В 4 раза быстрее операции Pandas с минимальным изменением кода

Одним из основных ограничений Pandas является то, что он может быть медленным при работе с большими наборами данных, особенно при выполнении сложных операций. Это может расстроить специалистов по обработке данных и аналитиков, которым в своей работе необходимо обрабатывать и анализировать большие наборы данных.
Есть несколько способов решить эту проблему. Одним из способов является использование параллельной обработки.
Введите Pandarallel
Pandarallel — это библиотека Python с открытым исходным кодом, которая обеспечивает параллельное выполнение операций Pandas с использованием нескольких CPU, что приводит к значительному ускорению.
Он построен на основе популярной библиотеки Pandas и требует лишь нескольких изменений кода.
Достижение значительного ускорения с Pandarallel
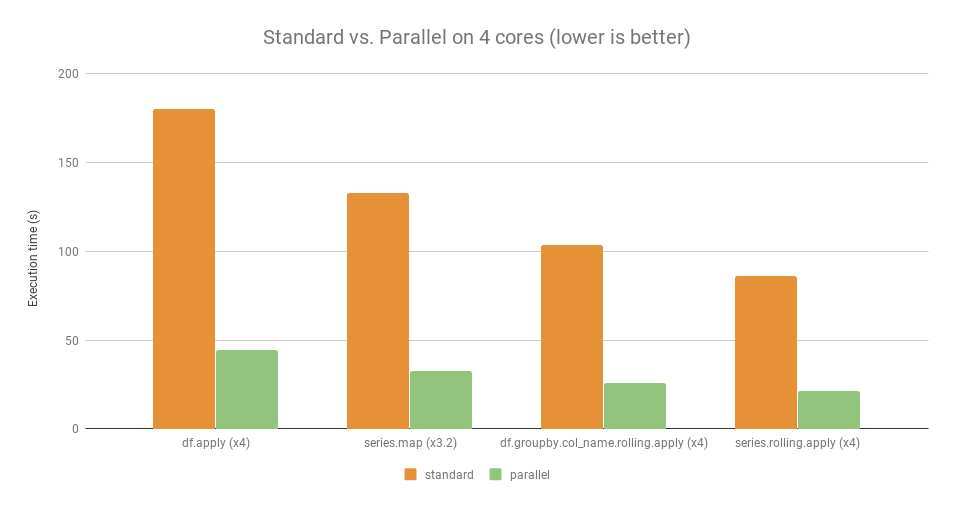
Вы можете сами убедиться, насколько быстрее pandas apply по сравнению с parallel_apply от pandarallel. Здесь pandarallel распределил нагрузку по 4 ядрам.

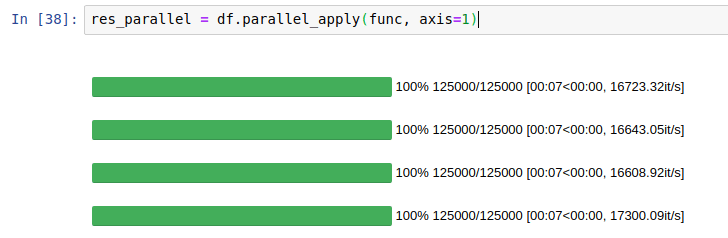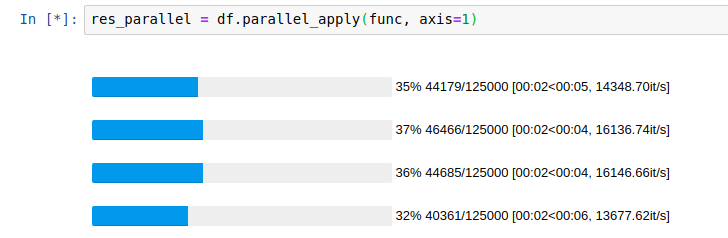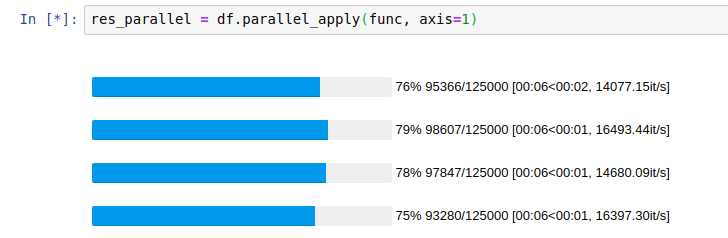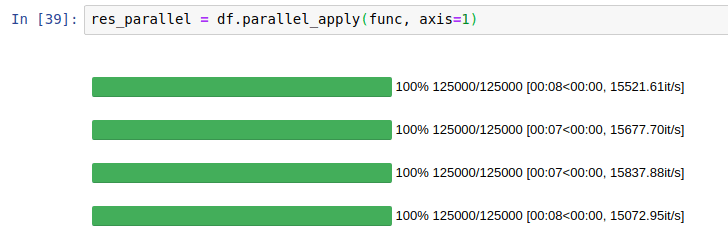
Более конкретно, ускорение видно из диаграммы ниже.
Начало работы с Pandarallel
Чтобы установить Pandarallel, вы можете использовать менеджер пакетов pip:
pip install pandarallelВы можете импортировать пакет в свой код Python и инициализировать его.
from pandarallel import pandarallel
# Initialize pandarallel
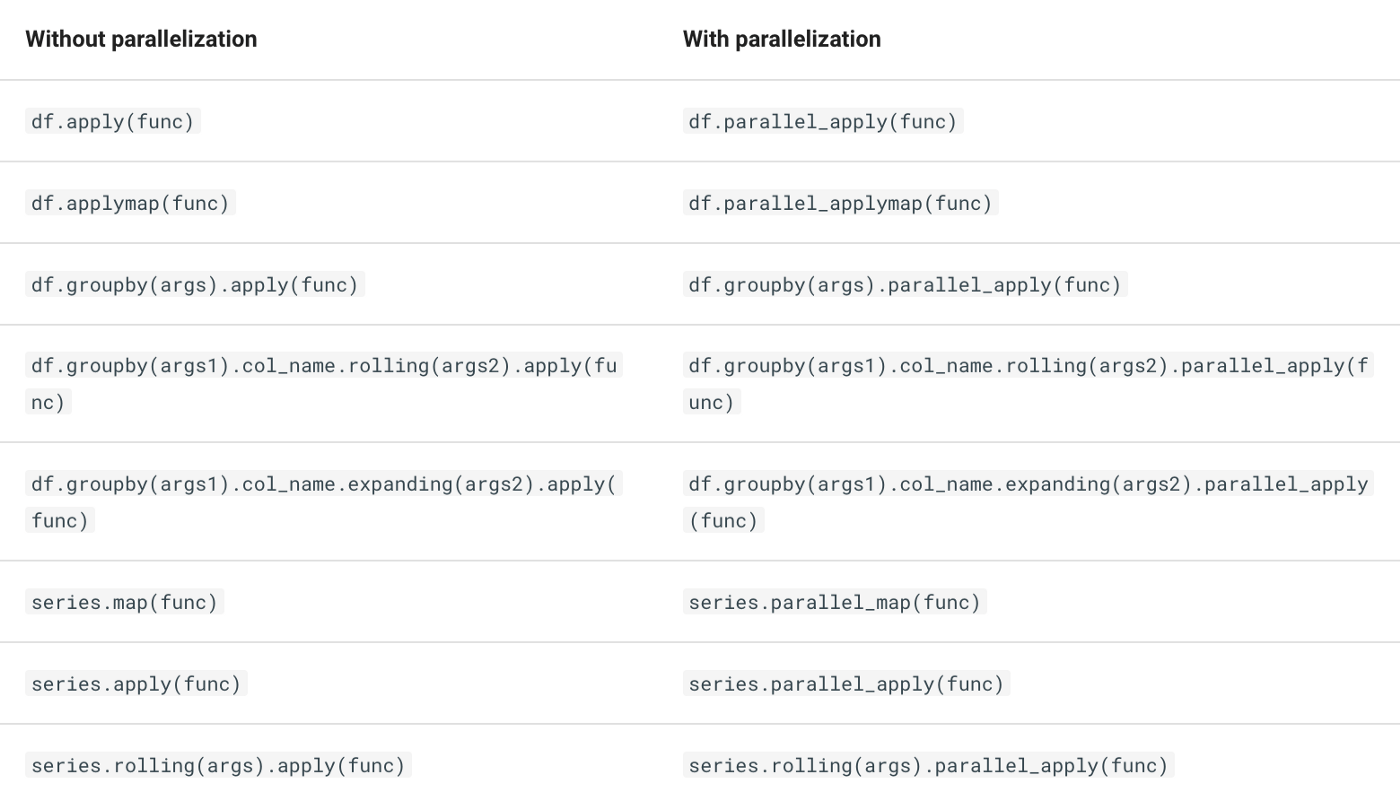
pandarallel.initialize()Как только это будет сделано, вы можете использовать следующие предоставленные функции.
Пример кода использования Pandarallel
Давайте сначала создадим фиктивный фрейм данных, содержащий покупки на сайте электронной коммерции. Каждая строка соответствует покупке одного продукта в каждую дату. Столбцы:
dateproduct_idquantity
import pandas as pd
import numpy as np
# Generate a dataframe.
df = pd.DataFrame()
# Generate a column of random dates from 2019-01-01 to 2019-12-31
df['date'] = pd.date_range('2019-01-01', '2019-12-31', periods=10000)
# Seed numpy random
np.random.seed(0)
# Generate a column of random product_id from 1 to 5
df['product_id'] = np.random.randint(1, 5, 10000)
# Generate a column of quantity bought from 1 to 100
df['quantity'] = np.random.randint(1, 100, 10000)Вот первые пять строк.
| | date | product_id | quantity |
|---:|:--------------------|-----------:|---------:|
| 0 | 2019-01-01 00:00:00 | 1 | 10 |
| 1 | 2019-01-01 00:52:25 | 4 | 36 |
| 2 | 2019-01-01 01:44:50 | 2 | 79 |
| 3 | 2019-01-01 02:37:15 | 1 | 33 |
| 4 | 2019-01-01 03:29:41 | 4 | 59 |Далее давайте воспользуемся pandarallel, чтобы ускорить наш рабочий процесс. Для этого давайте инициализируем наш pandarallel.
from pandarallel import pandarallel
# Initialize pandarallel
pandarallel.initialize()Обратите внимание, что у вас есть несколько вариантов инициализации pandarallel.
# Initialize pandarallel with a progress bar
pandarallel.initialize(progress_bar = True)
# Set the number of workers for parallelization.
# By default, this is the number of cores available.
pandarallel.initialize(nb_workers = 4)
# Initialize pandarallel with all logs printed.
# By default, this is 2 (display all logs), while 0 display n ologs.
pandarallel.initialize(verbose = 2)Используйте parallel_apply для применения функции к столбцу
Давайте извлечем месяц из столбца date. Например, январь — это 1, а февраль — это 2. Для этого мы можем использовать функцию parallel_apply.
# Group date by month using parallel_apply
df['month'] = df['date'].parallel_apply(lambda x: x.month)
| | date | product_id | quantity | month |
|---:|:--------------------|-----------:|---------:|------:|
| 0 | 2019-01-01 00:00:00 | 1 | 10 | 1 |
| 1 | 2019-01-01 00:52:25 | 4 | 36 | 1 |
| 2 | 2019-01-01 01:44:50 | 2 | 79 | 1 |
| 3 | 2019-01-01 02:37:15 | 1 | 33 | 1 |
| 4 | 2019-01-01 03:29:41 | 4 | 59 | 1 |Мы также можем использовать функцию lambda в parallel_apply. Давайте назначим цену для каждого product_id. Затем мы можем рассчитать revenue для каждой транзакции.
# Assign a price to each product_id
df['price'] = df['product_id'].parallel_apply(lambda x: 5.59 if x == 1 else 1.29 if x == 2 else 3.49 if x == 3 else 6.99)
# Get the revenue
df['revenue'] = df.parallel_apply(lambda x: x['quantity']* x['price'], axis=1)| | date |product_id |quantity |month |price |revenue |
|--:|:--------------------|----------:|--------:|-----:|-----:|-------:|
| 0 | 2019-01-01 00:00:00 | 1 | 10 | 1 | 5.59 | 55.9 |
| 1 | 2019-01-01 00:52:25 | 4 | 36 | 1 | 6.99 | 251.64 |
| 2 | 2019-01-01 01:44:50 | 2 | 79 | 1 | 1.29 | 101.91 |
| 3 | 2019-01-01 02:37:15 | 1 | 33 | 1 | 5.59 | 184.47 |
| 4 | 2019-01-01 03:29:41 | 4 | 59 | 1 | 6.99 | 412.41 |Используйте parallel_apply для применения функции к группе
Вы также можете сгруппировать по определенному столбцу перед применением parallel_apply. В приведенном ниже примере мы можем сгруппировать по определенному month и получить сумму revenue за каждый месяц.
# Get the sum of revenue for every month
monthly_revenue_df = df.groupby('month').parallel_apply(np.sum)[['revenue']]Еще лучше, мы можем вычислить скользящую сумму, используя parallel_apply.
# Generate 3-month rolling revenue by month
monthly_revenue_df['rolling_3_mth_rev'] = monthly_revenue_df['revenue'].rolling(3, min_periods=3).parallel_apply(np.sum)| month | revenue | rolling_3_mth_rev |
|--------:|----------:|--------------------:|
| 1 | 188268 | nan |
| 2 | 164251 | nan |
| 3 | 176198 | 528717 |
| 4 | 178021 | 518470 |
| 5 | 188940 | 543159 |Используйте parallel_applymap для применения функции ко всему фрейму данных
Если есть функция, которую можно применить ко всему фрейму данных, applymap — идеальная функция. Например, чтобы преобразовать все элементы df в строку, мы можем использовать эту функцию.
# Convert every element of df to a string
df.parallel_applymap(lambda x: str(x))Полный код
import pandas as pd
import numpy as np
from pandarallel import pandarallel
# Generate a dataframe.
df = pd.DataFrame()
# Generate a column of random dates from 2019-01-01 to 2019-12-31
df['date'] = pd.date_range('2019-01-01', '2019-12-31', periods=10000)
# Seed numpy random
np.random.seed(0)
# Generate a column of random product_id from 1 to 5
df['product_id'] = np.random.randint(1, 5, 10000)
# Generate a column of quantity bought from 1 to 100
df['quantity'] = np.random.randint(1, 100, 10000)
# Initialize pandarallel
pandarallel.initialize()
# Group date by month using parallel_apply
df['month'] = df['date'].parallel_apply(lambda x: x.month)
# Assign a price to each product_id
df['price'] = df['product_id'].parallel_apply(lambda x: 5.59 if x == 1 else 1.29 if x == 2 else 3.49 if x == 3 else 6.99)
# Get the revenue
df['revenue'] = df.parallel_apply(lambda x: x['quantity']* x['price'], axis=1)
# print(df.head().to_markdown())
# Get the sum of revenue for every month
monthly_revenue_df = df.groupby('month').parallel_apply(np.sum)[['revenue']]
# Generate 3-month rolling revenue by month
monthly_revenue_df['rolling_3_mth_rev'] = monthly_revenue_df['revenue'].rolling(3, min_periods=3).parallel_apply(np.sum)
# print(monthly_revenue_df.head().to_markdown())Когда НЕ использовать Pandarallel
Мы не должны использовать Pandarallel, когда данные не помещаются в память. В этом случае используйте spark, pyspark или vaex.
Тем не менее, есть несколько вариантов использования pandarallel, которые принесут пользу ученым, работающим с данными. Хватит ждать операций с пандами и распараллелить их.