Как Вы можете (и почему Вы должны) Доступ к ресурсам Amazon S3 с помощью Python

Amazon Simple Storage Service (S3) предоставляет пользователям дешевую, безопасную и простую в управлении инфраструктуру хранения данных. Возможно перемещать файлы в сегменты S3 и из них с помощью самой консоли AWS, но AWS также предлагает возможность упростить эти операции с помощью кода.
Для Python AWS software development kit (SDK) предлагает boto3, который позволяет пользователям создавать, настраивать и использовать сегменты и объекты S3 с помощью кода. Здесь мы углубимся в основные функции boto3 для ресурсов S3 и рассмотрим, как их можно использовать для автоматизации операций.
Boto3
Вам может быть интересно, есть ли смысл учиться использовать еще один инструмент, когда вы уже можете получить доступ к сервису S3 через консоль AWS. Конечно, благодаря простому и удобному пользовательскому интерфейсу (UI) AWS легко перемещать файлы в корзины S3 и из них.
Однако использование типичного подхода «щелкни и перетащи» нецелесообразно, когда операции должны масштабироваться. Одно дело обрабатывать от 1 до 10 файлов одновременно, но вы бы справились с сотнями или тысячами файлов? Такое мероприятие, естественно, потребовало бы много времени, если бы оно выполнялось вручную.
Кроме того, ручные задачи также делают пользователей склонными к ошибкам. При перемещении больших объемов данных вручную, можете ли вы гарантировать, что вы по ошибке не пропустите или не включите неправильные файлы?
Те, кто ценит эффективность или согласованность, несомненно, оценят преимущества использования сценариев Python для автоматизации использования ресурсов S3.
Предпосылки. Давайте начнем с предварительных условий для использования boto3.
Установка
Чтобы использовать boto3, вам необходимо установить AWS SDK, если вы еще этого не сделали, с помощью следующей команды.
pip install boto3Пользователь IAM
Вам также понадобится учетная запись пользователя IAM с разрешением на использование ресурсов S3.
Чтобы получить удостоверение пользователя, войдите в AWS с учетной записью пользователя root. Перейдите в раздел Управление идентификацией и доступом (IAM) и добавьте нового пользователя. Назначьте этому идентификатору пользователя политику, которая предоставит доступ к ресурсам S3. Самый простой вариант - выбрать политику разрешений “AmazonS3FullAccess”, но вы можете найти или создать политики, которые в большей степени соответствуют вашим потребностям.

После выбора политики выполните остальные запросы и создайте удостоверение пользователя. Вы должны увидеть свою вновь созданную личность в консоли. В этом примере мы используем идентификатор пользователя с именем «s3_demo».
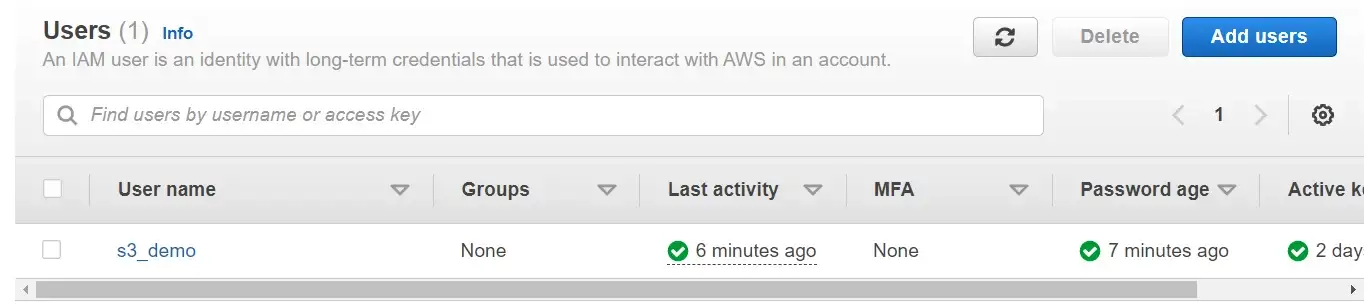
Затем щелкните имя пользователя (не флажок) и перейдите на вкладку учетных данных безопасности. В разделе ключа доступа выберите «создать ключ доступа» и ответьте на все запросы. Затем вы получите ключ доступа и секретный ключ доступа.
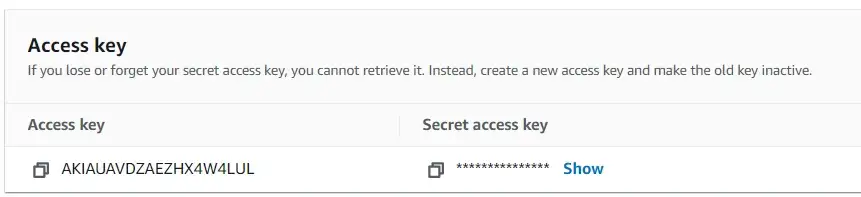
Эти ключи необходимы для доступа к ресурсам S3 с помощью boto3, поэтому они, естественно, будут включены в скрипт Python.
import os
AWS_KEY_ID = os.environ.get('S3_Demo_Access_Key')
AWS_SECRET = os.environ.get('S3_Demo_Secret_Access_Key')Основные команды
Boto3 включает в себя функции, которые могут выделять и настраивать различные ресурсы AWS, но основное внимание в этой статье будет уделено работе с корзинами и объектами S3. Ключевым преимуществом boto3 является то, что он выполняет такие задачи, как загрузка и загрузка файлов, с помощью простой однострочной строки.
Создание клиента
Чтобы получить доступ к ресурсам S3 с помощью boto3 (или любого другого ресурса AWS), сначала необходимо создать клиент сервиса низкого уровня.
# create a client
s3 = boto3.client(service_name='s3',
region_name='us-east-1',
aws_access_key_id = AWS_KEY_ID,
aws_secret_access_key = AWS_SECRET)Для создания клиента необходимо ввести имя службы, имя региона, ключ доступа и секретный ключ доступа.
Создание корзины
Начнем с создания корзины, которую назовем «a-random-bucket-2023». Этого можно добиться с помощью функции create_bucket.
# create a bucket
bucket = s3.create_bucket(Bucket='a-random-bucket-2023')Если вы обновите раздел S3 на консоли AWS, вы должны увидеть вновь созданную корзину.

Сегменты со списком
Чтобы вывести список доступных сегментов, пользователи могут использовать функцию list_buckets. Это возвращает словарь со многими парами ключ-значение. Чтобы увидеть только названия сегментов, извлеките значение ключа Buckets в словаре.
# list buckets
response = s3.list_buckets()
response['Buckets']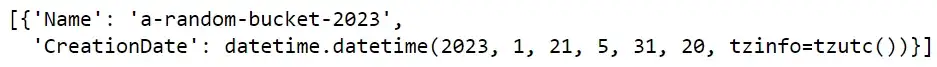
Загрузите файл в корзину
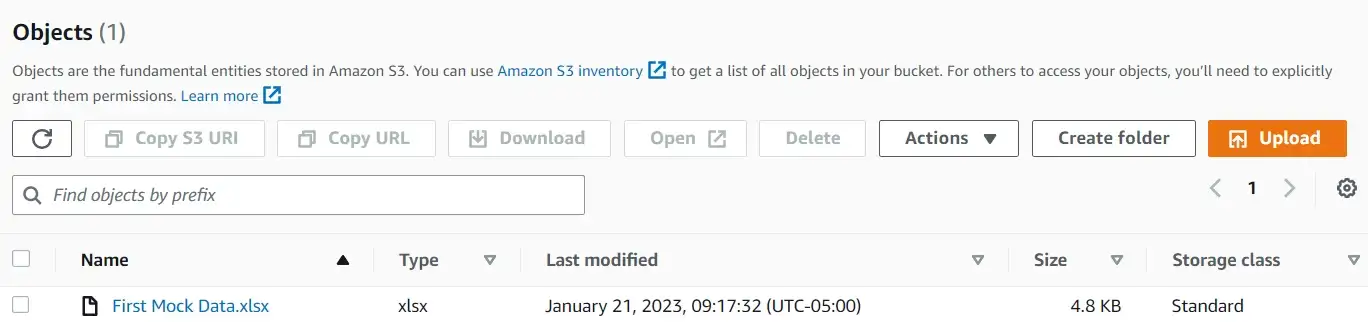
Файлы можно загружать с помощью функции upload_file. В этом случае давайте загрузим в корзину «mock_data.xlsx».
# uploade file to bucket
s3.upload_file(Filename='Mock data.xlsx',
Bucket='a-random-bucket-2023',
Key='First Mock Data.xlsx')Стоит различать разницу между параметрами Filename и Key. Filename относится к имени передаваемого файла, а Key относится к имени, которое присваивается объекту, хранящемуся в корзине.
Поскольку «First Mock Data.xlsx» был присвоен ключевому параметру, это будет имя объекта при его загрузке в корзину.
Загрузка фрейма данных Pandas в корзину
Поскольку мы работаем на Python, стоит знать, как загрузить фрейм данных Pandas непосредственно в корзину. Этого можно добиться с помощью модуля io. В следующем фрагменте мы загружаем фрейм данных «df» в корзину.
import io
# upload pandas data frame to bucket
csv_buffer = io.StringIO()
df.to_csv(csv_buffer)
s3.put_object(Bucket='a-random-bucket-2023',
Body=csv_buffer.getvalue(),
Key='Pandas Data Frame.csv')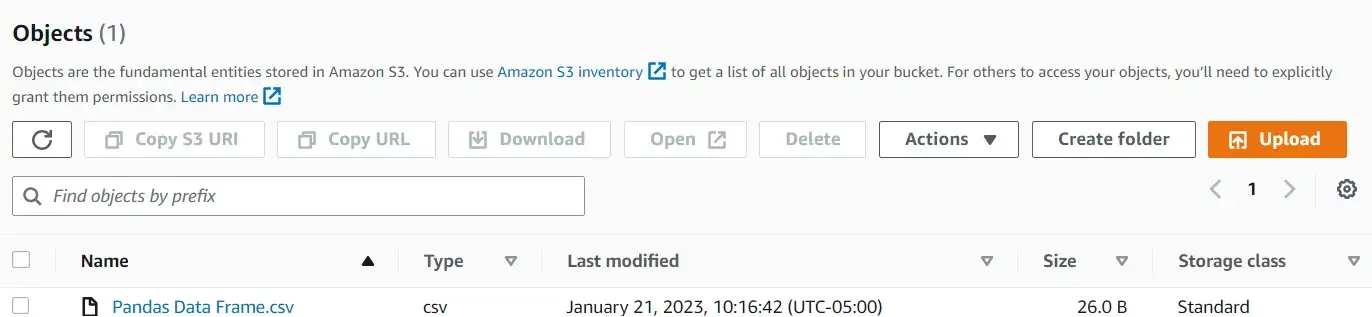
Список объектов
Объекты в данном сегменте могут быть перечислены с помощью функции list_objects.
# list objects
objects = s3.list_objects(Bucket='a-random-bucket-2023')Вывод самой функции — это большой словарь с кучей метаданных, но имена объектов можно найти, обратившись к ключу «Contents».
# show object names
objects['Contents']
Скачать файлы
Объекты можно загрузить из корзины с помощью функции download_file.
# Download the file from S3
s3.download_file('a-random-bucket-2023',
'First Mock Data.xlsx',
'Mock Data (Downloaded).xlsx')Удаление объектов
Объекты могут быть удалены с помощью функции delete_object.
# delete object
s3.delete_object(Bucket='a-random-bucket-2023',
Key='First Mock Data.xlsx')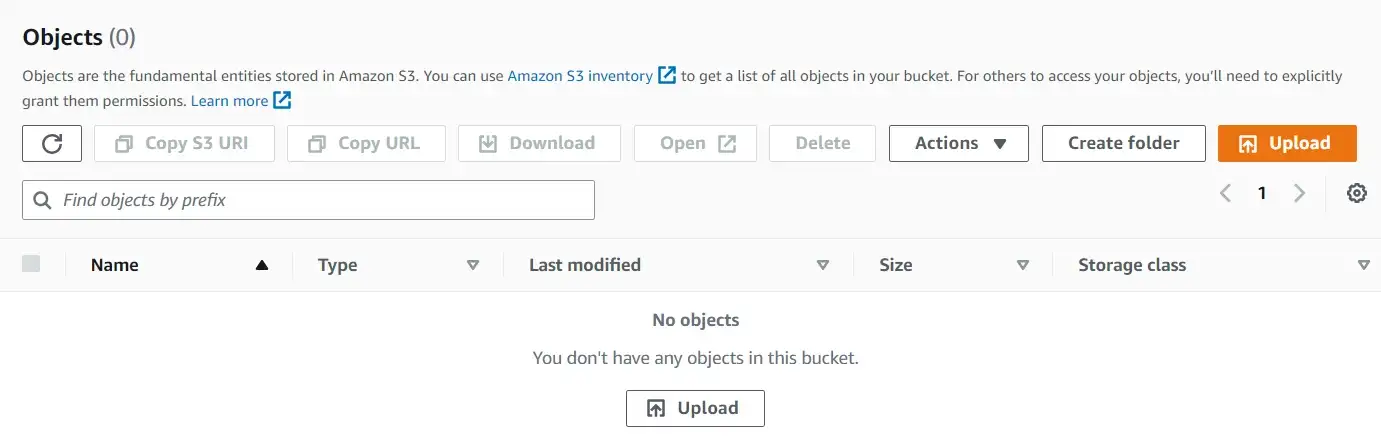
Удаление сегментов
Наконец, пользователи могут удалять сегменты с помощью функции delete_bucket.
# delete the bucket
delete = s3.delete_bucket(Bucket='a-random-bucket-2023')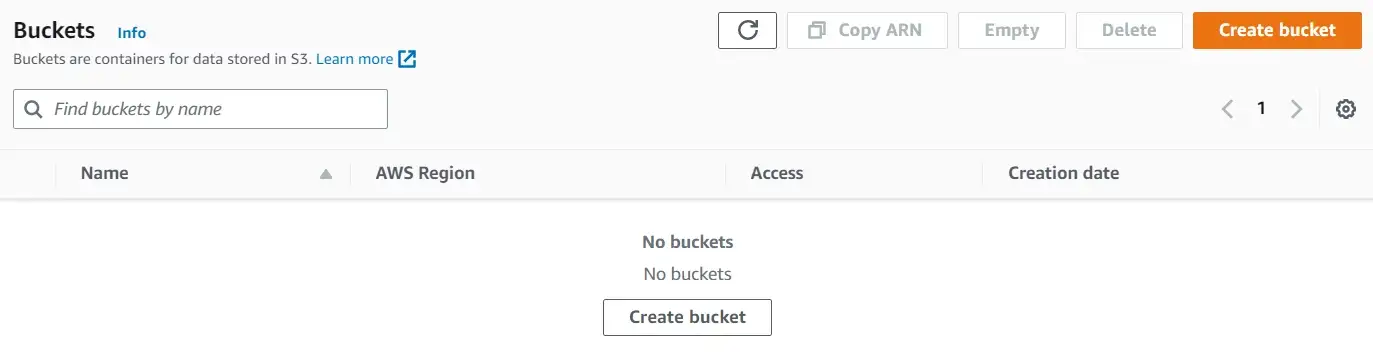
Тематическое исследование
Мы изучили некоторые основные функции boto3 для использования ресурсов S3. Тем не менее, проведение тематического исследования — лучший способ продемонстрировать, почему boto3 является таким мощным инструментом.
Постановка задачи 1: Нас интересуют книги, изданные в разные даты. Получите данные об опубликованных книгах с помощью NYT Books API и загрузите их в корзину S3.
Опять же, мы начинаем с создания низкоуровневого клиента службы.
# create a client
s3 = boto3.client(service_name='s3',
region_name='us-east-1',
aws_access_key_id = AWS_KEY_ID,
aws_secret_access_key = AWS_SECRET)Далее мы создаем корзину, которая будет содержать все эти файлы.
# create a bucket for nyt data
bucket = s3.create_bucket(Bucket='nyt-books')
Затем нам нужно получить данные с помощью API NYT Books и загрузить их в корзину. Мы можем выполнить извлечение данных для заданной даты с помощью следующей функции get_data:
def get_data(date, NYT_API_KEY):
"""Pull data with the given uri"""
uri = f'https://api.nytimes.com/svc/books/v3/lists/{date}/hardcover-fiction.json?api-key={NYT_API_KEY}'
data = requests.get(uri)
response = data.json()
response['results'].keys()
df = pd.DataFrame(response['results']['books'])
df['published_date'] = response['results']['published_date']
return dfВот предварительный просмотр того, как выглядит вывод функции get_data:
# preview of stored api response
random_df = get_data(date='2023-01-20', API_KEY=API_KEY)
random_df.head(1)
Есть много способов использовать эту функцию для сбора данных. Один из вариантов — запускать эту функцию и загружать выходные данные в корзину S3 каждый день (или использовать планировщик заданий). Другой вариант — использовать циклы для сбора данных о книгах, опубликованных за несколько дней.
Если нас интересуют книги, опубликованные за последние 7 дней, мы можем анализировать каждый день с помощью цикла. На каждый день мы:
- сделать вызов через API
- сохранить ответ во фрейме данных
- загрузить фрейм данных в корзину
Эти шаги выполняются с помощью следующего фрагмента:
import datetime
import time
import io
# get todays date
tod = datetime.datetime.now()
# get last 7 dates
last_7_dates = [str((tod- datetime.timedelta(days=i)).date()) for i in range(7)]
# parse through each date
for date in last_7_dates:
# pull data for books published in given day
data = get_data(date=date, NYT_API_KEY=API_KEY)
# upload pandas data frame to bucket
csv_buffer = io.StringIO()
data.to_csv(csv_buffer)
s3.put_object(Bucket='nyt-books',
Body=csv_buffer.getvalue(),
Key=f'nyt books {date}.csv')
# pause to stay within API limits
time.sleep(6)
print('Done!')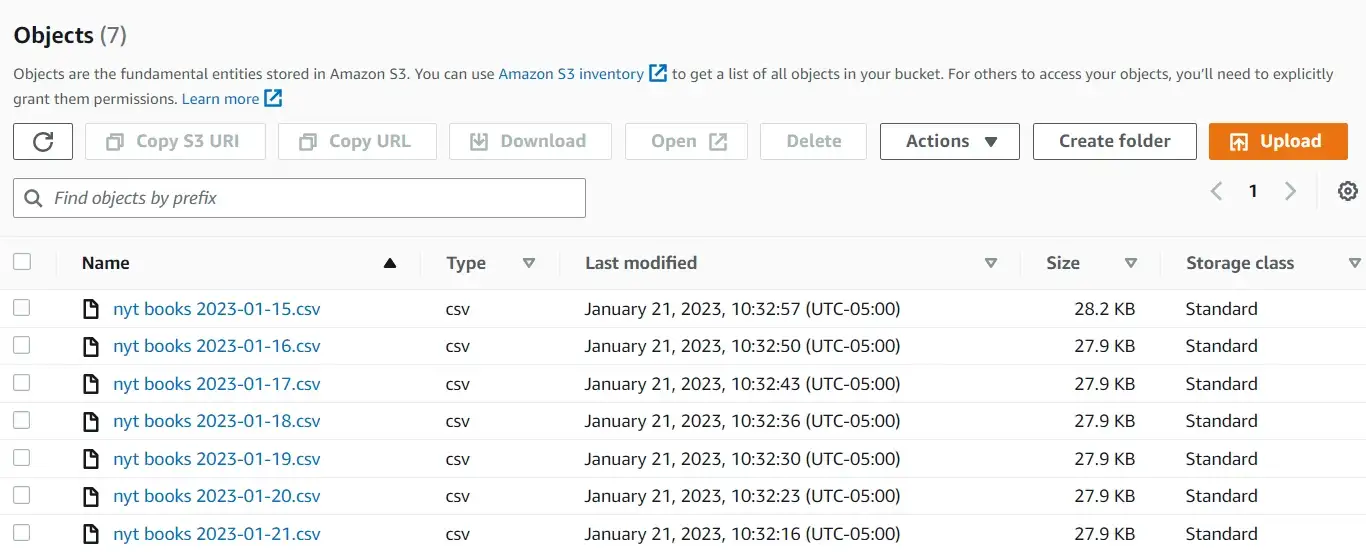
С помощью всего нескольких строк кода мы можем выполнять несколько вызовов API и загружать ответы в корзину одним махом!
В какой-то момент может возникнуть необходимость извлечь некоторую информацию из данных, загруженных в корзину. Для аналитиков данных естественно получать специальные запросы, касающиеся собираемых ими данных.
Постановка задачи 2. Найдите название книги, автора и издателя книг с самым высоким рейтингом за все даты и сохраните результаты локально.
import io
# list objects in bucket
contents = s3.list_objects(Bucket='nyt-books')['Contents']
list_df = []
# parse through all objects
for content in contents:
file_name = content['Key']
# store object into a data frame
obj = s3.get_object(Bucket='nyt-books', Key=file_name)
df_subset = pd.read_csv(io.BytesIO(obj['Body'].read()))
list_df.append(df_subset)
# merge all pulled datasets into one dataset
df = pd.concat(list_df)
# keep only books that ranked the highest and select the wanted columns
df = df[df['rank']==1][['rank','title', 'author', 'publisher']]
# export the data frame as a csv file
df.to_csv('top-ranking books.csv', index=False)С помощью Python мы можем хранить несколько объектов S3 во фреймах данных Pandas, обрабатывать фреймы данных и загружать выходные данные в плоский файл.
В этом тематическом исследовании продемонстрированы два ключевых преимущества использования boto3. Первое преимущество этого метода заключается в том, что он хорошо масштабируется; разница во времени и усилиях, необходимых для загрузки/скачивания 1 файла и 1000 файлов, незначительна. Второе преимущество заключается в том, что он позволяет пользователям беспрепятственно связывать другие процессы (например, сбор данных, фильтрацию) при перемещении данных в корзины S3 или из них.
Выводы
Надеемся, что этот краткий учебник по boto3 не только познакомил вас с основными командами Python для управления ресурсами S3, но и показал, как их можно использовать для автоматизации процессов.
С помощью AWS SDK для Python пользователи смогут перемещать данные в облако и из облака с большей эффективностью и согласованностью. Даже если в настоящее время вы довольны предоставлением и использованием ресурсов с помощью пользовательского интерфейса AWS, вы, несомненно, столкнетесь со случаями, когда масштабируемость является приоритетом. Знание основ boto3 гарантирует, что вы будете хорошо подготовлены к таким ситуациям.