Создание веб-приложения для визуализации данных с использованием python-Streamlit
Обычно, когда мы думаем о создании и распространении в Интернете панели мониторинга визуализации или приложения машинного обучения на Python (скажем) для наших коллег / товарищей по команде / заинтересованных сторон или в качестве нашего портфолио, мы полагаемся на старых добрых гигантов, таких как Django или Flask.
Очевидно, что использование таких фреймворков дает множество преимуществ. Но загвоздка здесь в том, насколько они удобны, быстры, интуитивно понятны для разработчика с низким уровнем кода? Я имею в виду, зачем нам нужен разработчик Django / Flask отдельно для небольшой команды или для быстрой демонстрации ML приложения. При рассмотрении вышеперечисленных параметров Streamlit превосходит их всех.
Что такое Streamlit?
Streamlit - это библиотека Python с открытым исходным кодом, которая упрощает создание и публикацию красивых пользовательских веб-приложений для машинного обучения и науки о данных. Всего за несколько минут вы можете создавать и развертывать мощные приложения для обработки данных.
Преимущества Streamlit:
- Легко учиться - практически не требуется обучения
- Удобный для пользователя (удобный для разработчиков)
- Меньше времени на сборку
- Сторонние интеграции для графиков
- И многое другое…
Поскольку мы увидели преимущества streamlit, давайте начнем с того, насколько легко с его помощью создать простое веб-приложение для визуализации данных. Имейте в виду, все это было сделано всего за несколько часов. Поскольку у меня нет предварительных знаний в области оптимизации и хорошего опыта программирования. Я знаю, как сложно просто настроить и изучить «Django» в системе. Таким образом, с точки зрения сложности я оцениваю это следующим образом: Django >> Flask >> Streamlit. Django - самый сложный, streamlit - самый простой.
Обзор проекта:
Я использовал общедоступный API для извлечения данных, необходимых для создания визуализаций. Сделал небольшие преобразования данных, как обычно, чтобы получить только необходимые данные в соответствии с требованиями. Построил базовые графики с помощью «Plotly». Попытался использовать большинство функций, но при этом сделать их простыми и быстрыми.
Чтобы сделать этот пост в блоге коротким, я сохранил весь код на своем GitHub. Не стесняйтесь заполучить его в свои руки. Взгляните на веб-приложение здесь.
Основы:
- Установка (windows)
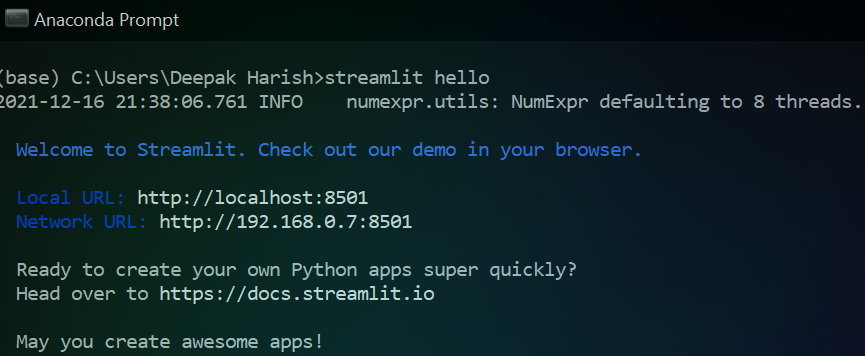
streamlitосуществляется через обычныйpip.pip install streamlit. Для других платформ, пожалуйста, проверьте страницу документа. - Чтобы протестировать нашу установку, запустите
streamlit helloв командной строке. Он открывается в браузере по умолчаниюlocalhost:8501. Откроется страница документации с несколькими примерами демонстраций. (Предлагаю попробовать, так как в нем много классных демоверсий)
Создание приложения:
После успешной установки вы увидите изображение, как на изображении выше, после того, как запустите команду. Пришло время создать настоящие вещи и стать свидетелем волшебства Streamlit. Я использовал редактор «sublime_text» для написания кода. Выбор за вами.
Это набор данных, который я использовал. По сути, набор данных TFL - это живой API с открытым исходным кодом. Просто краткое описание шагов по извлечению данных из API.
Шаг 1. Используйте библиотеку requests для извлечения данных API.
import requests as r
def get_data(url):
api = r.get(url)
api_status_code = api.status_code #200
api_data = api.json() #converting into json format
api_data_normal = pd.json_normalize(api_data) #converting into dataframe
return api_data_normal
get_data('https://api.tfl.gov.uk/AccidentStats/2019')Шаг 2. Во-вторых, после преобразования URL-адреса и извлечения данных API в формат JSON, а затем во фрейм данных, выполните необходимые преобразования данных. Ниже приведен код для базового преобразования данных.
api_data_normal = get_data()
api_casualities = pd.json_normalize(api_data_normal['casualties'])
api_casualities_col = pd.json_normalize(api_casualities[0])
#api_casualities_col['$type'][0]
api_casualities_col = api_casualities_col.drop(columns = '$type')
casuality_cols = api_casualities_col.columns
age = pd.Series(api_casualities_col['age'], name = 'age')
casualities_class = pd.Series(api_casualities_col['class'], name = 'class')
severity = pd.Series(api_casualities_col['severity'], name = 'severity')
mode = pd.Series(api_casualities_col['mode'], name = 'mode')
ageBand = pd.Series(api_casualities_col['ageBand'], name = 'ageBand')
api_vehicles = pd.json_normalize(api_data_normal['vehicles'])
api_vehicles_col = pd.json_normalize(api_vehicles[0])
api_vehicles_col = pd.Series(api_vehicles_col['type'], name = 'vehicles')
api_data_normal = api_data_normal.drop(columns = ['$type','casualties', 'vehicles'])
api_data_modified = pd.concat([api_data_normal,age, casualities_class, mode, ageBand, api_vehicles_col], axis=1)
class_dict = dict(api_data_modified['class'].value_counts())
class_df = pd.DataFrame(class_dict.items(), columns = ['class', 'count'])
mode_dict = dict(api_data_modified['mode'].value_counts())
mode_df = pd.DataFrame(mode_dict.items(), columns = ['mode', 'count'])
age_dict = dict(api_data_modified['age'].value_counts())
age_df = pd.DataFrame(age_dict.items(), columns = ['age', 'count'])
drop_cols = ['id', 'location', 'date', 'severity', 'borough', 'age', 'class', 'mode', 'ageBand', 'vehicles']
map_df = api_data_modified.drop(columns = drop_cols)Шаг 3: Теперь, когда преобразование данных выполнено, пришло время использовать фактические функции streamlit. Как ‘containers’, ‘sidebars’, ‘plotly’ для диаграмм, инструменты шрифтов, такие как 'subheaders', 'markdown', 'title' и т. д.
Примечание: это лишь некоторые из них, и вот полный список разнообразных функций, которые можно использовать, чтобы сделать наше веб-приложение более красивым и функциональным одновременно.
Позвольте мне показать вам, как просто создать контейнер. Контейнер на самом деле помогает разместить наш контент и идеально выровнять его на странице.
import streamlit as st
dataExploration = st.container()
with dataExploration:
st.title('Transport for London')
st.subheader('Keeping London moving...')
st.header('Dataset: Transport for London')
st.markdown('I found this dataset at... https://tfl.gov.uk/info-for/open-data-users/')
st.markdown('**Basically, it is a "London AccidentStats" dataset for the year 2019**')
st.text('Below is the sample DataFrame')
st.write(api_data_modified.head())Как видно из приведенного выше фрагмента кода, streamlit был импортирован. Создан контейнер, в котором есть встроенные функции 'title' (заголовок страницы, выделенный жирным крупным шрифтом), 'subheader', 'header', 'markdown', 'text', 'write' для обслуживания большинства потребностей. Здесь мы можем просматривать наш набор данных в форме dataframe прямо на веб-странице. Поскольку строк много, не рекомендуется просматривать весь набор данных, вместо этого я использовал, .head(), чтобы вывести только первые 5 строк данных.
Итак, чтобы увидеть наш контент на веб-странице во время разработки, все, что нам нужно сделать, это запустить stream run app_name.py в командной строке, находясь в той же папке, где находится приложение. Он будет открыт в localhost: 8501 браузера по умолчанию. И каждый раз, когда вы вносите изменения в код веб-приложения, вы можете выбрать run, либо rerun always автоматически перезапуская страницу при каждом внесении изменений. Они находятся в правом верхнем углу веб-приложения.
Точно так же я создал другие контейнеры, внутри которых есть графики, построенные с помощью «Plotly». Его интеграция также очень проста и понятна. Просто надо использовать st.plotly_chart(). Вот пример графической визуализации, построенной в контейнере.
severity_viz = st.container()
with severity_viz:
st.header('Severity wise AccidentStats')
st.text('A pie chart depicting the count of accident severity')
severity_plot = px.pie(api_data_modified, values='id', names='severity')
st.plotly_chart(severity_plot)Я также использовал встроенную функцию карты, чтобы отобразить на карте данные о долготе и широте.
map_con = st.container()
drop_cols = ['id', 'location', 'date', 'severity', 'borough', 'age', 'class', 'mode', 'ageBand', 'vehicles']
map_df = api_data_modified.drop(columns = drop_cols)
with map_con:
st.header('A simple map of the accident zones in london')
st.map(map_df, use_container_width = True)Я также использовал боковую панель, чтобы поздороваться и поприветствовать пользователя на странице. st.sidebar.header('*Hey, Hello there!!!*')
Наконец, я использовал специальную функцию @st.cache, которая на самом деле помогает создать кеш для нашего веб-приложения, которое в противном случае использует свою энергию, тратит время на загрузку набора данных каждый раз, когда мы запускаем наше приложение. Это тоже самый простой способ.
@st.cache
def get_data():
api = r.get('https://api.tfl.gov.uk/AccidentStats/2019')
api_status_code = api.status_code
api_data = api.json()
api_data_normal = pd.json_normalize(api_data)
cols = api_data_normal.columns
return api_data_normalШаг 4: Наконец, есть небольшой, но довольно важный шаг. Это развертывание веб-приложения. Я имею в виду, что весь смысл использования библиотеки и цель создания веб-приложения - поделиться. Если у вас на это есть свои планы, то ничего страшного. Если нет, то об этом тоже не нужно беспокоиться. «Streamlit» получил вашу поддержку, фактически разрешив хостинг веб-приложения на своих серверах, и это тоже бесплатно!!! Как это удивительно!
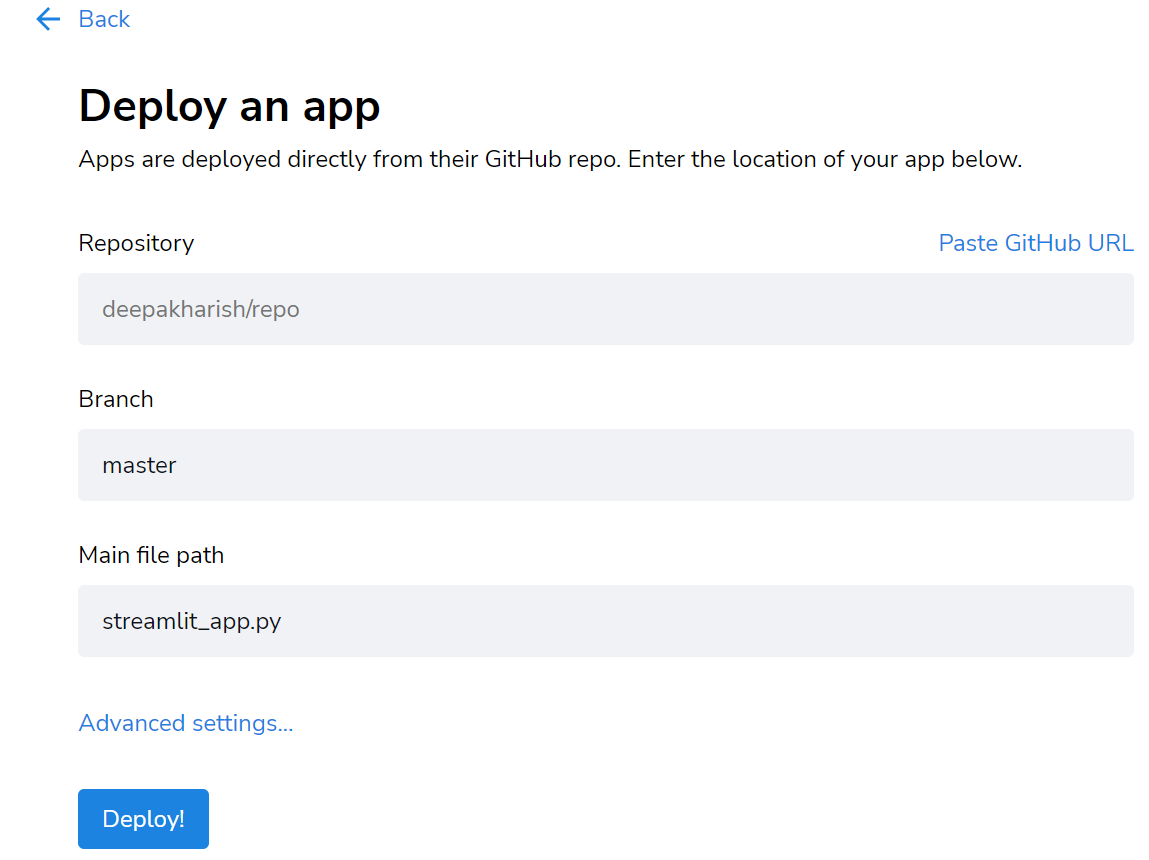
Все, что вам нужно сделать, это зарегистрироваться на их веб-сайте с помощью учетной записи Google или Github. Предпочтительно Github, так как это место, где должен быть ваш код.
- Во-первых, создайте файл
requirements.txt, используяpipreqs. - Загрузите приложение вместе с
requirements.txtв Github. - Нажмите кнопку «new app» справа от страницы оптимизированного развертывания.
- Вставьте ссылку на репозиторий Github, где находится код приложения.
- Щелкните «Deploy». Вот и все. Что ж, всего за несколько минут приложение развернуто.
В конечном счете, специалист по данным должен сосредоточиться на анализе и получении информации из данных, чтобы представить их заинтересованным сторонам для принятия решений. И тратьте меньше времени на размышления о различных действиях разработчика программного обеспечения, таких как интерфейс / бэкэнд приложения.