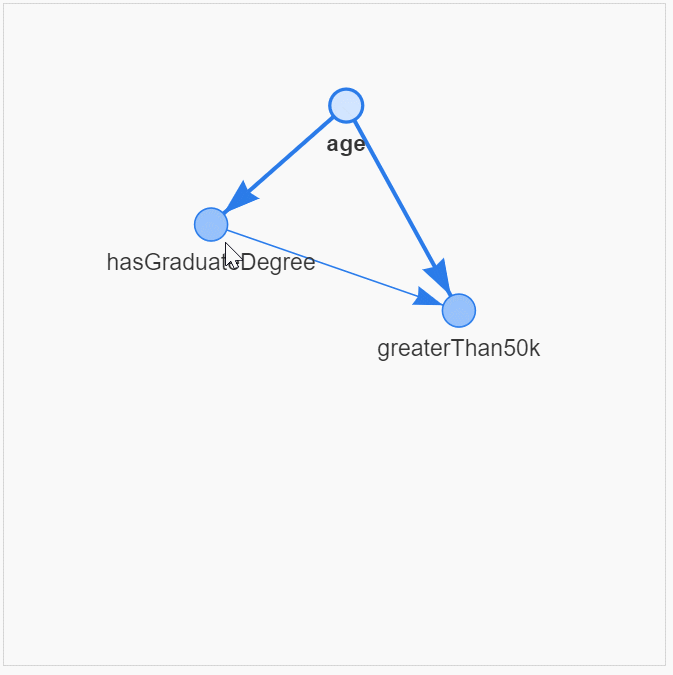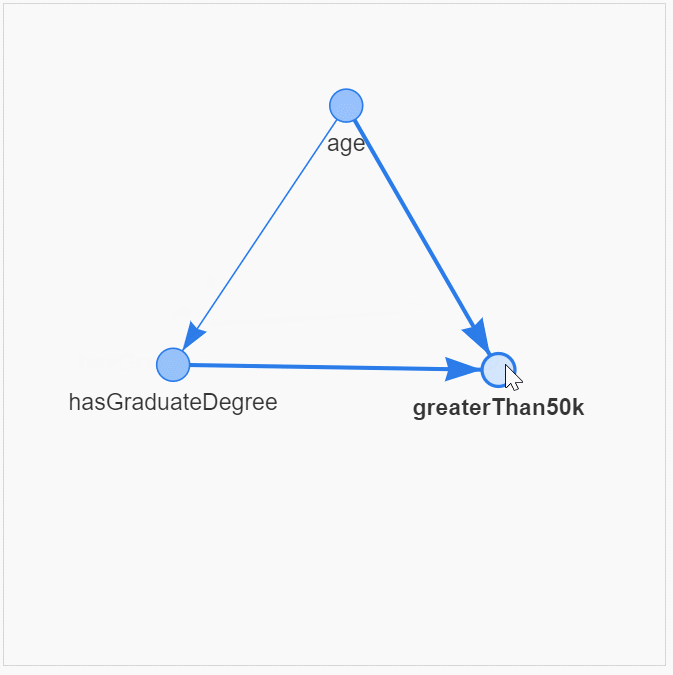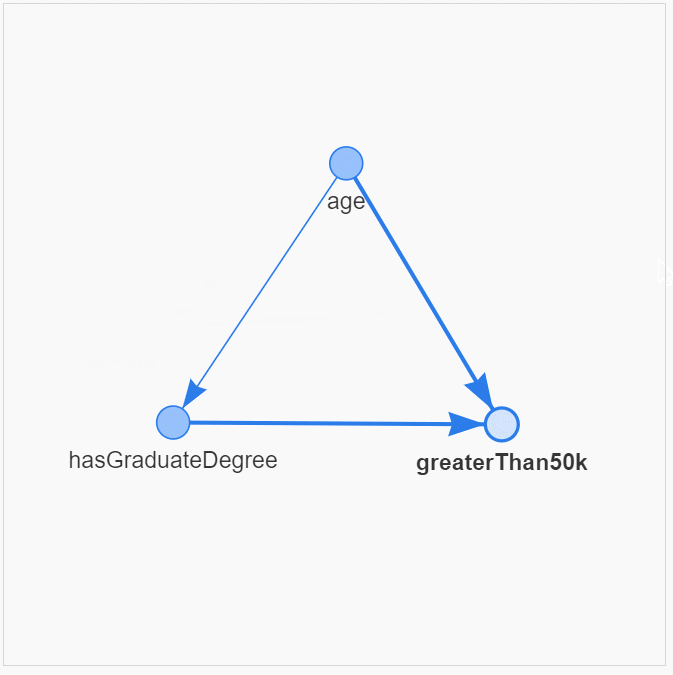
Последним шагом в построении модели является подгонка данных следующим образом:
census_model.fit(df_census)
census_model.check_model()Таблицы условной вероятности
Очень легко использовать нативный функционал в pgmpy библиотеке, чтобы бегло взглянуть на КПП
for cpt in census_model.get_cpds():
print(cpt)+---------+--------------+
| возраст(17) | 0,0128214 |
+---------+--------------+
| возраст(18) | 0,0179637 |
+---------+--------------+
| возраст(19) | 0,0225917 |
+---------+--------------+
| возраст(20) | 0,0236202 |
+---------+--------------+
| возраст(21) | 0,0223174 |
+---------+--------------+
| возраст(22) | 0,0234145 |
+---------+--------------+
| возраст(23) | 0,0264313 |
+---------+--------------+
...
+---------+----------- --+
| возраст(88) | 0,000102845 |
+---------+--------------+
| возраст(90) | 0,00126843 |
+---------+--------------+
+---------- --+-----+----------+-------+
| возраст | ... | возраст(88) | возраст(90) |
+--------------------------+-----+----------+------ ---------------+
| hasGraduateDegree(False) | ... | 1.0 | 0,8918918918918919 |
+--------------------------+-----+----------+------ ---------------+
| hasGraduateDegree(True) | ... | 0,0 | 0,10810810810810811 |
+--------------------------+-----+----------+------ ---------------+
+-----------------------+-----+--- ----------------------+
| возраст | ... | возраст(90) |
+-----------------------+------+----- ------+
| имеетвысшую степень | ... | hasGraduateDegree(True) |
+-----------------------+------+----- ------+
| больше чем 50 000 (ложь) | ... | 0,25 |
+-----------------------+------+----- ------+
| больше чем 50 000 (правда) | ... | 0,75 |
+-----------------------+------+----- ------+Результат очень неудовлетворительный.
- CPT, представляющий вероятности
age, распределен по вертикали (поскольку возраст имеет много стадий, по одной для каждого возраста от 17 до 90 лет). - CPT для вероятностей
hasGraduateDegreeеще хуже. Поскольку эта таблица распределена по горизонталиpgmpy, все столбцы для возрастов от 17 до 87 лет были усечены, а на дисплее остались только возрасты 88 и 90 лет. Это могло бы соответствовать таблице в ячейке, но полученное усечение не позволяет понять, что происходит. - CPT для
greaterThan50kимеет те же проблемы, что иhasGraduateDegree. - Последняя проблема с
pgmpyвыводом для CPT заключается в том, что они «перевернуты». Если вы читали Judea Pearl, опубликовавшего много основополагающих работ по причинно-следственным связям (включая «Книгу почему»), вы читали примеры, в которых Перл выражает свои CPT с помощью «Probability», выраженной в столбцах, и «Given» условий, выражено по рядам
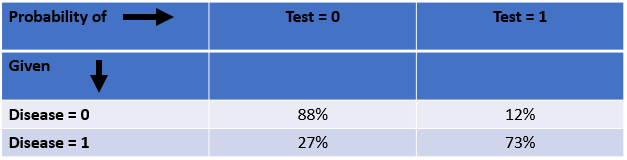
Лучшее решение
Все эти проблемы очень затрудняют визуализацию того, что происходит в причинно-следственной модели, и это приводит к отсутствию понимания, что, в свою очередь, приводит к невозможности использовать эти модели для решения реальных проблем клиентов.
Таким образом, неинтуитивный вывод pgmpy привел к разработке собственной cpt_tools библиотеки для решения всех проблем
Давайте посмотрим на вывод, сгенерированный с помощью cpt_tools
for cpt in census_model.get_cpds():
cpt_tools.display_cpt(cpt)
Выглядит намного лучше всего в 1 строке кода Python из cpt_tools библиотеки
Таблицы возвращаются как pandas DataFrames, и усечение происходит по оси Y (строки), чтобы обеспечить наилучший компромисс между читаемостью и использованием пространства.
Если вы хотите увидеть весь CPT без горизонтального усечения, просто измените display.max_rows параметр pandas, а затем используйте его cpt_tools.display_cpt следующим образом:
pd.set_option('display.max_rows', None)
cpt_tools.display_cpt(census_model.get_cpds()[2])
pd.reset_option('display.max_rows')Исходный код
Полный исходный код будет выглядеть следующим образом, также предоставляется документация
Вывод
Причинно-следственный вывод — отличный инструмент, который должен быть в вашем наборе инструментов для обработки данных, но чтобы использовать причинно-следственный вывод для решения бизнес-задачи, вам необходимо уметь визуализировать ориентированные ациклические графы и таблицы условной вероятности.
Библиотека pgmpy является всеобъемлющей и простой в использовании, но функциональные возможности визуализации моделей могут быть расширены и улучшены.
В этой статье показано, как визуализировать таблицы условной вероятности визуально мощным, интуитивно понятным и простым для понимания способом, используя всего одну строку кода Python.