Создаем Python Bot, который может найти вопрос с множественным выбором из любого заданного изображения

В этом посте я собираюсь показать вам, как создать собственную систему поиска ответов с помощью Python. В основном, эта автоматизация может найти ответ на вопрос с множественным выбором из рисунка.
Ясно одно: во время экзамена невозможно искать вопросы в Интернете, но я могу быстро сделать снимок, когда экзаменатор отвернулся. Это первая часть алгоритма. Как-то мне нужно извлечь вопрос из картинки.
Кажется, есть много сервисов, которые могут предоставить инструменты для извлечения текста, но мне нужен какой-то API для решения этой проблемы. Наконец, Google Vision API был именно тем инструментом, который я ищу. Самое замечательное то, что первые 1000 вызовов API бесплатны раз в месяц, чего вполне достаточно для тестирования и использования API.
Vision AI
Сначала зайдите и создайте учетную запись Google Cloud, затем выполните поиск Vision AI в сервисах. Используя Vision AI, вы можете выполнять такие действия, как назначение меток для изображения, чтобы упорядочить ваши изображения, обнаружить известные пейзажи или места, извлечь тексты и кое-что еще.
Проверьте документацию, чтобы включить и настроить API. После настройки вам необходимо создать файл JSON, содержащий ваши ключи для загрузки на ваш компьютер.
Выполните следующую команду для установки клиентской библиотеки:
pip install google-cloud-vision
Затем предоставьте учетные данные для аутентификации для своего кода приложения, установив переменную среды GOOGLE_APPLICATION_CREDENTIALS.
import os, io
from google.cloud import vision
from google.cloud.vision import types
# JSON file that contains your key
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'
# Instantiates a client
client = vision.ImageAnnotatorClient()
FILE_NAME = 'your_image_file.jpg'
# Loads the image into memory
with io.open(os.path.join(FILE_NAME), 'rb') as image_file:
content = image_file.read()
image = vision.types.Image(content=content)
# Performs text detection on the image file
response = client.text_detection(image=image)
print(response)
# Extract description
texts = response.text_annotations[0]
print(texts.description)
Когда вы запустите код, вы увидите ответ в формате JSON, который включает в себя спецификации обнаруженных текстов. Но нам нужно только чистое описание, поэтому я извлек эту часть из ответа.
Поиск вопроса в Google
Следующим шагом является поиск в разделе вопросов в Google, чтобы получить некоторую информацию. Я использовал библиотеку регулярных выражений для извлечения части вопроса из описания (ответа). Затем мы должны пройтись по извлеченной части вопроса, чтобы иметь возможность искать ее.
import re
import urllib
# If ending with question mark
if '?' in texts.description:
question = re.search('([^?]+)', texts.description).group(1)
# If ending with colon
elif ':' in texts.description:
question = re.search('([^:]+)', texts.description).group(1)
# If ending with newline
elif '\n' in texts.description:
question = re.search('([^\n]+)', texts.description).group(1)
# Slugify the match
slugify_keyword = urllib.parse.quote_plus(question)
print(slugify_keyword)
Сканирование информации
Мы будем использовать BeautifulSoup для сканирования первых 3 результатов, чтобы получить некоторую информацию по этому вопросу, потому что ответ, вероятно, находится в одном из них.
Кроме того, если вы хотите сканировать определенные данные из списка поиска Google, не используйте элемент inspect для поиска атрибутов элементов, вместо этого напечатайте всю страницу, чтобы увидеть атрибуты, потому что она отличается от фактической.
Нам нужно сканировать первые 3 ссылки в результатах поиска, но эти ссылки действительно перепутаны, поэтому важно получить чистые ссылки для сканирования.
/url?q=https://en.wikipedia.org/wiki/IAU_definition_of_planet&sa=U&ved=2ahUKEwiSmtrEsaTnAhXtwsQBHduCCO4QFjAAegQIBBAB&usg=AOvVaw0HzMKrBxdHZj5u1Yq1t0en
Как видите, фактическая ссылка находится между q= и &. Используя Regex, мы можем получить это конкретное поле или действительный URL.
result_urls = []
def crawl_result_urls():
req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'})
html = urlopen(req).read()
bs = BeautifulSoup(html, 'html.parser')
results = bs.find_all('div', class_='ZINbbc')
try:
for result in results:
link = result.find('a')['href']
# Checking if it is url (in case)
if 'url' in link:
result_urls.append(re.search('q=(.*)&sa', link).group(1))
except (AttributeError, IndexError) as e:
pass
Прежде чем мы просканируем содержимое этих URL, позвольте мне показать вам систему ответов на вопросы с Python.
Система ответов на вопросы
Это основная часть алгоритма. После сканирования информации из первых 3 результатов, программа должна определить ответ путем итерации документов. Сначала я подумал, что лучше использовать алгоритм сходства для обнаружения документов, который наиболее похож на вопрос, но я понятия не имел, как его реализовать.
После нескольких часов исследований я нашел статью в Medium, в которой объясняется система ответов на вопросы с Python. Это простой в использовании пакет Python для реализации системы контроля качества на ваших личных данных. Вы можете пойти и проверить подробности здесь
Давайте сначала установим пакет:
pip install cdqa
Я загружаю предварительно обученные модели и данные вручную, используя функции загрузки, которые включены в приведенный ниже пример кода:
import pandas as pd
from ast import literal_eval
from cdqa.utils.filters import filter_paragraphs
from cdqa.utils.download import download_model, download_bnpp_data
from cdqa.pipeline.cdqa_sklearn import QAPipeline
# Download data and models
download_bnpp_data(dir='./data/bnpp_newsroom_v1.1/')
download_model(model='bert-squad_1.1', dir='./models')
# Loading data and filtering / preprocessing the documents
df = pd.read_csv('data/bnpp_newsroom_v1.1/bnpp_newsroom-v1.1.csv', converters={'paragraphs': literal_eval})
df = filter_paragraphs(df)
# Loading QAPipeline with CPU version of BERT Reader pretrained on SQuAD 1.1
cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib')
# Fitting the retriever to the list of documents in the dataframe
cdqa_pipeline.fit_retriever(df)
# Sending a question to the pipeline and getting prediction
query = 'Since when does the Excellence Program of BNP Paribas exist?'
prediction = cdqa_pipeline.predict(query)
print('query: {}\n'.format(query))
print('answer: {}\n'.format(prediction[0]))
print('title: {}\n'.format(prediction[1]))
print('paragraph: {}\n'.format(prediction[2]))
вывод должен выглядеть так:

Он печатает точный ответ и параграф, который включает в себя ответ.
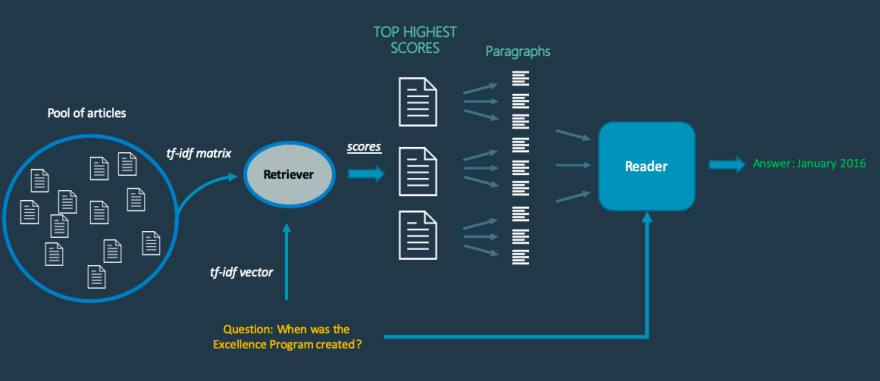
В основном, когда вопрос извлечен из изображения и отправлен в систему, ретривер выберет список документов из просканированных данных, которые с наибольшей вероятностью содержат ответ. Как я уже говорил ранее, он вычисляет косинусное сходство между вопросом и каждым документом в просканированных данных.
После выбора наиболее вероятных документов система делит каждый документ на параграфы и отправляет их с вопросом в Reader, который в основном представляет собой предварительно обученную модель глубокого обучения. Используемая модель была Pytorch-версией хорошо известной NLP модели BERT.
Затем Reader выводит наиболее вероятный ответ, который он может найти в каждом параграфе. После Reader в системе есть последний слой, который сравнивает ответы с использованием внутренней функции оценки и выводит наиболее вероятную в соответствии с оценками, которые будут ответом на наш вопрос.
Вот схема системного механизма.
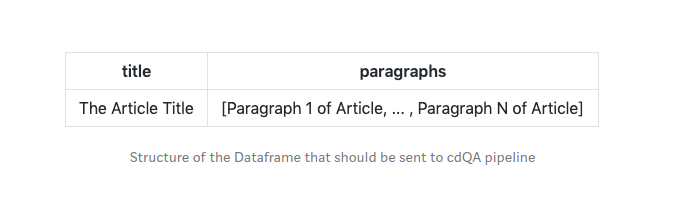
Вы должны установить свой фрейм данных (CSV) в определенной структуре, чтобы он мог быть отправлен в конвейер cdQA.
Но на самом деле я использовал конвертер PDF для создания входного фрейма данных из каталога файлов PDF. Итак, я собираюсь сохранить все просканированные данные в PDF-файл для каждого результата.
Надеемся, что у нас будет всего 3 файла PDF (может быть 1 или 2). Дополнительно, нам нужно назвать эти PDF-файлы, поэтому я просканировал заголовок каждой страницы.
def get_result_details(url):
try:
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
html = urlopen(req).read()
bs = BeautifulSoup(html, 'html.parser')
try:
# Crawl any heading in result to name pdf file
title = bs.find(re.compile('^h[1-6]$')).get_text().strip().replace('?', '').lower()
# Naming the pdf file
filename = "/home/coderasha/autoans/pdfs/" + title + ".pdf"
if not os.path.exists(os.path.dirname(filename)):
try:
os.makedirs(os.path.dirname(filename))
except OSError as exc: # Guard against race condition
if exc.errno != errno.EEXIST:
raise
with open(filename, 'w') as f:
# Crawl first 5 paragraphs
for line in bs.find_all('p')[:5]:
f.write(line.text + '\n')
except AttributeError:
pass
except urllib.error.HTTPError:
pass
def find_answer():
df = pdf_converter(directory_path='/home/coderasha/autoans/pdfs')
cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib')
cdqa_pipeline.fit_retriever(df)
query = question + '?'
prediction = cdqa_pipeline.predict(query)
print('query: {}\n'.format(query))
print('answer: {}\n'.format(prediction[0]))
print('title: {}\n'.format(prediction[1]))
print('paragraph: {}\n'.format(prediction[2]))
return prediction[0]
Что ж, если я обобщу алгоритм, он извлечет вопрос из картинки, выполнит поиск в Google, просканирует первые 3 результата, создаст 3 файла pdf из просканированных данных и, наконец, найдет ответ, используя систему ответов на вопросы.
import os, io
import errno
import urllib
import urllib.request
import hashlib
import re
import requests
from time import sleep
from google.cloud import vision
from google.cloud.vision import types
from urllib.request import urlopen, Request
from bs4 import BeautifulSoup
import pandas as pd
from ast import literal_eval
from cdqa.utils.filters import filter_paragraphs
from cdqa.utils.download import download_model, download_bnpp_data
from cdqa.pipeline.cdqa_sklearn import QAPipeline
from cdqa.utils.converters import pdf_converter
result_urls = []
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'
client = vision.ImageAnnotatorClient()
FILE_NAME = 'your_image_file.jpg'
with io.open(os.path.join(FILE_NAME), 'rb') as image_file:
content = image_file.read()
image = vision.types.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations[0]
# print(texts.description)
if '?' in texts.description:
question = re.search('([^?]+)', texts.description).group(1)
elif ':' in texts.description:
question = re.search('([^:]+)', texts.description).group(1)
elif '\n' in texts.description:
question = re.search('([^\n]+)', texts.description).group(1)
slugify_keyword = urllib.parse.quote_plus(question)
# print(slugify_keyword)
def crawl_result_urls():
req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'})
html = urlopen(req).read()
bs = BeautifulSoup(html, 'html.parser')
results = bs.find_all('div', class_='ZINbbc')
try:
for result in results:
link = result.find('a')['href']
print(link)
if 'url' in link:
result_urls.append(re.search('q=(.*)&sa', link).group(1))
except (AttributeError, IndexError) as e:
pass
def get_result_details(url):
try:
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
html = urlopen(req).read()
bs = BeautifulSoup(html, 'html.parser')
try:
title = bs.find(re.compile('^h[1-6]$')).get_text().strip().replace('?', '').lower()
# Set your path to pdf directory
filename = "/path/to/pdf_folder/" + title + ".pdf"
if not os.path.exists(os.path.dirname(filename)):
try:
os.makedirs(os.path.dirname(filename))
except OSError as exc:
if exc.errno != errno.EEXIST:
raise
with open(filename, 'w') as f:
for line in bs.find_all('p')[:5]:
f.write(line.text + '\n')
except AttributeError:
pass
except urllib.error.HTTPError:
pass
def find_answer():
# Set your path to pdf directory
df = pdf_converter(directory_path='/path/to/pdf_folder/')
cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib')
cdqa_pipeline.fit_retriever(df)
query = question + '?'
prediction = cdqa_pipeline.predict(query)
# print('query: {}\n'.format(query))
# print('answer: {}\n'.format(prediction[0]))
# print('title: {}\n'.format(prediction[1]))
# print('paragraph: {}\n'.format(prediction[2]))
return prediction[0]
crawl_result_urls()
for url in result_urls[:3]:
get_result_details(url)
sleep(5)
answer = find_answer()
print('Answer: ' + answer)
Иногда это может сбить с толку, но в целом все нормально, я думаю. По крайней мере, я могу сдать экзамен с 60% правильных ответов :D