Запуск Random Forest
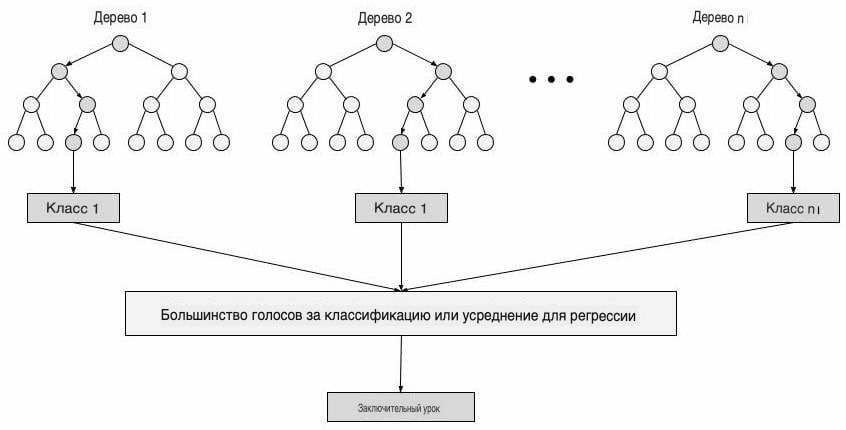
Random Forest - это контролируемый алгоритм машинного обучения, который широко используется в задачах классификации и регрессии. Он строит деревья решений на разных выборках и принимает их большинство голосов для классификации и усреднения в случае регрессии.
Одной из наиболее важных особенностей алгоритма случайного леса является то, что он может обрабатывать набор данных, содержащий непрерывные переменные, как в случае регрессии, и категориальные переменные, как и в случае классификации. Он дает лучшие результаты для задач классификации.
Аналогия с реальной жизнью:
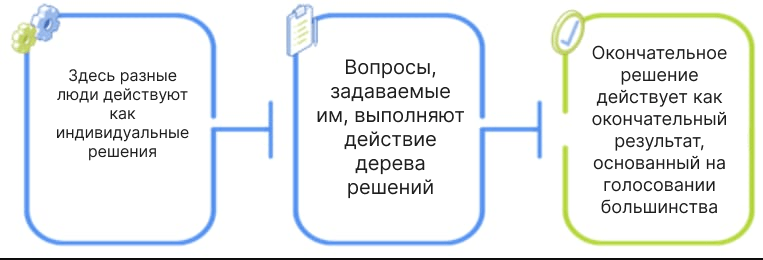
Работа алгоритма Random Forest:
Нам нужно знать технику Ensemble. Ensemble использует два типа методов:
- Bagging - Он создает другое обучающее подмножество из выборки обучающих данных с заменой, а окончательный результат основан на голосовании большинства. Например, случайный лес.
- Boosting (стимулирование) - Он объединяет слабых учеников в сильных учеников, создавая последовательные модели, так что окончательная модель имеет наивысшую точность. Например, ADA BOOS, XG BOOST.
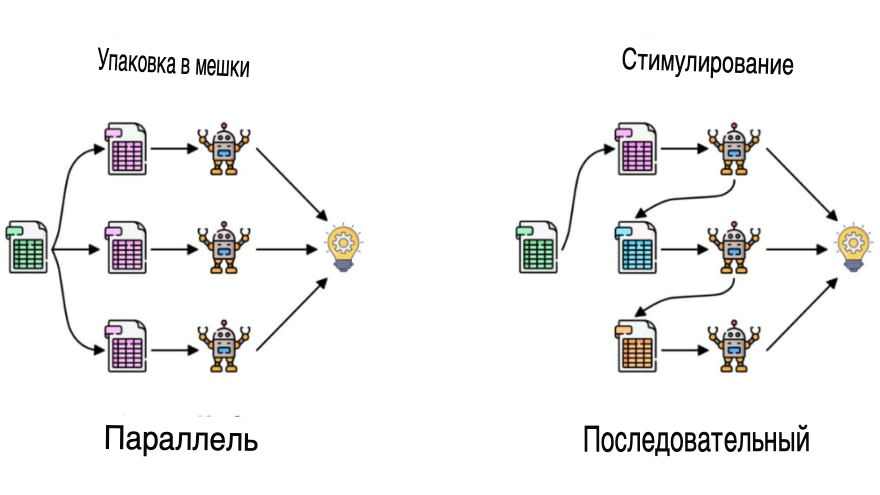
Шаги, задействованные в случайном лесу:
Шаг 1: В случайном лесу из набора данных, содержащего k записей, берется n случайных записей.
Шаг 2: Для каждой выборки строятся индивидуальные деревья решений.
Шаг 3: Каждое дерево решений будет генерировать выходные данные.
Шаг 4: Окончательный результат рассматривается на основе голосования большинства за классификацию и регрессию соответственно.
Кодирование в Python:
Давайте импортируем библиотеки:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snsИмпорт набора данных:
df = pd.read_csv('heart_v2.csv')
print(df.head())
sns.countplot(df['heart disease'])
plt.title('Value counts of heart disease patients')
plt.show()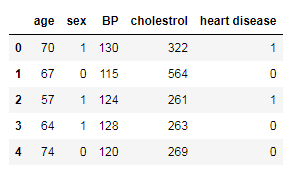
Присвоение переменной объекта значения X, а целевой переменной - значения Y:
X = df.drop('heart disease',axis=1)
y = df['heart disease']Выполнение Train Test Split:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42)
X_train.shape, X_test.shape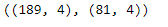
Импорт RandomForestClassifier и fit данных:
from sklearn.ensemble import RandomForestClassifier
classifier_rf = RandomForestClassifier(random_state=42, n_jobs=-1, max_depth=5, n_estimators=100, oob_score=True)
%%time
classifier_rf.fit(X_train, y_train)
classifier_rf.oob_score_
Настройка гиперпараметров для Random Forest с использованием GridSearchCV и подгонка данных:
rf = RandomForestClassifier(random_state=42, n_jobs=-1)
params = {
'max_depth': [2,3,5,10,20],
'min_samples_leaf': [5,10,20,50,100,200],
'n_estimators': [10,25,30,50,100,200]
}
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(estimator=rf, param_grid=params, cv = 4, n_jobs=-1, verbose=1, scoring="accuracy")
%%time
grid_search.fit(X_train, y_train)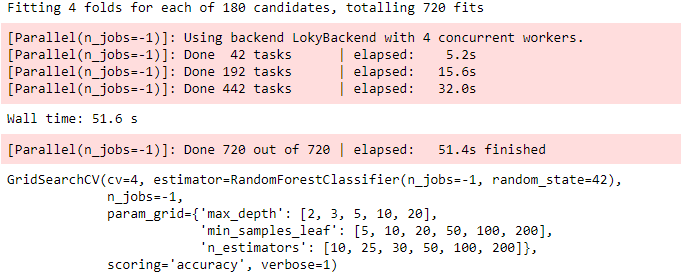
grid_search.best_score_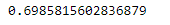
rf_best = grid_search.best_estimator_
rf_best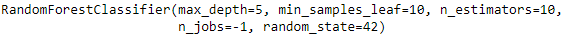
Визуализация:
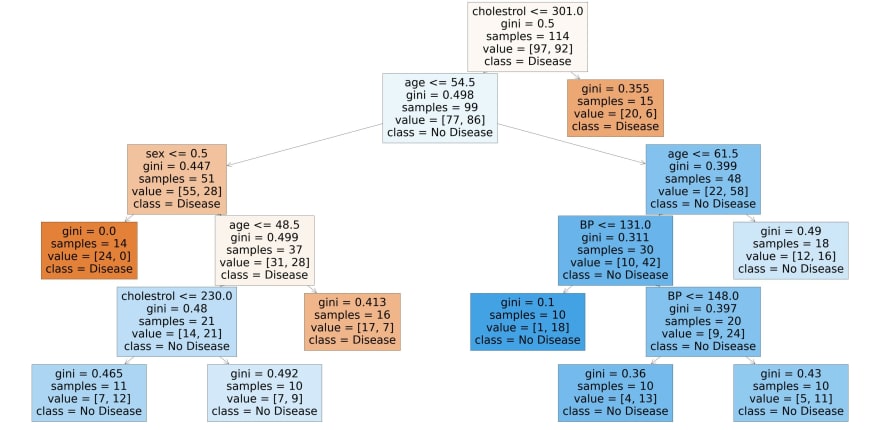
from sklearn.tree import plot_tree
plt.figure(figsize=(80,40))
plot_tree(rf_best.estimators_[7], feature_names = X.columns,class_names=['Disease', "No Disease"],filled=True);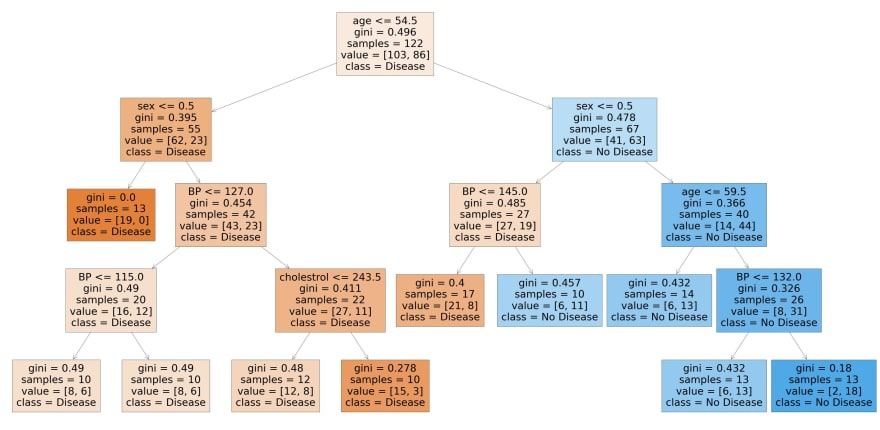
Сортировка данных в соответствии с важностью функции:
rf_best.feature_importances_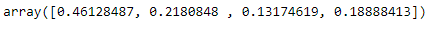
imp_df = pd.DataFrame({
"Varname": X_train.columns,
"Imp": rf_best.feature_importances_
})imp_df.sort_values(by="Imp", ascending=False)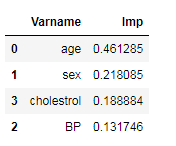
Заключение
Теперь мы можем сделать вывод, что Random Forest — одна из лучших техник с высокой производительностью, которая широко используется в различных отраслях благодаря своей эффективности. Он может обрабатывать двоичные, непрерывные и категориальные данные.
Random Forest — отличный выбор, если кто-то хочет построить модель быстро и эффективно, поскольку одна из лучших особенностей случайного леса — это то, что он также может обрабатывать пропущенные значения.
В целом, Random Forest — это быстрая, простая, гибкая и надежная модель с некоторыми ограничениями.