Лучшие практики для проектов HarperDB с использованием TypeScript

Когда вы работаете с HarperDb, вы можете использовать TypeScript для улучшения вашего опыта разработки. В этой статье мы покажем вам некоторые рекомендации по использованию TypeScript в HarperDB. Мы поговорим о структурах папок, лучших методах работы с кодом и о том, как наилучшим образом настроить ваш проект, чтобы максимально использовать HarperDB.
Прежде чем вы начнете
Обязательно ознакомьтесь с документацией HarperDB, чтобы узнать, как установить ее локально и приступить к работе. Вы также можете использовать облако HarperDB, чтобы быстро приступить к работе. Но я предполагаю, что у вас уже запущен ваш экземпляр.
Этот репозиторий находится на GitHub сообщества HarperDB. Вы можете клонировать его и следовать статье. Мы будем использовать облачную версию базы данных, но в репозитории вы найдете файл docker-compose.yml, который можно использовать для локального запуска с помощью docker compose up.
Настройка Node и TypeScript
Чтобы использовать TypeScript, вам необходимо установить Node.js, обязательно используйте последнюю версию LTS. Вы можете проверить это, запустив node -v в своем терминале. Если он у вас не установлен, вы можете скачать его здесь или использовать менеджер версий, например asdf, nvm или даже volta.
Я использую версию 20.7.0 от Node.js, но вы можете использовать любую версию выше 18 на момент написания этой статьи.
Давайте создадим новый каталог (вы можете назвать его как угодно) и внутри него запустим команду npm init -y. Это сгенерирует новый файл package.json со значениями по умолчанию. Теперь давайте установим TypeScript в качестве зависимости от разработки, запустив npm install --save-dev typescript. Это приведет к установке последней версии TypeScript в вашем проекте.
Совет: Вы можете проверить последнюю версию TypeScript здесь. Я использую версию 5.2.2
Мы также установим внешние типы для Node.js, запустив npm install --save-dev @types/node. Это позволит нам использовать типы Node.js в нашем проекте.
Наконец, мы добавим пакет поддержки под названием tsx, который позволит нам разрабатывать наше приложение без необходимости компилировать его каждый раз, когда мы что-то меняем. Мы установим его, запустив npm install --save-dev tsx.
Давайте затем загрузим typescript с помощью npx tsc --init, это создаст файл tsconfig.json со всеми определениями, необходимыми TS. Однако нам нужно будет изменить там некоторые значения. Итак, откроем его, удалим все значения и оставим так:
{
"compilerOptions": {
"target": "ESNext",
"module": "NodeNext",
"outDir": "./dist",
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
"strict": true,
"skipLibCheck": true
}
}
Мы также будем использовать ESModules, поэтому нам нужно изменить ключ type в нашем файле package.json на module. Это позволит нам использовать синтаксис import в нашем коде. Давайте также добавим скрипт запуска, который позволит нам запускать наш скомпилированный код. Наш файл package.json будет таким:
{
"name": "hdb-typescript-best-practices",
"version": "0.0.1",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"start": "node --env-file=.env dist/index.js",
"start:dev": "NODE_OPTIONS='--loader=tsx' node --env-file=.env src/index.ts"
},
"keywords": [],
"author": "Lucas Santos <hello@lsantos.dev> (https://lsantos.dev/)",
"license": "GPL-3.0",
"devDependencies": {
"@types/node": "^20.7.1",
"tsx": "^3.13.0",
"typescript": "^5.2.2"
}
}
Тестирование установки
Теперь давайте создадим папку src и файл index.ts внутри нее. Это будет наша точка входа для приложения. Давайте также добавим папки dist и node_modules в наш файл .gitignore (если вы еще этого не добавили), чтобы не фиксировать скомпилированный код.
Node.js, начиная с версии 20.6, имеет встроенную поддержку файлов env, поэтому мы воспользуемся этим, чтобы хранить наши секреты в файле .env. Это первый лучший способ:
Лучшая практика: Никогда не сохраняйте секреты в своем репозитории. Используйте файл.envдля их хранения и добавьте его в свой файл.gitignore.
Давайте создадим файл .env и добавим следующее содержимое:
EXAMPLE=Test environmentТеперь давайте добавим следующий код в наш файл index.ts:
export async function main() {
console.log('Hello world!')
console.log(process.env.EXAMPLE)
}
await main()Теперь запустите программу установки с помощью npm run start:dev, вы должны увидеть следующий вывод:
$ npm run start:dev
Hello World!
Test environmentЭто означает, что все настроено правильно!
Совет: Вы также можете запустить файл вручную посредством компиляции, для этого вам нужно запуститьnpx tscв корневом каталоге, затем запуститьnode --env-file=.env dist/index.js. Это будет иметь тот же результат. Вы даже можете добавить сценарий сборки, который будет использовать командуtsc, чтобы вы могли запуститьnpm run build, а затемnpm run startдля запуска кода.
Настройка среды и базы данных
Теперь, когда мы знаем, что все работает, давайте перейдем в HarperDB Studio и создадим нашу схему. Мы создадим новую схему с именем todo и таблицу с именем todo_items. Это будет наша таблица, в которой будут храниться список дел.
hash таблицы будет являться столбец id:
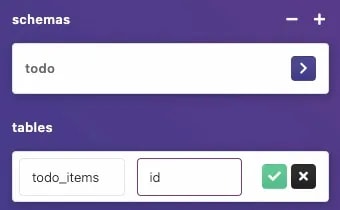
У Harper гибкая схема, поэтому нам не нужно определять все свойства, только начальное свойство hash, все остальные будут добавлены по мере создания объектов.
Давайте установим переменные среды в файле .env:
HDB_HOST=https://your-instance.harperdbcloud.com
HDB_USERNAME=your username
HDB_PASSWORD=your password
HDB_SCHEMA=todo
HDB_TABLE=todo_itemsРазделение слоев
Для нашего приложения мы создадим простое и великолепное приложение со списком дел. Это приложение будет иметь следующие возможности:
- Создание нового элемента списка дел
- Список всех дел
- Отметка задачи как выполненная
- Удаление задачи
Это простое приложение, но оно позволит нам изучить некоторые лучшие практики использования TypeScript с HarperDB.
Мы также будем использовать многоуровневую архитектуру для разделения нашего кода. Это позволит нам лучше разделить задачи и сделать наш код более удобным в сопровождении. Многоуровневая архитектура позволяет TypeScript проявить себя, поскольку мы можем использовать интерфейсы для определения наших контрактов и убедиться, что наш код соответствует правильной структуре.
У нас будет как минимум три слоя:
- Уровень представления: Это уровень, который взаимодействует с пользователем. Это может быть интерфейс командной строки, веб-приложение или даже мобильное приложение. Этот уровень будет отвечать за получение пользовательских данных и отправку их на следующий уровень. В нашем случае у нас будет API, который будет представлять собой REST API, который будет получать пользовательские данные и отправлять их на следующий уровень. Но это позволяет нам отделить реальную логику приложения от уровня представления, что позволяет нам перенести уровень представления на другую технологию без необходимости изменять логику приложения. Таким образом, мы могли бы добавить CLI, конечную точку GraphQL, gRPC или что-либо еще без необходимости изменять базовую структуру.
- Уровень домена или сервиса: Это уровень, на котором будет находиться бизнес-логика нашего приложения. Он будет отвечать за получение подтвержденных пользовательских данных и действия в соответствии с ними. Он также будет отвечать за получение данных со уровня данных и преобразование их в правильный формат для уровня представления. Этот слой будет обладать наибольшей логикой и может быть разделен на несколько частей. Уровень домена может быть доступен любым другим уровням, поскольку он является основной частью системы.
- Уровень данных: Как следует из названия, это уровень, который будет отвечать за данные, данные могут поступать из любого источника, базы данных, внешнего клиента и т.д. Он будет отвечать за получение данных с уровня домена и преобразование их в правильный формат для базы данных. Он также будет отвечать за получение данных из базы данных и преобразование их в правильный формат для уровня домена. Этот уровень будет тем, в котором будет меньше всего логики, но он самый важный, потому что именно здесь мы добавим логику нашей базы данных и наше взаимодействие с базой данных.
Это очень близко к знаменитой архитектуре MVC, но требует некоторых определений из доменно-ориентированного проектирования и чистой архитектуры.
Уровень домена
Прежде чем создавать какие-либо слои, нам нужно смоделировать наш объект домена, который является элементом задач. Это позволит нам лучше понять, что нам нужно делать и как мы должны это делать. Это позволит нам понять, какова форма нашего объекта и как мы будем им манипулировать.
Давайте начнем с доменной папки внутри src, там мы создадим файл с именем TodoItem.ts. Это будет наш доменный объект, поэтому давайте добавим к нему следующий код:
import { randomUUID } from 'node:crypto'
export class TodoItem {
constructor(
public title: string,
public dueDate: Date,
readonly id: string = randomUUID(),
public completed: boolean = false,
readonly createdAt: Date = new Date()
) {}
}Это простой класс, который будет представлять наш список дел. У него есть конструктор, который получает название и дату выполнения и устанавливает другие свойства. id - это случайный UUID, значение completed по умолчанию равно false, а значение createdAt - текущая дата.
Итак, теперь мы можем создать новый элемент списка дел, запустив new TodoItem('My first to-do item', new Date()). Это создаст новый элемент списка дел с названием My first to-do item и датой выполнения в качестве текущей даты.
Давайте добавим некоторые функции к нашему объекту домена, чтобы сделать его более полезным. Мы добавим метод toJSON, который будет возвращать объект в виде строки JSON, и статический метод fromObject, который будет получать объект, соответствующий объекту данных, и возвращать новый экземпляр класса.
Для этого нам нужно будет создать схему, с которой мы сможем сравнивать и проверять наш объект. Это идеальный вариант использования Zod! Zod — это библиотека проверки схемы, основанная на TypeScript, которая позволяет нам создавать схемы и проверять по ним наши объекты. Давайте установим его, запустив npm install --save zod.
Чтобы определить схему, у нас есть два варианта:
- Мы определяем его в новом файле и импортируем в наш объект домена.
- Мы определяем его внутри объекта домена.
Лично я предпочитаю второй вариант, поскольку и схема, и объект домена тесно связаны и являются частью одного и того же объекта, поэтому имеет смысл разместить их в одном файле. Но вы можете выбрать тот, который вам более понятен.
Давайте добавим следующий код в начало нашего объекта домена:
import { z } from 'zod'
const todoItemSchema = z.object({
title: z.string(),
dueDate: z.date(),
id: z.string().uuid(),
completed: z.boolean().default(false),
createdAt: z.date().default(new Date())
})
export type TodoObjectType = z.infer<typeof TodoObjectSchema>Примечание. Также можно в некоторой степени имитировать то, что мы делаем вz.infer<typeof TodoObjectSchema>, используя служебный типInstanceType, но тогда нам нужно будет удалить методы из типа, поэтому я предпочитаю использовать методinfer. чтобы также создать четкое ощущение разделения того, что является нашим объектом домена (классом), а также объектом передачи данных (JSON).
Затем мы будем использовать эту схему, чтобы убедиться, что наш объект является действительным элементом списка дел. Давайте изменим функцию fromJSON в нашем объекте домена:
static fromObject(todoObject: TodoObjectType): InstanceType<typeof TodoItem> {
TodoObjectSchema.parse(todoObject) // This will throw an error if the object is not valid
return new TodoItem(todoObject.title, todoObject.dueDate, todoObject.id, todoObject.completed, todoObject.createdAt)
}Это позволит проанализировать строку JSON и вернуть новый экземпляр класса. Мы также можем добавить toObject, чтобы превратить класс в сериализуемый объект, и метод toJSON, который будет возвращать строку JSON. Это будет полезно, когда нам нужно отправить объект в базу данных. Давайте добавим следующий код в наш объект домена:
toObject() {
return JSON.stringify({
title: this.title,
dueDate: this.dueDate,
id: this.id,
completed: this.completed,
createdAt: this.createdAt
})
}
toJSON() {
return JSON.stringify(this.toObject())
}Совет: Еще одна вещь, которую мы можем здесь сделать, — это не использовать методtoObject, а вместо этого использовать сокращенную запись{ ...item }, которая автоматически преобразует его в объект. Но я предпочитаю иметь метод, который я могу вызвать, чтобы сделать его более явным. Вы также можете вернуть{ ...this }
Наш окончательный объект домена будет выглядеть так:
import { randomUUID } from 'node:crypto'
import { z } from 'zod'
const TodoObjectSchema = z
.object({
title: z.string(),
dueDate: z.date({ coerce: true }),
id: z.string().uuid().readonly(),
completed: z.boolean().default(false),
createdAt: z.date({ coerce: true }).default(new Date()).readonly()
})
.strip()
export type TodoObjectType = z.infer<typeof TodoObjectSchema>
export class TodoItem {
constructor(
public title: string,
public dueDate: Date,
readonly id: string = randomUUID(),
public completed: boolean = false,
readonly createdAt: Date = new Date()
) {}
toObject() {
return JSON.stringify({
title: this.title,
dueDate: this.dueDate,
id: this.id,
completed: this.completed,
createdAt: this.createdAt
})
}
toJSON() {
return JSON.stringify(this.toObject())
}
static fromObject(todoObject: TodoObjectType): InstanceType<typeof TodoItem> {
TodoObjectSchema.parse(todoObject)
return new TodoItem(todoObject.title, todoObject.dueDate, todoObject.id, todoObject.completed, todoObject.createdAt)
}
}Уровень данных
Теперь, когда у нас есть объект домена, мы можем приступить к созданию уровня данных. Этот уровень будет отвечать за связь с базой данных и преобразование данных из базы данных в правильный формат для уровня домена. Он также будет отвечать за преобразование данных уровня домена в правильный формат для базы данных.
Поскольку мы используем Harper, все наше взаимодействие с БД осуществляется через API! Это чрезвычайно полезно, поскольку нам не нужно настраивать сложные драйверы или что-то в этом роде. Итак, давайте создадим новый файл в папке данных с именем TodoItemClient.ts. Это будет наш клиент HarperDB.
Совет: лучше всего называть внешние API «клиентами». Если бы у нас был какой-либо другой уровень данных, скажем, система очередей, которая не подключена через API, мы могли бы просто назвать егоqueueAdapterилиqueue, и все было бы хорошо. Это не правило, но лично я считаю, что проще понять, что делает файл, внешний агент или внутренний драйвер.
Наш клиент - это HTTP API, поэтому давайте использовать встроенную fetch из node для связи с ним (помните, что fetch api доступен только в node начиная с версии 18 и выше). Давайте добавим следующий код в наш файл TodoItemClient.ts:
import { TodoItem, TodoObjectType } from '../domain/TodoItem.js'
export class TodoItemClient {
#defaultHeaders: Record<string, string> = {
'Content-Type': 'application/json'
}
credentialsBuffer: Buffer
constructor(
private readonly url: string,
private readonly schema: string,
private readonly table: string,
credentials: { username: string; password: string }
) {
this.credentialsBuffer = Buffer.from(`${credentials.username}:${credentials.password}`)
this.#defaultHeaders['Authorization'] = `Basic ${this.credentialsBuffer.toString('base64url')}`
}
async upsert(data: TodoItem) {
const payload = {
operation: 'upsert',
schema: this.schema,
table: this.table,
records: [data.toObject()]
}
const response = await fetch(this.url, {
method: 'POST',
headers: this.#defaultHeaders,
body: JSON.stringify(payload)
})
if (!response.ok) {
throw new Error(response.statusText)
}
return data
}
async delete(id: string) {
const payload = {
operation: 'delete',
schema: this.schema,
table: this.table,
hash_values: [id]
}
const response = await fetch(this.url, {
method: 'POST',
headers: this.#defaultHeaders,
body: JSON.stringify(payload)
})
if (!response.ok) {
throw new Error(response.statusText)
}
}
async findOne(id: string) {
const payload = {
operation: 'search_by_hash',
schema: this.schema,
table: this.table,
hash_values: [id],
get_attributes: ['*']
}
const response = await fetch(this.url, {
method: 'POST',
headers: this.#defaultHeaders,
body: JSON.stringify(payload)
})
if (!response.ok) {
throw new Error(response.statusText)
}
const data = (await response.json()) as TodoObjectType[]
if (data[0] && Object.keys(data[0]).length > 0) {
return TodoItem.fromObject(data[0])
}
return null
}
async listByStatus(completed = true) {
const payload = {
operation: 'search_by_value',
schema: this.schema,
table: this.table,
search_attribute: 'completed',
search_value: completed,
get_attributes: ['*']
}
const response = await fetch(this.url, {
method: 'POST',
headers: this.#defaultHeaders,
body: JSON.stringify(payload)
})
if (!response.ok) {
throw new Error(response.statusText)
}
const data = (await response.json()) as TodoObjectType[]
return data.map((todoObject) => TodoItem.fromObject(todoObject))
}
}Как вы можете видеть, здесь есть все методы, необходимые нам для взаимодействия с базой данных. У нас есть метод upsert, который создаст или обновит запись, метод delete, который удалит запись, метод findOne, который найдет запись по ее хэшу, и метод listByStatus, который перечислит все записи, соответствующие определенному значению.
Уровень сервиса
Сервисный слой будет связующим звеном между всеми остальными слоями. В таком простом приложении это обычно не очень полезно, но это хорошая практика, так что позже мы сможем добавить к нему больше логики. Давайте создадим новую папку с названием services и новый файл с именем TodoItemService.ts. Это будет наш сервисный уровень.
Уровень обслуживания получит обработанный пользовательский ввод, выполнит любую бизнес-логику и затем отправит ее на уровень данных. Он также получит данные из уровня данных и преобразует их в правильный формат для уровня представления.
Давайте добавим следующий код в наш файл TodoItemService.ts:
import { TodoItemClient } from '../data/TodoItemClient.js'
import { TodoItem, TodoObjectType } from '../domain/TodoItem.js'
export class TodoItemService {
#client: TodoItemClient
constructor(client: TodoItemClient) {
this.#client = client
}
async findOne(id: string) {
return this.#client.findOne(id)
}
async findAll() {
return [...(await this.findPending()), ...(await this.findCompleted())]
}
async findCompleted() {
return this.#client.listByStatus(true)
}
async findPending() {
return this.#client.listByStatus(false)
}
async create(todoItem: TodoObjectType) {
const todo = new TodoItem(todoItem.title, todoItem.dueDate)
return this.#client.upsert(todo)
}
async update(todoItem: TodoObjectUpdateType) {
const todo = await this.#client.findOne(todoItem.id ?? '')
if (!todo) {
throw new Error('Todo not found')
}
todo.completed = todoItem.completed ?? todo.completed
todo.dueDate = todoItem.dueDate ?? todo.dueDate
todo.title = todoItem.title ?? todo.title
return this.#client.upsert(todo)
}
async delete(id: string) {
return this.#client.delete(id)
}
}Видите, что, хотя в клиентской реализации на более низком уровне у нас есть более общая логика, которая выполняет поиск по статусу. В сервисе мы уже разделили команды на поиск отложенных и завершенных элементов.
Кроме того, мы реализовали метод findAll, который дважды вызывает метод listByStatus, а затем объединяет результаты. Это хороший пример того, как мы можем использовать уровень сервиса, чтобы добавить больше логики в наше приложение, фактически не добавляя больше логики на уровень данных.
Еще одним важным аспектом, на который следует обратить внимание, является то, что уровень обслуживания уже предполагает, что все данные будут обработаны. Это хорошая практика, потому что она позволяет нам лучше разделять интересы. Уровень представления должен быть тем, который проверяет данные в маршруте, а затем отправляет их на уровень обслуживания. Уровень обслуживания должен предполагать, что данные уже проверены и обработаны.
Совет: В любом случае, мы уже внедрили другой уровень проверок в нашем доменном объекте, когда мы получаем объекты, потому что TypeScript будет применять их только во время компиляции, поэтому мы можем быть уверены, что данные действительны.
Последнее, на что следует обратить внимание, это то, что теперь, когда мы поднялись на уровень выше, уровень обслуживания принимает в качестве параметра уровень ниже, а это означает, что нам нужно передать экземпляр клиента уровня данных на уровень обслуживания. Это называется инверсией управления и является частью принципа инверсии зависимостей.
Этот принцип гласит, что уровни более высокого уровня не должны зависеть от слоев более низкого уровня, а вместо этого они должны зависеть от абстракций. В нашем случае уровень сервиса зависит от уровня данных, но не от реализации уровня данных, а от абстракции уровня данных, которым является клиент.
Мы сделаем то же самое с уровнем представления.
Уровень представления
Теперь, когда у нас есть наш уровень данных, мы можем приступить к созданию нашего уровня представления. Этот уровень будет отвечать за получение пользовательских данных и отправку их на следующий уровень. В нашем случае у нас будет API, который будет представлять собой REST API, который будет получать пользовательские данные и отправлять их на следующий уровень.
Давайте создадим новую папку под названием presentation и новый файл под названием RestAPI.ts. Это будет наш интерфейс REST.
Обычно мы используем веб-фреймворк, чтобы избежать необходимости все пересоздавать заново. В этом примере мы будем использовать очень быстрый фреймворк под названием Hono, просто чтобы на некоторое время отойти от Express.
Установите его, а затем это адаптер для Node.js запустив, запустив npm install --save hono @hono/node-server.
Реализация сервисного уровня обычно соответствует Factory Pattern, который представляет собой шаблон создания, позволяющий нам создавать объекты без необходимости знать детали реализации. В нашем случае мы будем использовать фабрику для создания клиента Rest API, чтобы мы могли получить (посредством внедрения зависимостей) сервисный уровень.
Это переводится примерно так:
import { Hono } from 'hono'
import { TodoItemService } from '../services/TodoItemService.js'
export async function restAPIFactory(service: TodoItemService) {
const app = new Hono()
app.get('/api/todos/:id', async (c) => {})
app.get('/api/todos', async (c) => {})
app.post('/api/todos', async (c) => {})
app.put('/api/todos/:id', async (c) => {})
app.delete('/api/todos/:id', async (c) => {})
return app
}Это очень простая фабрика, которая получает уровень обслуживания и возвращает новый экземпляр клиента Rest API. Мы сейчас реализуем маршруты, но сначала вернемся к нашему файлу index.ts в каталоге src. Это будет нашей отправной точкой для подачи заявки.
Там мы запустим переменные окружения, а также клиент базы данных и уровень обслуживания. Давайте добавим следующий код в наш файл index.ts:
import { z } from 'zod'
import { TodoItemClient } from './data/TodoItemClient.js'
import { TodoItemService } from './services/TodoItemService.js'
import { restAPIFactory } from './presentation/api.js'
import { serve } from '@hono/node-server'
const conf = {
host: process.env.HDB_HOST,
credentials: {
username: process.env.HDB_USERNAME,
password: process.env.HDB_PASSWORD
},
schema: process.env.HDB_SCHEMA,
table: process.env.HDB_TABLE
}
const EnvironmentSchema = z.object({
host: z.string(),
credentials: z.object({
username: z.string(),
password: z.string()
}),
schema: z.string(),
table: z.string()
})
export type EnvironmentType = z.infer<typeof EnvironmentSchema>
export default async function main() {
const parsedSchema = EnvironmentSchema.parse(conf)
const DataLayer = new TodoItemClient(
parsedSchema.host,
parsedSchema.schema,
parsedSchema.table,
parsedSchema.credentials
)
const ServiceLayer = new TodoItemService(DataLayer)
const app = await restAPIFactory(ServiceLayer)
serve({ port: 3000, fetch: app.fetch }, console.log)
}
await main()Примечание: Мы могли бы создать другой файл с именемconfig.tsи переместить туда как нашуEnvironmentSchema, так и объектconf, но поскольку мы используем его только в файлеindex.ts, я предпочитаю сохранить его там. Однако, если вы получите эту конфигурацию где-то в другом месте, вам следует создать файлconfig.tsи переместить его туда.
Вернемся к нашему файлу restAPI.ts, давайте реализуем маршруты. Большинство из них будут содержать только параметры пути, поэтому я просто помещу их здесь и объясню логику:
import { Hono } from 'hono'
import { TodoItemService } from '../services/TodoItemService.js'
export async function restAPIFactory(service: TodoItemService) {
const app = new Hono()
app.get('/api/todos/:id', async (c) => {
try {
const todo = await service.findOne(c.req.param('id'))
if (!todo) {
c.status(404)
return c.json({ error: 'Todo not found' })
}
c.json(todo.toObject())
} catch (err) {
c.status(500)
c.json({ error: err })
}
})
app.get('/api/todos', async (c) => {
try {
let data
if (c.req.query('completed')) {
data = await service.findCompleted()
} else if (c.req.query('pending')) {
data = await service.findPending()
} else {
data = await service.findAll()
}
c.json(data.map((todo) => todo.toObject()))
} catch (err) {
c.status(500)
c.json({ error: err })
}
})
app.post('/api/todos', async (c) => {})
app.put('/api/todos/:id', async (c) => {})
app.delete('/api/todos/:id', async (c) => {
try {
await service.delete(c.req.param('id'))
c.status(204)
return c.body(null)
} catch (err) {
c.status(500)
c.json({ error: err })
}
})
return app
}Для маршрутов post и put нам также нужно будет проверить поступающие данные, у Hono есть валидатор для Zod, который мы можем использовать в качестве промежуточного программного обеспечения, давайте установим его с помощью npm i @hono/zod-validator.
Мы можем импортировать zValidator и добавить его после названия нашего маршрута, но перед нашим обработчиком, вот так:
app.post('/api/todos', zValidator('json', ourSchema) async (c) => {})Но здесь нам понадобится несколько вещей, во-первых, нам понадобится новый тип для представления типа создания и еще один для представления типа обновления. Давайте добавим следующий код в наш файл TodoItem.ts:
export const TodoObjectCreationSchema = TodoObjectSchema.omit({ id: true, createdAt: true, completed: true }).extend({
dueDate: z.string().datetime()
})
export const TodoObjectUpdateSchema = TodoObjectSchema.omit({ createdAt: true }).partial().extend({
dueDate: z.string().datetime().optional()
})
export type TodoObjectType = z.infer<typeof TodoObjectSchema>
export type TodoObjectCreationType = z.infer<typeof TodoObjectCreationSchema>
export type TodoObjectUpdateType = z.infer<typeof TodoObjectUpdateSchema>Мы создаем новые, более узкие типы, на основе более широкого типа, созданного Zod. Нам нужно обновить этот тип в служебном файле:
async create(todoItem: TodoObjectCreationType) {
const todo = new TodoItem(todoItem.title, new Date(todoItem.dueDate))
return this.#client.upsert(todo)
}
async update(todoItem: TodoObjectUpdateType) {
const todo = await this.#client.findOne(todoItem.id ?? '')
if (!todo) {
throw new Error('Todo not found')
}
todo.completed = todoItem.completed ?? todo.completed
todo.dueDate = new Date(todoItem.dueDate ?? todo.dueDate)
todo.title = todoItem.title ?? todo.title
return this.#client.upsert(todo)
}Теперь мы можем использовать эти типы на уровне представления. Давайте добавим следующий код в наш файл restAPI.ts:
app.post('/api/todos', zValidator('json', TodoObjectCreationSchema), async (c) => {
try {
const todoItemObject = await c.req.json<TodoObjectCreationType>()
const todo = await service.create(todoItemObject)
c.status(201)
c.json(todo.toObject())
} catch (err) {
c.status(500)
c.json({ error: err })
}
})Теперь о маршруте обновления:
app.put('/todos/:id', zValidator('json', TodoObjectUpdateSchema), async (c) => {
try {
const todoItemObject = await c.req.json<TodoObjectUpdateType>()
const todo = await service.update({ ...todoItemObject, id: c.req.param('id') })
c.status(200)
return c.json(todo.toObject())
} catch (err) {
c.status(500)
return c.json({ error: err })
}
})И это все! У нас есть наш презентационный слой, готовый к работе!
Тестирование
Тестирование нашего приложения заключается в запуске npm run start:dev и отправке запросов к нему. Чтобы лучше протестировать, я оставлю в репозитории файл Hurl, который вы можете использовать для тестирования API. Вы можете запустить его с помощью hurl --test ./collection.hurl. Это позволит запустить все тесты и убедиться, что все работает должным образом.
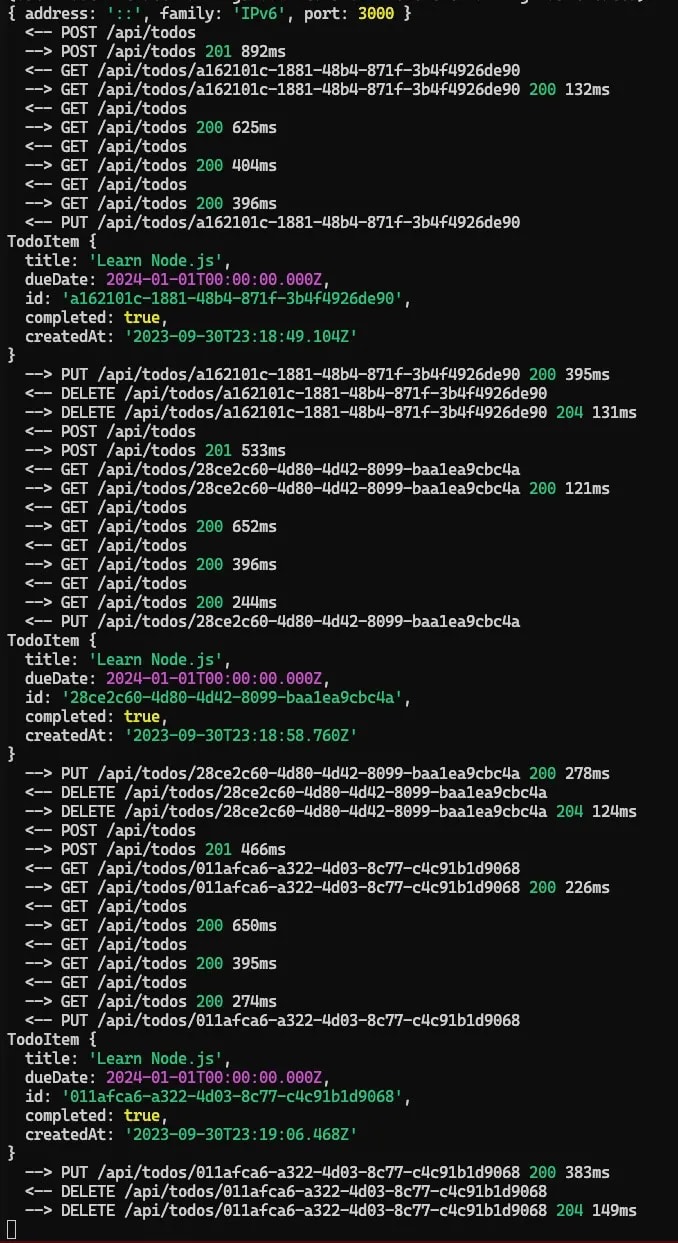
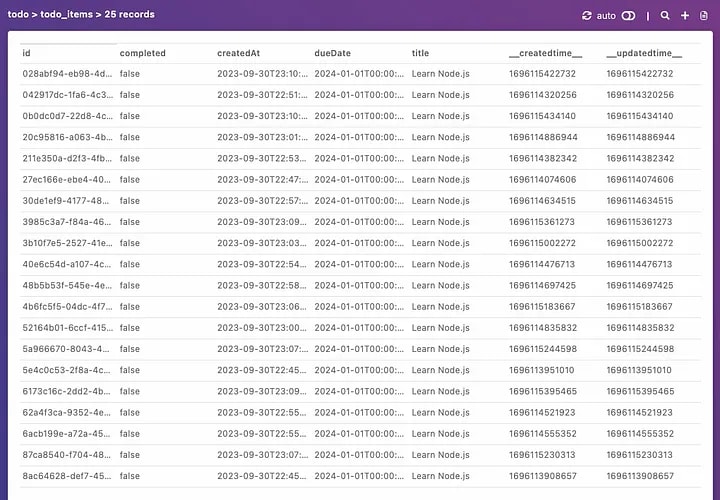
Вы также можете самостоятельно отправлять запросы к API, используя curl или любой другой инструмент, который вы предпочитаете. Затем проверьте свою HarperDB studio, чтобы убедиться, что данные были вставлены правильно.
Заключение
В этой статье мы узнали, как настроить проект TypeScript с помощью HarperDB, научились разделять код на слои и научились тестировать наше приложение. Попутно мы также изучили некоторые лучшие практики.
Идея состоит в том, что эти слои не высечены на камне, вы можете добавить больше слоев, если вам нужно, или удалить некоторые слои, если они вам не нужны. Важно иметь четкое разделение задач и убедиться, что ваш код удобен в сопровождении.