Pandas и Python: Советы и рекомендации по науке о данных и анализу данных

Здесь мы приведем все приемы и советы Pandas и Python, которые вы можете использовать в дальнейшем в своих проектах.
Содержание разделено на два основных раздела:
- Трюки и советы Pandas относятся только к Pandas.
- Трюки и советы на Python, связанные с Python.
Также предоставляются видео с канала YouTube. Каждое видео охватывает примерно два или три трюка одновременно.
Трюки и советы Pandas
В этом разделе приведен список всех приемов
1. Создание нового столбца для нескольких столбцов в вашем фрейме данных
Выполнение простых арифметических задач, таких как создание нового столбца в виде суммы двух других столбцов, может быть простым.
Но что, если вы хотите реализовать более сложную функцию и использовать ее в качестве логики создания столбца? Вот тут-то все и может стать немного сложнее.
𝙖𝙥𝙥𝙡𝙮 и 𝙡𝙖𝙢𝙗𝙙𝙖 могут помочь вам легко применить любую логику к вашим столбцам, используя следующий формат:
𝙙𝙛[𝙣𝙚𝙬_𝙘𝙤𝙡] = 𝙙𝙛.𝙖𝙥𝙥𝙡𝙮(𝙡𝙖𝙢𝙗𝙙𝙖 𝙧𝙤𝙬: 𝙛𝙪𝙣𝙘(𝙧𝙤𝙬), 𝙖𝙭𝙞𝙨=1) где:
𝙙𝙛- это ваш фрейм данных.𝙧𝙤𝙬будет соответствовать каждой строке в вашем фрейме данных.𝙛𝙪𝙣𝙘- это функция, которую вы хотите применить к своему фрейму данных.𝙖𝙭𝙞𝙨=1примените эту функцию к каждой строке в вашем фрейме данных.
Проиллюстрируем ниже:
import pandas as pd
# Create the dataframe
candidates= {
'Name':["Aida","Mamadou","Ismael","Aicha","Fatou", "Khalil"],
'Degree':['Master','Master','Bachelor', "PhD", "Master", "PhD"],
'From':["Abidjan","Dakar","Bamako", "Abidjan","Konakry", "Lomé"],
'Years_exp': [2, 3, 0, 5, 4, 3],
'From_office(min)': [120, 95, 75, 80, 100, 34]
}
candidates_df = pd.DataFrame(candidates)
"""
----------------My custom function-------------------
"""
def candidate_info(row):
# Select columns of interest
name = row.Name
is_from = row.From
year_exp = row.Years_exp
degree = row.Degree
from_office = row["From_office(min)"]
# Generate the description from previous variables
info = f"""{name} from {is_from} holds a {degree} degree
with {year_exp} year(s) experience
and lives {from_office} from the office"""
return info
"""
-------Application of the function to the data ------
"""
candidates_df["Description"] = candidates_df.apply(lambda row: candidate_info(row), axis=1)Функция candidate_info объединяет информацию о каждом кандидате, чтобы создать один столбец описания этого кандидата.
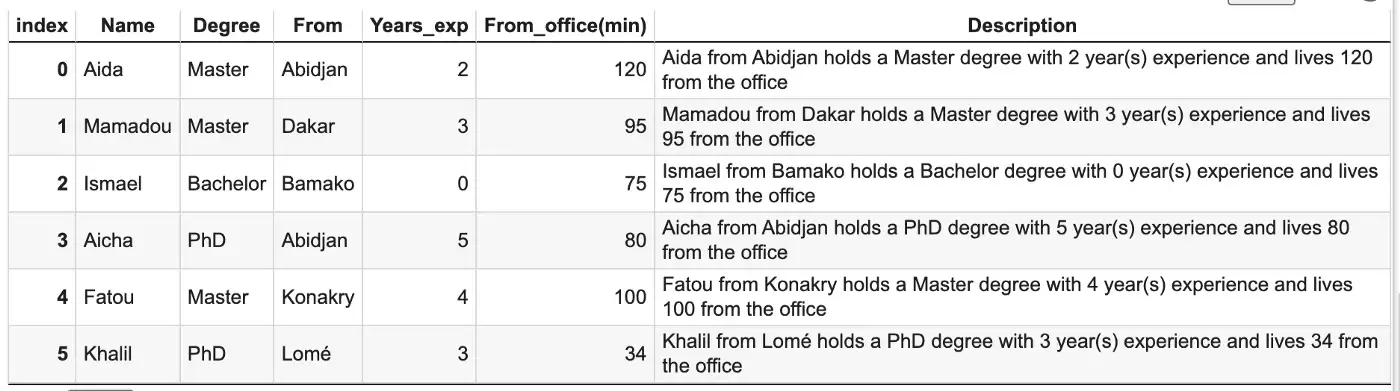
2. Преобразование категориальных данных в числовые
Этот процесс в основном может происходить на этапе разработки функциональных возможностей. Некоторые из его преимуществ заключаются в следующем:
- идентификация выбросов, недопустимых и отсутствующих значений в данных.
- снижение вероятности переоснащения за счет создания более надежных моделей.
Используйте эти две функции от Pandas, в зависимости от ваших потребностей. Примеры приведены на изображении ниже.
.𝙘𝙪𝙩()чтобы конкретно определить края вашей ячейки.
Сценарий
Классифицируйте кандидатов по экспертным знаниям в зависимости от их количества опыта, где:
- Entry level: 0–1 года
- Mid-level: 2–3 года
- Senior level: 4–5 лет
seniority = ['Entry level', 'Mid level', 'Senior level']
seniority_bins = [0, 1, 3, 5]
candidates_df['Seniority'] = pd.cut(candidates_df['Years_exp'],
bins=seniority_bins,
labels=seniority,
include_lowest=True)
candidates_df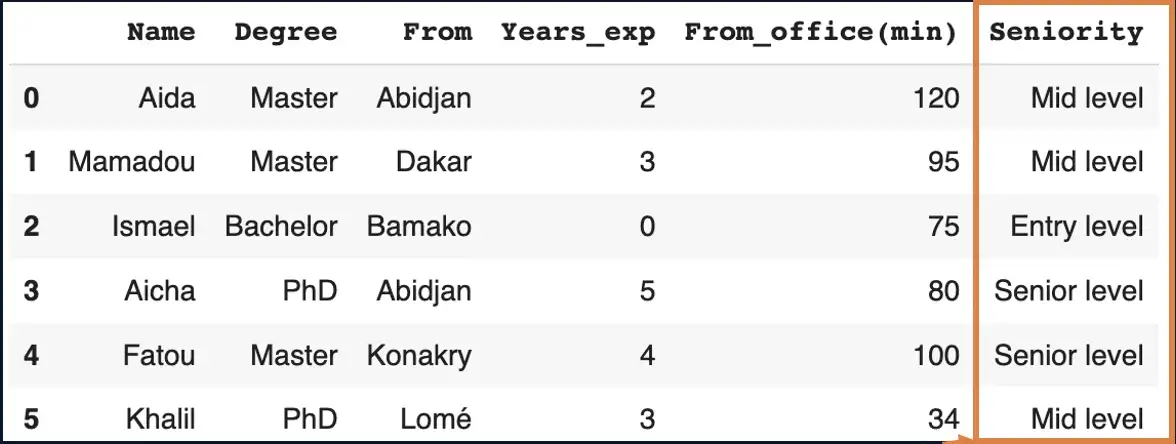
.𝙦𝙘𝙪𝙩()чтобы разделить ваши данные на ячейки одинакового размера.
Он использует базовые процентили распределения данных, а не границы ячеек.
Сценарий
Распределите время поездок кандидатов на работу по категориям: good, acceptable и too long,
commute_time_labels = ["good", "acceptable", "too long"]
candidates_df["Commute_level"] = pd.qcut(
candidates_df["From_office(min)"],
q = 3,
labels=commute_time_labels
)
candidates_df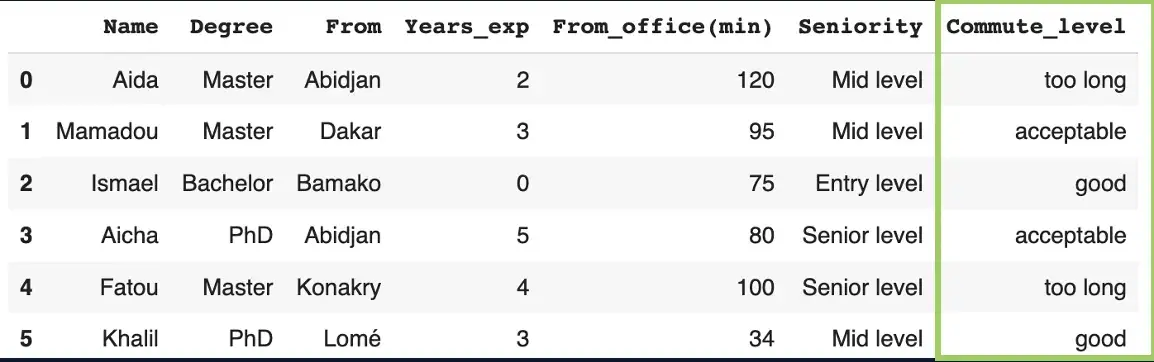
Имеем в виду, что:
- При использовании
.𝙘𝙪𝙩(): количество ячеек = количество меток + 1. - При использовании
.𝙦𝙘𝙪𝙩(): количество ячеек = количество меток. - С
.𝙘𝙪𝙩(): настраивайте𝙞𝙣𝙘𝙡𝙪𝙙𝙚_𝙡𝙤𝙬𝙚𝙨𝙩=𝙏𝙧𝙪𝙚, в противном случае наименьшее значение будет преобразовано в NaN.
3. Выбор строки из фрейма данных Pandas на основе значений столбцов
- используйте функцию
.𝙦𝙪𝙚𝙧𝙮(), указав условие фильтрации. - выражение фильтра может содержать любые операторы (<, >, ==, != и др.)
- используйте знак
@, чтобы использовать переменную в выражении.
# Get all the candidates with a Master degree
ms_candidates = candidates_df.query("Degree == 'Master'")
# Get non bachelor candidates
no_bs_candidates = candidates_df.query("Degree != 'Bachelor'")
# Get values from list
list_locations = ["Abidjan", "Dakar"]
candiates = candidates_df.query("From in @list_locations")
# Get all the candidates with a Master degree
ms_candidates = candidates_df.query("Degree == 'Master'")
# Get non bachelor candidates
no_bs_candidates = candidates_df.query("Degree != 'Bachelor'")
# Get values from list
list_locations = ["Abidjan", "Dakar"]
candiates = candidates_df.query("From in @list_locations")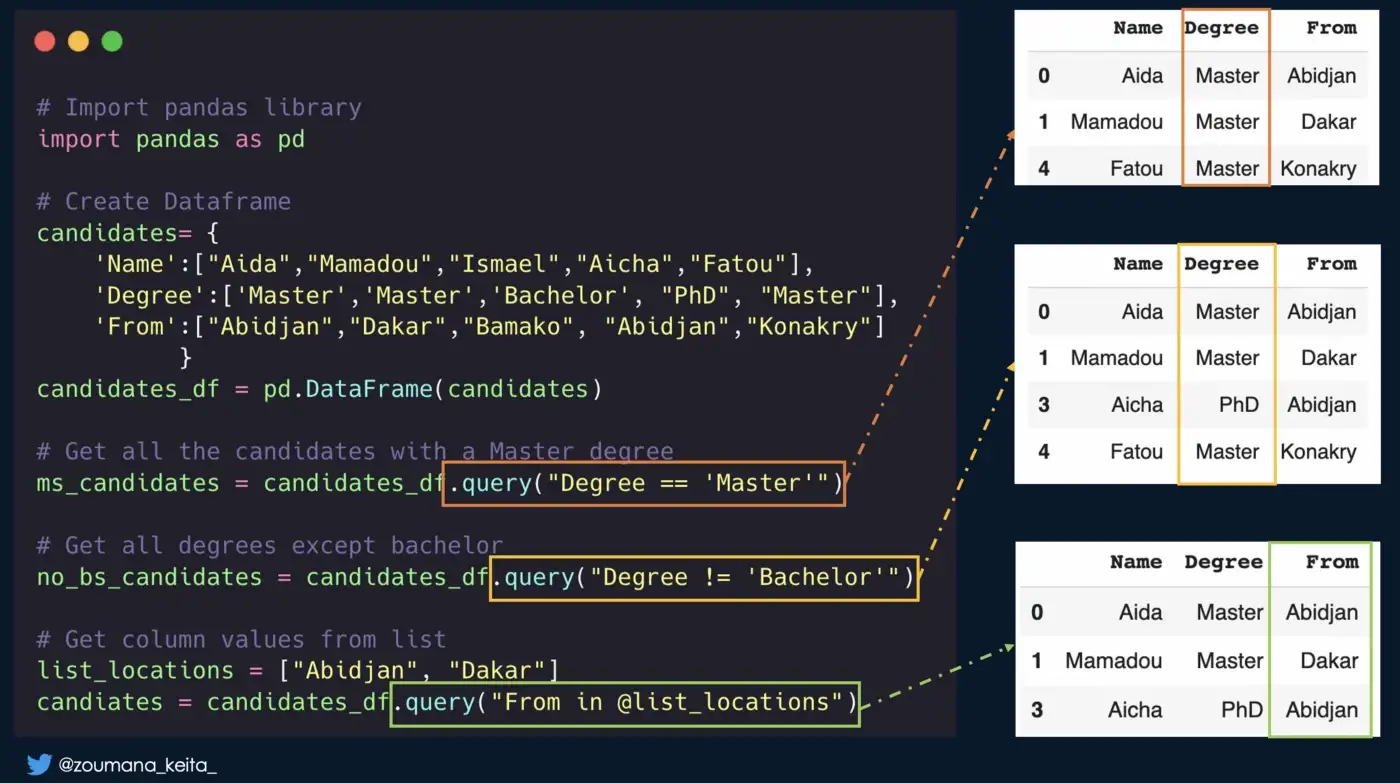
4. Работа с zip-файлами
Иногда может быть эффективно читать и записывать zip-файлы, не извлекая их с вашего локального диска. Ниже приведена иллюстрация.
import pandas as pd
"""
------------ READ ZIP FILES -----------
"""
# Case 1: read a single zip file
candidate_df_unzip = pd.read_csv('candidates.csv.zip', compression='zip')
# Case 2: read a file from a folder
from zipfile import ZipFile
# Read the file from a zip folder
sales_df = pd.read_csv(ZipFile("data.zip").open('data/sales_df.csv'))
"""
------------ WRITE ZIP FILES -----------
"""
# Read data from internet
url = "https://raw.githubusercontent.com/keitazoumana/Fastapi-tutorial/master/data/spam.csv"
spam_data = pd.read_csv(url, encoding="ISO-8859-1")
# Save it as a zip file
spam_data.to_csv("spam.csv.zip", compression="zip")
# Check the files sizes
from os import path
path.getsize('spam.csv') / path.getsize('spam.csv.zip')5. Выбор подмножества вашего фрейма данных Pandas с определенными типами столбцов
Вы можете использовать функцию 𝙨𝙚𝙡𝙚𝙘𝙩_𝙙𝙩𝙮𝙥𝙚𝙨. Он принимает два основных параметра: include и exclude.
𝚍𝚏.𝚜𝚎𝚕𝚎𝚌𝚝_𝚍𝚝𝚢𝚙𝚎𝚜(𝚒𝚗𝚌𝚕𝚞𝚍𝚎 = [‘𝚝𝚢𝚙𝚎_𝟷’, ‘𝚝𝚢𝚙𝚎_𝟸’, … ‘𝚝𝚢𝚙𝚎_𝚗’])означает, что нам нужно подмножество нашего фрейма данных СО столбцами 𝚝𝚢𝚙𝚎_𝟷, 𝚝𝚢𝚙𝚎_𝟸,…, 𝚝𝚢𝚙𝚎_𝚗.𝚍𝚏.𝚜𝚎𝚕𝚎𝚌𝚝_𝚍𝚝𝚢𝚙𝚎𝚜(𝚎𝚡𝚌𝚕𝚞𝚍𝚎 = [‘𝚝𝚢𝚙𝚎_𝟷’, ‘𝚝𝚢𝚙𝚎_𝟸’, … ‘𝚝𝚢𝚙𝚎_𝚗’])означает, что нам нужно подмножество моего фрейма данных БЕЗ столбцов 𝚝𝚢𝚙𝚎_𝟷, 𝚝𝚢𝚙𝚎_𝟸,…, 𝚝𝚢𝚙𝚎_𝚗.
Ниже приведена иллюстрация
# Import pandas library
import pandas as pd
# Read my dataset
candidates_df = pd.read_csv("./data/candidates_data.csv")
# Check the data columns' types
candidates_df.dtypes
# Only select columns of type "object" & "datetime"
candidates_df.select_dtypes(include = ["object", "datetime64"])
# Exclude columns of type "datetime" & "int"
candidates_df.select_dtypes(exclude = ["int64", "datetime64"])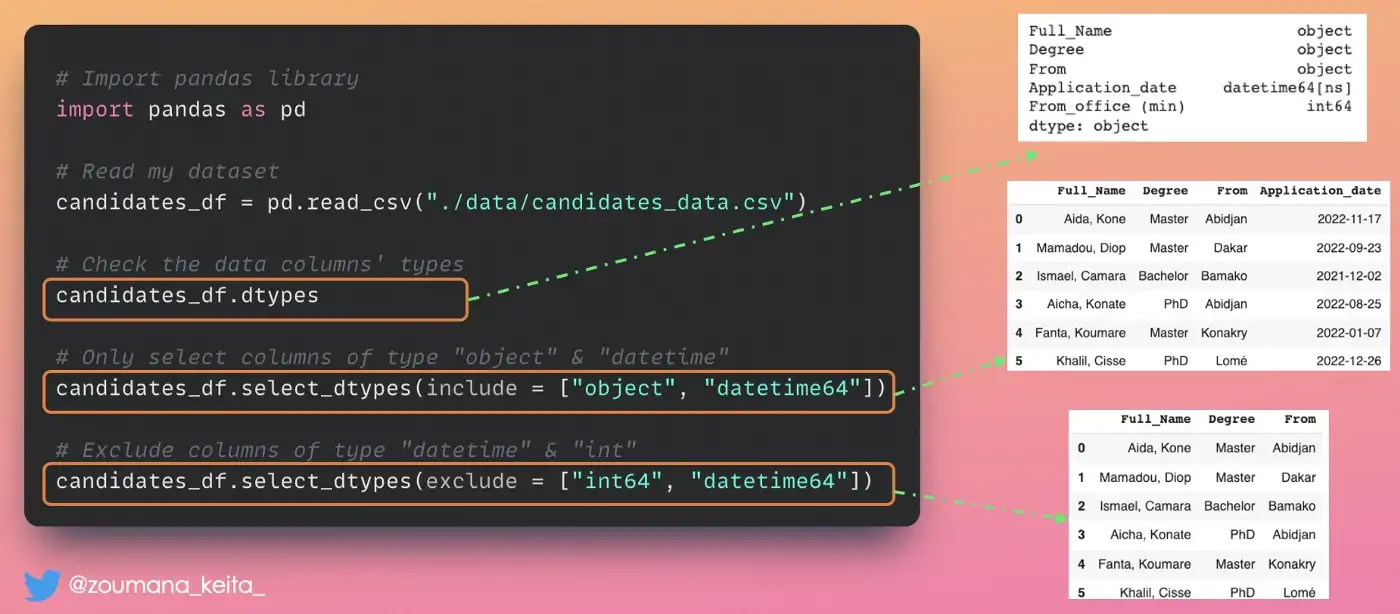
6. Удаление комментарий из столбца фрейма данных Pandas.
Представьте, что мы хотим очистить эти данные (candidates.csv), удалив комментарии из столбца даты заявки. Это можно сделать на лету при загрузке фрейма данных pandas с помощью параметра 𝙘𝙤𝙢𝙢𝙚𝙣𝙩 следующим образом:
𝚌𝚕𝚎𝚊𝚗_𝚍𝚊𝚝𝚊 = 𝚙𝚍.𝚛𝚎𝚊𝚍_𝚌𝚜𝚟(𝚙𝚊𝚝𝚑_𝚝𝚘_𝚍𝚊𝚝𝚊, 𝙘𝙤𝙢𝙢𝙚𝙣𝙩=’𝚜𝚢𝚖𝚋𝚘𝚕’)В нашем случае 𝙘𝙤𝙢𝙢𝙚𝙣𝙩=’#’, но это может быть любой другой символ (|, / и т. д.) в зависимости от вашего случая. Иллюстрация — это первый сценарий.
Подождите, а что, если мы захотим создать новый столбец для этих комментариев и при этом удалить их из столбца даты подачи заявки? Иллюстрацией является второй сценарий.
# Import pandas library
import pandas as pd
# Read my messy dataset
messy_df = pd.read_csv("./data/candidates_data.csv")
# FIRST SCENARIO -> REMOVE COMMENTS
clean_df = pd.read_csv("./data/candidates_data.csv", comment='#')
# SECOND SCENARIO -> CREATE NEW COLUMN FOR COMMENTS
messy_df[['application_date', 'comment']] = messy_df['application_date'].str.split('#', 1, expand=True)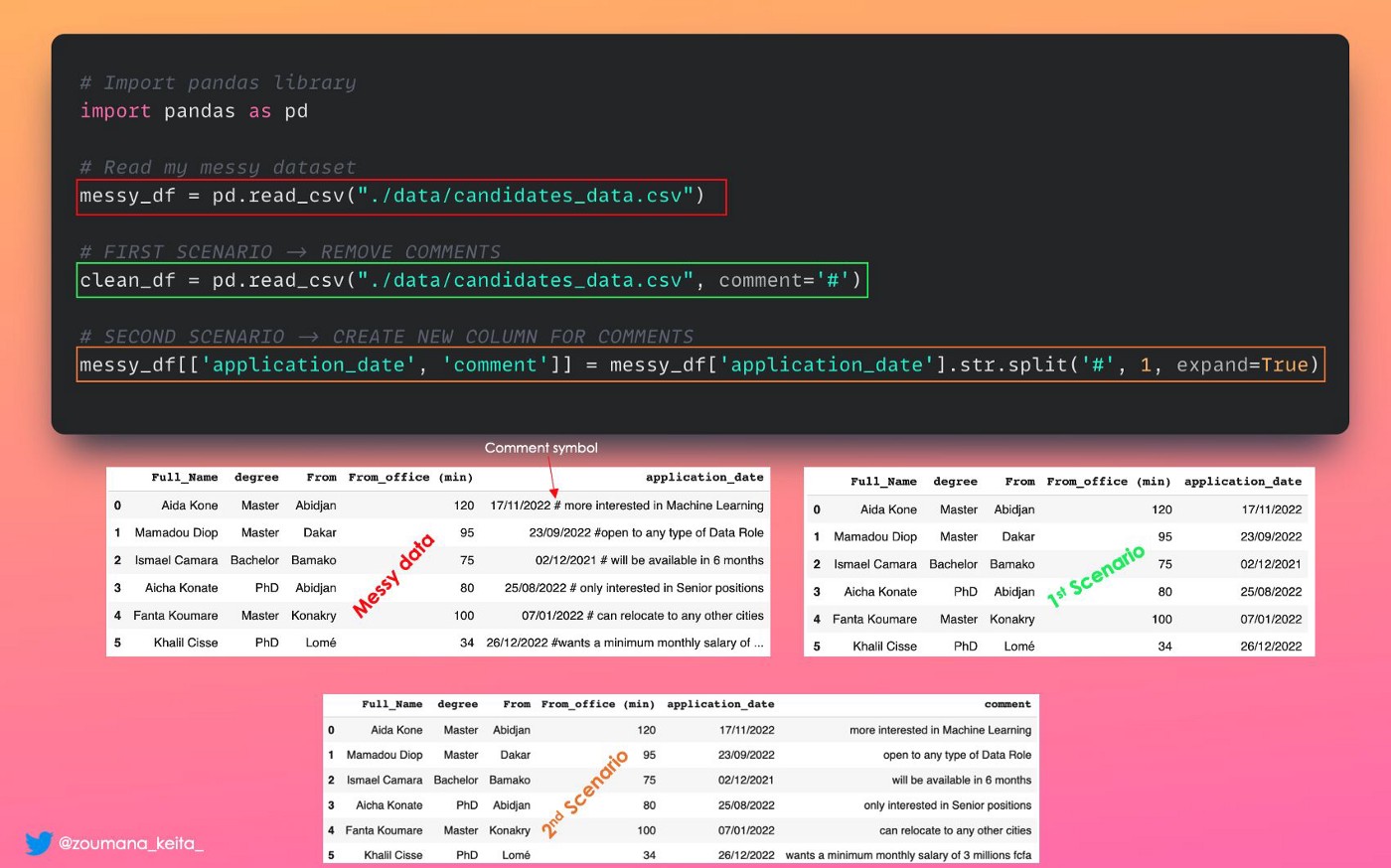
7. Печать фрейма данных Pandas в табличном формате с консоли
Нет, применение функции 𝚙𝚛𝚒𝚗𝚝() к фрейму данных pandas не всегда обеспечивает вывод, который легко читается, особенно для фреймов данных с несколькими столбцами.
Если вы хотите получить приятный для консоли табличный вывод, используйте функцию .𝚝𝚘_𝚜𝚝𝚛𝚒𝚗𝚐(), как показано ниже.
# Import pandas library
import pandas as pd
data_URL = "https://raw.githubusercontent.com/keitazoumana/Experimentation-Data/main/vgsales.csv"
# Read your dataframe
video_game_data = pd.read_csv(data_URL)
"""
Printing without to_string() function
"""
print(video_game_data.head())
"""
Printing with to_string() function
"""
print(video_game_data.head().to_string())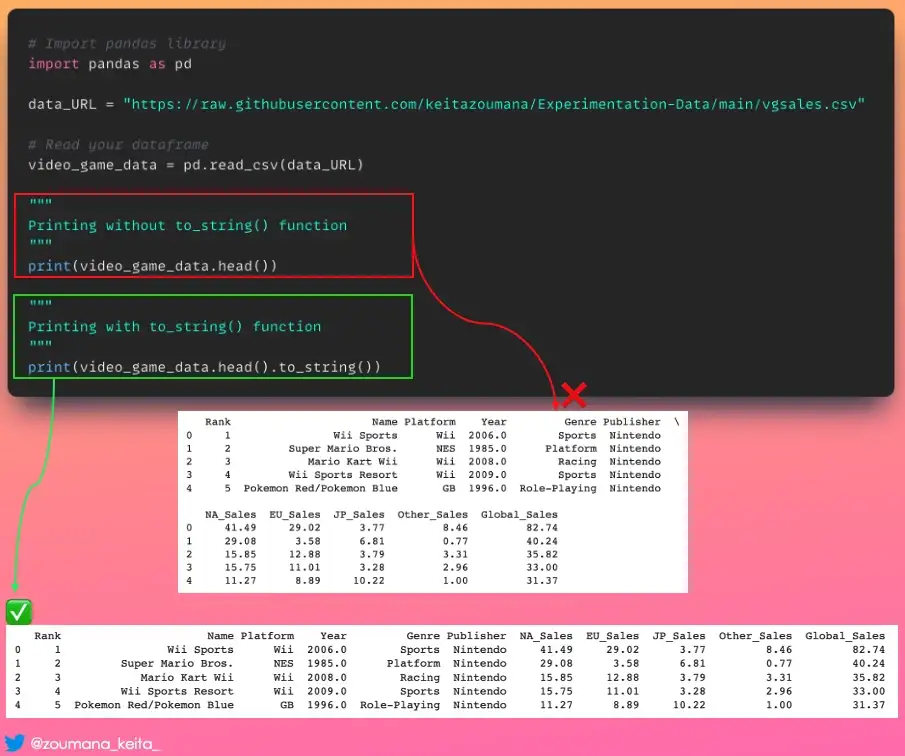
8. Выделение точек данных в Pandas
Применение цветов к фрейму данных pandas может быть хорошим способом выделить определенные точки данных для быстрого анализа.
Вот где пригодится модуль 𝚙𝚊𝚗𝚍𝚊𝚜.𝚜𝚝𝚢𝚕𝚎. Он имеет множество функций, но не ограничивается следующими:
𝚍𝚏.𝚜𝚝𝚢𝚕𝚎.𝚑𝚒𝚐𝚑𝚕𝚒𝚐𝚑𝚝_𝚖𝚊𝚡()чтобы присвоить цвет максимальному значению каждого столбца.𝚍𝚏.𝚜𝚝𝚢𝚕𝚎.𝚑𝚒𝚐𝚑𝚕𝚒𝚐𝚑𝚝_𝚖in()чтобы присвоить цвет минимальному значению каждого столбца.𝚍𝚏.𝚜𝚝𝚢𝚕𝚎.𝚊𝚙𝚙𝚕𝚢(𝚖𝚢_𝚌𝚞𝚜𝚝𝚘𝚖_𝚏𝚞𝚗𝚌𝚝𝚒𝚘𝚗)чтобы применить вашу пользовательскую функцию к вашему фрейму данных.
import pandas as pd
my_info = {
"Salary": [100000.2, 95000.9, 103000.2, 65984.1, 150987.08],
"Height": [6.5, 5.2, 5.59, 6.7, 6.92],
"weight": [185.23, 105.12, 110.3, 190.12, 200.59]
}
my_data = pd.DataFrame(my_info)
"""
Function to highlight min and max
"""
def highlight_min_max(data_frame, min_color, max_color):
# This first line create a styler object
final_data = data_frame.style.highlight_max(color = max_color)
# On this second line, no need to use ".style"
final_data = final_data.highlight_min(color = min_color)
return final_data
# Function to apply ORANGE to min and GREEN to max
highlight_min_max(my_data, min_color='orange', max_color='green')
"""
Custom function: apply RED or GREEN whether data is below or above the mean.
"""
def highlight_values(data_row):
low_value_color = "background-color:#C4606B ; color: white;"
high_value_color = "background-color: #C4DE6B; color: white;"
filter = data_row < data_row.mean()
return [low_value_color if low_value else high_value_color for low_value in filter]
# Application of my custom function to only 'Height' & 'weight'
my_data.style.apply(highlight_values, subset=['Height', 'weight'])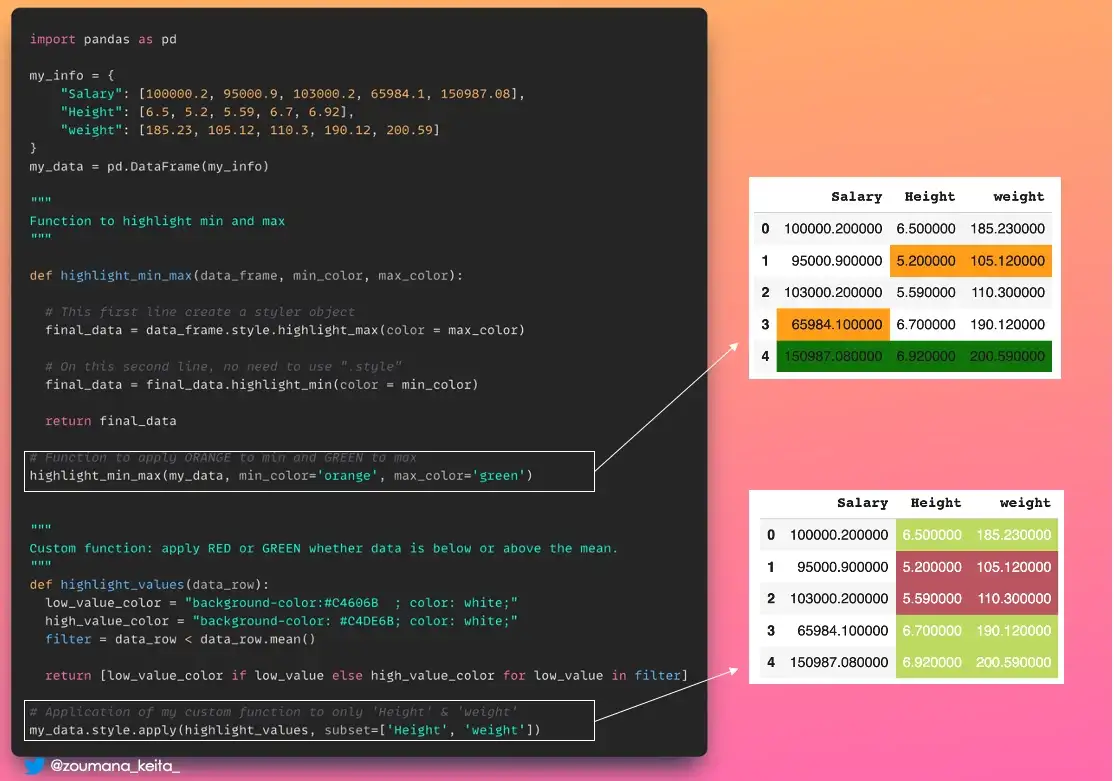
9. Уменьшение количества десятичных знаков в ваших данных
Иногда очень длинные десятичные значения в вашем наборе данных не дают существенной информации, и на них бывает больно смотреть
Таким образом, вы можете преобразовать свои данные примерно в 2-3 десятичных знака, чтобы облегчить анализ.
Это то, что вы можете выполнить с помощью функции 𝚙𝚊𝚗𝚍𝚊𝚜.𝙳𝚊𝚝𝚊𝙵𝚛𝚊𝚖𝚎.𝚛𝚘𝚞𝚗𝚍(), как показано ниже.
long_decimals_info = {
"Salary": [100000.23400000, 95000.900300, 103000.2300535, 65984.14000450, 150987.080345],
"Height": [6.501050, 5.270000, 5.5900001050, 6.730001050, 6.92100050],
"weight": [185.23000059, 105.1200099, 110.350003, 190.12000000, 200.59000000]
}
long_decimals_df = pd.DataFrame(long_decimals_info)
"""
Format the data with 2 decimal places
"""
fewer_decimals_df = long_decimals_df.round(decimals=2)
fewer_decimals_df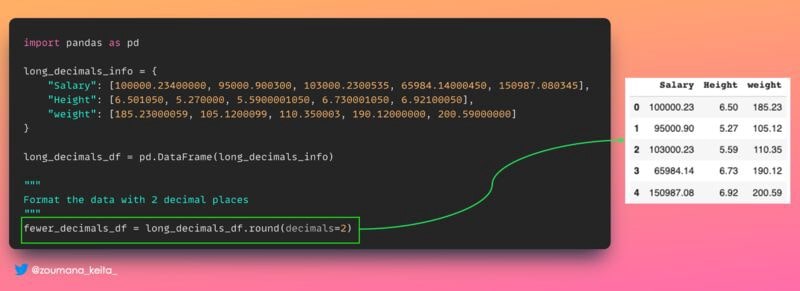
10. Замена некоторых значений в вашем фрейме данных
Возможно, вы захотите заменить некоторую информацию в своем фрейме данных, чтобы поддерживать ее как можно более актуальной.
Этого можно достичь с помощью функции Pandas 𝚍𝚊𝚝𝚊𝚏𝚛𝚊𝚖𝚎.𝚛𝚎𝚙𝚕𝚊𝚌𝚎(), как показано ниже.проиллюстрировано ниже.
import pandas as pd
import numpy as np
candidates_info = {
'Full_Name':["Aida Kone","Mamadou Diop","Ismael Camara","Aicha Konate",
"Fanta Koumare", "Khalil Cisse"],
'degree':['Master','MS','Bachelor', "PhD", "Masters", np.nan],
'From':[np.nan,"Dakar","Bamako", "Abidjan","Konakry", "Lomé"],
'Age':[23,26,19, np.nan,25, np.nan],
}
candidates_df = pd.DataFrame(candidates_info)
"""
Replace Masters, Master by MS
"""
degrees_to_replace = ["Master", "Masters"]
candidates_df.replace(to_replace = degrees_to_replace, value = "MS", inplace=True)
"""
Replace all the NaN by "Missing"
"""
candidates_df.replace(to_replace=np.nan, value = "Missing", inplace=True)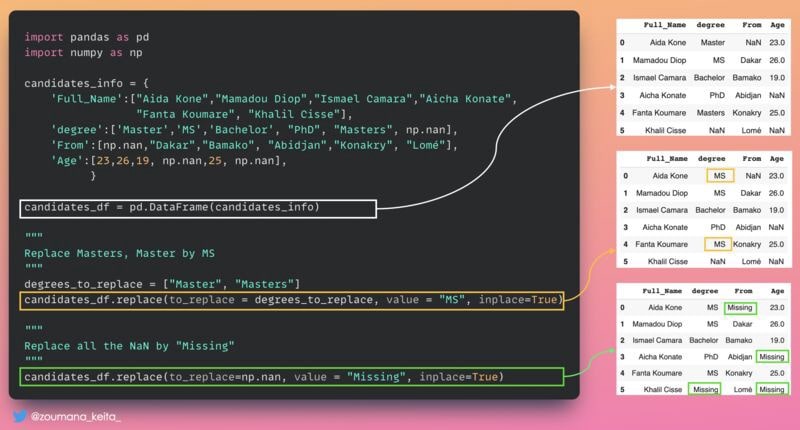
11. Сравнение двух фреймов данных и определение их различий
Иногда, сравнивая два фрейма данных pandas, вы хотите не только знать, эквивалентны ли они, но и в чем разница, если они не эквивалентны.
Это то место, где .Функция .𝚌𝚘𝚖𝚙𝚊𝚛𝚎() пригодится.
Он генерирует фрейм данных, показывающий столбцы с различиями рядом друг с другом. Его форма отличается от (0, 0) только в том случае, если два сравниваемых данных совпадают.
Если вы хотите отображать одинаковые значения, установите для параметра 𝚔𝚎𝚎𝚙_𝚎𝚚𝚞𝚊𝚕 значение 𝚃𝚛𝚞𝚎. В противном случае они отображаются как 𝙽𝚊𝙽.
import pandas as pd
from pandas.testing import assert_frame_equal
candidates_df = pd.read_csv("data/candidates.csv")
"""
Create a second dataframe by changing "Full_Name" & "Age" columns
"""
candidates_df_test = candidates_df.copy()
candidates_df_test.loc[0, 'Full_Name'] = 'Aida Traore'
candidates_df_test.loc[2, 'Age'] = 28
"""
Compare the two dataframes: candidates_df & candidates_df_test
"""
# 1. Comparison showing only unmatching values
candidates_df.compare(candidates_df_test)
# 2. Comparison including similar values
candidates_df.compare(candidates_df_test, keep_equal=True)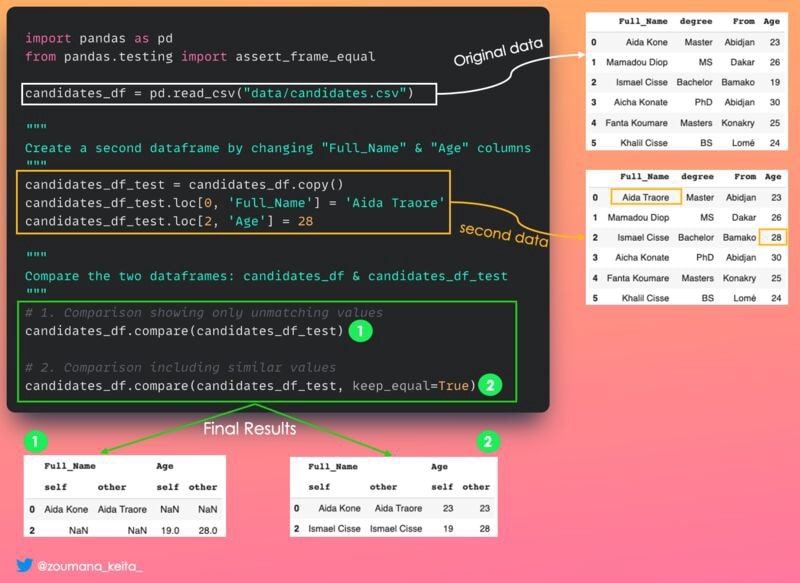
12. Получение подмножества очень большого набора данных для быстрого анализа
Иногда нам просто нужно подмножество очень большого набора данных для быстрого анализа. Одним из подходов может быть чтение всех данных в памяти перед получением образца.
Это может потребовать много памяти в зависимости от того, насколько велики ваши данные. Кроме того, чтение ваших данных может занять значительное время.
Вы можете использовать параметр 𝚗𝚛𝚘𝚠𝚜 в функции pandas 𝚛𝚎𝚊𝚍_𝚌𝚜𝚟(), указав необходимое количество строк.
# Pandas library
import pandas as pd
# Load execution time
%load_ext autotime
# File to get sample from: Size: 261,6 MB
large_data = "diabetes_benchmark_data.csv"
# Sample size of interest
sample_size = 400
"""
Approach n°1: Read all the data in memory before getting the sample
"""
read_whole_data = pd.read_csv(large_data)
sample_data = read_whole_data.head(sample_size)
"""
Approach n°2: Read the sample on the fly
"""
read_sample = pd.read_csv(large_data, nrows=sample_size)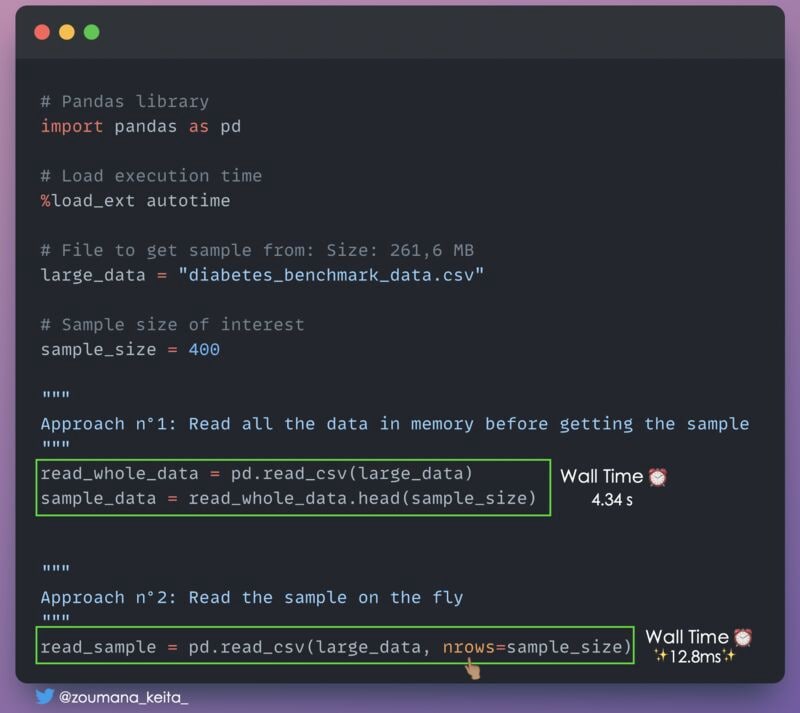
13. Преобразование фрейма данных из широкого формата в длинный
Иногда это может быть полезно 𝚝𝚛𝚊𝚗𝚜𝚏𝚘𝚛𝚖 𝚍𝚊𝚝𝚊𝚏𝚛𝚊𝚖𝚎 𝚏𝚛𝚘𝚖 𝚊 𝚠𝚒𝚍𝚎 𝚝𝚘 𝚊 𝚕𝚘𝚗𝚐 𝚏𝚘𝚛𝚖𝚊𝚝, что является более гибким для лучшего анализа, особенно при работе с данными временных рядов.
Что имеется в виду под широким и длинным:
- Широкий формат — это когда у вас много колонок.
- С другой стороны, длинный формат — это когда у вас много строк.
𝙿𝚊𝚗𝚍𝚊𝚜.𝚖𝚎𝚕𝚝() идеальный вариант для этой задачи.
Приведем иллюстрацию
import pandas as pd
# My experimentation data
candidates= {
'Name':["Aida","Mamadou","Ismael","Aicha"],
'ID': [1, 2, 3, 4],
'2017':[85, 87, 89, 91],
'2018':[96, 98, 100, 102],
'2019':[100, 102, 106, 106],
'2020':[89, 95, 98, 100],
'2021':[94, 96, 98, 100],
'2022':[100, 104, 104, 107],
}
"""
Data in wide format
"""
salary_data = pd.DataFrame(candidates)
"""
Transformation into the long format
"""
long_format_data = salary_data.melt(id_vars=['Name', 'ID'],
var_name='Year', value_name='Salary(k$)')
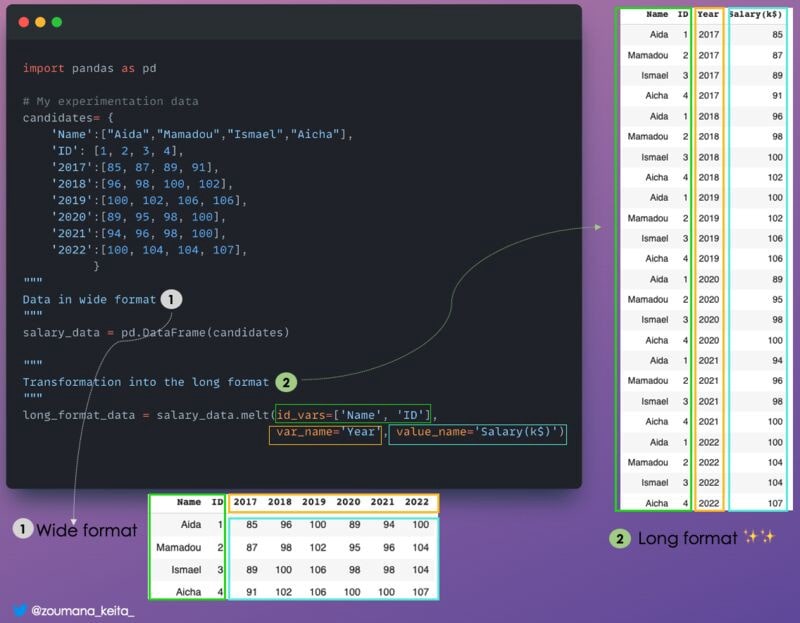
14. Уменьшение размера фрейма данных Pandas, игнорируя индекс
Знаете ли вы, что вы можете уменьшить размер вашего фрейма данных Pandas, игнорируя индекс при его сохранении?
Что-то вроде 𝚒𝚗𝚍𝚎𝚡 = 𝙵𝚊𝚕𝚜𝚎 при сохранении файла.
Выглядит это следующим образом:
import pandas as pd
# Read data from Github
URL = "https://raw.githubusercontent.com/keitazoumana/Experimentation-Data/main/diabetes.csv"
data = pd.read_csv(URL)
# Create large data by repeating each row 10000 times
large_data = data.loc[data.index.repeat(10000)]
"""
SAVE WITH INDEX
"""
large_data.to_csv("large_data_with_index.csv")
# Check the size of the file
!ls -GFlash large_data_with_index.csv
"""
SAVE WITHOUT INDEX
"""
large_data.to_csv("large_data_without_index.csv", index = False)
# Check the size of the file
!ls -GFlash large_data_without_index.csv 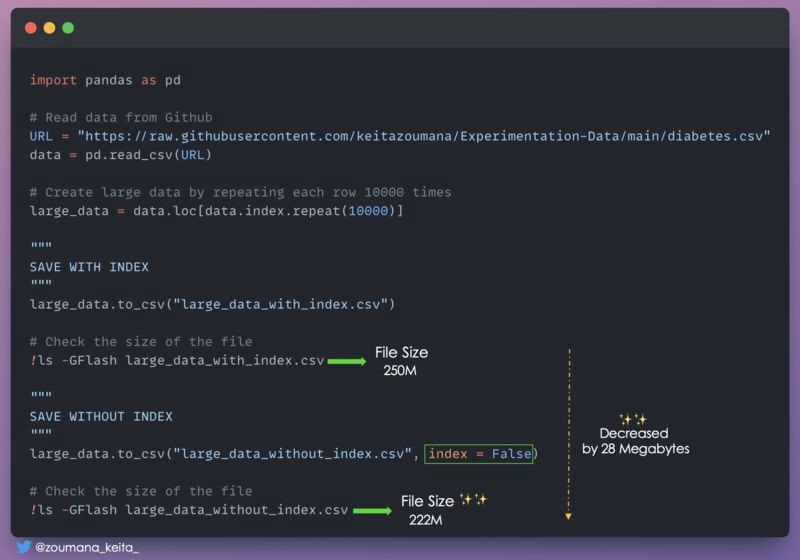
15. Parquet вместо CSV
Вы можете не просматривать вручную содержимое файла CSV или Excel, которое будет использоваться Pandas для дальнейшего анализа. И вам не следует больше использовать .CSV и стоит задуматься о лучшем варианте.
Особенно, если вас волнует только
- Скорость обработки
- Скорость сохранения и загрузки
- Дисковое пространство, занимаемое фреймом данных
В этом случае формат .𝙥𝙖𝙧𝙦𝙪𝙚𝙩 - ваш лучший вариант, как показано ниже. ниже.
import pandas as pd
# Read data from Github
URL = "https://raw.githubusercontent.com/keitazoumana/Experimentation-Data/main/diabetes.csv"
data = pd.read_csv(URL)
# Create large data for experimentation by repeating each row 20.000 times
exp_data = data.loc[data.index.repeat(20000)]
"""
EXPERIMENT WITH .CSV FORMAT
"""
# Write Time
%%time
exp_data.to_csv("exp_data.csv", index=False)
# Read Time
%%time
csv_data = pd.read_csv("exp_data.csv")
# File Size
!ls -GFlash exp_data.csv
"""
EXPERIMENT WITH .PARQUET FORMAT
"""
# Write Time
%%time
exp_data.to_parquet('exp_data.parquet')
# Read Time
%%time
parquet_data = pd.read_parquet('exp_data.parquet')
# File Size
!ls -GFlash exp_data.parquet 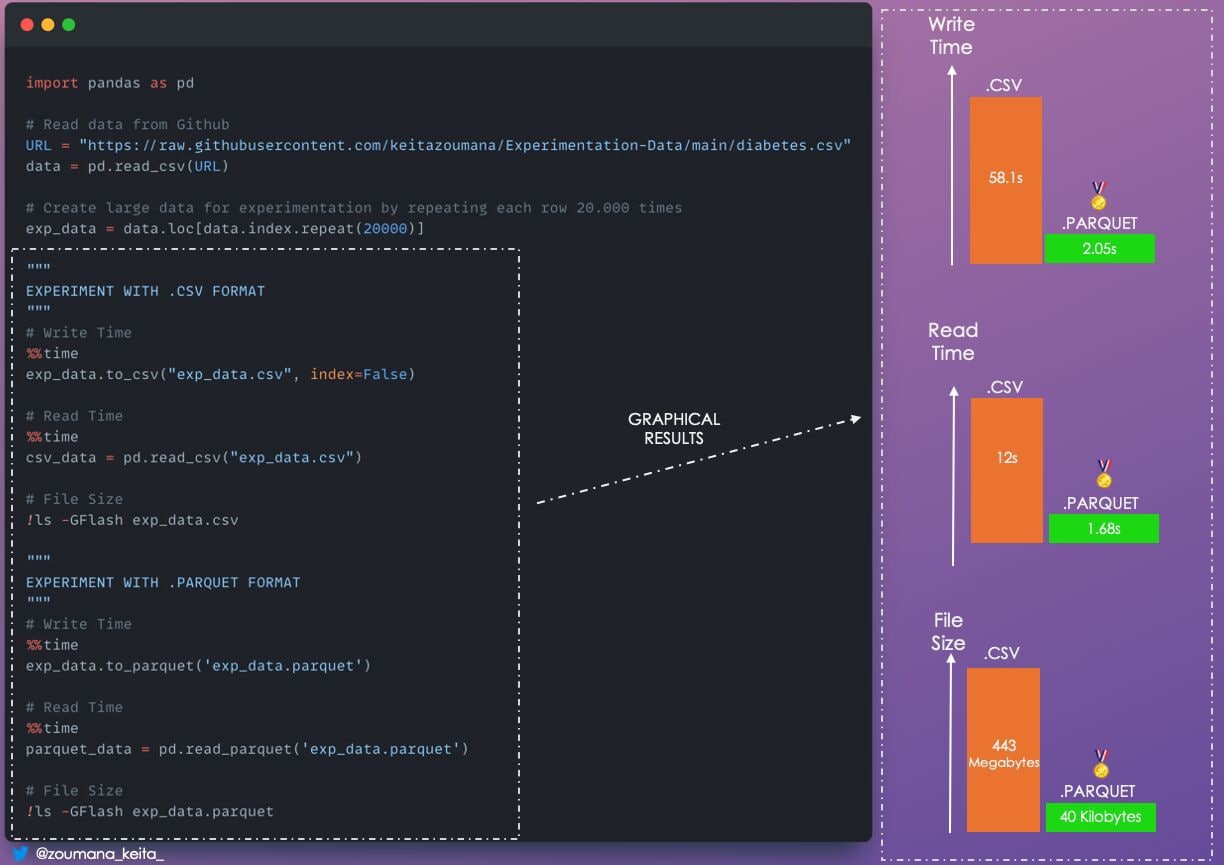
16. Превращение фрейма данных в markdown
Всегда лучше печатать свой фрейм данных таким образом, чтобы его было легче понять.
Один из способов сделать это — отобразить его в формате уценки с помощью функции .𝚝𝚘_𝚖𝚊𝚛𝚔𝚍𝚘𝚠𝚗().
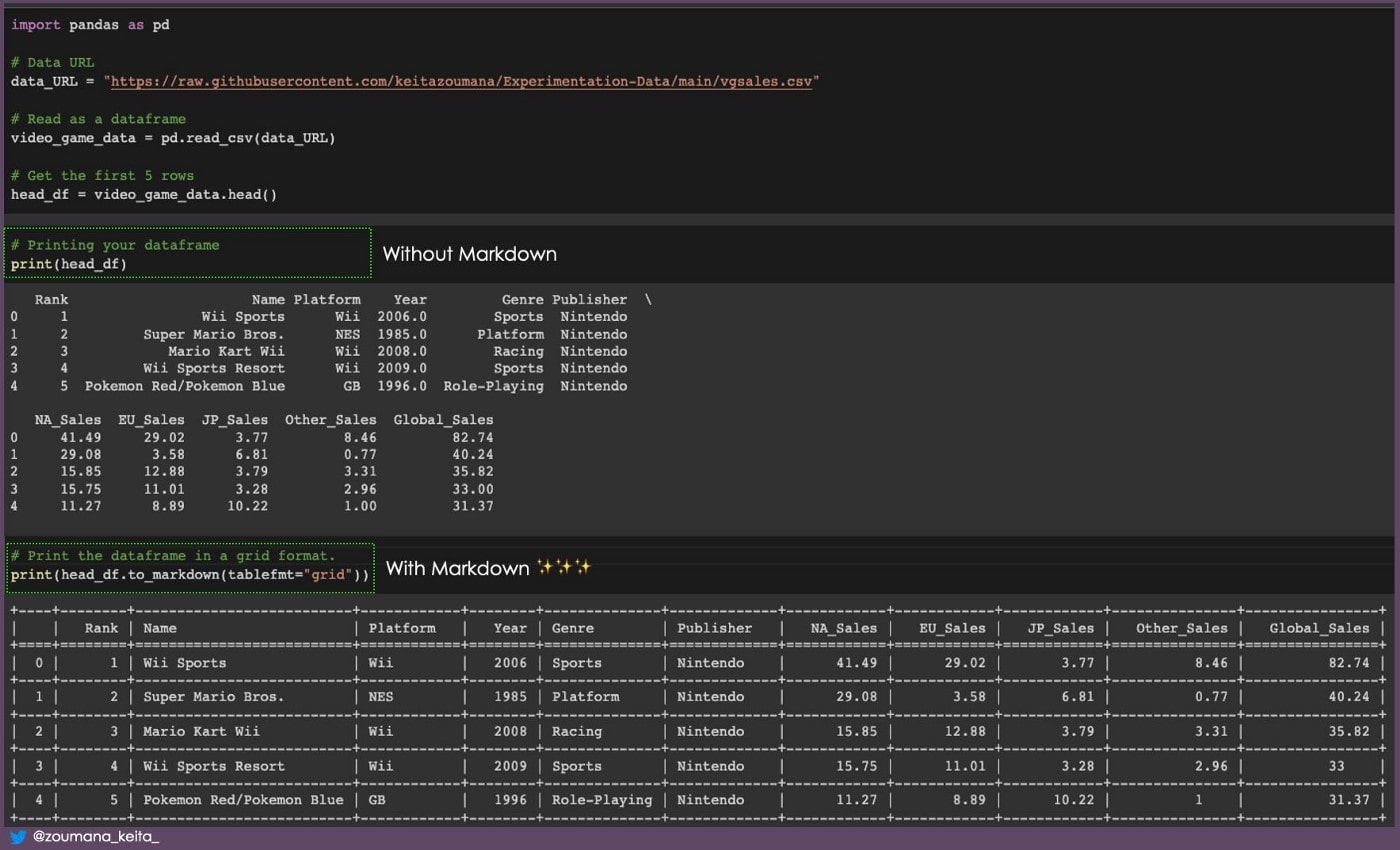
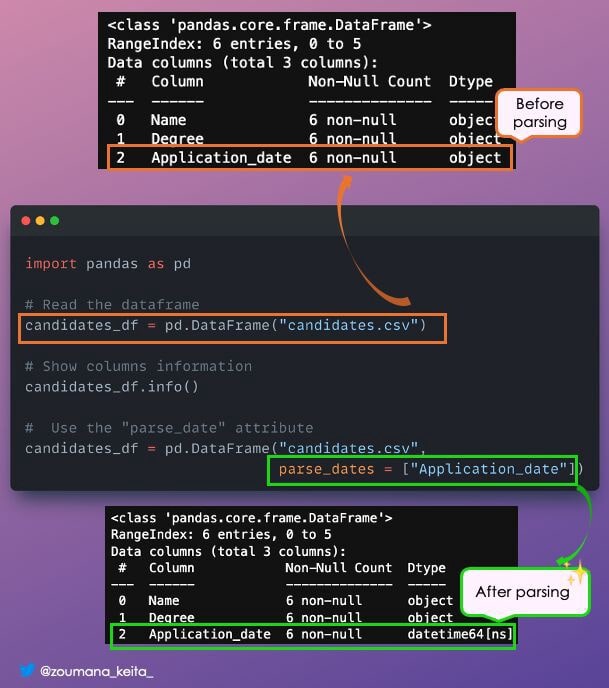
17. Столбец «Формат даты и времени»
При загрузке фреймов данных Pandas столбцы дат по умолчанию представляются как 𝗼𝗯𝗷𝗲𝗰𝘁, что не является правильным форматом даты.
Вы можете указать целевой столбец в аргументе 𝗽𝗮𝗿𝘀𝗲_𝗱𝗮𝘁𝗲𝘀, чтобы получить правильный тип столбца.
Советы и рекомендации по Python
1. Создание индикатора выполнения с помощью tqdm и rich
Использование индикатора выполнения полезно, когда вы хотите иметь визуальный статус данной задачи.
#!pip -q install rich
from rich.progress import track
from tqdm import tqdm
import timeРеализовать функцию обратного вызова
def compute_double(x):
return 2*xСоздайте индикаторы выполнения
final_dict_doubles = {}
for i in track(range(20), description="Computing 2.n..."):
final_dict_doubles[f"Value = {i}"] = f"double = {compute_double(i)}"
# Sleep the process to highligh the progress
time.sleep(0.8)for i in tqdm(range(20), desc="Computing 2.n..."):
final_dict_doubles[f"Value = {i}"] = f"double = {compute_double(i)}"
# Sleep the process to highligh the progress
time.sleep(1)2. Получение: день, месяц, год, день недели, месяц года
candidates= {
'Name':["Aida","Mamadou","Ismael","Aicha","Fatou", "Khalil"],
'Degree':['Master','Master','Bachelor', "PhD", "Master", "PhD"],
'From':["Abidjan","Dakar","Bamako", "Abidjan","Konakry", "Lomé"],
'Application_date': ['11/17/2022', '09/23/2022', '12/2/2021',
'08/25/2022', '01/07/2022', '12/26/2022']
}
candidates_df = pd.DataFrame(candidates)
candidates_df['Application_date'] = pd.to_datetime(candidates_df["Application_date"])
# GET the Values
application_date = candidates_df["Application_date"]
candidates_df["Day"] = application_date.dt.day
candidates_df["Month"] = application_date.dt.month
candidates_df["Year"] = application_date.dt.year
candidates_df["Day_of_week"] = application_date.dt.day_name()
candidates_df["Month_of_year"] = application_date.dt.month_name()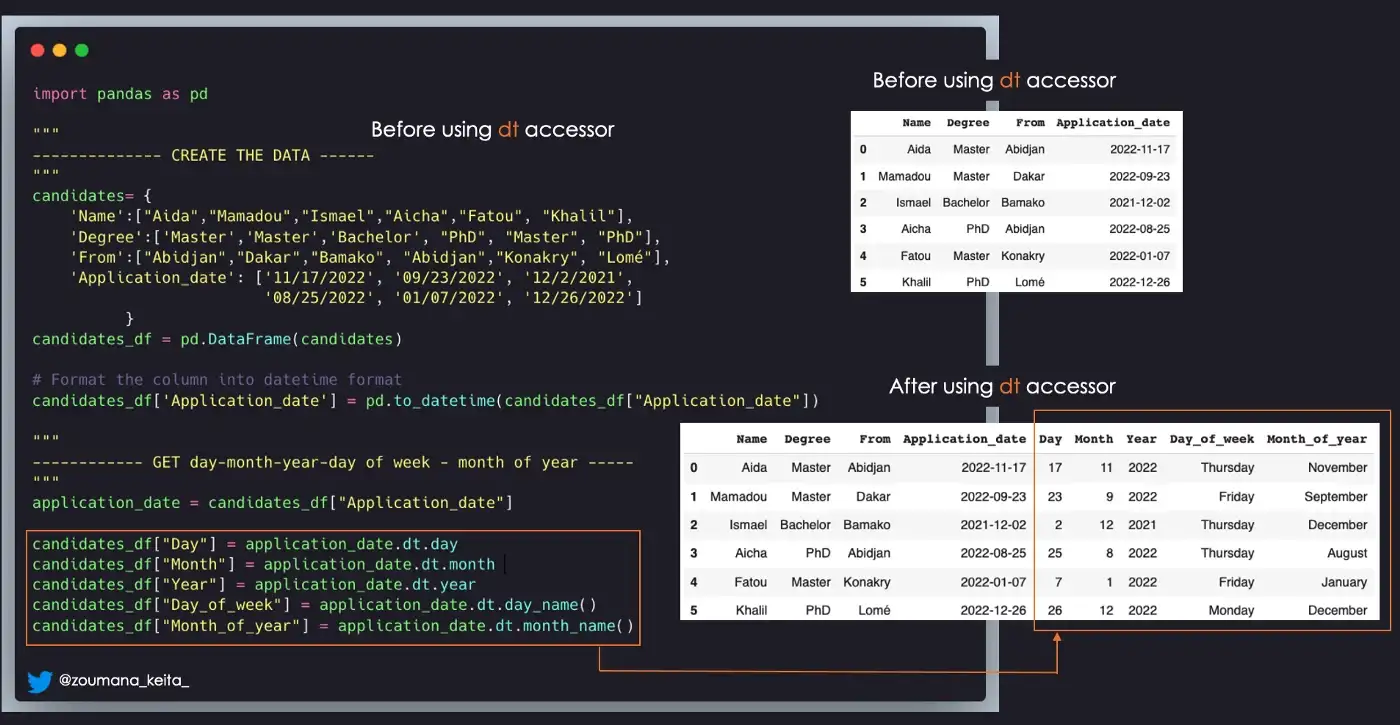
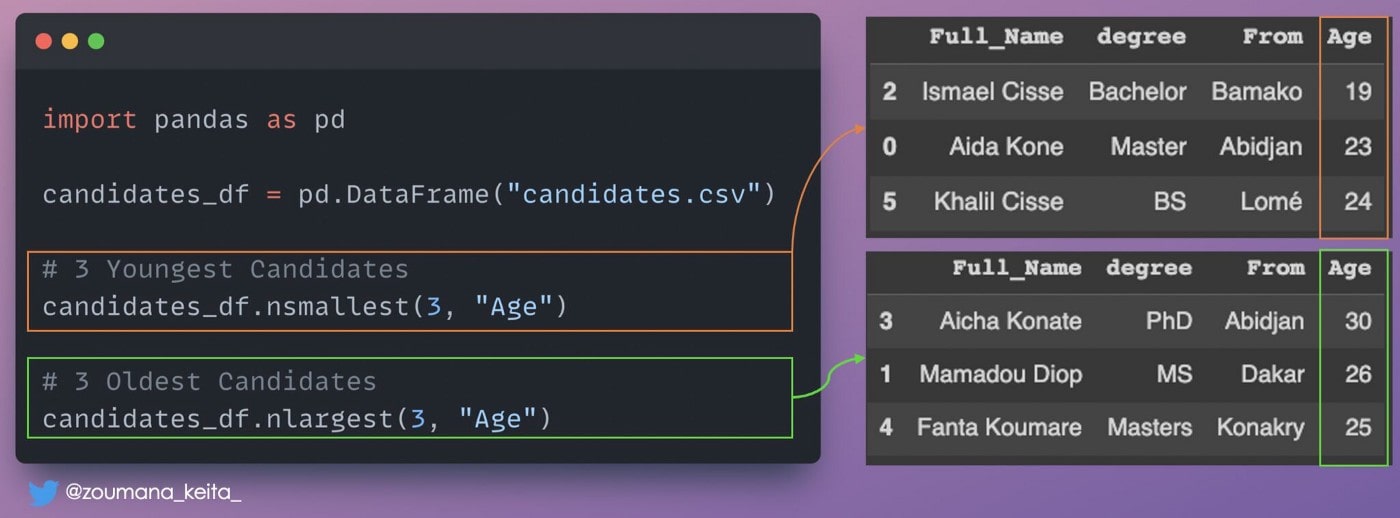
3. Наименьшее и наибольшее значения столбца
Если вы хотите получить строки с наибольшими или наименьшими значениями для данного столбца, вы можете использовать следующие функции:
𝚍𝚏.𝚗𝚕𝚊𝚛𝚐𝚎𝚜𝚝(𝙽, “𝙲𝚘𝚕_𝙽𝚊𝚖𝚎”)→ верхние 𝙽 строки на основе 𝙲𝚘𝚕_𝙽𝚊𝚖𝚎𝚍𝚏.𝚗𝚜𝚖𝚊𝚕𝚕𝚎𝚜𝚝(𝙽, “𝙲𝚘𝚕_𝙽𝚊𝚖𝚎”)→ 𝙽 наименьшие строки на основе 𝙲𝚘𝚕_𝙽𝚊𝚖𝚎𝙲𝚘𝚕_𝙽𝚊𝚖𝚎- имя интересующего вас столбца.
4. Игнорирование вывода журнала команды pip install
Иногда при установке библиотеки из блокнота Jupyter вы можете не захотеть, чтобы все подробности процесса установки генерировались командой по умолчанию 𝚙𝚒𝚙 𝚒𝚗𝚜𝚝𝚊𝚕𝚕.
Вы можете указать опцию -q или -quiet, чтобы избавиться от этой информации.
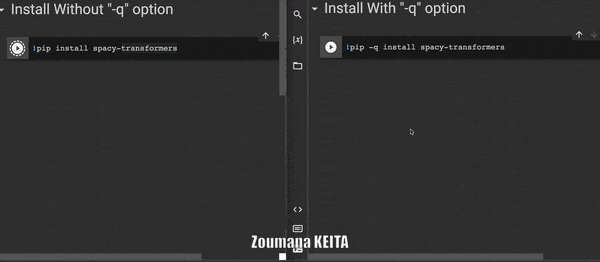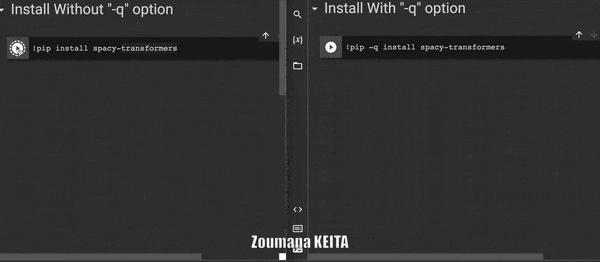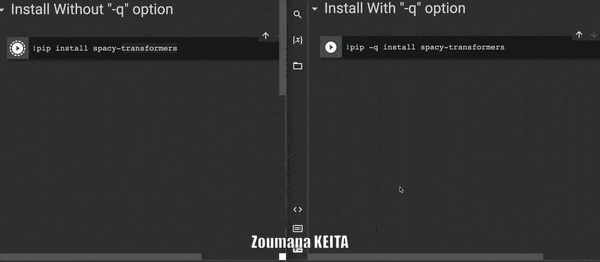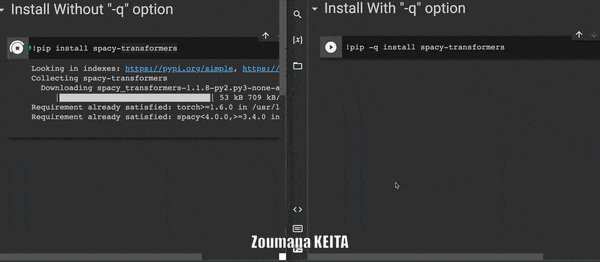
5. Запуск нескольких команд в одной ячейке записной книжки
Восклицательный знак «!» необходим для успешного запуска команды оболочки из вашего ноутбука Jupyter.
Однако этот подход может быть довольно повторяющимся при работе с несколькими командами или очень длинными и сложными.
Лучший способ решить эту проблему — использовать выражение %%𝐛𝐚𝐬𝐡 в начале ячейки блокнота.
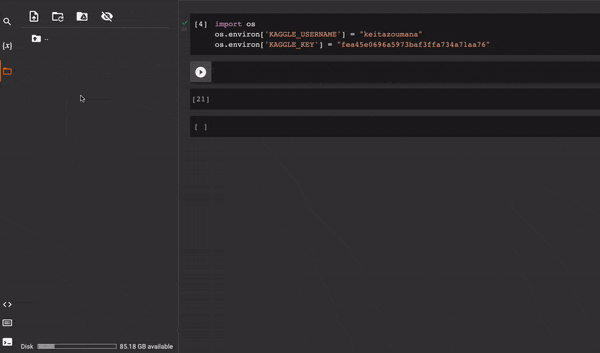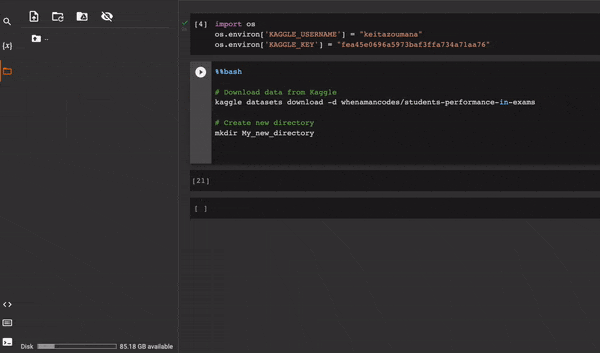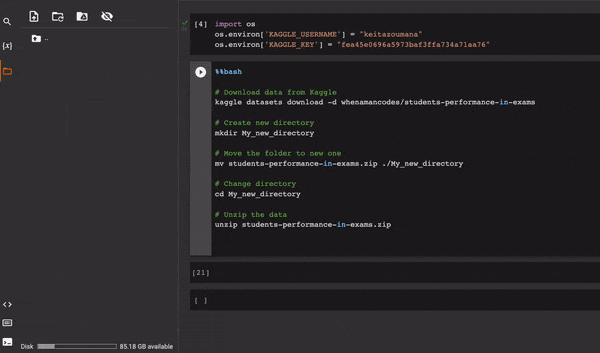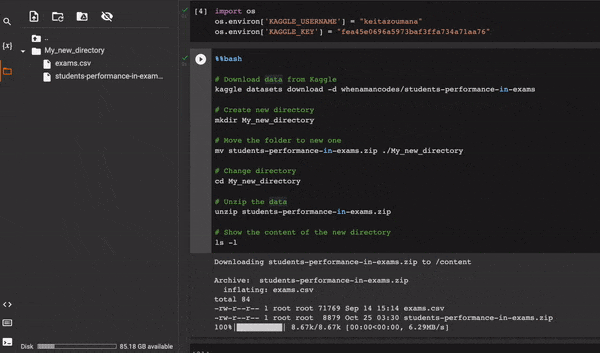
6. Виртуальная среда
Проект Data Science может включать несколько зависимостей, и работа со всеми ними может немного раздражать.
Хорошей практикой является организация вашего проекта таким образом, чтобы им можно было легко поделиться с членами вашей команды и воспроизвести с наименьшими усилиями.
Один из способов сделать это — использовать виртуальные среды.
Cоздание виртуальной среды и установка библиотеки
→ Установите модуль виртуальной среды 𝚙𝚒𝚙 𝚒𝚗𝚜𝚝𝚊𝚕𝚕 𝚟𝚒𝚛𝚝𝚞𝚊𝚕𝚎𝚗𝚟
→ Создайте свою среду, дав осмысленное имя 𝚟𝚒𝚛𝚝𝚞𝚊𝚕𝚎𝚗𝚟 [𝚢𝚘𝚞𝚛_𝚎𝚗𝚟𝚒𝚛𝚘𝚗𝚖𝚎𝚗𝚝_𝚗𝚊𝚖𝚎]
→ Активируйте свою среду 𝚜𝚘𝚞𝚛𝚌𝚎 [𝚢𝚘𝚞𝚛_𝚎𝚗𝚟𝚒𝚛𝚘𝚗𝚖𝚎𝚗𝚝_𝚗𝚊𝚖𝚎]/𝚋𝚒𝚗/𝚊𝚌𝚝𝚒𝚟𝚊𝚝𝚎
→ Начать установку зависимостей для вашего проекта 𝚙𝚒𝚙 𝚒𝚗𝚜𝚝𝚊𝚕𝚕 𝚙𝚊𝚗𝚍𝚊𝚜
Виртуальная среда, которую вы только что создали, является локальной для вашей машины.
Вам необходимо навсегда сохранить эти зависимости, чтобы поделиться ими с другими с помощью этой команды:
→ 𝚙𝚒𝚙 𝚏𝚛𝚎𝚎𝚣𝚎 > 𝚛𝚎𝚚𝚞𝚒𝚛𝚎𝚖𝚎𝚗𝚝𝚜.𝚝𝚡𝚝
Это создаст файл 𝚛𝚎𝚚𝚞𝚒𝚛𝚎𝚖𝚎𝚗𝚝𝚜.𝚝𝚡𝚝, содержащий зависимости вашего проекта.
Наконец, любой может установить точно такие же зависимости, выполнив эту команду:
→ 𝚙𝚒𝚙 𝚒𝚗𝚜𝚝𝚊𝚕𝚕 -𝚛 𝚛𝚎𝚚𝚞𝚒𝚛𝚎𝚖𝚎𝚗𝚝𝚜.𝚝𝚡𝚝
7. Запуск нескольких показателей одновременно
Метрики обучения Scikit
"""
Individual imports
"""
from sklearn.metrics import precision_score, recall_score, f1_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
print("Precision: ", precision_score(y_true, y_pred, average='macro'))
print("Recall: ", recall_score(y_true, y_pred, average='macro'))
print("F1 Score: ", f1_score(y_true, y_pred, average='macro'))
"""
Single Line import
"""
from sklearn.metrics import precision_recall_fscore_support
precision, recall, f1_score, _ = precision_recall_fscore_support(y_true,
y_pred,
average='macro')
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1_score}")8. Объединение нескольких списков в единую последовательность
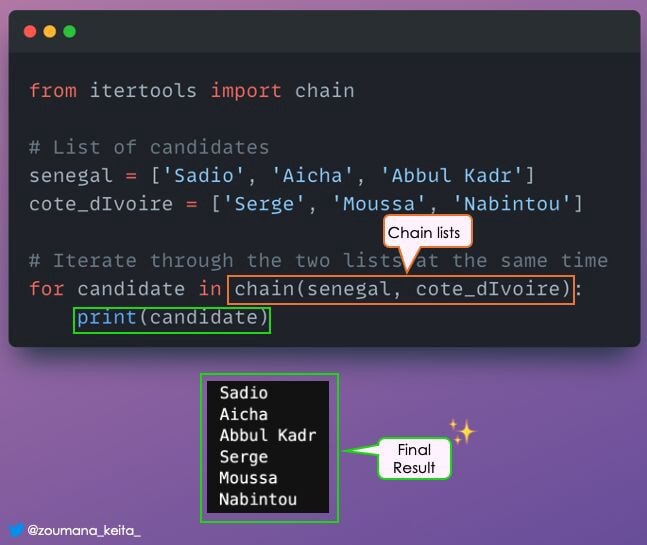
Вы можете использовать один цикл for для перебора нескольких списков в виде одной последовательности.
Этого можно добиться с помощью функции 𝚌𝚑𝚊𝚒𝚗() из модуля Python 𝗶𝘁𝗲𝗿𝘁𝗼𝗼𝗹𝘀.
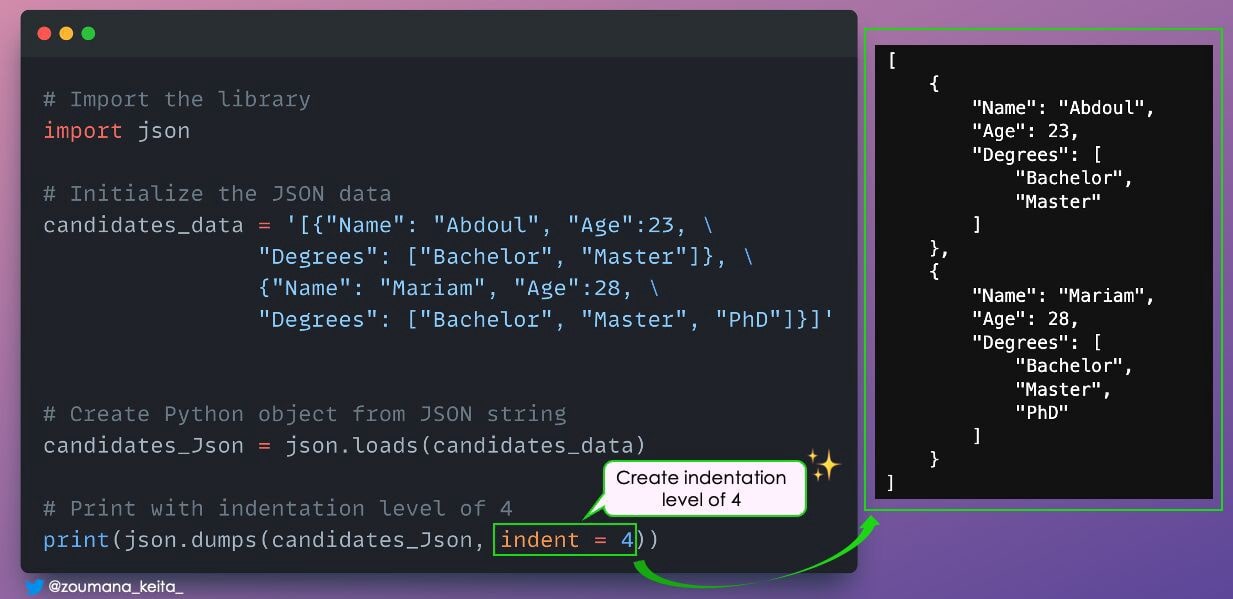
9. Красивая печать данных JSON
Вы когда-нибудь хотели распечатать данные JSON в правильном формате с отступом для лучшей визуализации?
Параметр отступа метода dumps() можно использовать для указания уровня отступа вывода отформатированной строки.
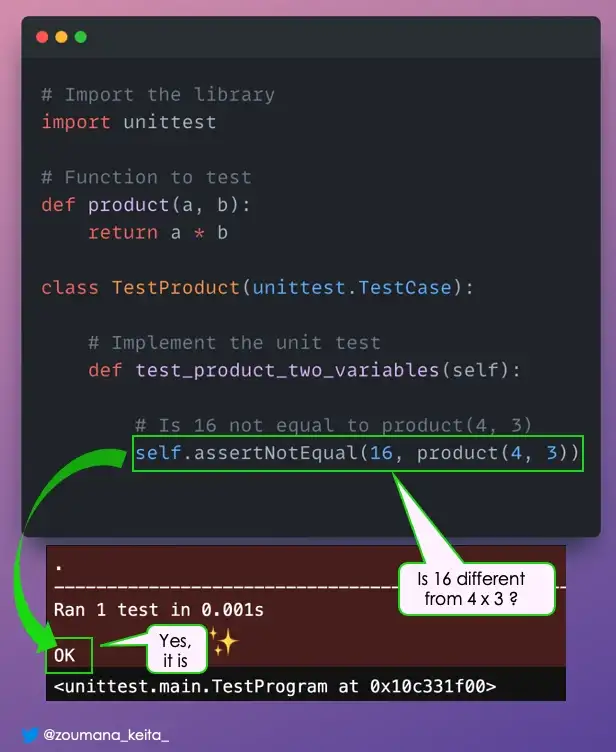
10. Модульное тестирование
Выполняете ли вы модульное тестирование своего кода?
Независимо от того, являетесь ли вы специалистом по данным или разработчиком программного обеспечения, модульное тестирование является важным шагом, позволяющим убедиться, что реализуемые функции соответствуют ожидаемому поведению.
Это, несомненно, полезно на многих уровнях:
- Более качественный код
- Позволяет использовать более простой и гибкий код при добавлении новых функций.
- Снижает затраты за счет экономии времени разработки и предотвращения более поздних этапов обнаружения ошибок.
С 𝘂𝗻𝗶𝘁𝘁𝗲𝘀𝘁 вы можете выполнять модульное тестирование как профессионал.
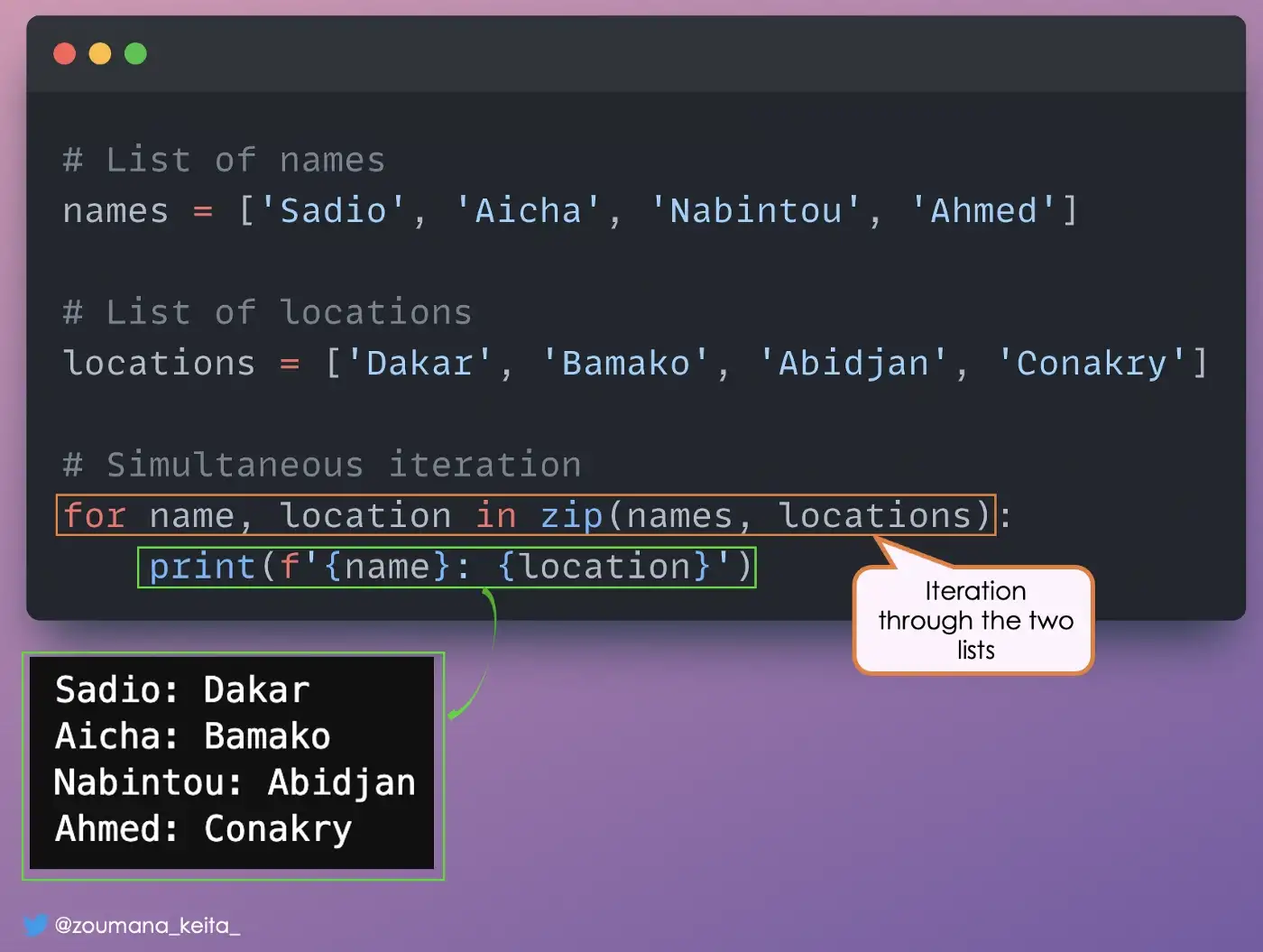
11. Итерация по нескольким спискам
Одновременное перебор нескольких списков может быть полезным при попытке отобразить информацию из этих списков.
Подход — это функция Python 𝘇𝗶𝗽.
Мы надеемся, что этот список приемов Python и Pandas был вам полезен.