Системы машинного обучения и рекомендаций с использованием ваших собственных данных Spotify

Как человек, который ежедневно использует Spotify, мне было интересно, какой анализ я могу сделать с моими собственными музыкальными данными. Spotify отлично справляется с рекомендациями треков как через ежедневные миксы, так и через радиостанции, но как мы сами создадим что-то подобное? Целью здесь было использовать машинное обучение и методы системы рекомендаций, чтобы рекомендовать новые треки на основе треков из моих любимых плейлистов.
В этой статье дается более подробный обзор этого проекта. Код и результаты можно найти на GitHub:
Exploration implementing recommender systems using Spotify data. - anthonyli358/spotify-recommender-systems
Данные Spotify
Любому хорошему проекту в области науки о данных сначала нужны данные, и много.
Доступ к Spotify API

Чтобы начать работу с нашими музыкальными данными, нам сначала нужно получить доступ к Spotify API:
- Создайте учетную запись Spotify для разработчиков
- Из панели управления настройте проект (необходим для доступа к API)
- Получите идентификатор клиента, секрет клиента и настройте URI перенаправления (в локальных проектах я установил для него
http://localhost:9001/callback) - Изучите документацию по API.
Музыкальные данные
После настройки учетной записи разработчика мы можем получить доступ к API для извлечения музыкальных данных. Для этого мы можем использовать Python пакет spotipy, которому нужны данные разработчика, которые мы настроили ранее, чтобы предоставлять разрешения через OAuth.
with open("spotify/spotify_details.yml", 'r') as stream:
spotify_details = yaml.safe_load(stream)
# https://developer.spotify.com/web-api/using-scopes/
scope = "user-library-read user-follow-read user-top-read playlist-read-private"
sp = spotipy.Spotify(auth_manager=SpotifyOAuth(
client_id=spotify_details['client_id'],
client_secret=spotify_details['client_secret'],
redirect_uri=spotify_details['redirect_uri'],
scope=scope,)
)
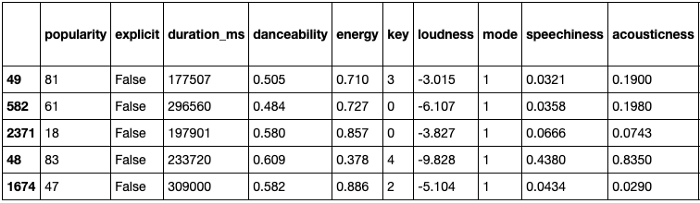
Теперь мы можем извлекать данные из различных источников в нашей библиотеке Spotify. У класса sp есть функции для этого, такие как sp.current_user_playlists() и sp.current_user_top_tracks(). Из этих вызовов API нам нужно извлечь детали трека, такие как уникальный идентификатор, имя, продолжительность и жанры, а также связанные свойства исполнителя, альбома и списка воспроизведения. Я сохранил их как фреймы данных pandas для простоты анализа.
Spotify также может предоставлять звуковые функции для трека. Это числовые значения (в основном нормализованные между 0 и 1), которые полезны для анализа, но особенно в качестве функций для традиционных методов машинного обучения.
Рекомендательные системы
Машинное обучение
С указанным выше набором табличных данных довольно просто сформулировать это как классическую проблему регрессии, оценивая песни в обучающем наборе от 1 до 10, или как задачу классификации, пытаясь рекомендовать треки, похожие на наши любимые песни (довольно простой подход, если у вас есть плейлист любимых песен). Не забудьте удалить повторяющиеся идентификаторы треков из тестовых наборов данных, чтобы избежать утечки данных!
Однако вышеупомянутый подход в значительной степени зависит как от разработки функций, так и от пользователей, обеспечивающих маркировку. Он страдает как от неправильной маркировки, так и от проблемы с холодным запуском, когда пользователь имеет новую учетную запись или не предоставляет никаких оценок, поэтому вместо этого часто используются рекомендательные системные подходы.
Рекомендация по популярности
Рекомендатель популярности рекомендует песни, ранжированные по их популярности, независимо от предпочтений пользователя. Это, конечно, зависит от методологии, используемой для определения показателя популярности (обычно это некоторая функция времени, взаимодействия с пользователем и оценок пользователей).

Поскольку при этом не учитывается активность пользователей, рекомендовать треки исключительно по популярности - плохой способ рекомендовать треки. Однако, как мы увидим позже, это хороший способ добавить разнообразия и избежать проблем с холодным запуском.
Контент-рекомендатель
Рекомендатель на основе содержимого использует атрибуты элементов, с которыми взаимодействовал пользователь, чтобы рекомендовать аналогичные элементы. Здесь используется популярный метод TF-IDF для преобразования неструктурированного текста (униграммы и биграммы жанров и названия песни / исполнителя / альбома / плейлиста) в разреженную матрицу. Косинусное сходство между пользовательским вектором и исходной матрицей (все пользователи) затем дает метрику для рекомендации новых треков.
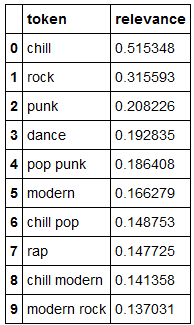
Похоже, жанр - самая сильная форма контента, на котором основываются рекомендации по трекам.
Совместная рекомендация
Рекомендации для совместной работы могут быть основаны либо на памяти (на основе прошлых взаимодействий с пользователем), либо на модели (например, кластеризации). Здесь матрица элементов × пользователи затем используется для рекомендации элементов пользователям на основе взаимодействий схожих пользователей.

Коллаборативный подход может страдать от проблемы разреженности, если набор пользователей слишком мал или количество взаимодействий слишком мало.
Гибридный рекомендатель
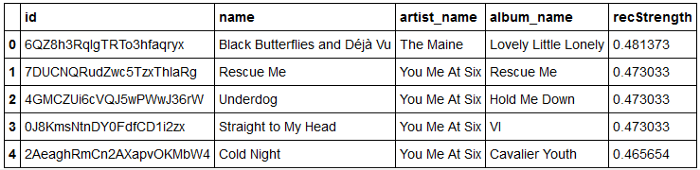
Гибридный рекомендатель сочетает в себе подходы, основанные на содержании, и подходы сотрудничества, и во многих исследованиях было показано, что он работает лучше. Это позволяет избежать большого разброса и обеспечивает разнообразие и взвешивание (например, жанровое взвешивание). Мы также можем включить подход популярности, чтобы дать рекомендацию гибрид + популярность.

Субъективно этот советник дает лучшие практические рекомендации!
Финальный плейлист и мысли
Теперь мы можем добавлять наши треки в плейлист Spotify и слушать их! Создайте массив tracks_to_add идентификаторов треков, где сила рекомендации превышает определенное значение.
# Create a new playlist for tracks to add
new_playlist = sp.user_playlist_create(
user=spotify_details['user'],
name="spotify-recommender-playlists",
public=False,
collaborative=False,
description="Created by https://github.com/anthonyli358/spotify- recommender-systems",
)
# Add tracks to the new playlist
for id in tracks_to_add:
sp.user_playlist_add_tracks(user=spotify_details['user'],
playlist_id=new_playlist['id'],
tracks=[id],
)
Надеюсь, список воспроизведения 🔥 . Чтобы еще больше улучшить рекомендации, мы могли бы:
- Развернуть набор данных, чтобы включить других пользователей
- Разработать другие оценочных метрик (здесь использовалась метрика точности Top-N)