Создание веб-приложения для визуализации данных с использованием python-Streamlit
Обычно, когда мы думаем о создании и распространении в Интернете панели мониторинга визуализации или приложения машинного обучения на Python (скажем) для наших коллег / товарищей по команде / заинтересованных сторон или в качестве нашего портфолио, мы полагаемся на старых добрых гигантов, таких как Django или Flask.
Создание полярной диаграммы JS за 4 шага
Полярные диаграммы часто выглядят впечатляюще, что заставляет некоторых людей думать, что их создание - сложный процесс, требующий большого количества навыков и опыта. Что ж, я собираюсь развенчать этот миф прямо сейчас! Позвольте мне показать вам, как легко визуализировать данные в красивой интерактивной полярной диаграмме JavaScript.
Обработка отсутствующих данных в машинном обучении

В реальных (табличных) наборах данных вы часто понимаете, что не все функции будут доступны для всех ваших строк. Научившись справляться с этим явлением, вы все равно сможете использовать свой набор данных, даже если некоторые данные отсутствуют.
«Мыслительный процесс» геолокационной аналитики
Представьте, что вы являетесь участником игры «жизнь и смерть» в стиле Squid-game (шоу Netflix). Вам нужно выбрать только два поля данных, которые присутствуют в большинстве данных вокруг нас. Я могу с уверенностью сказать, что два поля данных о местоположении - широта и долгота - могут вас спасти.
Что такое обработка естественного языка (NLP)?

Привет, ребята, сегодня в этой статье я расскажу вам о том, что такое обработка естественного языка (NLP), и о многом другом, так что давайте начнем.
По определению обработка естественного языка (NLP) - это область искусственного интеллекта (ИИ), информатики и лингвистики, которая помогает машине взаимодействовать между компьютерами и человеческим языком
Подсказки типов и строки документации Python
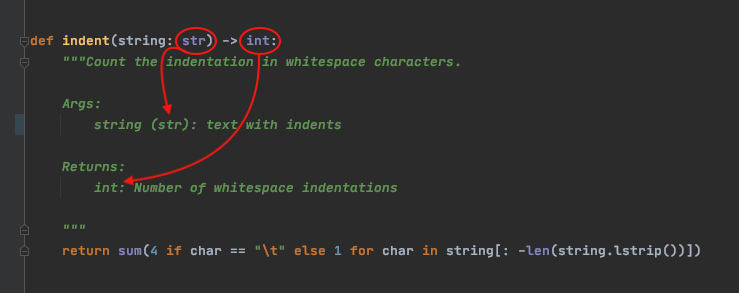
В этой статье вы будете сопровождать меня в путешествии по автоматической генерации строк документации в стиле Google из подсказок типов Python. Мы рассмотрим следующие элементы.
- Подсказки типов Python
- Вставка подсказки типа в строки документации функции
- Автоматизация с помощью хуков Git перед фиксацией
Виртуальные среды для абсолютных новичков - что это такое и как создать (+ примеры)

Если вы работаете над множеством разных проектов, вы узнаете ад зависимости множества проектов, требующих нескольких версий, нескольких пакетов. Вы не можете просто установить все пакеты глобально, как вы отслеживаете? Также что происходит, когда projectA требуется PackageX_version1, а ProjectB - PackageX_version2? Как оставаться в здравом уме, когда все представляет собой один большой беспорядок взаимозависимости, похожий на спагетти?
{kind=link}
В этой статье я попытаюсь убедить, что использование venv (виртуальной среды) - это способ отделить зависимости от других проектов. Мы начнем с определения, что такое venv, для чего он нужен и зачем он вам нужен. Затем мы создадим его и увидим все его преимущества. В конце у нас будет несколько основных правил, позволяющих сохранять зависимости в наших проектах как можно более чистыми.
Топ-3 альтернативных пакета Python для Pandas

Для многих современных специалистов по обработке данных Python - это язык программирования, который использовался в повседневной работе - как следствие, анализ данных будет выполняться с использованием одного из самых распространенных пакетов данных, которым являются Pandas. Многие онлайн-курсы и лекции представят Pandas как основу для любого анализа данных с помощью Python.
На мой взгляд, Pandas по-прежнему остается наиболее полезным и жизнеспособным пакетом для анализа данных на Python. Однако для сравнения я хочу познакомить вас с несколькими альтернативами пакетов Pandas. Я не собираюсь убеждать людей переходить с Pandas на другой пакет, но я просто хочу, чтобы люди знали, что есть альтернативы для пакета Pandas.
Итак, что это за альтернативные пакеты Pandas? Давайте займемся этим!
Анализ кибербезопасности - Руководство для начинающих по обработке журналов безопасности в Python
Сегодняшний взаимосвязанный мир делает нас более уязвимыми для кибератак: вездесущие устройства Интернета вещей записывают и слушают то, что мы делаем, спам и фишинговые электронные письма угрожают нам каждый день, а атаки на сети, которые воруют данные, могут привести к серьезным последствиям. Эти системы создают терабайты журналов, полных информации, которая может помочь обнаружить и защитить уязвимые системы. По консервативным оценкам, компания среднего размера с сотнями и тысячами взаимосвязанных устройств может создавать до 100 ГБ файлов журналов в день. Кроме того, частота регистрируемых событий может достигать уровней, исчисляемых десятками тысяч в секунду.
CLX (выраженные клики) является частью экосистемы RAPIDS, которая ускоряет обработку и анализ киберлогов. Как часть RAPIDS, он построен на основе RAPIDS DataFrames cuDF и дополнительно расширяет возможности библиотеки RAPIDS ML cuML, используя последние достижения в области обработки естественного языка для организации неструктурированных данных и построения моделей классификации.
Системы машинного обучения и рекомендаций с использованием ваших собственных данных Spotify

Как человек, который ежедневно использует Spotify, мне было интересно, какой анализ я могу сделать с моими собственными музыкальными данными. Spotify отлично справляется с рекомендациями треков как через ежедневные миксы, так и через радиостанции, но как мы сами создадим что-то подобное? Целью здесь было использовать машинное обучение и методы системы рекомендаций, чтобы рекомендовать новые треки на основе треков из моих любимых плейлистов.
Присоединяйся в тусовку
Поделитесь своим опытом, расскажите о новом инструменте, библиотеке или фреймворке. Для этого не обязательно становится постоянным автором.