Программирование, ориентированное на данные, в Python

Резюме по программированию, ориентированному на данные, написанное Йехонатаном Шарвитом, но проиллюстрированное примерами Python (вместо JavaScript и Java)
«Data-Oriented Programming» Йехонатана Шарвита — отличная книга, в которой дается краткое введение в концепцию Data-Oriented Programming (DOP) как альтернативу старому доброму объектно-ориентированному программированию (OOP). Sharvit разбирает элементы сложности, которые иногда кажутся неизбежными в ООП, и резюмирует основные принципы DOP, которые помогают нам сделать систему более управляемой.
Как следует из названия, DOP ставит данные на первое место. Этого можно достичь, придерживаясь четырех основных принципов. Эти принципы не зависят от языка. Они могут быть представлены на языках ООП (Java, C++ и т.д.), языках функционального программирования (FP) (Clojure и т.д.) или языках общего назначения (Python, JavaScript). В то время как автор иллюстрирует свои примеры с использованием JavaScript и Java, в этой статье предпринята попытка продемонстрировать идеи на Python.
Следуя по тексту статьи, вы найдете простые фрагменты кода на Python, которые иллюстрируют, как можно придерживаться каждого принципа или нарушать его. Шарвит также разъясняет, каковы преимущества и издержки каждого принципа — многие из них актуальны в Python, в то время как некоторые - нет.
Пожалуйста, обратите внимание, что все упомянутые принципы, соответствующие преимущества и недостатки принадлежат Йехонатану Шарвиту, в то время как точки зрения на применимость этих утверждений к Python в сочетании с иллюстрациями кода Python принадлежат мне.
Принцип #1: Отделяйте код от данных
“Отделите код от данных таким образом, чтобы код находился в функциях, поведение которых не зависит от данных, инкапсулированных в контекст функции”. — Йехонатан Шарвит
Естественный способ придерживаться этого принципа в Python — использовать функции верхнего уровня (для кода) и классы данных, которые имеют только поля (для данных). В то время как Шарвит иллюстрирует в своей книге, как следовать этому принципу в ООП и ФП (функциональном программировании) по отдельности, мой пример на Python представляет собой гибрид ООП и ФП.
Обратитесь к приведенному ниже фрагменту кода в качестве примера, где код (поведение) отделен от данных (фактов/информации).
from dataclasses import dataclass
@dataclass
class AuthorData:
"""Class for keeping track of an author in the system"""
first_name: str
last_name: str
n_books: int
def calculate_name(first_name: str, last_name: str):
return f"{first_name} {last_name}"
def is_prolific(n_books: int):
return n_books > 100
author_data = AuthorData("Isaac", "Asimov", 500)
calculate_name(author_data.first_name, author_data.last_name)
# 'Isaac Asimov'Преимущество #1: «Код можно повторно использовать в разных контекстах» — Йехонатан Шарвит
Как видно из приведенного выше примера, calculate_name() может использоваться не только для авторов, но и для пользователей, библиотекарей или любого другого лица, у которого есть поля имени и фамилии. Код, который занимается вычислением полного имени, отделен от кода, который занимается созданием данных об авторе.
@dataclass
class UserData:
"""Class for keeping track of a user in the system"""
first_name: str
last_name: str
email: str
user_data = UserData("John", "Doe", "john.doe@gmail.com")
calculate_name(user_data.first_name, user_data.last_name)
# 'John Doe'Преимущество #2: «Код можно тестировать изолированно» — Йехонатан Шарвит
Ниже приведен пример, который не соответствует Принципу #1.
class Address:
def __init__(self, street_num: int, street_name: str,
city: str, state: str, zip_code: int):
self.street_num = street_num
self.street_name = street_name
self.city = city
self.state = state
self.zip_code = zip_code
class Author:
def __init__(self, first_name: str, last_name: str, n_books: int,
address: Address):
self.first_name = first_name
self.last_name = last_name
self.n_books = n_books
self.address = address
@property
def full_name(self):
return f"{self.first_name} {self.last_name}"
@property
def is_prolific(self):
return self.n_books > 100
address = Address(651, "Essex Street", "Brooklyn", "NY", 11208)
author = Author("Issac", "Asimov", 500, address)
assert author.full_name == "Issac Asimov"Чтобы протестировать свойство full_name(), которое находится внутри класса Author, нам нужно создать экземпляр объекта Author, который требует, чтобы у нас были значения для всех атрибутов, включая те, которые не связаны с тестируемым поведением (например, n_books и пользовательский класс address). Это излишне сложная и утомительная настройка только для проверки одного метода.
С другой стороны, в версии DOP для тестирования кода calculate_name() мы можем создавать данные для передачи в функцию изолированно.
assert calculate_name("Issac", "Asimov") == "Issac Asimov"Стоимость #1: «Нет контроля над тем, какой код может получить доступ к каким данным» — Йехонатан Шарвит
«…в ООП данные инкапсулируются в объект, что гарантирует, что данные доступны только для методов объекта. В DOP, поскольку данные существуют сами по себе, к ним может получить доступ любой фрагмент кода… что по своей сути небезопасно». — Йонатан Шарвит
Это утверждение неприменимо в Python.
В Python к данным, хранящимся в классе, все еще можно получить доступ с помощью любого фрагмента кода, который имеет ссылку на объект. Например:
class Author:
def __init__(self, first_name: str, last_name: str, n_books: int):
self.first_name = first_name
self.last_name = last_name
self.n_books = n_books
@property
def full_name(self):
return f"{self.first_name} {self.last_name}"
@property
def is_prolific(self):
return self.n_books > 100
author = Author("Issac", "Asimov", 500, address)
author.full_name
# 'Issac Asimov'Кроме того, если мы не храним данные в глобальной переменной, мы все равно можем использовать области видимости (функции, циклы и т.д.) Для управления тем, кто может получать доступ к данным/изменять их в Python.
Стоимость #2: «Упаковки нет» — Йехонатан Шарвит
“В DOP код, который манипулирует данными, может находиться где угодно. Это может затруднить разработчикам обнаружение того, что [a specific function] доступна, что может привести к потере времени и дублированию кода”. — Джонатан Шарвит
Это верно для нашего примера Python выше. Например, наш класс данных AuthorData может находиться в одном файле, а функция calculate_name() — в другом.
Принцип #2: Представляйте данные с помощью общих структур данных
“В DOP данные представлены с помощью общих структур данных, таких как карты (или словари) и массивы (или списки)”. — Йехонатан Шарвит
В Python нашими встроенными параметрами для универсальных структур данных являются dict, list и tuple.
В этой статье я использую dataclass Python, который можно рассматривать как “изменяемый именованный кортеж со значениями по умолчанию”. Обратите внимание, что это было не то, что Шарвит подразумевал под “общей структурой данных”. dataclass Python - это гибрид, который ближе к ООП, чем к DOP. Однако, по сравнению со словарями и кортежами, эта альтернатива менее подвержена опечаткам, более описательна с помощью подсказок типа, помогает представить вложенную сложную структуру более четким и сжатым способом и многое другое. Кроме того, его можно легко превратить в словарь или кортеж, если мы захотим.
from dataclasses import dataclass, asdict
@dataclass
class AuthorData:
"""Class for keeping track of an author in the system"""
first_name: str
last_name: str
n_books: int
author_data = AuthorData("Isaac", "Asimov", 500)
asdict(author_data)
# {'first_name': 'Isaac', 'last_name': 'Asimov', 'n_books': 500}Преимущество #1: «Возможность использовать универсальные функции, которые не ограничиваются нашим конкретным вариантом использования» — Йехонатан Шарвит
Учитывая общие структуры, мы можем манипулировать данными, используя богатый набор встроенных функций Python, доступных для dict, list, tuple и т. д.
Ниже приведены несколько примеров универсальных функций, которые можно использовать для управления данными, хранящимися в dict.
author = {"first_name": "Issac", "last_name": "Asimov", "n_books": 500}
# Access dict values
author.get("first_name")
# Add new field to dict
author["alive"] = False
# Update existing field
author["n_books"] = 703Это означает, что нам не нужно изучать и запоминать пользовательские методы всех классов. Кроме того, универсальные функции не могут сломаться, если мы изменим некоторые версии библиотеки. Они ломаются только в том случае, если язык Python изменяет их (чего почти никогда не происходит).
Преимущество #2: «Гибкая модель данных» — Йехонатан Шарвит
“При использовании универсальных структур данных данные могут быть созданы без предопределенной формы, и их форма может быть изменена по желанию”. — Йехонатан Шарвит
В приведенном ниже примере не все словари в списке имеют одинаковые ключи. Дополнительные ключи могут существовать во втором словаре до тех пор, пока присутствуют обязательные поля.
names = []
names.append({"first_name": "Isaac", "last_name": "Asimov"})
names.append({"first_name": "Jane", "last_name": "Doe",
"suffix": "III", "age": 70})
Стоимость #1: «Хит производительности» — Йехонатан Шарвит.
Это не полностью переводится на Python.
В Python нет большой разницы в производительности между получением значения члена класса и получением значения, связанного с ключом в словаре. В отличие от Java, в Python нет этапа компиляции, что означает отсутствие оптимизации компилятора при доступе к члену класса.
Однако не все общие структуры данных одинаковы. Время поиска для set и dict более эффективно, чем для list и tuple, учитывая, что множества и словари используют хэш-функцию для определения любого конкретного фрагмента данных сразу, без поиска.
Стоимость #2: «Нет схемы данных» — Йехонатан Шарвит
“Когда данные создаются из класса, информация о форме данных содержится в определении класса. Наличие схемы данных на уровне класса позволяет легко определить ожидаемую форму данных. Когда данные представлены с помощью общих структур данных, схема данных не является частью представления данных”. — Йехонатан Шарвит
Например, мы можем легко определить форму данных FullName, которая создается как объект класса ниже.
class FullName:
def __init__(self, first_name, last_name, suffix):
self.first_name = first_name
self.last_name = last_name
self.suffix = suffixСтоимость #3: «Нет проверки правильности данных во время компиляции» — Йехонатан Шарвит
Это не полностью переводится на Python
Опять же, в Python нет этапа компиляции, как в Java. Единственной проверкой во время компиляции для Python будет запуск такого инструмента, как mypy.
Тем не менее, пример Шарвита о том, как ошибки формы данных могут проскользнуть через трещину с помощью общих структур данных, все же можно продемонстрировать на Python, как показано ниже.
Когда в класс FullName передаются данные, не соответствующие ожидаемой форме, во время выполнения возникает ошибка. Например, если мы опечатаемся в поле, в котором хранится имя (fist_name вместо first_name), мы получим TypeError: __init__() got an unexpected keyword argument 'fist_name'.
class FullName:
def __init__(self, first_name, last_name, suffix):
self.first_name = first_name
self.last_name = last_name
self.suffix = suffix
FullName(fist_name="Jane", last_name="Doe", suffix="II")Однако при использовании универсальных структур данных неправильный ввод поля может не привести к ошибке или исключению. Скорее всего, имя таинственным образом опущено в результате.
names = []
names.append({"first_name": "Jane", "last_name": "Doe", "suffix": "III"})
names.append({"first_name": "Isaac", "last_name": "Asimov"})
names.append({"fist_name": "John", "last_name": "Smith"})
print(f"{names[2].get('first_name')} {names[2].get('last_name')}")
# None SmithСтоимость #4: “Необходимость явного приведения типов” — Джонатан Шарвит
Это не переводится на Python
Python — это язык с динамической типизацией. Он не требует явного приведения типов.
Принцип #3: Данные неизменны
“Согласно DOP, данные никогда не должны меняться! Вместо изменения данных создается их новая версия”. — Джонатан Шарвит
Чтобы придерживаться этого принципа, мы делаем наш dataclass замороженным (то есть неизменяемым).
@dataclass(frozen=True)
class AuthorData:
"""Class for keeping track of an author in the system"""
first_name: str
last_name: str
n_books: intНеизменяемыми типами данных во встроенном Python являются int, float, decimal, bool, string, tuple и range. Обратите внимание, что dict, list и set являются изменяемыми.
Преимущество #1: «Уверенный доступ к данным для всех» — Йехонатан Шарвит
“Когда данные изменчивы, мы должны быть осторожны при передаче данных в качестве аргумента функции, поскольку они могут быть изменены или клонированы”. — Джонатан Шарвит
В приведенном ниже примере мы изначально передаем функции пустой список в качестве аргумента по умолчанию. Поскольку list является изменяемым объектом, каждый раз, когда мы вызываем функцию, список видоизменяется и при последующем вызове используется другое значение по умолчанию.
def append_to_list(el, ls=[]):
ls.append(el)
return ls
append_to_list(1)
# [1]
append_to_list(2)
# [1, 2]
append_to_list(3)
# [1, 2, 3]Чтобы исправить приведенный выше вариант использования, мы можем сделать:
def append_to_list(el, ls=None):
if ls is None:
ls = []
ls.append(el)
return ls
append_to_list(1)
# [1]
append_to_list(2)
# [2]Этот код работает так, как ожидалось, потому что None является неизменяемым.
«Когда данные неизменяемы, их можно с уверенностью передать любой функции, потому что данные никогда не меняются». — Йонатан Шарвит
Преимущество #2: “Предсказуемое поведение кода” — Джонатан Шарвит
Вот пример непредсказуемого фрагмента кода:
from datetime import date
dummy = {"age": 30}
if date.today().day % 2 == 0:
dummy["age"] = 40Значение age в dummy словаре непредсказуемо. Это зависит от того, запускаете ли вы код в четный или нечетный день.
Однако при использовании неизменяемых данных гарантируется, что данные никогда не изменятся.
author_data = AuthorData("Issac", "Asimov", 500)
if date.today().day % 2 == 0:
author_data.n_books = 100
# dataclasses.FrozenInstanceError: cannot assign to field "n_books"Приведенный выше фрагмент кода выдаст ошибку, говоря dataclasses.FrozenInstanceError: cannot assign to field "n_books". С замороженным классом данных, независимо от того, четный это день или нечетный, author_data.n_books всегда равно 500.
Преимущество #3: “Быстрая проверка на равенство” — Джонатан Шарвит
В Python есть два похожих оператора для проверки равенства двух объектов: is и ==. is проверяет идентичность (объектов) путем сравнения целочисленного равенства адреса памяти.== проверяет равенство (значений) путем изучения фактического сохраненного содержимого.
# String is immutable
x = "abc"
# Note that the identity of `x` and `abc` is the same
print(id(x))
# 140676188882480
print(id("abc"))
# 140676188882480
print(x == "abc")
# True
print(x is "abc")
# True
# List is mutable
y = [1, 2, 3]
# Note that the identity of `y` and `[1, 2, 3]` is different
print(id(y))
# 140676283875904
print(id([1, 2, 3])
# 140676283875584
print(y == [1, 2, 3])
# True
print(y is [1, 2, 3])
# FasleКак видно выше, is и == ведут себя одинаково для x, который является строкой (т.е. неизменяемым типом данных), но ведет себя по-другому для y, который является списком (т.е. изменяемым типом данных). С неизменяемыми объектами данных is ведет себя более предсказуемо. Кроме того, is обычно быстрее, чем ==, потому что сравнение адресов объектов происходит быстрее, чем сравнение всех полей. Таким образом, неизменяемые данные позволяют быстро проверять равенство путем сравнения данных по ссылке.
Преимущество #4: «Бесплатная безопасность параллелизма» — Йехонатан Шарвит
Когда данные изменчивы в многопоточной среде, может произойти сбой состояния гонки. Например, предположим, что два потока пытаются получить доступ к значению x и изменить его, добавив/вычтя из него 10:
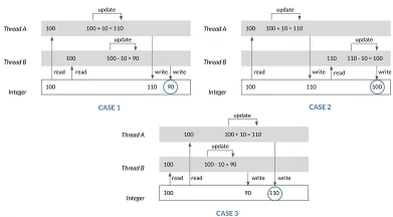
Возможны три ответа: x=90, x=100 и x=110. В зависимости от порядка выполнения поведение программы меняется при каждом запуске, что небезопасно и уязвимо для повреждения. Для обеспечения безопасности параллелизма данные должны быть в неизменном состоянии.
Стоимость #1: «Хит производительности» — Йехонатан Шарвит.
Учитывая, что list является изменяемым, а tuple неизменяемым, по мере расширения обоих объектов идентификатор list остается прежним, тогда как новый tuple создается с другим идентификатором.
list1 = [1, 2, 3]
tuple1 = (1, 2, 3)
print(id(list1))
# 140218642718848
print(id(tuple1))
# 140218642722496
list1 += [4, 5]
tuple1 += (4, 5)
print(id(list1))
# 140218642718848
print(id(tuple1))
# 140218642772352
Необходимость копировать содержимое неизменяемого объекта в новый объект каждый раз, когда мы его модифицируем, требует дополнительной памяти и увеличивает нагрузку на ЦП, особенно для очень больших коллекций.
Стоимость #2: “Необходимая библиотека для неизменяемых структур данных” — Джонатан Шарвит
Это не переводится на Python
Frozenset и tuple — это некоторые базовые встроенные неизменяемые структуры данных в Python. Мы не всегда обязаны включать стороннюю библиотеку, чтобы придерживаться принципа неизменности данных.
Принцип #4: Отделите схему данных от представления данных
«В DOP ожидаемая форма данных представлена в виде (мета) данных, которые хранятся отдельно от основного представления данных». — Йонатан Шарвит
Ниже приведена базовая схема JSON (по сути, словарь), которая описывает формат данных, которые также представлены в виде словаря. Схема определяет, какие поля являются обязательными, и типы данных полей, тогда как данные представлены общей структурой данных в соответствии с принципом #3.
schema = {
"required": ["first_name", "last_name"],
"properties": {
"first_name": {"type": str},
"last_name": {"type": str},
"books": {"type": int},
}
}
data = {
"valid": {
"first_name": "Isaac",
"last_name": "Asimov",
"books": 500
},
"invalid1": {
"fist_name": "Isaac",
"last_name": "Asimov",
},
"invalid2": {
"first_name": "Isaac",
"last_name": "Asimov",
"books": "five hundred"
}
}Функции проверки данных (или библиотеки) можно использовать для проверки того, соответствует ли часть данных схеме данных.
def validate(data):
assert set(schema["required"]).issubset(set(data.keys())), \
f"Data must have following fields: {schema['required']}"
for k in data:
if k in schema["properties"].keys():
assert type(data[k]) == schema["properties"][k]["type"], \
f"Field {k} must be of type {str(schema['properties'][k]['type'])}"Функция validate проходит, когда данные верны, или возвращает ошибки с подробностями в удобочитаемом формате, когда данные недействительны.
validate(data["valid"]))
# No error
validate(data["invalid1"])
# AssertionError: Data must have following fields: ['first_name', 'last_name']
validate(data["invalid2"])
# AssertionError: Field books must be of type <class 'int'>Преимущество #1: «Необязательные поля» — Йехонатан Шарвит
«В ООП сделать член класса необязательным непросто. В DOP естественно объявить поле на карте необязательным». — Йехонатан Шарвит
Это не переводится на Python
В Python, даже с ООП, сделать член класса необязательным несложно. Таким образом, это преимущество не является сильным в контексте Python. Например, ниже мы можем установить для аргумента n_books по умолчанию значение None, чтобы указать, что поле является необязательным.
class Author:
def __init__(self, first_name: str, last_name: str, n_books: int = None):
self.first_name = first_name
self.last_name = last_name
self.n_books = n_books
@property
def fullname(self):
return f"{self.first_name} {self.last_name}"
@property
def is_prolific(self):
if self.n_books:
return self.n_books > 100
author = Author("Issac", "Asimov")Преимущество #2: «Расширенные условия проверки данных» — Йехонатан Шарвит
“В DOP проверка данных происходит во время выполнения. Это позволяет определять условия проверки данных, которые выходят за рамки типа поля”. — Йехонатан Шарвит
По сравнению с минимальной схемой, определенной выше, следующая схема может быть расширена, чтобы включить больше свойств для каждого поля.
schema = {
"required": ["first_name", "last_name"],
"properties": {
"first_name": {
"type": str,
"max_length": 100,
},
"last_name": {
"type": str,
"max_length": 100
},
"books": {
"type": int,
"min": 0,
"max": 10000,
},
}
}
Хотя не все преимущества и недостатки принципов DOP, упомянутые Шарвитом, напрямую применимы к Python, основные принципы остаются надежными. Этот подход продвигает код, который легче анализировать, тестировать и поддерживать. Используя принципы и методы DOP, программисты Python могут создавать более удобный и масштабируемый код и раскрывать весь потенциал своих данных.