Создайте образ Docker для Jupyter Notebook и запустите на облачном VertexAI

Вы успешно запрограммировали приложение Python локально и теперь хотите перенести его в облако? Это простое и исчерпывающее пошаговое руководство о том, как превратить скрипт Python в образ Docker и отправить его в Google Cloud Registry. В Google Cloud Platform этот образ Docker может автоматически вызываться в VertexAI через Pub/Sub. Это руководство было создано на компьютере с Windows, но для Linux или Mac основные шаги одинаковы. В конце этой статьи вы сможете создать свой собственный образ Docker в своей операционной системе и автоматически запускать скрипты Python в VertexAI.
Через что вы пройдете:
- Установка «Docker Desktop»
- Образ и контейнер Docker: сборка, тегирование, запуск и отправка в GCloud
- Автоматически запускайте любой скрипт Python в GCloud VertexAI через Bash, Scheduler, Pub/Sub и Function.
Исходная ситуация
В этой структуре каталогов у вас есть следующие файлы:
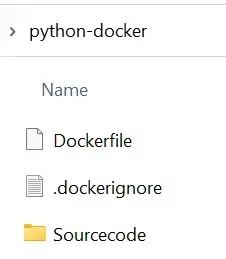
Папка исходного кода содержит Jupyter Notebook «dockerVertexai» и файл «input.csv»:
Сам Jupyter Notebook — это всего лишь крошечное приложение Python:
import pandas as pd
df=pd.read_csv('input.csv')
df['Output'] ='Now With Output added'
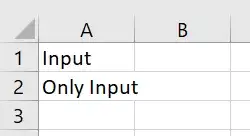
df.to_csv('output.csv')Все, что делает этот скрипт, — импортирует CSV-файл под названием «input»:
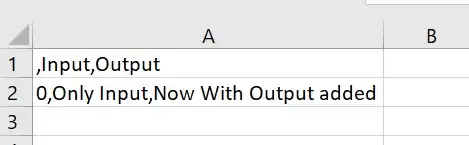
Добавляет новый столбец «Вывод» в этот фрейм данных и экспортирует результат в виде нового файла «output.csv»:
Несмотря на то, что это, возможно, не самый впечатляющий скрипт в мире, он очень хорошо послужит вам, чтобы позже легко подтвердить функциональность в VertexAI. Кроме того, мы надеемся, что этот скрипт предоставляет полезное расширение для обычных примеров «Hello World Flask Docker». Несмотря на то, что этот скрипт очень прост, он показывает вам, как работать не только с файлами исходного кода, но и с дополнительными файлами ввода-вывода в экземплярах облачного ноутбука. Обладая этими знаниями, нет никаких ограничений на то, что вы можете делать с Python в Cloud.
Подготовка:
Если это еще не так, вам нужно будет загрузить Docker Desktop, прежде чем вы сможете начать создавать образ Docker.
После загрузки версии (в данном случае для Windows) вы можете запустить Docker Desktop, просто открыв приложение:
Для нашей цели нам не нужно делать ничего, кроме запуска Docker Desktop.
Следующим этапом подготовки является Dockerfile.
Dockerfile
Сначала взгляните на Dockerfile:
FROM gcr.io/deeplearning-platform-release/base-cpu:latest
# RUN pip install torch # you can pip install any needed package like this
RUN mkdir -p /Sourcecode
COPY /Sourcecode /Sourcecode Dockerfile определяет, какой образ vm (виртуальная машина) будет использоваться при последующем запуске экземпляра. В этом случае вы выбираете версию платформы для глубокого обучения.
Если потребуются какие-либо дополнительные пакеты Python, они также могут быть установлены pip здесь (например, ЗАПУСТИТЕ pip install python-dotenv). Поскольку вы собираетесь использовать только Pandas (который уже поставляется с выпуском платформы глубокого обучения), нет необходимости устанавливать его pip.
Команда «run mkdir -p /Sourcecode» создаст новую папку «Sourcecode», как только экземпляр будет запущен и запущен позже.
Последняя команда в файле докеров скопирует все файлы из папки исходного кода (это папка в пути на вашем локальном компьютере, из которого вы вскоре собираетесь собрать образ докера) во вновь созданную папку исходного кода в работающем экземпляре (вы увидите это снова через несколько шагов).
Dockerignore
Кроме того, вы также можете дополнительно сохранить файл Dockerignore. Это предназначено для исключения пакетов, которые не требуются для выполнения кода Python. Это делается для того, чтобы образ был как можно меньше, а не для создания ненужных пакетов без необходимости.
__pycache__
Sourcecode/tempDockerignore не имеет значения для дальнейших шагов этого руководства.
Для создания образов Docker вы также можете использовать Requirement.txt файлы.
В качестве самой последней подготовки (перед тем, как вы сможете запустить сборку Docker) вам понадобится развернутый проект на Google Cloud Platform.
Google Cloud Project
Наш совет на этом этапе — скопировать ProjectId, потому что он понадобится вам много раз в этом руководстве. Идентификатор проекта в GCP для этого примера: socialsentiment-xyz.
Command-Line Interface (CLI)
Интерфейс командной строки gcloud (Google Cloud) является основным инструментом CLI для создания облачных ресурсов Google и управления ими. Инструмент CLI выполняет многие общие платформенные задачи из командной строки, а также в сценариях и других средствах автоматизации. Если вы еще не скачали CLI, вы можете найти инструкции здесь.
Сначала вы инициализируете конфигурацию, чтобы иметь возможность работать с вашим Google Cloud Project в командной строке:
gcloud init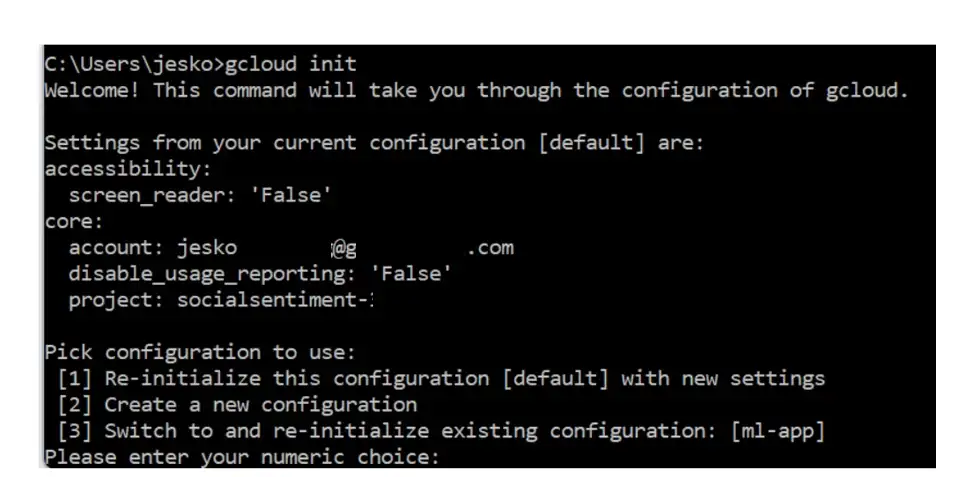
Войдите в существующую учетную запись:
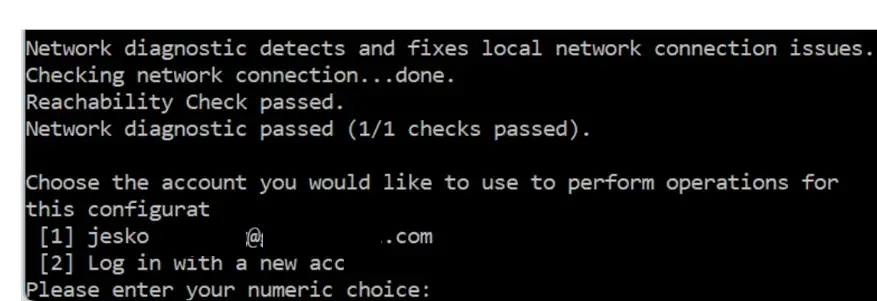
И, наконец, выберите соответствующий номер проекта (если есть).
Включить Artifact Registry для проекта
По умолчанию реестр артефактов не включен для новых проектов. Поэтому вы должны сначала включить его (иначе вы не сможете публиковать в GCloud Artifact Registry).
Чтобы включить Artifact Registry, выполните следующую команду:
gcloud services enable artifactregistry.googleapis.comИ добавьте список имен repository-host, например europe-west3-docker.pkg.dev:
gcloud auth configure-docker europe-west3-docker.pkg.dev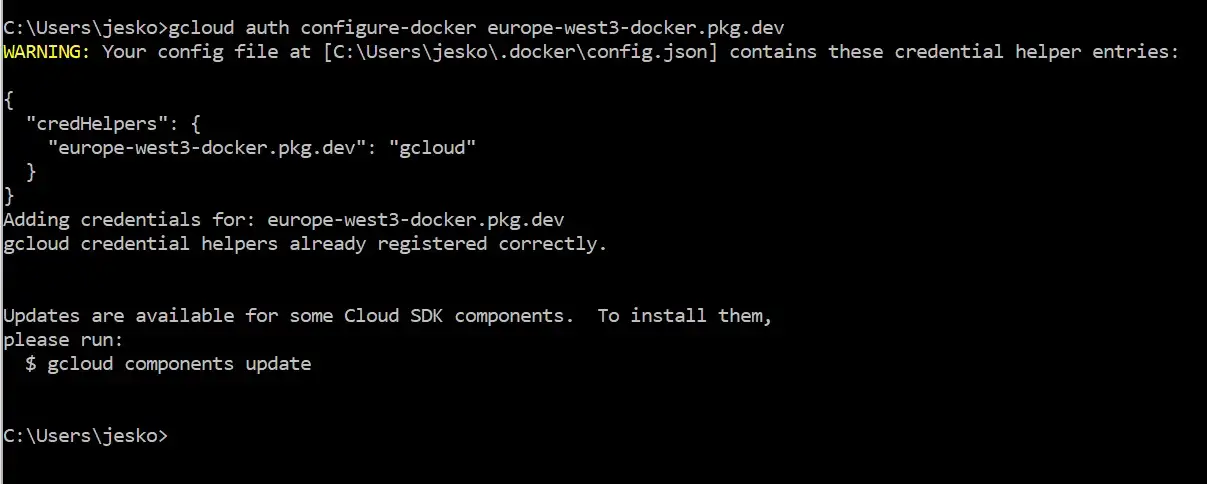
Отлично, вы закончили все приготовления и наконец-то можете приступить к сборке Docker.
Сборка образа Docker
В терминале перейдите в папку, в которой хранятся ваши локальные файлы, и введите:
docker build --tag python-docker .Обратите внимание на пробел перед точкой.
Если вы получаете сообщение об ошибке, например «Демон Docker не запущен», это может быть связано с тем, что вы забыли запустить приложение Docker Desktop. Просто запустите Docker-Desktop (как упоминалось в начале) и повторно запустите команду сборки docker.
После сборки:

Закончено:


Образ Docker запущен и работает. Вы также можете получить дополнительную уверенность в этом, взглянув на приложение Docker Desktop:
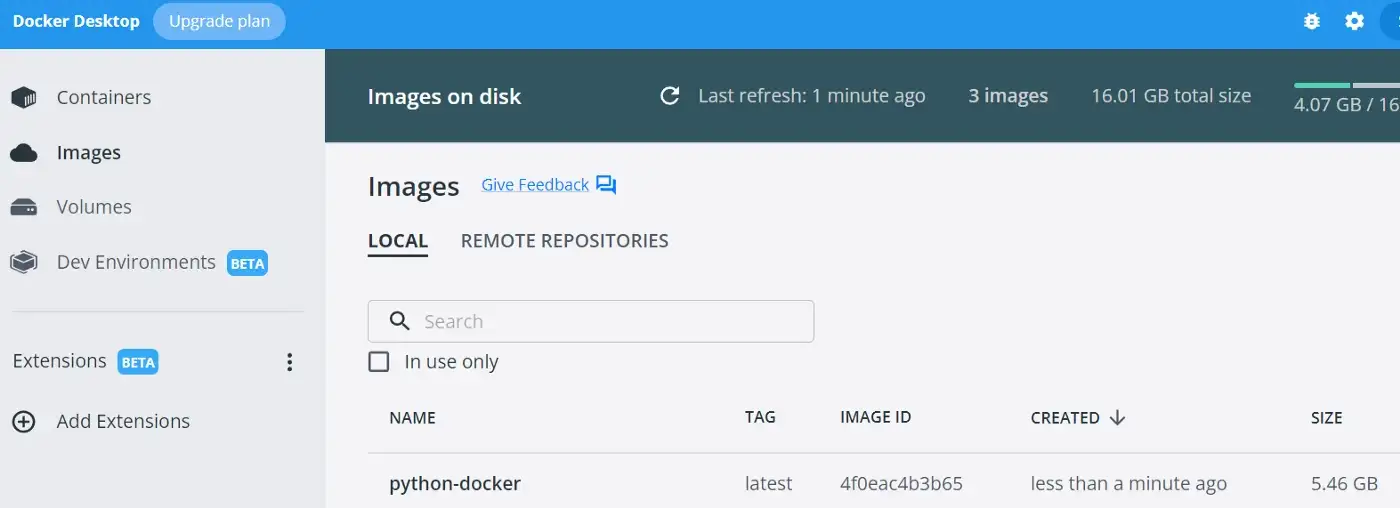
Или вы также можете перепроверить это в своем терминале:
docker images
Docker Image Tag
Скопируйте и вставьте ImageID из приведенной выше команды изображений Docker и используйте его в качестве тега Docker. Во-вторых, вам нужно скопировать путь для вашего проекта Google Cloud. Он состоит из вашего идентификатора проекта Google Cloud (socialsentiment-xyz) и репозитория (имя из настроек вашего артефакта):

Docker Run
Хотя этот шаг не имеет для нас дальнейшего значения, он кратко упоминается для полноты картины.
Просто используйте run для запуска образа в качестве контейнера:
docker run python-dockerArtifact Repository
Есть еще одна перекрестная ссылка в этом месте. Но пока мы не создали репозиторий Artifact на платформе GCloud. Но это элементарно важно, прежде чем вы сможете запушить образ Docker. К счастью, это детская игра:
Вы должны создать репозиторий для загрузки артефактов. Каждый репозиторий может содержать артефакты для поддерживаемого формата, в вашем случае Docker.
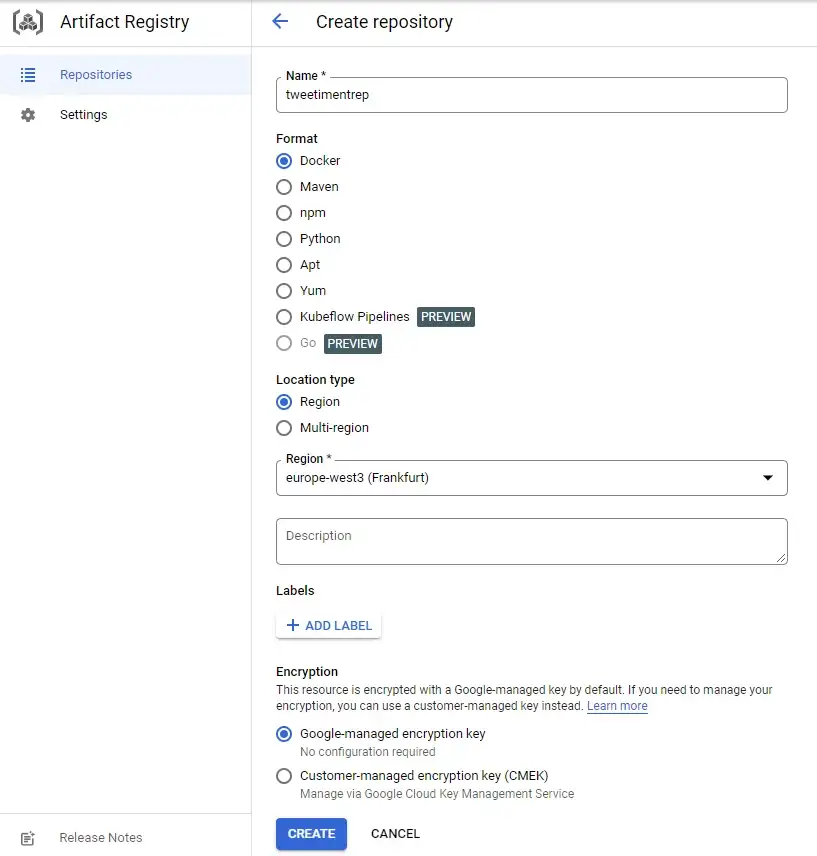
Выберите подходящий вам регион. В нашем случае это Франкфурт:
Прежде чем продолжить, убедитесь, что вы действительно создали имя репозитория в артефакте GCloud:
Извините за непоследовательность: когда в дальнейшем упоминается tweetiment-xyz, имеется в виду тот же проект socialsentiment-xyz.
Тег Docker Image
Теперь продолжайте и отметьте свои настройки соответствующим образом:
docker tag 4f0eac4b3b65 europe-west3-docker.pkg.dev/tweetiment-xyz/tweetimentrep/python-dockerВот как легко вы пометили образ Docker.
Теперь, когда вы пометили образ Docker, вы можете отправить его в реестр GCP:
docker push europe-west3-docker.pkg.dev/tweetiment-xyz/tweetimentrep/python-dockerЕсли вы получили сообщение, похожее на это:

Это означает только то, что вам нужно активировать Artifact Registry API (и не забудьте указать ему имя репозитория, иначе вы не сможете правильно пометить и отправить образ Docker).
Теперь вы можете повторно запустить команду push. Если API по-прежнему не активен, просто подождите несколько минут, пока он не активируется.
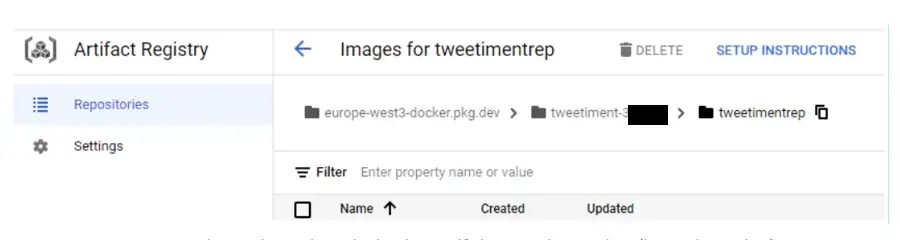
После того, как Push будет готов:

Вы сможете увидеть его в своем Artifact Registry:
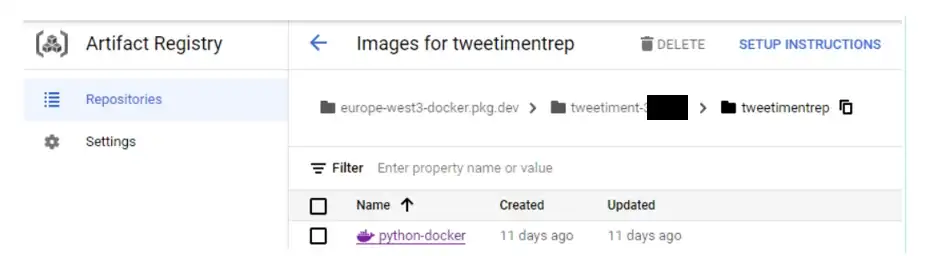
Отлично, вы перенесли свой код Python вместе со структурой папок и содержимым в Google Cloud в виде образа Docker! Это означает, что вы можете создать записную книжку в Google Cloud, где вы можете вручную запустить записную книжку Jupyter (или код Python .py).
VertexAI
Полезно понять, как вручную создать экземпляр Notebook. Если вы не знаете, как, эта ссылка должна быть вспомогательной. Но гораздо интереснее научиться запускать такой экземпляр автоматически. Для этого сначала посмотрите, как автоматически запускать скрипт Python в экземпляре VertexAI после его создания. Для этого используйте скрипт bash (файл .sh).
Bash Script
#!/bin/bash
# copy sourcode files from docker container to vm directory
sudo docker cp -a payload-container:/Sourcecode/ /home/jupyter
sudo -i
cd /home/jupyter/Sourcecode
# Execute notebook
ipython -c “%run dockerVertexai.ipynb”Теперь загрузите файл запуска script.sh в корзину вашего облачного хранилища:
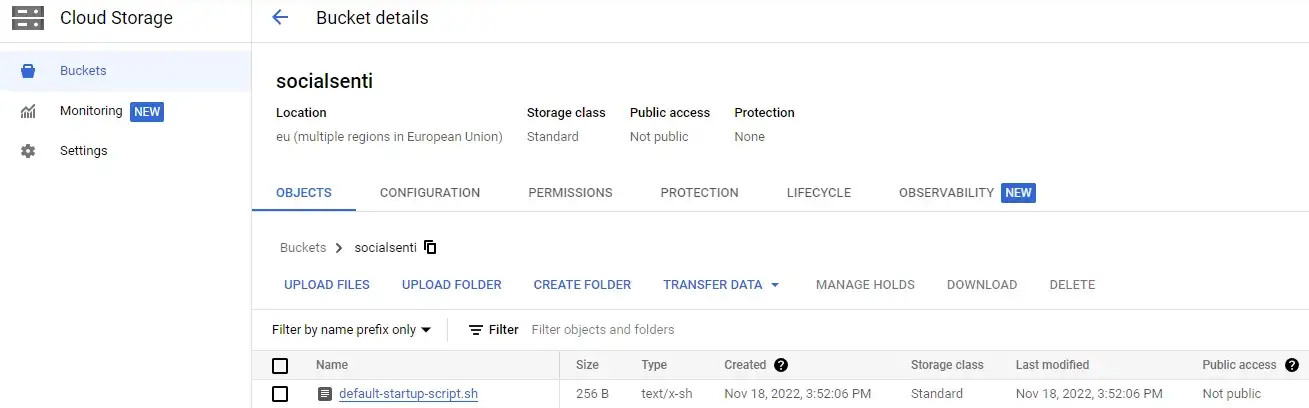
Перейдите на VertexAI и активируйте VertexAI API и Notebook API, если это еще не сделано.
В Workbench нажмите «Новый блокнот» и выберите «Настроить» в качестве первого варианта сверху:
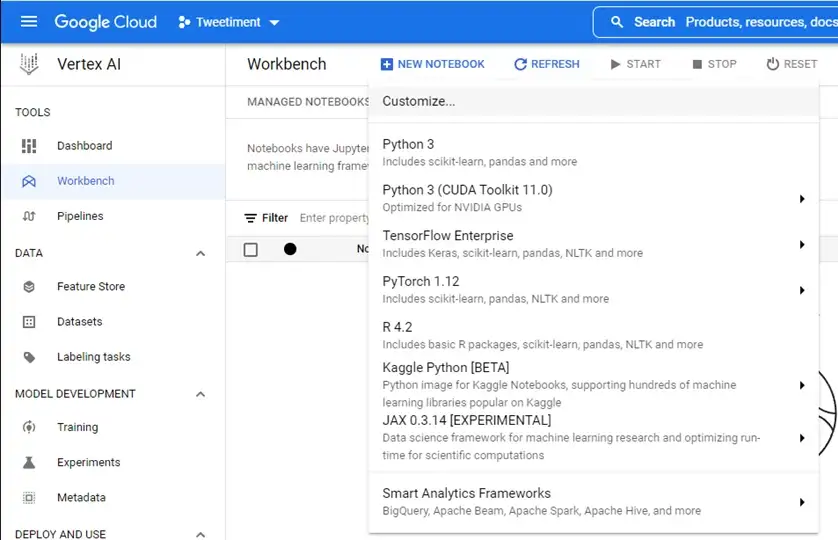
В следующей форме выберите изображение вашего контейнера из вашего реестра артефактов.
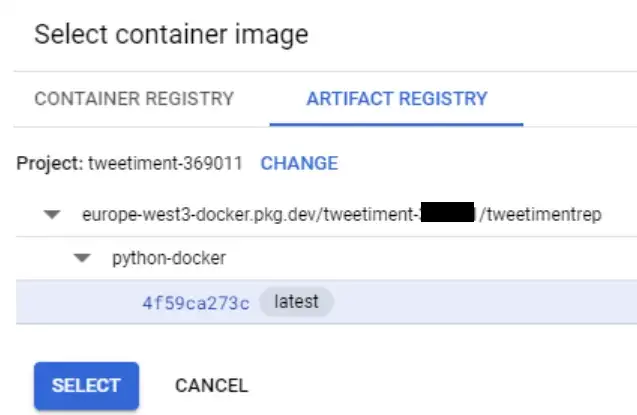
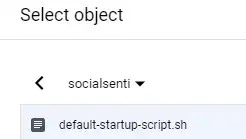
Также не забудьте выбрать сценарий для запуска после создания. Это будет ваш файл .sh, который вы только что сохранили в своей корзине несколько минут назад:
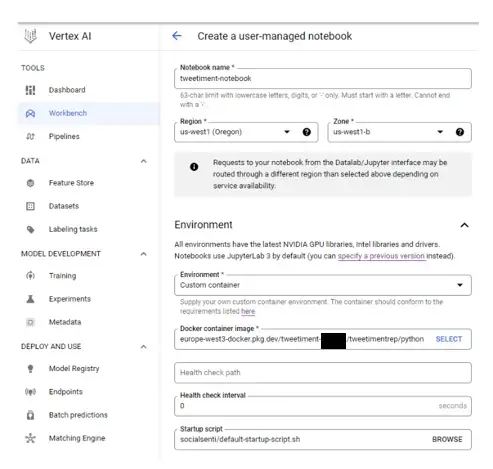
И теперь вы можете идти:
Благодаря сценарию запуска Jupyter Notebook автоматически запускался при загрузке экземпляра Jupyter Lab. Вы можете убедиться, что скрипт запустился из-за существования файла output.csv (которого раньше не было):
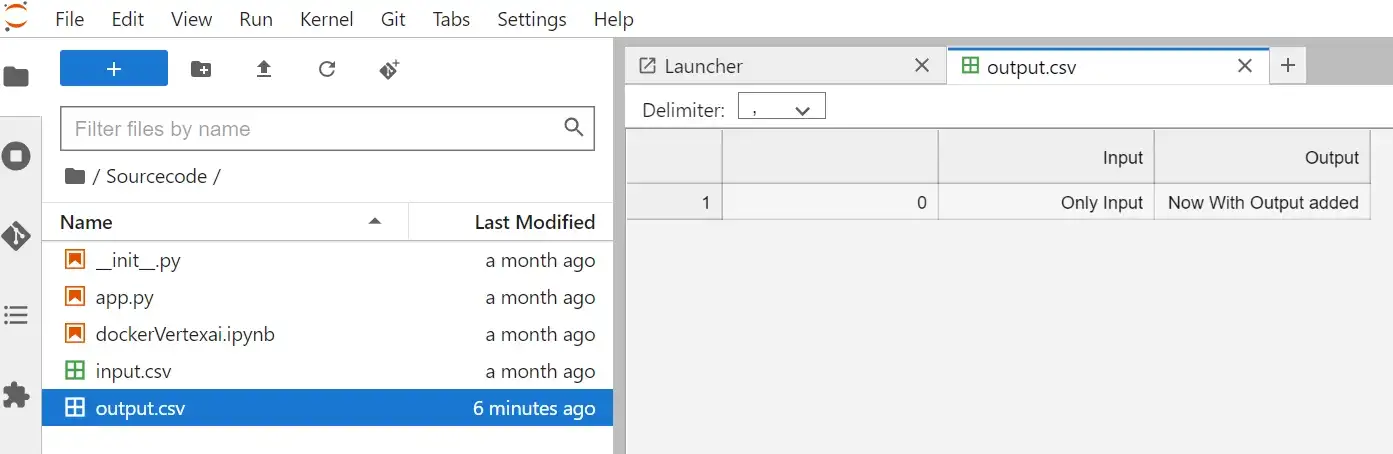
Скрипт выполнился автоматически и был создан выходной файл. Но, к сожалению, этот выходной файл не сохраняется. Так что лучше будет сохранить этот файл в облачном хранилище. А именно в созданном нами ранее ведре.
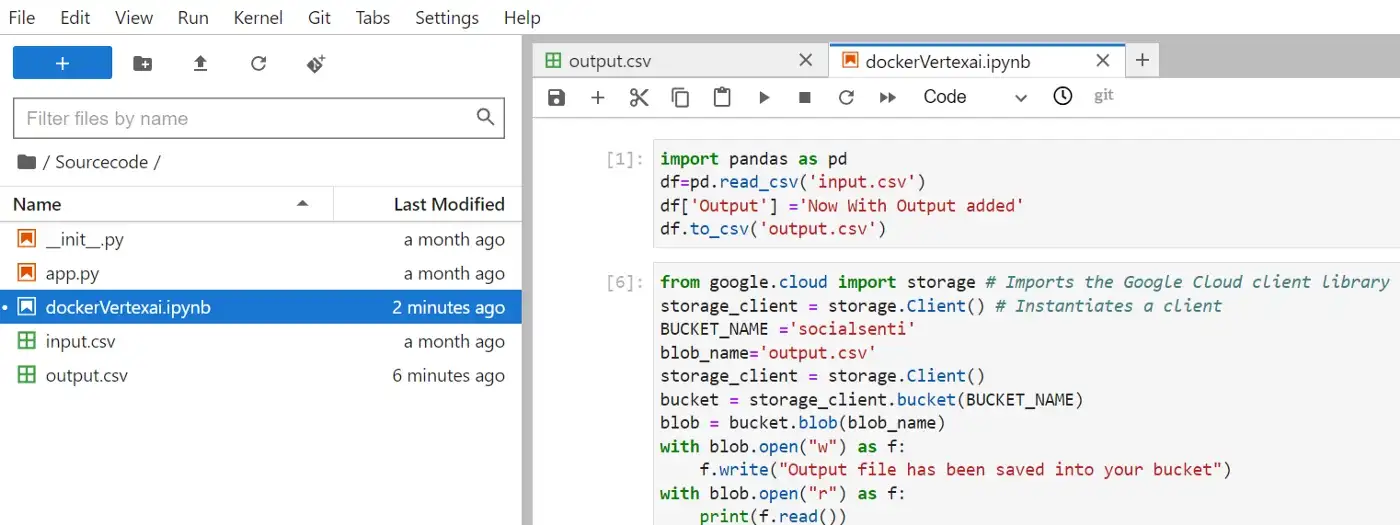
from google.cloud import storage # Imports the Google Cloud client library
storage_client = storage.Client() # Instantiates a client
BUCKET_NAME =’socialsenti’
blob_name=’output.csv’
storage_client = storage.Client()
bucket = storage_client.bucket(BUCKET_NAME)
blob = bucket.blob(blob_name)
with blob.open(“w”) as f:
f.write(“Output file has been saved into your bucket”)
with blob.open(“r”) as f:
print(f.read())Добавьте это в новую ячейку вашего блокнота Jupyter, и вы увидите, что выходной файл впоследствии будет сохранен в вашей корзине.
Но есть еще одна возможная оптимизация. Потому что до сих пор экземпляр работает постоянно, даже если результат (выходной файл) уже создан. Таким образом, вам понадобится способ выключения виртуальной машины (в конечном счете, VertexAI использует только Google Compute Engine GCE) в конце сценария, чтобы не нести дополнительных затрат на ожидание.
Теперь давайте сделаем следующий шаг к автоматизации. Вместо того, чтобы запускать экземпляр вручную, теперь вы создадите его командой из терминала:
gcloud notebooks instances create instancetweetiment - container-repository=europe-west3-docker.pkg.dev/tweetiment-xyz/tweetimentrep/python-docker - container-tag=latest - machine-type=n1-standard-4 - location=us-central1-b - post-startup-script="gs://socialsenti/default-startup-script.sh"Или, если хотите, вы можете запустить его прямо из блокнота Jupyter.
from google.cloud.notebooks_v1.types import Instance, VmImage, ContainerImage
from google.cloud import notebooks_v1
client = notebooks_v1.NotebookServiceClient()
notebook_instance = Instance(container_image=ContainerImage(repository="europe-west3-docker.pkg.dev/tweetiment-xyz/tweetimentrep/python-docker",),machine_type="n1-standard-8",post_startup_script="gs://socialsenti/default-startup-script.sh")
parent = "projects/tweetiment-xyz/locations/us-central1-a"
request = notebooks_v1.CreateInstanceRequest(parent=parent,instance_id="notetweeti",instance=notebook_instance,)
op = client.create_instance(request=request)
op.result()На всякий случай, если вы получите сообщение об ошибке из-за отсутствия аутентификации при первом запуске, выполните эту команду. Это создаст файл учетных данных:
gcloud auth application-default loginЭтот файл учетных данных обычно хранится по этому пути: %APPDATA%\gcloud\application_default_credentials.json
Теперь вы можете программно добраться до GCP. Если вы создали записную книжку (независимо от того, вручную или программно), вы можете прочитать ее с помощью этого кода Python. Instance_Name — это имя самой записной книжки. Этот отрывок из документации GCP:
from google.cloud import notebooks_v1
def sample_get_instance():
# Create a client
client = notebooks_v1.NotebookServiceClient()
# Initialize request argument(s)
request = notebooks_v1.GetInstanceRequest(
name="projects/tweetiment-xyz/locations/us-central1-a/instances/test",
)
# Make the request
response = client.get_instance(request=request)
# Handle the response
print(response)
sample_get_instance()Если вы хотите запланировать повторяющийся скрипт Python, вы можете использовать Google Cloud Scheduler в сочетании с Cloud Function и Pub/Sub.
Cloud Scheduler

Выберите Pub/Sub в качестве типа цели и соответствующую тему Pub/Sub:
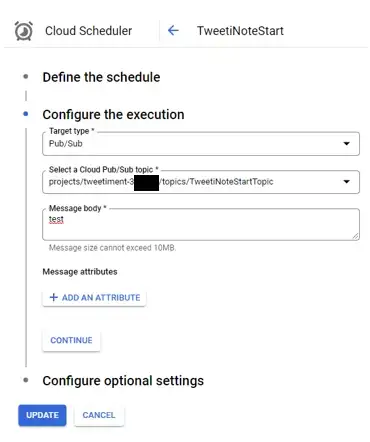
Вы можете подождать, пока не наступит время, когда планировщик должен стать активным. Вы также можете запустить его вручную в любое время, чтобы проверить его.
Планировщики хорошие. Но иногда вы также хотите, чтобы скрипт Python выполнялся сразу после выполнения действия на веб-странице. Для этой цели облачные функции — хороший выбор.
Cloud Functions
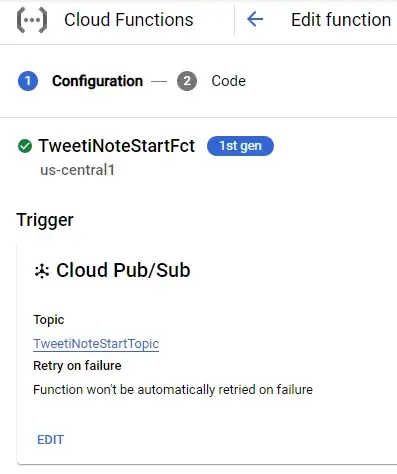
Выберите Python в качестве среды выполнения и введите, например. «TweetiNoteStartTopic» в качестве точки входа. Эта точка входа также будет именем вашей функции. Итак, в итоге облачная функция выглядит так:
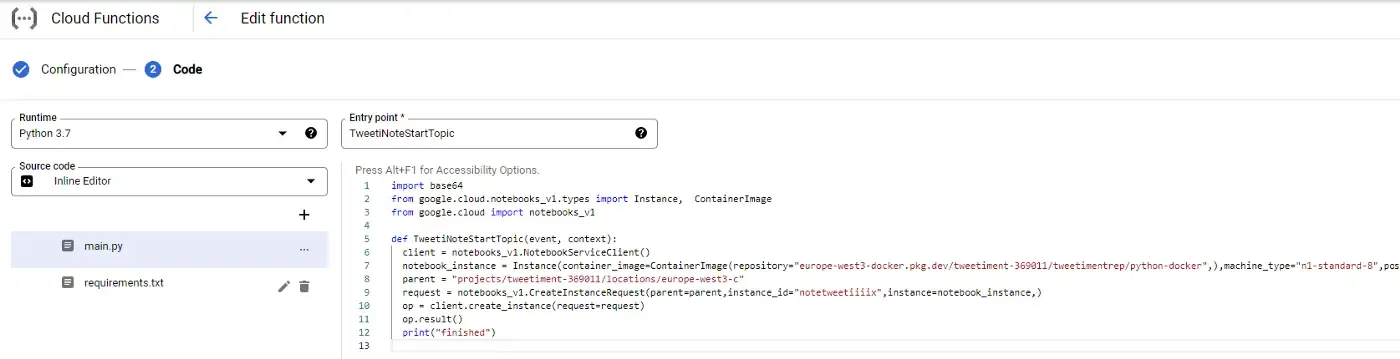
В файле requirements.txt вы можете разместить все зависимости по мере необходимости:
# Function dependencies, for example:
google-cloud-notebooks>=1.4.4
google-cloud>=0.34.0И ваш main.py может быть похож на это:
import base64
from google.cloud.notebooks_v1.types import Instance, ContainerImage
from google.cloud import notebooks_v1
def TweetiNoteStartTopic(event, context):
client = notebooks_v1.NotebookServiceClient()
notebook_instance = Instance(container_image=ContainerImage(repository="europe-west3-docker.pkg.dev/tweetiment-xyz/tweetimentrep/python-docker",),machine_type="n1-standard-8",post_startup_script="gs://socialsenti/default-startup-script.sh")
parent = "projects/tweetiment-xyz/locations/us-central1-a"
request = notebooks_v1.CreateInstanceRequest(parent=parent,instance_id="notetweeti",instance=notebook_instance,)
op = client.create_instance(request=request)
op.result()
print("finished")Pub/Sub
Обратите внимание, что вы также можете активировать облачную функцию в любое время. Просто перейдите на вкладку test и введите этот json: {“data”:”TweetiNoteStartTopic"}.
Вывод
Теперь вы можете программно запускать любые скрипты Python в облаке. Либо напрямую через Cloud Function в виде чистого скрипта Python, либо в виде контейнера Docker на виртуальной машине. Именно VertexAI предлагает вам запускать Jupyter Notebook в среде Jupyter Lab, которая сама работает на виртуальных машинах в Google Cloud Engine (GCE). Благодаря оборудованию Google, которое можно программно настроить на VertexAI, ограничений почти нет. Теперь можно с гордостью носить рубашку Google Cloud.