Сетевые программы на Python - но с программой для преобразования веб-страниц в markdown

Протокол, обеспечивающий работу Интернета, известен как HTTP (протокол передачи гипертекста). Между двумя программами может существовать соединение для отправки и получения данных.
Протокол - это набор правил и рекомендаций для передачи данных. Правила определяются для каждого шага и процесса во время связи между двумя и более компьютерами. Сети должны следовать этим правилам для успешной передачи данных.
Python предоставляет библиотеку, называемую сокетами, для установления соединений и передачи данных между соединениями.
import socket
mysock = sockek.socket(socket.AF_INET, sock.SOCK_STREAM)
cmd = "GET http://data.pr4e.org /HTTP1.0\r\n\r\n"
mysock.connect(("data.pr4e.org", 80))
mysock.sendall(cmd)
# цикл получения данных до тех пор, пока он не вернет 0
# которые указывают, что данные больше не отправляются
while True:
data = mysock(512)
if data < 1:
break
print(data.decode(), end='')
mysock.close()
Python предоставляет библиотеку urllib для управления сетями HTTP, абстрагируя всю часть заголовка HTTP.
Скачивание файла с веб-сервера
import urllib.request, urllib.parse, urllib.error
data = urllib.request("http://data.pr4e.org/cover3.jpg").read()
fhand = open("image.jpg", "wb")
fhand.write(data)
fhand.close()
Urllib особенно полезен, когда вы хотите отказаться от веб-сайта и использовать информацию.
Итак, давайте напишем программу для преобразования веб-страниц в Markdown.
- Установите markdownify, который будет использоваться для преобразования HTML в Markdown
- Установите BeautifulSoup, чтобы использовать синтаксический анализ HTML
- Приведенный ниже код выполняет запрос к URL-адресу, указанному ниже, анализирует HTML, конвертирует HTML в markdown и сохраняет markdown в файле, указанном в качестве имени заголовка документа.
from markdownify import markdownify as md
import urllib.request, urllib.parse, urllib.error
import ssl
from bs4 import BeautifulSoup
url = input("Enter URL: ")
# игнорировать ошибки SSL-сертификата
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
try:
html = urllib.request.urlopen(url).read()
except:
print("Error opening URL")
exit()
soup = BeautifulSoup(html, "html.parser")
# удалите все эти длинные классы, идентификаторы, имена и встроенные стили
for tag in soup():
for attribute in ["class", "id", "name", "style"]:
del tag[attribute]
# удалите теги из списка ниже
for tag in soup(["style", "script", "sidebar", "aside"]):
tag.decompose()
print(soup.prettify())
prettiified_html = soup.prettify()
markdownified_html = md(prettiified_html)
fhand = open("{}.md".format(soup.title.string), "w")
fhand.write(markdownified_html)
fhand.close()
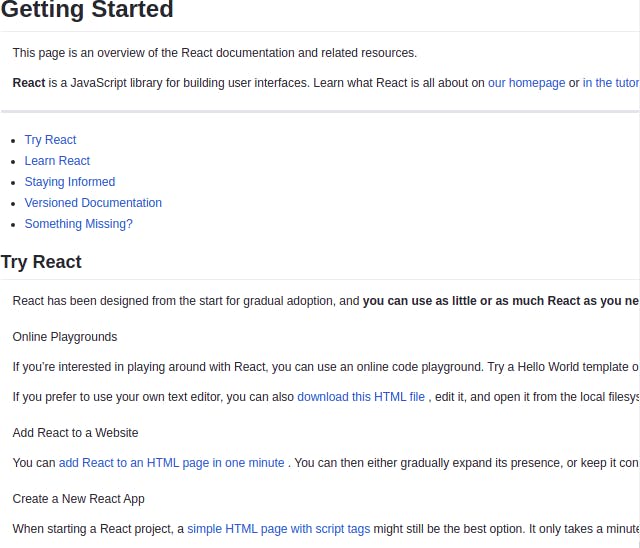
Предварительный просмотр Markdown на URL-адресе фреймворка React.
Вывод
Код, который мы написали, отнюдь не идеален. Это просто для того, чтобы показать краткий пример того, что вы можете делать с HTTP-соединениями в python. Мы можем решить продолжить работу над функциями, добавив дополнительные функции и интеграции.